PDF文件中表格信息的提取方法与流程
本发明涉及图文处理
技术领域:
,具体是一种pdf文件中表格信息的提取。
背景技术:
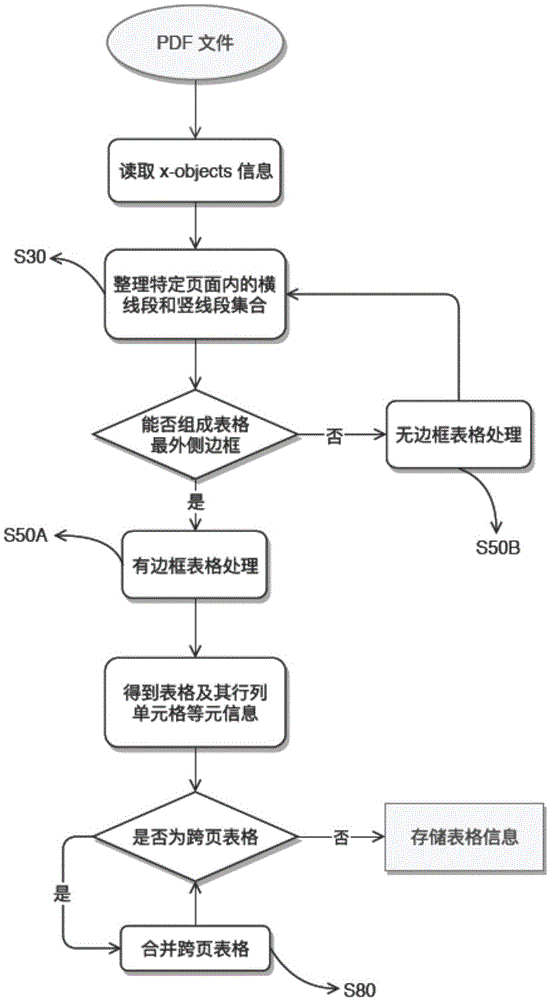
:现有的方法可以识别文本线段的组合并检测到表格,但是往往会有一些信噪比不高(因为有干扰线段存在)的情况错误地还原表格的行、列以及合并单元格的情况。技术实现要素:本发明所要解决的技术问题是针对上述现有技术存在的不足,而提供一种能更正确的还原pdf文件中的表格信息的一种pdf文件中表格信息的提取方法。为解决上述技术问题,本发明采用的技术方案是:一种pdf文件中表格信息的提取方法,其特征在于,包括:[s10]读取pdf文件到内存,读取x-refs以及所有的页面;[s20]解析页面内所有x-objects(包括文字、线段、曲线以及矩形)的位置等属性;[s30]找到并整理页面内所有横线(水平线)以及竖线(垂直线)的集合;[s40]判断当前页面的横竖线集合能否组成完整的表格边框,若能则按照步骤[s50a]处理,反之则按照步骤[s50b]处理;[s50]两种不同类型的表格处理方案;[s50a]有边框表格处理:[s50a1]提选出整理得到的原始线段;[s50a2]合并横纵向距离小于某个小量的临近平行线段;[s50a3]延长并连接端点之间距离小于某个小量的线段;[s50a4]对于某些表格单元格横竖线不对齐的状况,如果不对齐的值小于某个小量,则强行将其对齐;否则对不对齐的单元格所在的同行同列的单元格拆分成合并单元格;[s50b]无边框表格处理:[s50b1]收集页面内的散落文本框;[s50b2]确定文本框整体的边界,并将之作为当前表格的外边框;[s50b3]分别通过三种方案获取表格的内分割线:[s50b3i]根据文本框字符的对齐状况获得行和列的分割线;[s50b3ii]通过文本框的平均字符大小为单位,逐行逐列扫描得到文本的共同边界作为分割线;[s50b3iii]直接计算的到文本框之间的空白区域,并以此确定表格的内边框;[s50b4]根据新增的辅助内边框线段重新尝试有边框表格的处理方案;[s60]得到表格的行列以及单元格的元信息;[s70]判断是否为跨页表格,如果是跨页表格则合并跨页表格;若不是跨页表格则直接存储表格;[s80]存储表格的行列信息,以及所在的页和页面内位置等提取得到的信息。判断是否跨页以及合并跨页表格的具体方法是:[s701]将表格开始页面作为当前页,查看当前页面(去除页眉页脚以及水印等不相关信息后)是否为最底部一枚元素,若是则结束跨页表格合并;[s702]如果当前表格是页面最底部的元素,则查看下一页的最上方的元素是否为表格,若否则提前结束表格的跨页合并过程;[s703]若上一步为是,则对比开始页的表头和下一页的表格首行去除重复的表头;[s704]归一化跨页表格的总宽度和高度,如果列数相同则采用等比例缩放后的宽度,若列数不同则采用相同的行总宽度作为缩放比例;[s705]合并归一化后的跨页表格,并前进一页(将下一页设置为当前页);对步骤[s30]中找到的集合进行预处理,具体步骤包括:[s301]将矩形(左上角坐标[x1,y1],右下角坐标[x2,y2])拆分成四条单独的线段:([x1,y1],[x2,y1])、([x1,y2],[x2,y2])、([x1,y1],[x1,y2])、([x2,y1],[x2,y2]),其中x、y分别为以页面左上角为原点,以文字排版方向为坐标轴正方向计算得到的坐标值;[s302]将某些厚度非常接近零的线段剔除掉;[s303]将端点从坐标点[x1,y1]出发至终点[x2,y2]的非封闭曲线用最小的矩形包络,并把该矩形拆分成与[s301]类似的四条独立线段;[s304]从每条线段的较长边两侧方向截取一段狭长的矩形,分析后去除周边颜色不为纯色(或者与线段相同颜色)的线段(比如一些透明或者纯白色的交叉线以及与文字重叠的线段);[s305]在两个任意最近距离的横线段之间,若检测到一些竖线段,则在横线的左右两侧极值出分别增加一条辅助线段,竖线亦做类似处理;[s306]计算页面内的平均字体大小以及平均行间距,并以此组值,合并一些间距小于此值的线段(并忽略后续识别出的高度或宽度小于它们的单元格);与现有技术相比,本发明实现了pdf表格的更精确识别、更好的还原率以及更完整的表格提取过程。附图说明图1是本发明pdf文件中表格信息提取方法流程图;图2是对集合进行预处理的流程图;图3是s50a有边框表格处理方法流程图;图4是s50b无边框表格处理方法流程图;图5是s80跨页表格处理方法流程图。具体实施方式下面结合附图,对本发明作详细说明:本发明pdf文件中表格信息提取方法,流程图参考图1,详细的步骤如下:[s10]读取pdf文件到内存,读取对象号、代号引用表(x-refs)以及所有的页面;[s20]解析页面内所有x-objects即对象(包括文字、线段、曲线以及矩形)的位置等属性;[s30]找到并整理页面内所有横线(水平线)以及竖线(垂直线)的集合,并对它们进行一些预处理;预处理的具体流程参见图2,步骤包括:[s301]将矩形([x1,y1],[x2,y2])拆分成四条单独的线段:([x1,y1],[x2,y1])、([x1,y2],[x2,y2])、([x1,y1],[x1,y2])、([x2,y1],[x2,y2]),其中x、y分别为以页面左上角为原点,以文字排版方向为坐标轴正方向计算得到的坐标值;[s302]将某些厚度非常接近零的线段剔除掉,因为毫无粗度的线段完全无法在页面上被显示出来并识别为有效的表格分割线;[s303]将从[x1,y1]出发至[x2,y2]的曲线同样拆分成四条独立的线段;[s304]从每条线段的较长边两侧方向截取一段狭长的矩形,分析后去除周边颜色不为纯色(或者与线段相同颜色)的线段(比如一些透明或者纯白色的交叉线以及与文字重叠的线段);[s305]在两个任意最近距离的横线段之间,若检测到一些竖线段,则在横线的左右两侧极值出分别增加一条辅助线段,竖线亦做类似处理;[s306]计算页面内的平均字体大小以及平均行间距,并以此组值,合并一些间距小于此值的线段(并忽略后续识别出的高度或宽度小于它们的单元格);[s40]判断当前页面的横竖线集合能否组成完整的表格边框,若能则采用有边框表格的处理方案[s50a],反之采用无边框表格的处理方案[s50b];[s50]两种不同类型的表格处理方案,分别见图3以及图4;[s50a]有边框表格处理(图3):[s50a1]提选出整理得到的原始线段;[s50a2]合并横纵向距离小于某个小量的临近平行线段;[s50a3]延长并连接端点之间距离小于某个小量的线段;[s50a4]对于某些表格单元格横竖线不对齐的状况,如果不对齐的值小于某个小量,则强行将其对齐;否则对不对齐的单元格所在的同行同列的单元格拆分成合并单元格。[s50b]无边框表格处理(图4):[s50b1]收集页面内的散落文本框(舍弃为段落所在的文本行);[s50b2]确定文本框整体的边界,并将之作为当前表格的外边框;[s50b3]分别通过三种方案获取表格的内分割线:[s50b3i]更具文本框字符的对齐状况获得行和列的分割线(对文本排版要求严格);[s50b3ii]通过文本框的平均字符大小为单位,逐行逐列扫描得到文本的共同边界作为的分割线;[s50b3iii]直接计算的到文本框之间的空白区域,并以此确定变革的内边框;[s50b4]根据新增的辅助内边框线段重新尝试有边框表格的处理方案;[s60]得到表格的行列以及单元格(长宽以及文本等)的元信息;[s70]判断是否为跨页表格如果是跨页表格则合并跨页表格;若不是跨页表格则直接存储表格;[s80]具体的判断以及合并跨页表格的方案(见图5):[s801]将表格开始页面作为当前页,查看当前页面(去除页眉页脚以及水印等不相关信息后)是否为最底部一枚元素,若是则结束跨页表格合并;[s802]如果当前表格是页面最底部的元素,则查看下一页的最上方的元素是否为表格,若否则提前结束表格的跨页合并过程;[s803]若上一步为是,则对比开始页的表头和下一页的表格首行去除重复的表头;[s804]归一化跨页表格的总宽度和高度,如果列数相同则采用等比例缩放后的宽度,若列数不同则采用相同的行总宽度作为缩放比例;[s805]合并归一化后的跨页表格,并前进一页(将下一页设置为当前页);[s90]存储表格的行列信息,以及所在的页和页面内位置等提取得到的信息。实施例1采用本发明方法对如下pdf表格进行提取:提取后的表格信息为:上市公司东华软件股份公司上市地点深圳证券交易所股票简称东华软件股票代码002065从本实施例的提取结果来看,采用本发明提取方法,很好的实现了对线段的降噪处理。实施例2采用本发明方法对如下pdf表格进行提取:提取后的表格信息为:交易对方住所地址黄麟雏西安市碑林区交大三村24舍506号侯丹军北京市东城区香河园街1号院7楼1911号侯丹云北京市朝阳区西坝河南路3号c座1807号其他15名自然人交易对方具体信息详见报告书之第三节交易对方基本情况配套融资投资者待定从本实施例的提取结果来看,采用本发明提取方法,很好的实现了对线段的降噪处理。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1