一种工单数据的投诉倾向分析预警方法及装置与流程
本申请涉及大数据应用技术领域,具体涉及一种工单数据的投诉倾向分析预警方法及装置。
背景技术:
随着电力行业信息化建设的快速发展和普遍应用,电力企业各级单位、各业务部门基本实现了信息化全覆盖。其中,95598客户服务系统是电力企业与客户交流的重要窗口,该系统中积累了大量的非结构化的工单数据,电力企业根据工单数据的内容,了解客户的意图和态度,提升服务质量。
由于工单数据的数量众多,且各个工单数据的紧急程度存在差异,对于紧急程度较高的工单数据,若电力企业没有及时处理,则有可能被客户投诉。为了降低被客户投诉的风险,电力企业需要对工单数据进行分析,将工单数据进行投诉倾向等级划分,并对投诉倾向等级较高的的工单数据作出预警,电力企业根据预警情况,能够快速、有预见性和针对性地采取措施。
现有工单数据的投诉倾向分析仍然处于人工分析的阶段,而人工分析无法对工单数据进行及时有效地处理,从而导致现有分析方法效率低下的问题,因此,目前亟需一种能够及时有效地对工单数据进行分析,并及时作出投诉倾向预警的方法。
技术实现要素:
本申请提供一种工单数据的投诉倾向分析预警方法及装置,以解决现有人工分析方法效率低下的问题。
本申请的第一方面,提供一种工单数据的投诉倾向分析预警方法,包括:
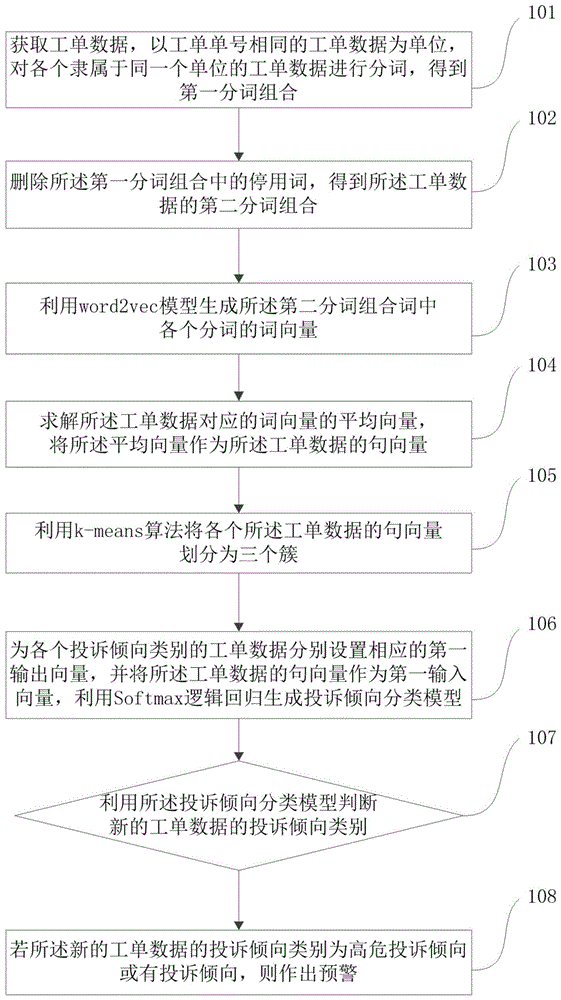
获取工单数据,以工单单号相同的工单数据为单位,对各个隶属于同一个单位的工单数据进行分词,得到第一分词组合;
删除所述第一分词组合中的停用词,得到所述工单数据的第二分词组合;
利用word2vec模型生成所述第二分词组合词中各个分词的词向量;
求解所述工单数据对应的词向量的平均向量,将所述平均向量作为所述工单数据的句向量;
利用k-means算法将各个所述工单数据的句向量划分为三个簇,所述三个簇对应所述工单数据的三个投诉倾向类别,其中,所述三个投诉倾向类别分别为:高危投诉倾向、有投诉倾向以及无投诉倾向;
为各个投诉倾向类别的工单数据分别设置相应的第一输出向量,并将所述工单数据的句向量作为第一输入向量,利用softmax逻辑回归生成投诉倾向分类模型;
利用所述投诉倾向分类模型判断新的工单数据的投诉倾向类别;
若所述新的工单数据的投诉倾向类别为高危投诉倾向或有投诉倾向,则作出预警。
可选的,所述利用word2vec模型生成所述第二分词组合词中各个第二分词的词向量,包括:
根据以下公式计算所述第二分词出现的频率,并判断所述第二分词出现的频率是否大于第一预设阈值:
其中,p(wi)为第二分词出现的频率,f(wi)为第二分词的出现频次,wi为第二分词,i=1,2,3...x,x为第二分词的数量,n为第二预设阈值;
若所述第二分词出现的频率大于第一预设阈值,则确定频率大于第一预设阈值的第二分词为高频分词,并将所述高频分词从所述第二分词组合中剔除,将剔除高频分词后的第二分词组合作为第三分词组合;
采用word2vec模型中的skip-gram模型构建所述第三分词组合的训练模型;
利用所述训练模型,生成所述第三分词组合中各个分词的词向量。
可选的,所述利用k-means算法将各个所述工单数据的句向量划分为三个簇,所述三个簇对应所述工单数据的三个投诉倾向类别,包括:
步骤301,利用k-means算法,随机选取三个句向量分别作为三个簇的中心,将所述三个簇的中心分别记为c1、c2和c3;
步骤302,分别计算各个所述句向量与所述三个簇的中心之间的欧式距离,确定与各个所述句向量的欧式距离最近的ci,并将所述句向量归类到ci对应的簇,其中,i=1,2,3;
步骤303,计算各个簇中所有句向量的各个维度的均值,将所述均值组成的向量作为所述簇的新的中心;
步骤304,判断所述簇的新的中心与随机选取的所述簇的中心是否一致,若不一致,则返回执行步骤302的操作,直至各个簇的新的中心与前一次计算的中心一致,并将所述簇的新的中心作为目标中心。
可选的,利用所述投诉倾向分类模型判断新的工单数据的投诉倾向类别,包括:
生成与所述新的工单数据对应的句向量;
将所述新的工单数据对应的句向量作为所述投诉倾向分类模型的第二输入向量,获取与所述第二输入向量对应的第二输出向量;
将所述第二输出向量与所述第一输出向量比较,获取与所述第二输出向量对应的第一输出向量,将所述第二输出向量对应的第一输出向量作出目标输出向量;
确定与所述目标输出向量对应的投诉倾向类别,并将所述目标输出向量对应的投诉倾向类别作为所述新的工单数据的投诉倾向类别。
本申请的第二方面,提供一种工单数据的投诉倾向分析预警装置,包括:
获取模块,用于获取工单数据,以工单单号相同的工单数据为单位,对各个隶属于同一个单位的工单数据进行分词,得到第一分词组合;
删除模块,用于删除所述第一分词组合中的停用词,得到所述工单数据的第二分词组合;
词向量生成模块,用于利用word2vec模型生成所述第二分词组合词中各个分词的词向量;
句向量生成模块,用于求解所述工单数据对应的词向量的平均向量,将所述平均向量作为所述工单数据的句向量;
划分模块,用于利用k-means算法将各个所述工单数据的句向量划分为三个簇,所述三个簇对应所述工单数据的三个投诉倾向类别,其中,所述三个投诉倾向类别分别为:高危投诉倾向、有投诉倾向以及无投诉倾向;
分类模型生成模块,用于为各个投诉倾向类别的工单数据分别设置相应的第一输出向量,并将所述工单数据的句向量作为第一输入向量,利用softmax逻辑回归生成投诉倾向分类模型;
判断模块,用于利用所述投诉倾向分类模型判断新的工单数据的投诉倾向类别;
预警模块,用于在所述判断模块确定所述新的工单数据的投诉倾向类别为高危投诉倾向或有投诉倾向的情况下,作出预警。
可选的,所述词向量生成模块包括:
第一判断单元,用于根据以下公式计算所述第二分词出现的频率,并判断所述第二分词出现的频率是否大于第一预设阈值:
其中,p(wi)为第二分词出现的频率,f(wi)为第二分词的出现频次,wi为第二分词,i=1,2,3...x,x为第二分词的数量,n为第二预设阈值;
剔除单元,用于在所述第一判断单元确定所述第二分词出现的频率大于第一预设阈值的情况下,确定频率大于第一预设阈值的第二分词为高频分词,并将所述高频分词从所述第二分词组合中剔除,将剔除高频分词后的第二分词组合作为第三分词组合;
训练模型构建单元,用于采用word2vec模型中的skip-gram模型构建所述第三分词组合的训练模型;
第一生成单元,用于利用所述训练模型,生成所述第三分词组合中各个分词的词向量。
可选的,所述划分模块包括:
选取单元,用于利用k-means算法,随机选取三个句向量分别作为三个簇的中心,将所述三个簇的中心分别记为c1、c2和c3;
第一计算单元,用于分别计算各个所述句向量与所述三个簇的中心之间的欧式距离,确定与各个所述句向量的欧式距离最近的ci,并将所述句向量归类到ci对应的簇,其中,i=1,2,3;
第二计算单元,用于计算各个簇中所有句向量的各个维度的均值,将所述均值组成的向量作为所述簇的新的中心;
第二判断单元,用于判断所述簇的新的中心与随机选取的所述簇的中心是否一致,若不一致,则返回执行所述第一计算单元的操作,直至各个簇的新的中心与前一次计算的中心一致,并将所述簇的新的中心作为目标中心。
可选的,所述判断模块包括:
第二生成单元,用于生成与所述新的工单数据对应的句向量;
第一获取单元,用于将所述新的工单数据对应的句向量作为所述投诉倾向分类模型的第二输入向量,获取与所述第二输入向量对应的第二输出向量;
第二获取单元,用于将所述第二输出向量与所述第一输出向量比较,获取与所述第二输出向量对应的第一输出向量,将所述第二输出向量对应的第一输出向量作出目标输出向量;
确定单元,用于确定与所述目标输出向量对应的投诉倾向类别,并将所述目标输出向量对应的投诉倾向类别作为所述新的工单数据的投诉倾向类别。
由以上技术方案可知,本申请提供一种工单数据的投诉倾向分析预警方法及装置,其中,所述方法包括:获取工单数据,以工单单号相同的工单数据为单位,对各个隶属于同一个单位的工单数据进行分词,得到第一分词组合;删除所述第一分词组合中的停用词,得到所述工单数据的第二分词组合;利用word2vec模型生成所述第二分词组合词中各个分词的词向量;求解所述工单数据对应的词向量的平均向量,得到所述工单数据对应的句向量;利用k-means算法将各个所述工单数据的句向量划分为三个簇;为各个投诉倾向类别的工单数据分别设置相应的第一输出向量,并将所述工单数据的句向量作为第一输入向量,利用softmax逻辑回归生成投诉倾向分类模型;利用所述投诉倾向分类模型判断新的工单数据的投诉倾向类别;若所述新的工单数据的投诉倾向类别为高危投诉倾向或有投诉倾向,则作出预警。
本申请提供的方法中,利用大量工单数据生成投诉倾向分类模型,在投诉倾向分类模型的基础上,对新的工单数据进行投诉倾向类别的预测,根据预测结果,实现及时主动预警的目的,从而解决了现有人工分析方法效率低下的问题。
附图说明
为了更清楚地说明本申请的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种工单数据的投诉倾向分析预警方法的工作流程图;
图2为本申请实施例提供的一种工单数据的投诉倾向分析预警方法中,词向量的生成方法的工作流程图;
图3为本申请实施例提供的一种工单数据的投诉倾向分析预警方法中,将句向量划分为三个簇的方法的工作流程图;
图4为本申请实施例提供的一种工单数据的投诉倾向分析预警方法中,判断新的工单数据的投诉倾向类别的方法的工作流程图;
图5为本申请实施例提供的一种工单数据的投诉倾向分析预警装置的结构示意图。
具体实施方式
为解决现有人工分析方法效率低下的问题,本申请提供一种工单数据的投诉倾向分析预警方法及装置。
参照图1所示的工作流程图,本申请实施例提供一种工单数据的投诉倾向分析预警方法,包括以下步骤:
步骤101,获取工单数据,以工单单号相同的工单数据为单位,对各个隶属于同一个单位的工单数据进行分词,得到第一分词组合。
该步骤中,通过95598客户服务系统获取实时或离线方式的工单文本,将工单文本作为工单数据,其中,所述工单文本包括以下字段:工单单号、来电内容、申请人、手机号码、受理人、紧急程度、用户地址、开始时间、创建工单时间、工单结束时间、当前环节、工单类型。其中,工单类型可以包括7种类型,分别是:表扬、故障报修、建议、举报、投诉、业务咨询和意见。
在一种可实现的方式中,以工单单号相同的工单数据为单位,使用python语言,在jieba工具包的支持下,采用精确模式,对工单数据进行分词。在对工单数据进行分词的过程中,定义电力行业相关的行业词典,例如,将电力行业相关的行业词典定义为:财务月、停送电、空开、停送点等单词。
步骤102,删除所述第一分词组合中的停用词,得到所述工单数据的第二分词组合。
在一种可实现的方式中,使用哈工大停用词词库,对第一分词组合进行处理,删除第一分词组合中的停用词,得到第二分词组合。
步骤103,利用word2vec模型生成所述第二分词组合词中各个分词的词向量。
word2vec模型是一群用来产生词向量的相关模型,这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。神经网络以词文本表现,并且需猜测相邻位置的输入词,在word2vec模型中的词袋模型假设下,词文本的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词文本到一个向量,该向量表示词对词之间的关系,该向量为神经网络之隐藏层。本申请实施例中,利用第二分词组合词中各个分词作为word2vec模型的词文本进行词向量的生成。
词向量是将词汇表的单词或短语映射到实数的向量。从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。本申请请实施例中,第二分词组合即为词汇表。
步骤104,求解所述工单数据对应的词向量的平均向量,将所述平均向量作为所述工单数据的句向量。
句向量是将一个句子或段落映射到实数的向量。在一种可实现的方式中,根据每条工单数据对应的词向量,对这些词向量进行求和,得到求和的词向量;然后对求和的词向量求平均,生成每条工单数据的句向量。
该步骤中,假设一条工单数据对应的第二分词组合为“客户咨询户号升位问题”,若分词“客户”对应的向量为[1,0,0,0,0];分词“咨询”对应的向量为[0,1,0,0,0];分词“户号”对应的向量为[0,0,1,0,0];分词“升位”对应的向量为[0,0,0,1,0];分词“问题”对应的向量为[0,0,0,0,1],则该条工单数据对应的句向量应为[0.2,0.2,0.2,0.2,0.2]。
步骤105,利用k-means算法将各个所述工单数据的句向量划分为三个簇,所述三个簇对应所述工单数据的三个投诉倾向类别,其中,所述三个投诉倾向类别分别为:高危投诉倾向、有投诉倾向以及无投诉倾向。
k-means算法是输入聚类个数k,以及包含n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法。k-means算法接受输入量k;然后将n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。本申请实施例中,将各个工单数据对应的句向量作为数据对象,聚类个数k的取值为3。
步骤106,为各个投诉倾向类别的工单数据分别设置相应的第一输出向量,并将所述工单数据的句向量作为第一输入向量,利用softmax逻辑回归生成投诉倾向分类模型。
softmax逻辑回归模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签y可以取两个以上的值。softmax逻辑回归中包含一个参数集,本申请实施例使用梯度下降算法对该参数集中的参数进行优化,优化时,学习率learning_rate设置为0.1。
在一种可实现的方式中,本申请实施例提供一种利用softmax逻辑回归生成投诉倾向分类模型的方法,包括以下步骤:
(1)使用python语言,在tensorflow工具包的支持下,指定假设函数为hypothesis=tf.nn.softmax(tf.matmul(x,w)+b),其中,x为句向量,w为权重,b为偏移量;
(2)使用python语言,在tensorflow工具包的支持下,使用交叉熵作为目标函数,记为:cost=tf.reduce_mean(-tf.reduce_sum(y*tf.log(hypothesis),axis=1));
(3)使用python语言,在tensorflow工具包的支持下,使用梯度下降优化权重参数,optimizer=tf.train.gradientdescentoptimizer(learning_rate=0.1).minimize(cost);
(4)通过上述(1)、(2)和(3)步骤,以带有第一输出向量的工单数据作为训练数据,生成投诉倾向的分类模型。
步骤107,利用所述投诉倾向分类模型判断新的工单数据的投诉倾向类别。
步骤108,若所述新的工单数据的投诉倾向类别为高危投诉倾向或有投诉倾向,则作出预警。
例如,一条工单数据的内容如下:“某处一栋楼表箱由于之前箱内着火,现表箱烧焦迹象严重,且进线和出线处都有烧焦迹象,担心有安全隐患,要求尽快处理”,若分类模型预测的等级为高危投诉倾向,则意味着存在投诉风险,将立即预警,并通知相关业务部门处理。
由以上技术方案可知,本申请提供的方法中,利用大量工单数据生成投诉倾向分类模型,在投诉倾向分类模型的基础上,对新的工单数据进行投诉倾向类别的预测,根据预测结果,实现及时主动预警的目的,从而解决了现有人工分析方法效率低下的问题。
参照图2所示的工作流程图,所述利用word2vec模型生成所述第二分词组合词中各个第二分词的词向量,包括以下步骤:
步骤201,根据以下公式计算所述第二分词出现的频率,并判断所述第二分词出现的频率是否大于第一预设阈值:
其中,p(wi)为第二分词出现的频率,f(wi)为第二分词的出现频次,wi为第二分词,i=1,2,3...x,x为第二分词的数量,n为第二预设阈值。
步骤202,若所述第二分词出现的频率大于第一预设阈值,则确定频率大于第一预设阈值的第二分词为高频分词,并将所述高频分词从所述第二分词组合中剔除,将剔除高频分词后的第二分词组合作为第三分词组合。
在一种可实现的方式中,n取1e-5。第一预设阈值取0.8,此时,当第二分词对应的p(wi)≥0.8时,该第二分词为高频分词,则该第二分词将被删除。
步骤203,采用word2vec模型中的skip-gram模型构建所述第三分词组合的训练模型。
对于所述第三分词组合中的每个第三分词,构建训练数据,训练数据的格式为(输入分词,输出分词)。首先,使用skip_window=2,从第三分词组合中找出每个第三分词的上下文;其次,基于上下文,构建训练数据。例如,假设一条工单数据对应的第三分词组合为:“客户咨询户号升位问题”,若“户号”为输入分词,则产生的训练数据包括:(户号,客户);(户号,咨询);(户号,升位)和(户号,问题)。
使用三层全连接神经网络构建训练模型,该神经网络包括:输入层、隐含层和输出层,从训练数据中训练模型,采用负采样方式(negativesampling)进行权重更新。其中,隐含层包含100个神经元。
步骤204,利用所述训练模型,生成所述第三分词组合中各个分词的词向量。
参照图3所示的工作流程图,所述利用k-means算法将各个所述工单数据的句向量划分为三个簇,所述三个簇对应所述工单数据的三个投诉倾向类别,包括以下步骤:
步骤301,利用k-means算法,随机选取三个句向量分别作为三个簇的中心,将所述三个簇的中心分别记为c1、c2和c3。
步骤302,分别计算各个所述句向量与所述三个簇的中心之间的欧式距离,确定与各个所述句向量的欧式距离最近的ci,并将所述句向量归类到ci对应的簇,其中,i=1,2,3。
步骤303,计算各个簇中所有句向量的各个维度的均值,将所述均值组成的向量作为所述簇的新的中心。
步骤304,判断所述簇的新的中心与随机选取的所述簇的中心是否一致,若不一致,则返回执行步骤302的操作,直至各个簇的新的中心与前一次计算的中心一致。
步骤305,将所述簇的新的中心作为目标中心。
参照图4所示的工作流程图,利用所述投诉倾向分类模型判断新的工单数据的投诉倾向类别,包括以下步骤:
步骤401,生成与所述新的工单数据对应的句向量。
步骤402,将所述新的工单数据对应的句向量作为所述投诉倾向分类模型的第二输入向量,获取与所述第二输入向量对应的第二输出向量。
步骤403,将所述第二输出向量与所述第一输出向量比较,获取与所述第二输出向量对应的第一输出向量,将所述第二输出向量对应的第一输出向量作出目标输出向量。
步骤404,确定与所述目标输出向量对应的投诉倾向类别,并将所述目标输出向量对应的投诉倾向类别作为所述新的工单数据的投诉倾向类别。
本申请实施例中,若3个第一输出向量分别为:[1,0,0,0,0]、[0,0,1,0,0]和[0,0,0,0,1],其中,[1,0,0,0,0]代表高危投诉倾向,[0,0,1,0,0]代表有投诉倾向,[0,0,0,0,1]代表无投诉倾向。
若新的工单数据的句向量对应的第二输出向量为[1,0,0,0,0],则该第二输出向量对应的第一输出向量为[1,0,0,0,0],该第二输出向量对应的新的工单数据的投诉倾向类别为高危投诉倾向。
参照图2所示的结构示意图,本申请实施例提供一种工单数据的投诉倾向分析预警装置,包括:
获取模块100,用于获取工单数据,以工单单号相同的工单数据为单位,对各个隶属于同一个单位的工单数据进行分词,得到第一分词组合;
删除模块200,用于删除所述第一分词组合中的停用词,得到所述工单数据的第二分词组合;
词向量生成模块300,用于利用word2vec模型生成所述第二分词组合词中各个分词的词向量;
句向量生成模块400,用于求解所述工单数据对应的词向量的平均向量,将所述平均向量作为所述工单数据的句向量;
划分模块500,用于利用k-means算法将各个所述工单数据的句向量划分为三个簇,所述三个簇对应所述工单数据的三个投诉倾向类别,其中,所述三个投诉倾向类别分别为:高危投诉倾向、有投诉倾向以及无投诉倾向;
分类模型生成模块600,用于为各个投诉倾向类别的工单数据分别设置相应的第一输出向量,并将所述工单数据的句向量作为第一输入向量,利用softmax逻辑回归生成投诉倾向分类模型;
判断模块700,用于利用所述投诉倾向分类模型判断新的工单数据的投诉倾向类别;
预警模块800,用于在所述判断模块确定所述新的工单数据的投诉倾向类别为高危投诉倾向或有投诉倾向的情况下,作出预警。
可选的,所述词向量生成模块包括:
第一判断单元,用于根据以下公式计算所述第二分词出现的频率,并判断所述第二分词出现的频率是否大于第一预设阈值:
其中,p(wi)为第二分词出现的频率,f(wi)为第二分词的出现频次,wi为第二分词,i=1,2,3...x,x为第二分词的数量,n为第二预设阈值;
剔除单元,用于在所述第一判断单元确定所述第二分词出现的频率大于第一预设阈值的情况下,确定频率大于第一预设阈值的第二分词为高频分词,并将所述高频分词从所述第二分词组合中剔除,将剔除高频分词后的第二分词组合作为第三分词组合;
训练模型构建单元,用于采用word2vec模型中的skip-gram模型构建所述第三分词组合的训练模型;
第一生成单元,用于利用所述训练模型,生成所述第三分词组合中各个分词的词向量。
可选的,所述划分模块包括:
选取单元,用于利用k-means算法,随机选取三个句向量分别作为三个簇的中心,将所述三个簇的中心分别记为c1、c2和c3;
第一计算单元,用于分别计算各个所述句向量与所述三个簇的中心之间的欧式距离,确定与各个所述句向量的欧式距离最近的ci,并将所述句向量归类到ci对应的簇,其中,i=1,2,3;
第二计算单元,用于计算各个簇中所有句向量的各个维度的均值,将所述均值组成的向量作为所述簇的新的中心;
第二判断单元,用于判断所述簇的新的中心与随机选取的所述簇的中心是否一致,若不一致,则返回执行所述第一计算单元的操作,直至各个簇的新的中心与前一次计算的中心一致,并将所述簇的新的中心作为目标中心。
可选的,所述判断模块包括:
第二生成单元,用于生成与所述新的工单数据对应的句向量;
第一获取单元,用于将所述新的工单数据对应的句向量作为所述投诉倾向分类模型的第二输入向量,获取与所述第二输入向量对应的第二输出向量;
第二获取单元,用于将所述第二输出向量与所述第一输出向量比较,获取与所述第二输出向量对应的第一输出向量,将所述第二输出向量对应的第一输出向量作出目标输出向量;
确定单元,用于确定与所述目标输出向量对应的投诉倾向类别,并将所述目标输出向量对应的投诉倾向类别作为所述新的工单数据的投诉倾向类别。
本领域的技术人员可以清楚地了解到本发明实施例中的技术可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本发明实施例中的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。
本说明书中各个实施例之间相同相似的部分互相参见即可。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例中的说明即可。
以上结合具体实施方式和范例性实例对本申请进行了详细说明,不过这些说明并不能理解为对本申请的限制。本领域技术人员理解,在不偏离本申请精神和范围的情况下,可以对本申请技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本申请的范围内。本申请的保护范围以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!