一种基于Labeled-LDA模型的用户音乐偏好分类方法与流程
本发明涉及自然语言处理领域,尤其涉及一种基于labeled-lda模型的用户音乐偏好分类方法。
背景技术:
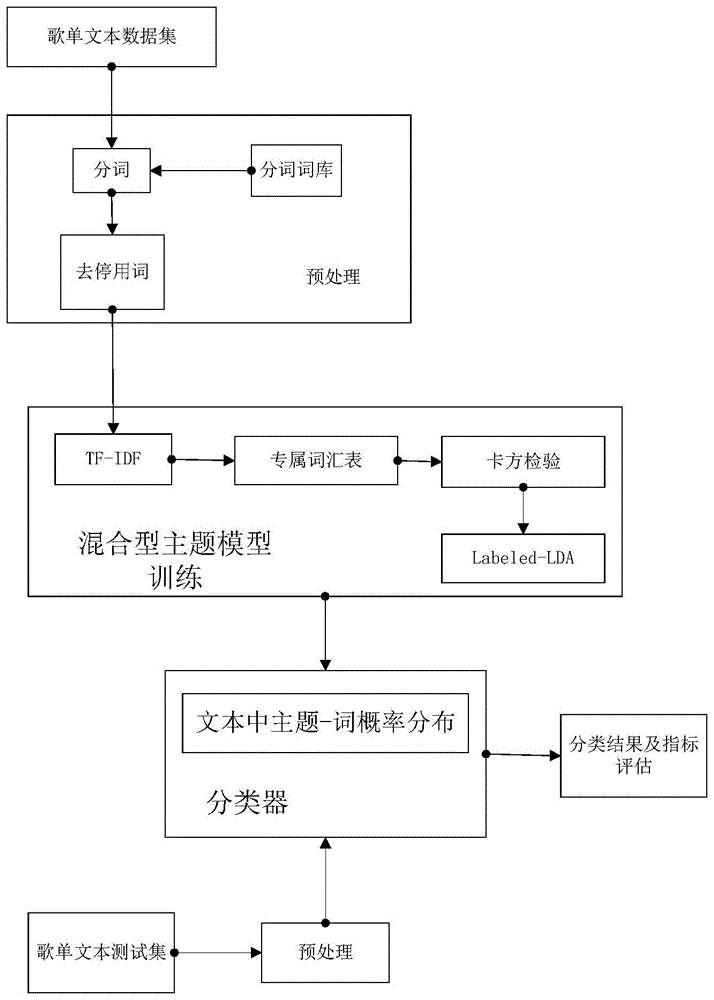
:近几年在线音乐平台如网易云音乐等将“音乐社交”的理念植入平台,通过歌单、评论、分享等多种互动方式,形成其独具特色的社交生态。因此利用用户的社交信息来分析用户的音乐喜好,个性化地给用户推荐音乐变得尤为重要。本发明主要应用于音乐社交网络上用户的音乐喜好。集合某一用户在平台创建的歌单的所有介绍信息,组织形成一份专属于该用户的音乐风格描绘文档。对该文档进行分析后得出该用户的音乐风格倾向。音乐平台中部分用户对自己的歌单介绍带上标签而部分用户并未带上标签,此发明可应用于未带上标签的用户的音乐偏好,向其推送更多的相关风格音乐。近些年研究者针对大规模,动态增长的语料库进行了建模,促使了文本分类技术的迅速发展和广泛应用。d.blei等人提出了一个重要的无监督主题模型,lda(latentdirichletallocation),克服了以往模型例如plsi(probabilisticlatentsemanticanalysis)中计算复杂度随文档数量线性增长的问题,且具有有效的训练方法。但lda仅仅是一个数据降维和聚类的算法,不能对人工标记的主题信息加以利用,将它实际运用在文本中会出现目标文本在不是自己的类别上处理分类时导致隐性主题被迫分类的困境,因此后续提出了labeled-lda模型,它比lda多了一项通过伯努利分布产生的文档的标签集,在训练时将标签信息嵌入到模型中,实现了将文档所属的隐含类别和文档集合的标签相关联。labeled-lda虽然可以较为准确的将文本进行分类,但是文本数据的杂乱性以及文档中无用词的过多干扰,往往不能突出关键词的权重,对算法的分类结果造成了一定的影响。技术实现要素:本发明的目的在于针对普通labeled-lda容易受文档本身数据的杂乱性以及文档中无用词的干扰的缺点,提出一种混合型主题文本分类方法。本发明的目的是通过以下技术方案来实现的:一种基于labeled-lda模型的用户音乐偏好分类方法,包括以下步骤:步骤1获取数据及预处理:步骤1.1使用网络爬虫技术爬取大量音乐平台用户的歌单数据,存入数据库中,所述歌单数据包括用户名,用户对自己创建的歌单的相关介绍,以及歌单的标签;步骤1.2选定九大音乐风格:电子,古典,古风,爵士,民谣,轻音乐,说唱,摇滚,流行;取数据库中用户的歌单数据进行预处理,通过中文分词系统进行分词、常见停用词过滤处理,形成词袋;步骤2建立混合型文本主题分类模型:步骤2.1对不同风格的音乐建立一份低频专属名词库,将出现频率低但能够代表一类音乐风格的词汇收录其中,如摇滚音乐有代表性的乐队,“黑豹”,“披头士”,人名如“崔健”,古典音乐中的英文词汇,如“modestmussorgsky”,“nocturne”,说唱音乐中的“mc”等;步骤2.2根据公式(1)将已经过步骤1.2初步预处理的歌单数据通过tf-idf算法计算每个词的权重,将tf-idf值大于阈值的词作为待分类文本的特征值,而小于该阈值的词添加到停用词列表中再一次进行过滤处理;其中:ni,j表示关键词j在文档i中出现的次数,q表示文档中的任意词汇;|d|表示语料库中的文档总数;|j:ti∈dj|表示包含词语ti的文档dj的个数,+1是为了防止分母为0;步骤2.3根据公式(2)对步骤2.2处理后的歌单数据进行卡方检验,计算每个词的卡方值,卡方检验的基本思想就是观察并检验数据的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度决定卡方值的大小,卡方值越大,越不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合;其中t代表词汇,k代表主题,a是包含词t且属于主题k的文档数量,b是包含词t但不属于主题k的文档数量,c是不包含词t且属于主题k的文档数量,d是不包含词t且不属于主题k的文档数量,n是语料库中文档的总数;步骤2.4labeled-lda模型采用目前较为主流的吉布斯采样(gibbssampling)算法;这种算法的主要思想是不断地用条件分布进行采样,使每次采样的结果更接近全概率分布,即每次保持其他分量的值不变,只对一个分量进行采样;gibbs采样公式如下:其中,p(zi=k|z-i,w)表示当前词wi在已知其他词各自所属主题的条件下,属于主题k的概率,zi表示文档第i个特征词对应的主题,z-i表示除去第i个词汇后剩余词汇的主题,m代表文档,αk,βt是两个超参数,代表主题k中词汇t的数量,代表文档m中主题k的数量,k是主题向量,v是词汇向量;结合步骤2.1,步骤2.2,步骤2.3,现改进gibbs采样公式如下:其中,zi表示文档第i个特征词对应的主题,z-i表示除去第i个词汇后剩余词汇的主题,k是当前文档所标记的主题,若当前词汇w存在于低频专属名词库中,则将该词的权重μ设为μ>2,否则μ<1,chi(t,k)是词t对主题k的卡方值,w(t)是词t的tf-idf值;步骤3训练数据与测试:步骤3.1将歌单训练数据经过步骤2,即通过改进的gibbs采样公式进行计算,最终统计歌单数据中的主题-词频率矩阵,得到k个主题中每个主题下的词的分布概率,从而完成混合型文本主题分类模型的训练;步骤3.2将歌单测试数据输入到步骤3.1中已经训练好的混合型文本主题分类模型中,其中采样公式的主题-词概率分布不再改变,由步骤3.1的训练结果提供,得到歌单测试数据的主题概率分布,即完成用户音乐偏好的分类。进一步地,所述步骤1.2中,常见停用词过滤处理包括去除歌单介绍中的<br>标签。本发明的有益效果是:本发明方法利用音乐社交平台的文本信息作为训练数据,结合了tf-idf算法(词频-逆文档频率),低频专属名词库以及卡方检验算法形成一种混合型文本主题分类模型,克服了普通labeled-lda模型受文档无意义高频词汇干扰,难以突出关键特征词汇等缺陷,在精确度,召回率以及macro-f1指标上都有较大的提升,非常适用于分析用户的音乐风格,对后续个性化提供音乐推荐方案具有重大意义。附图说明图1为本发明基于labeled-lda模型的用户音乐偏好分类方法的流程图;图2为labeled-lda模型示意图;图3为混合型文本主题分类模型示意图。具体实施方式下面结合附图和具体实施例对本发明作进一步详细说明。如图1所示,本发明提供的一种基于labeled-lda模型的用户音乐偏好分类方法,包括以下步骤:步骤1获取数据及预处理:步骤1.1使用网络爬虫技术爬取大量的网易云用户的歌单数据,存入数据库中,所述歌单数据包括用户名,用户对自己创建的歌单的相关介绍,以及歌单的标签,部分用户数据如表1所示;表1歌单数据步骤1.2选定九大音乐风格:电子,古典,古风,爵士,民谣,轻音乐,说唱,摇滚,流行;取数据库中用户的歌单数据进行预处理,通过中文分词系统进行分词、常见停用词过滤处理(例:去掉歌单介绍中的<br>标签等),形成词袋;步骤2建立混合型文本主题分类模型:步骤2.1通过对用户音乐风格文本的分析,发现有很多出现频率很低但能代表一类音乐风格的词汇,比如摇滚音乐有代表性的乐队,“黑豹”,“披头士”,人名如“崔健”,古典音乐中的英文词汇,如“modestmussorgsky”,“nocturne”,说唱音乐中的“mc”等。这些词语出现的频率较低,但包含重要的信息,与音乐风格的类别关联性大,对分类的结果起着重要的作用。在构建主题模型时容易造成特征词的过滤或者占有的权重过低,导致分类准确度下降。因此建立音乐风格的低频专属名词库变得尤为重要。本发明对不同风格的音乐建立一份低频专属名词库,将出现频率低但能够代表一类音乐风格的词汇收录其中,部分词汇表内容如表2所示;表2低频专属名词库音乐类别专属词汇电子house,电子舞曲,edm,dj,build-up,drop,breakdown,drumkit古典美声,modestmussorgsky,nocturne,穆索尔斯基,舒伯特,弥撒,波兰舞曲古风高山流水,庄生晓梦,浮生,浮屠,宫商角徵羽,河图,墨明棋妙,江湖爵士jazz,蓝调,萨克斯,爵士鼓,barrelhouse,bop,standard,摇摆乐,波普乐民谣吉他,爱尔兰,赵雷,安和桥,老狼,童年,李志,花粥,成都,陈粒轻音乐宁静,詹姆士·拉斯特,班德瑞,保罗·莫里哀,曼托瓦尼,理查德.克莱德曼说唱rap,嘻哈,hiphop,diss,freestyle,flow,r&b,饶舌,battle,mchotdog摇滚重金属,朋克,哥特,许巍,郑钧,崔健,黑豹,披头士,滚石,魔岩三杰流行周杰伦,中国风,李宗盛,五月天,林俊杰,邓丽君,粤语歌,迈克尔·杰克逊步骤2.2尽管在分词过程中使用停用词表能够去除部分的无意义高频词,但是仍然有大量的无关词汇存在,会大幅度拉低关键字在文本中的权重。因此本发明结合tf-idf(词频-逆文档频率)算法进行改进。tf-idf的主要思想是,某个词如果在一篇文档中出现的频率高,并且在其他文档中很少出现,则认为此词很可能是该篇文档的关键词,需要赋予较高的权重。本发明通过tf-idf算法计算每个词的权重,将tf-idf值大于阈值的词作为待分类文本的特征值,而小于该阈值的词添加到停用词列表中再一次进行过滤处理;其中:ni,j表示关键词j在文档i中出现的次数,q表示文档中的任意词汇;|d|表示语料库中的文档总数;|j:ti∈dj|表示包含词语ti的文档dj的个数,+1是为了防止分母为0;步骤2.3根据公式(2)对步骤2.2处理后的歌单数据进行卡方检验,计算每个词的卡方值,卡方检验的基本思想就是观察并检验数据的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度决定卡方值的大小,卡方值越大,越不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合;其中t代表词汇,k代表主题,a是包含词t且属于主题k的文档数量,b是包含词t但不属于主题k的文档数量,c是不包含词t且属于主题k的文档数量,d是不包含词t且不属于主题k的文档数量,n是语料库中文档的总数,如表3所示表3属于类别k不属于类别k总计包含词taba+b不包含词tcdc+d总计a+cb+dn步骤2.4图2表示labeled-lda文本主题模型,labeled-lda模型采用目前较为主流的吉布斯采样(gibbssampling)算法,结合tf-idf算法、低频专属名词库以及卡方检验形成混合型文本主题分类模型,如图3所示;a.labeled-ldalda是一个具有文档、主题和词的三层贝叶斯概率模型,每个文档的主题概率分布θm和每个主题的词分布相互独立,分别从参数为α和β的dirichlet分布中抽样产生。lda模型中的所有可见变量以及隐含变量的联合分布为:其中α代表θ的超参数,β代表的超参数,w代表词,z代表词的主题分配;但lda仅仅是一个数据降维和聚类的算法,将它实际运用在文本中会出现隐性主题被迫分类的困境。而改进的labeled-lda模型比lda模型多了一层文档标记层,使lda模型改良成监督型的算法。每篇训练文档中有自己的隐含主题,利用这些隐含主题,labeled-lda模型在训练阶段对词进行主题采样时,不再计算该词在未标记的类别上的概率。b.吉布斯采样考虑到labeled-lda模型中隐含变量联合分布的复杂度,采用目前较为主流的吉布斯采样(gibbssampling)算法。这种算法的主要思想是不断地用条件分布进行抽样,使每次抽样的结果更接近全概率分布,即每次保持其他分量的值不变,只对一个分量进行采样。gibbs采样公式如下:其中,p(zi=k|z-i,w)表示当前词wi在已知其他词各自所属主题的条件下,属于主题k的概率,zi表示文档第i个特征词对应的主题,z-i表示除去第i个词汇后剩余词汇的主题,m代表文档,αk,βt是两个超参数,代表主题k中词汇t的数量,代表文档m中主题k的数量,k是主题向量,v是词汇向量;对于上述公式中的两个超参数一般设置成α=50/t,β=0.01。模型的参数个数只与主题数和词数有关,参数估计是计算出文本-主题概率分布以及主题-词概率分布,即θ和通过对变量进行gibbs采样间接估算θ和c.改进吉布斯采样公式本发明在labeled-lda模型的基础上结合tf-idf算法,突出文本中的关键词汇权重,并利用专属名词库以及卡方检验降低无意义高频词汇对主题表达的影响,提高与主题关联度更高的低频词汇的权重;改进后的吉布斯采样公式如下:其中,zi表示文档第i个特征词对应的主题,z-i表示除去第i个词汇后剩余词汇的主题,k是当前文档所标记的主题,若当前词汇w存在于低频专属名词库中,则将该词的权重μ设为μ>2,否则μ<1,chi(t,k)是词t对主题k的卡方值,w(t)是词t的tf-idf值。步骤3获取并训练数据3.1爬取数据:使用网络爬虫技术爬取大量的网易云用户的歌单数据;3.2训练数据(1)预先选定九大音乐风格(电子,古典,古风,爵士,民谣,轻音乐,说唱,摇滚,流行)。取数据库中的680个用户的文档数据进行预处理,通过中文分词系统进行分词、停用词过滤等处理,形成词袋;(2)随机初始化,对训练语料中的每篇文档中的每个词w,随机赋一个主题z;(3)重新扫描整个语料库,对语料库中的每篇文档中的每个词w,按照改进后主题模型的gibbs抽样公式重新采样它的主题,在语料中进行更新;(4)迭代步骤(3)多次,直到gibbs抽样过程已经收敛;(5)统计语料库的主题-词频率矩阵,得到k个主题中每个主题下的词的分布概率;步骤4测试数据4.1评测指标采用精确度(precision)和召回率(recall)作为评价指标。f1-score是一种衡量分类模型准确度的重要指标,它同时兼顾了分类模型的精确度跟召回率,可以看作是模型精确度跟召回率的一种加权平均。将每个用户的歌单信息合成一篇文档,每篇文档使用自己的混淆矩阵计算f1-score,然后计算f1-score的平均值,即4.2将测试的数据文本输入到已经训练好的混合主题模型中,其中采样公式中的主题-词概率分布不再改变,由之前的训练结果提供,只需要估计新来的文本上的主题概率分布,即完成用户音乐偏好的分类。本发明可有效应用于未给歌单打上标签的用户,为其进行音乐偏好分类,继而推送更多相关风格音乐。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1