在128位宽的操作数上的融合乘加浮点运算的制作方法
本发明一般涉及数据处理系统,尤其涉及用于在128位宽的操作数上执行融合乘加浮点运算的单元、方法、系统和计算机程序产品。
背景技术:
2008年发布的ieee-754-2008二进制浮点运算标准规定了浮点数据架构,该架构通常在计算机硬件中实现,例如具有乘法器的浮点处理器。格式由符号、无符号偏置阶码和有效数组成。符号位是单个位,用“s”表示。用“e”表示的无符号偏置阶码例如对于单精度是8位长,对于双精度是11位长,对于四精度是15位长。有效数例如对于单精度是24位长,对于双精度是53位长,对于四精度是113位长。如ieee-754-2008标准所定义的,有效数的最高有效位,即所谓的隐含位,从阶码位中解码出。
为了改进浮点算术处理,大多数现代处理器使用称为融合乘法加法(在下面缩写为fma)的过程来合并浮点乘法运算(例如a×b)和浮点加法运算(例如,+c),用于作为单个指令执行,例如a×b+c,其中a、b、c是乘法乘积a×b以及c与乘积的和的操作数。通过在单个指令中执行两个运算,fma过程减少了总体执行时间。fma过程还提供了改进的精度,因为在以全精度执行了乘法和加法运算之后只需执行舍入。例如,只有一个舍入误差而不是两个。
分析应用程序(尤其是在大数据量上运行时)是非常计算密集型的。它们的主要数据类型是二进制浮点数。这包括商业上可用的分析软件,如ilog、spss、cognos、algo以及许多针对保险和银行业的专业分析软件包。
许多移动应用需要位置检测例程,这也是浮点密集型计算。这些例程的性能是远程信息处理等新兴领域的关键,它将移动输入与数据库查询和保险分析代码相结合,并具有实时要求。
随着问题规模的增大,算法的数值灵敏度被放大。这降低了算法的稳定性并降低了收敛速度。这在高性能领域是众所周知的效果。解决此问题的最简单方法是将数学上关键的例程从双精度切换到四精度浮点(128位)。
采用大数据分析,这个数值稳定性问题也在商业领域占据了一席之地。例如,注意到针对非常大的ilog安装和在大型数据集上运行的客户风险评估代码的收敛问题。对于大型ilog安装,当切换到128位浮点计算时,注意到收敛速度提高了15-30%。
us2016/0048374a1公开了通过使用辅助指令来模拟融合乘加(fma)运算的技术。根据该现有技术公开的技术,通过辅助指令模拟fma运算,以使得用于执行未融合乘加运算的现有硬件可用于模拟融合乘加运算而无需其他专用硬件。
模拟第一操作数、第二操作数和第三操作数的融合乘加运算包括由至少一个处理器至少部分地基于将第一操作数与第二操作数相乘来确定中间值。现有技术方法还包括由至少一个处理器确定上中间值或下中间值中的至少一个,其中,确定上中间值包括用指定的比特数对中间值向上舍入,确定下中间值包括用高中间值减去中间值。该方法还包括由至少一个处理器至少部分地基于将第三操作数添加到上中间值或下中间值之一来确定上限值和下限值。该方法还包括由至少一个处理器通过将上限值和下限值相加来确定第一操作数、第二操作数和第三操作数的模拟融合乘加结果。
us9,104,474b2公开了用于节能浮点乘法和/或加法运算的方法和电路。实施例提供节能的可变精度乘法和/或加法运算,同时跟踪浮点数的多少尾数位可以是确定的和/或提供包括乘法重放的节能浮点乘法,当乘法结果的最低部分可能影响最终结果时。
可变精度浮点电路使用实时确定性跟踪来提供运行时精度选择。确定性跟踪使得低精度计算(其结果可能不确定)能够在必要时以更高的精度重新进行。由于确定性可取决于数据,因此,它与数值计算一起确定。跟踪确定性的电路增加了最小的开销,而大多数计算产生具有较低精度的正确结果。
浮点乘法步骤由n位乘n位乘法器(n×n位乘法器)电路执行,该电路包括并行图和检测电路,其中并行图被配置为将乘法乘积的预定数量的最低有效位的载波设置为零以用于乘法运算,检测电路引起由乘法器进行的乘法运算的重放,以在必要时产生完全乘法结果。
可变精度浮点电路与浮点计算并行地确定乘加浮点计算的结果的确定性。可变精度浮点电路使用输入的确定性并结合来自计算的信息,例如取消、规格化移位和舍入的二进制数字,以执行结果的确定性的计算。可变精度浮点电路包括支持多个精度的可变精度尾数单元、以最低精度支持最大并行度的多阶码数据路径、以及提供输出的确定性边界的确定性计算单元。
在根据如上所述的现有技术的处理器上,以软件模拟128位浮点运算。所描述的方法通常比硬件实现慢一到两个数量级,这使得它们对大数据分析的吸引力降低。
技术实现要素:
提出了一种浮点单元,被配置为在三个128位宽的操作数上实现融合乘加运算。浮点单元包括:(i)113×113位乘法器,其连接到用于乘法操作数的数据流,并被配置为迭代地计算226位进位保存乘积,其中和项和进位项被分成乘积的高部分和低部分;(ii)左移位器,其连接到用于加数操作数的高部分和低部分的数据流,并被配置为传递加数的对齐部分;(iii)右移位器,其连接到用于加数操作数的高部分和低部分的数据流,并被配置为传递加数的对齐部分;(iv)选择电路,其连接到移位器的输出,包括3到2压缩器以将和项和进位项与加数合并;(v)加法器,其连接到来自选择电路的数据流;(vi)第一反馈路径,其将加法器的进位输出连接到选择电路,用于在两个后续的加法中对高部分和低部分执行中间乘积和对齐加数的宽加法运算;(vii)第二反馈路径,其将加法器的输出连接到移位器,用于使中间宽结果通过移位器以进行规格化,第二次通过加法器以进行舍入。
融合乘加运算(fma)的价值是一个指令执行两个运算:乘法运算和加法运算,因此,实现两倍的吞吐量。然而,fma的更高价值是组合操作的增强的准确性:加法是在准确的乘积和准确的加数上进行的。
对于128位浮点计算,舍入效应更严重。因此,当切换到128位浮点计算以获得更高精度时,具有fma是有利的。然而,128位fma也必须具有不错的性能,以使其对于应用具有吸引力并可用。
在浮点处理器中,一个中心区域是乘法器阵列。乘法器阵列用于进行两个数的乘法。通常使用具有基数4的最先进的布斯编码,这是常用的快速乘法算法。这减少了需要总计为n/2+1的乘积项的数量,其中n是每个操作数的位数。使用进位保存加法器电路完成求和,与其中通常由进位传播加法器电路执行的低位位置的进位被链接到下一个更高位置的正常加法相反,该电路允许并行处理所有位。进行这种求和的电路在本领域被称为缩减树。在缩减树的末尾,仍然存在两个项,即和项和进位项,它们分别代表信息的总和部分和信息的进位部分。这些项最终与对齐加数相加。同样,在此执行进位保存加法。最后,只剩下两个项,也是和项和进位项,这两个项必须使用进位传播加法器相加以生成一个最终结果。
有利地,本发明的浮点单元(fpu)由于其配置而允许在传统的128位浮点单元上用基于加法的数据流执行128位fma操作,如所介绍的,例如在ibmz13处理器中。由于只有适度的硬件扩展,本发明的实施例允许在128位基于加法的fpu上执行具有128位精度的真正fma,具有与乘法运算相同的23周期延迟时间。新的运算可每15个周期开始,它比例如在ibmzec12处理器上快5倍以上并且吞吐量高7.5倍,ibmzec12处理器模拟基于64位fma的浮点单元的操作。
有利地,根据本发明的实施例,对用于128位浮点运算的传统fma单元的扩展是操作数锁存器和用于第三操作数的解包电路。此外,还增加了乘法器,其中,为了节省电路面积,乘法器以迭代方式计算113×113位乘积。由于本发明的实施例,可能需要7次迭代来计算完整乘积。乘法器以进位保存格式传递乘积。此外,还增加了左移位器,其可连接到传统fma单元的寄存器。这也可以通过使右移位器成为旋转器并在随后的周期中使用来获得。进一步地,在移位器之后的选择电路由3到2压缩器增强,以将两个乘积项与加数合并。进一步地,前导零计数器连接到加数的解包电路。进一步地,还存在从加法器的输出到选择电路的反馈路径,作为加法器的另一输入,以执行中间乘积与未舍入和的宽加法。经由选择/交换电路返回到移位器的反馈路径用于使中间宽结果通过移位器以进行规格化,并且第二次通过加法器以进行舍入。
为了清楚起见,可以注意到,移位器可以被实现为移位器电路,加法器可以被实现为加法器电路,计数器可以被实现为计数器电路。
添加到基于加法的数据流中作为乘法器和反馈路径的块用于支持128位浮点乘法。其他块是乘加运算的开销。通过多次循环,对该数据流模拟128位fma。
根据有利的实施例,乘法器可被配置为顺序地计算乘积的高部分和低部分。因此,可以有效地计算四精度乘积。
根据有利的实施例,该单元可以包括用于如果加数的阶码减去加数的前导零数量大于乘积的阶码加上常数,则将乘积与加数对齐的装置,其中常数至少是2。通过这种方式,加数和乘积可以通过加法器和舍入单元有效地相加和舍入。
根据有利的实施例,该单元可包括用于将乘积的高部分和低部分与加数对齐并合并到单个数据部分的装置。这使得能够有效地计算四精度乘积。
根据有利的实施例,该单元可包括用于如果加数的阶码减去加数的前导零数量小于或等于乘积的阶码加上常数,则通过左移位器和/或右移位器将加数与乘积对齐的装置,其中常数至少为2。通过这种方式,加数和乘积可通过加法器和舍入单元有效地进行相加和舍入。
根据有利的实施例,该单元可以包括用于通过左移位器和/或右移位器将加数的高部分和低部分分别对齐乘积的装置。因此,双精度单元可用于计算四精度操作数。
根据有利的实施例,该单元可以包括用于在有效加法运算的情况下,通过选择电路和3到2压缩器将乘积的高部分和低部分与加数相加的装置。这实现了在双精度单元上计算四精度操作数。
根据有利的实施例,该单元可以包括用于在有效减法运算的情况下,如果循环进位运算的结果等于零,则计算乘积与负加数的负和作为结果,否则计算乘积与负加数之和加1作为结果的装置。因此,可以实现结果的最终舍入或规格化。
进一步地,提出了一种用于在浮点单元中执行二进制浮点算术计算的方法,浮点单元被配置为在三个128位宽操作数上实现融合乘加运算。该方法包括:(i)通过113×113位乘法器迭代地计算乘法操作数的226位进位保存乘积,其中和项和进位项被分为乘积的高部分和低部分;(ii)通过连接到数据流的左移位器对加数操作数的高部分和低部分进行对齐,左移位器被配置为传递加数的对齐部分;(iii)通过连接到数据流的右移位器对加数操作数的高部分和低部分进行对齐,右移位器被配置为传递加数的对齐部分;(iv)通过连接到移位器的输出并包括3到2压缩器的选择电路将两个乘积项与加数合并;(v)操作连接到来自选择电路的数据流的加法器;(vi)用将加法器的进位输出连接到选择电路的第一反馈路径,在两个后续的加法中,对高部分和低部分进行中间乘积和对齐的加数的宽加法;以及(vii)在将加法器的输出连接到移位器的第二反馈路径中,使中间宽结果通过移位器以进行规格化,并第二次通过加法器以进行舍入。
本发明的方法可以有利地使用如上所述的浮点单元在三个128位操作数上实现融合乘加运算。
根据有利的实施例,可由乘法器顺序地计算乘积的高部分和低部分。因此,可以以有效的方式计算四精度乘积。
根据有利的实施例,如果加数的阶码减去加数的前导零数量大于乘积的阶码加上常数,则乘积可与加数对齐,其中常数至少为2。通过这种方式,加数和乘积可以通过加法器和舍入单元有效地相加和舍入。
根据有利的实施例,乘积的高部分和低部分可以与加数对齐,并合并到单个数据部分。这使得能够以有效的方式计算四精度乘积。
根据有利的实施例,如果加数的阶码减去加数的前导零数量小于或等于乘积的阶码加上常数,则加数可通过左移位器和/或右移位器与乘积对齐,其中常数至少为2。通过这种方式,加数和乘积可通过加法器和舍入单元有效地相加和舍入。
根据有利的实施例,加数的高部分和低部分可通过左和/或右移位器分别与乘积对齐。因此,双精度单元可用于计算四精度操作数。
根据有利的实施例,在有效加法运算的情况下,乘积的高部分和低部分与加数可通过选择电路和3到2压缩器相加。这实现了在双精度单元上计算四精度操作数。
根据有利的实施例,在有效减法运算的情况下,如果循环进位运算的结果等于零,则可计算乘积和负加数的负和作为结果,否则,可计算乘积和负加数之和加一作为结果。因此,可以实现结果的最终舍入或规格化。
由于另一方面,提出了一种有利的计算机程序产品,用于在浮点单元中执行二进制浮点算术计算,浮点单元被配置为在三个128位宽操作数上实现融合乘加运算。该计算机程序产品包括计算机可读存储介质,其具有与其一起实现的程序指令,该程序指令可由计算机系统执行以使计算机系统执行包括以下步骤的方法:(i)由113×113位乘法器迭代地计算乘法操作数的226位进位保存乘积,其中和项和进位项被分成乘积的高部分和低部分;(ii)通过连接到数据流的左移位器对加数操作数的高部分和低部分进行对齐,左移位器被配置为传递加数的对齐部分;(iii)通过连接到数据流的右移位器对加数操作数的高部分和低部分进行对齐,右移位器被配置为传递加数的对齐部分;(iv)通过连接到移位器的输出并包括3到2压缩器的选择电路,将两个乘积项与加数合并;(v)操作连接到来自选择电路的数据流的加法器;(vi)采用将加法器的进位输出连接到选择电路的第一反馈路径,在两个后续的加法中,对高部分和低部分执行中间乘积和对齐的加数的宽加法操作;以及(vii)在将加法器的输出连接到移位器的第二反馈路径中,使中间宽结果通过移位器以进行规格化,并第二次通过加法器以进行舍入。
此外,提出了一种用于执行数据处理程序的数据处理系统,包括用于执行上述方法的计算机可读程序指令。
附图说明
从以下对实施例的详细描述中可以最好地理解本发明以及上述和其他目的和优点,但是不限于这些实施例。
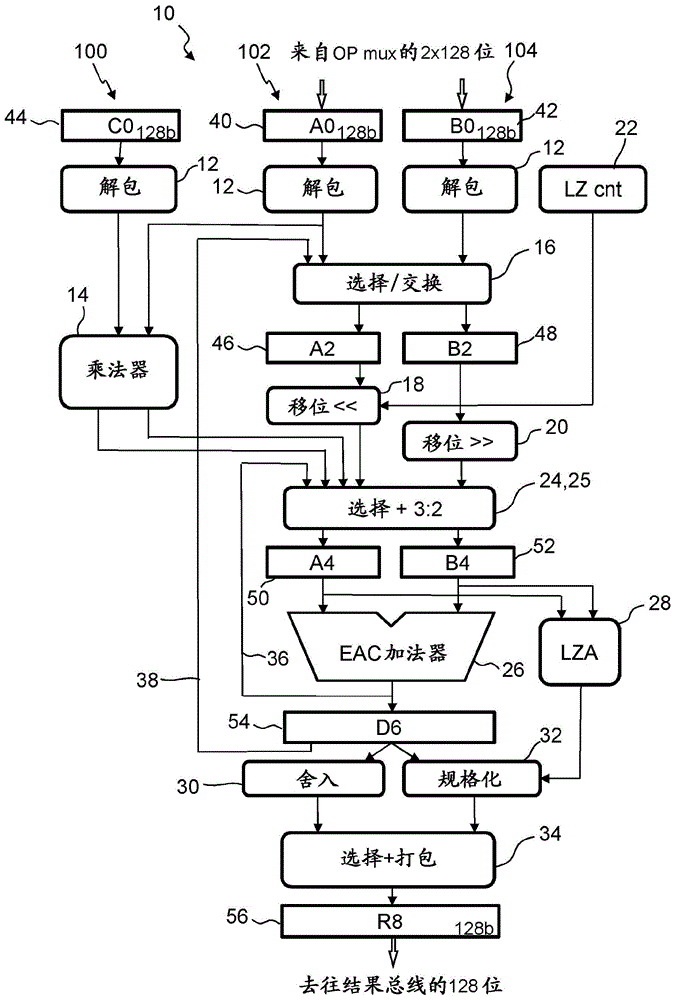
图1描绘了根据本发明实施例的用于执行二进制浮点算术计算的浮点单元的数据流,该浮点单元被配置为在三个128位宽的操作数a、b、c上实现融合乘加运算即a×c+b运算;
图2描绘了根据本发明另一实施例的用于执行二进制浮点算术计算的浮点单元的数据流,该浮点单元被配置为在三个128位宽的操作数a、b、c上实现融合乘加运算即a×b+c运算;
图3描绘了根据本发明实施例的加法器循环中的数据流,其被分成数据的高部分和低部分;
图4描绘了根据本发明实施例的与乘积相关的取决于加数的大小的数据流的流程图;
图5描绘了用于执行根据本发明的方法的数据处理系统的示例实施例。
具体实施方式
在附图中,相同的元件用相同的附图标记表示。附图仅是示意性表示,并非旨在描绘本发明的特定参数。此外,附图旨在仅描绘本发明的典型实施例,因此不应视为限制本发明的范围。
这里描述的说明性实施例提供了用于在三个128位宽的操作数上实现融合乘加运算(fma)的单元、方法、系统和计算机程序产品。为了描述清楚,说明性实施例在本文有时使用特定技术描述仅作为示例。
说明性实施例可用于在本发明的浮点单元上实现三个128位宽的操作数上的融合乘加运算。
图1描绘了根据本发明实施例的用于执行二进制浮点算术计算的浮点单元10的数据流,浮点单元10被配置为在三个128位宽的操作数a(102)、b(104)、c(100)上实现融合乘加运算即a×c+b运算。
根据本发明的实施例,因此可以在传统的128位浮点单元上,用基于加法的数据流执行128位fma,而仅有适度的硬件扩展。
浮点单元(fpu)10包括(i)113×113位乘法器14,其连接到用于乘法操作数100、102的数据流,并被配置为迭代地计算226位进位保存乘积70,其中和项71和进位项74被分成乘积70的高部分72、75和低部分73、76。分成和项71和进位项74以及高部分72、75和低部分73、76的详情在图3的数据流程中描绘。
fpu10还包括(ii)左移位器18,其连接到用于加数操作数104的高部分78和低部分79的数据流,并被配置为传递加数77的对齐部分,以及(iii)右移位器20,其连接到用于加数操作数104的高部分78和低部分79的数据流,并被配置为传递加数77的对齐部分。此外,fpu10具有(iv)选择电路24,其连接到移位器18、20的输出,包括3到2压缩器25以将和项71和进位项74与加数77合并;以及(v)加法器26,其连接到来自选择电路24的数据流。另外,fpu10包括(vi)第一反馈路径36,其将加法器26的进位输出91连接到选择电路24,用于在两个后续的加法中,针对高部分72、75、78和低部分73、76、79,执行中间乘积70与对齐的加数77的宽加法运算;(vii)第二反馈路径38,其将加法器26的输出连接到移位器18,20,用于使中间宽结果86通过移位器18、20以进行规格化以及第二次通过加法器26以进行舍入。
一个附加的移位器18是足够的,因为根据本发明的方法,数据流使得较大的操作数总是第一操作数。
作为和项71和进位项74中的乘积70的226位宽乘法器结果被分成低部分73,76和高部分72,75以适合窄128位fpu加法器26。低部分73、76和高部分72、75被顺序地发送通过加法器26。最后,低部分73、76和高部分72、75被合并、舍入或规格化到最终结果86。
因此,与传统的128位浮点单元相比,图1所示的本发明的浮点单元10的硬件扩展包括用于第三操作数100的操作数锁存器44和解包电路12、以及113×113乘法器14,其用于在进位项74和和项71中以迭代的方式顺序地获得226位进位保存乘积70,分成乘积70的高部分72、75和低部分73、76。进一步地,硬件扩展包括连接到a2寄存器46的左移位器18。可替换地,右移位器20可用位旋转功能实现并在后续的循环中使用。在移位器18、20之后的选择电路24通过3到2压缩器25增强,以将两个乘积项(和项71和进位项74)与加数77合并。另一个扩展是前导零计数器,其连接到加数操作数104(在该实施例中为操作数b)的解包电路12。进一步地,另外提供了围绕加法器26(其是循环进位加法器)的第一反馈路径36,其将加法器26的进位输出91连接到选择电路24,以实现用于针对高部分72、75、78和低部分73、76、79来执行中间乘积70和对齐的加数77的宽加法运算的第一反馈路径36。最后,另外提供了第二反馈路径38,其将加法器26的输出连接到移位器18、20,用于使中间宽结果86通过移位器18,20以进行规格化并第二次通过加法器26以进行舍入。
如图1所示的数据流通常采用自上而下的结构。输入操作数100、102、104被锁存到输入寄存器44、40、42中,然后进行解包。乘法操作数100、102被馈送到乘法器14。由乘法器14计算的乘积70被馈送到包括3到2压缩器25的选择电路24,然后通过a4寄存器50和b4寄存器52锁存到加法器26中。这是与分别通过选择/交换电路16、a2寄存器46和b2寄存器48锁存加数操作数104以及可选地通过移位器18、20(在图4种更详细地说明)移位到加法器26一起执行。左移位取决于前导零计数器22的结果,该计数器计算加数104的前导零数量。前导零计数器22特别用于非正规操作数。因此,在继续操作数的运算之前,可以对非正规操作数进行规格化。第一反馈环路36通过将加法器26的中间低结果88的进位91反馈回具有3到2压缩器25的选择电路24开始。加法器26的结果87和88在后续循环中被馈送到d6寄存器54,其中,第二反馈环路38开始将数据反馈回选择/交换电路16以用于下一次迭代。最后,d6寄存器54中的结果86分别由舍入电路30进行舍入或由规格化电路32进行规格化,这取决于前导零预测器28的结果。然后,最终结果可在选择和打包单元34中选择和打包,并锁存到r8输出寄存器56中,将数据馈送到128位结果总线。
因此,根据本发明实施例的方法可包括:(i)由113×113位乘法器14迭代地计算乘法操作数100、102的226位进位保存乘积70,其中和项71和进位项74被分成乘积70的高部分72,75和低部分73,76;(ii)通过连接到数据流的左移位器18将加数操作数104的高部分78和低部分79对齐,左移位器被配置成传递加数77的对齐部分;(iii)通过连接到数据流的右移位器20将加数操作数104的高部分78和低部分79对齐,右移位器被配置成传递对齐的加数77;(iv)通过连接到移位器18、20的输出并包括3到2压缩器25的选择电路24将两个乘积项71、74与加数77合并;(v)操作连接到来自选择电路24的数据流的加法器26;(vi)在将加法器26的进位输出91连接到选择电路24的第一反馈路径36中,针对高部分72、75、78和低部分73、76、79进行执行中间乘积70和对齐的加数77的宽加法;以及(vii)在将加法器26的输出连接到移位器18、20的第二反馈路径38中,在两个后续循环中,使中间宽结果86通过移位器18、20以进行规格化,并第二次通过加法器26以进行舍入。
图2描绘了根据本发明另一实施例的用于执行二进制浮点算术计算的浮点单元10的数据流,其中浮点单元10被配置为在三个128位宽的操作数a、b、c(100、102、104)上实现融合乘加运算即a×b+c运算。数据流与图1中所示的数据流非常相似,除了在该实施例中乘法操作数100、102是a和b,其中第三加数操作数104是c。主要的算术运算与图1中的相同。因此,为了说明,可以使用图1的描述。
图3描绘了根据本发明实施例的加法器环路s200、s202中的数据流,其被分成数据的高部分72、75、78和低部分73、76、79。在第一加法器环路s200中,通过将和项73、76与加数项79相加以便得到和项80的低部分82以及进位项83的低部分85并导致结果86的低部分88来计算低部分73、76、79,而在第二加法器环路s202中,通过将和项72、75与加数项78相加以便得到和项80的高部分81以及进位项83的高部分84并导致结果86的高部分87来计算高部分72、75、78。因此,进位位90、91从低部分85、88移位到高部分84、87。
在图4中示出了根据本发明实施例的与乘积70相关的取决于加数104的大小的数据流的流程图。
在加数77大的情况下,如果加数77的阶码减去加数77的前导零数量大于乘积70的阶码加上常数,其中常数至少为2,则乘积70与加数77对齐,s101。接下来,在非正规加数77并具有启用的下溢检查的情况下,步骤s106,加数77在移位器18中被规格化,步骤s108(参见图1)。非正规数是浮点数,其中没有前导零的有效数将导致阶码,该阶码低于浮点表示的最小阶码。
并行地,在步骤s102中,在乘法器14中利用进位项74和和项71计算乘积70,其分成高部分72、75和低部分73、76。低部分79和高部分78在两个后续循环中相加以形成完全计算的低乘积和完全计算的高乘积。在左移位器18中,低乘积和高乘积在步骤s104中基于阶码差而与加数77对齐,并在加法器26中与对齐的加数77相加或被减去。最后,在步骤s112中对结果86舍入。
在加数小的情况下,如果加数77的阶码减去加数77的前导零数量小于或等于乘积70的阶码加上常数,其中常数至少为2,则加数77的低部分79和高部分78通过移位器18和20与乘积70对齐,s103。首先,在乘法器14中,在步骤s120利用和项71和进位项74计算乘积70,其分成高部分72、75和低部分73、76。在步骤s122中,基于阶码差,加数77通过移位器18、20对齐,被分成高加数78和低加数79。
如果是有效加法运算的情况,则在步骤s124中做出决定。在有效加法运算的情况下,乘积70的高部分72、75、78和低部分73、76、79与加数77由选择电路24和3到2压缩器25顺序地相加,步骤s126。
在有效减法运算的情况下,在步骤s128中,针对低部分73、76和高部分72、75,由3到2压缩器25和加法器26顺序地计算乘积70与负加数77的负和作为第一结果86,计算乘积70与负加数77之和加1作为第二结果86。如果循环进位运算的结果等于零,则采用第一结果86,否则采用第二结果86。在步骤s132中,由前导零预测器28确定前导零的数量,以用于后来的规格化。分别针对结果和86的低部分88和高部分87,在移位器18和20中进行相对于舍入点的对齐和规格化或非规格化移位,步骤s130、s134。加法器26用于合并结果86的低部分88和高部分87。最后的舍入或规格化作为最后的步骤s136执行,以便得到最终结果。
现在参考图5,示出了数据处理系统210的示例的示意图。数据处理系统210仅是合适的数据处理系统的一个示例,并不旨在对本文描述的本发明的实施例的使用范围或功能提出任何限制。无论如何,数据处理系统210能够实现和/或执行上文阐述的任何功能。
在数据处理系统210中,存在计算机系统/服务器212,其可与许多其他通用或专用计算系统环境或配置一起操作。可适用于与计算机系统/服务器212一起使用的众所周知的计算系统、环境和/或配置的示例包括但不限于个人计算机系统、服务器计算机系统、瘦客户端、胖客户端、手持设备或膝上型设备、多处理器系统、基于微处理器的系统、机顶盒、可编程消费电子产品、网络pc、小型计算机系统、大型计算机系统、以及包括任何上述系统或设备的分布式云计算环境等。
计算机系统/服务器212可以在由计算机系统执行的计算机系统可执行指令(例如程序模块)的一般上下文中描述。通常,程序模块可以包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、逻辑、数据结构等。计算机系统/服务器212可以在分布式云计算环境中实践,其中任务由通过通信网络链接的远程处理设备执行。在分布式云计算环境中,程序模块可以位于包括存储器存储设备的本地和远程计算机系统存储介质中。
如图5所示,数据处理系统210的计算机系统/服务器212以通用计算设备的形式表现。计算机系统/服务器212的组件可以包括但不限于:一个或者多个处理器或者处理单元216,系统存储器228,连接不同系统组件(包括系统存储器228和处理单元216)的总线218。
总线218表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器,外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(isa)总线,微通道体系结构(mac)总线,增强型isa总线、视频电子标准协会(vesa)局域总线以及外围组件互连(pci)总线。
计算机系统/服务器212典型地包括多种计算机系统可读介质。这些介质可以是任何能够被计算机系统/服务器212访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
系统存储器228可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(ram)230和/或高速缓存存储器232。计算机系统/服务器212可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统234可以用于读写不可移动的、非易失性磁介质(图中未显示,通常称为“硬盘驱动器”)。尽管图5中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如cd-rom,dvd-rom或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线218相连。存储器228可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本发明各实施例的功能。
具有一组(至少一个)程序模块242的程序/实用工具240,可以存储在例如存储器228中,这样的程序模块242包括——但不限于——操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块242通常执行本发明所描述的实施例中的功能和/或方法。
计算机系统/服务器212也可以与一个或多个外部设备214(例如键盘、指向设备、显示器224等)通信,还可与一个或者多个使得用户能与该计算机系统/服务器212交互的设备通信,和/或与使得该计算机系统/服务器212能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口222进行。并且,计算机系统/服务器212还可以通过网络适配器220与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图所示,网络适配器220通过总线218与计算机系统/服务器212的其它模块通信。应当明白,尽管图中未示出,可以结合计算机系统/服务器212使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、raid系统、磁带驱动器以及数据备份存储系统等。
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是――但不限于――电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。这里所使用的计算机可读存储介质不被解释为瞬时信号本身,诸如无线电波或者其他自由传播的电磁波、通过波导或其他传输媒介传播的电磁波(例如,通过光纤电缆的光脉冲)、或者通过电线传输的电信号。
这里所描述的计算机可读程序指令可以从计算机可读存储介质下载到各个计算/处理设备,或者通过网络、例如因特网、局域网、广域网和/或无线网下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光纤传输、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或者网络接口从网络接收计算机可读程序指令,并转发该计算机可读程序指令,以供存储在各个计算/处理设备中的计算机可读存储介质中。
用于执行本发明操作的计算机程序指令可以是汇编指令、指令集架构(isa)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据或者以一种或多种编程语言的任意组合编写的源代码或目标代码,所述编程语言包括面向对象的编程语言—诸如smalltalk、c++等,以及常规过程式编程语言—诸如“c”语言或类似的编程语言。计算机可读程序指令可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络—包括局域网(lan)或广域网(wan)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。在一些实施例中,通过利用计算机可读程序指令的状态信息来个性化定制电子电路,例如可编程逻辑电路、现场可编程门阵列(fpga)或可编程逻辑阵列(pla),该电子电路可以执行计算机可读程序指令,从而实现本发明的各个方面。
这里参照根据本发明实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述了本发明的各个方面。应当理解,流程图和/或框图的每个方框以及流程图和/或框图中各方框的组合,都可以由计算机可读程序指令实现。
这些计算机可读程序指令可以提供给通用计算机、专用计算机或其它可编程数据处理装置的处理器,从而生产出一种机器,使得这些指令在通过计算机或其它可编程数据处理装置的处理器执行时,产生了实现流程图和/或框图中的一个或多个方框中规定的功能/动作的装置。也可以把这些计算机可读程序指令存储在计算机可读存储介质中,这些指令使得计算机、可编程数据处理装置和/或其他设备以特定方式工作,从而,存储有指令的计算机可读介质则包括一个制造品,其包括实现流程图和/或框图中的一个或多个方框中规定的功能/动作的各个方面的指令。
也可以把计算机可读程序指令加载到计算机、其它可编程数据处理装置、或其它设备上,使得在计算机、其它可编程数据处理装置或其它设备上执行一系列操作步骤,以产生计算机实现的过程,从而使得在计算机、其它可编程数据处理装置、或其它设备上执行的指令实现流程图和/或框图中的一个或多个方框中规定的功能/动作。
附图中的流程图和框图显示了根据本发明的多个实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或指令的一部分,所述模块、程序段或指令的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 还没有人留言评论。精彩留言会获得点赞!