一种基于RGB-D相机的卷积神经网络目标检测方法与流程
本发明属于计算机视觉领域,具体涉及一种基于rgb-d相机的卷积神经网络目标检测方法。
背景技术:
传统目标检测算法利用人工设计的特征提取器提取图像特征,再使用svm等机器学习算法,对特定区域内的特征进行分类,得到检测结果。但是由于人工设计的特征提取器具有一定的局限性,只能提取部分物体特征,难以对一个物体的特征进行充分提取,机器学习算法也难以学得物体的所有特征,导致整个算法的泛化能力比较差,识别的精度非常低,难以达到预期要求。
从2012年起,深度学习在计算机领域内得到广泛的应用,解决了诸多计算机视觉领域的难题。尤其是卷积神经网络在图像分类、目标检测、语义分割等计算机视觉问题上表现突出。经过在大量图片数据集上的训练,卷积神经网络能够充分学习目标物体的特征,并将这些特征进行组合得到最后的检测结果。相较传统的目标检测算法,基于卷积神经网络的目标检测算法需要依赖于更大的图片数据集,所以通过卷积层提取出的特征更具有普适性,更能代表物体的通用特征。所以基于卷积神经网络的目标检测算法能达到传统算法难以达到的精度。
而仅仅依赖于彩色图像的卷积神经网络算法在精度上的提升有限,在近几年增长已经趋于平缓。而在实际的目标检测系统中,需要利用深度传感器采集到的深度信息来辅助得到物体的空间坐标。所以本发明提出了一种利用深度信息来辅助目标检测的方法,提升目标检测算法的精度。
技术实现要素:
本发明针对现有技术只利用卷积神经网络来检测目标物体的位置在检测精度上有一定的上限,提出了一种基于rgb-d相机的卷积神经网络目标检测方法。
本发明提出了一种基于rgb-d相机的卷积神经网络目标检测方法,并利用soft-nms对于传统的nms(nonmaximumsuppression)算法进行了改进。本方法利用彩色相机和深度相机采集图片,利用rgb-d相机采集的深度图,将彩色图片输入目标检测网络,利用融合深度图信息,调整网络输出结果,达到高检测精度。
本发明目的是利用视觉系统中经常会使用到的深度图像,改变目标检测只利用彩色图像的单一性,从而提高预测的精度。
具体步骤如下:
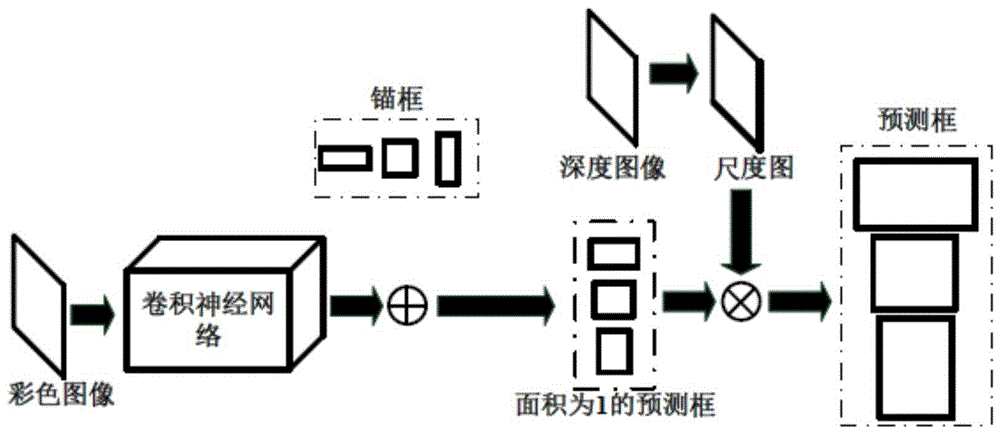
步骤(1):利用rgb-d相机获取彩色图像和深度图像
使用rgb-d相机对于包含目标物体的场景进行拍摄,得到一张彩色图像和与彩色图像像素一一对应的深度图像。
步骤(2):利用卷积神经网络对于目标物体位置进行预测
(a)先收集包含目标物体的数据集,手工标定目标框,使目标框刚好能包含目标物体。统计数据集中目标框的长宽比,利用k均值聚类产生k个长宽比例值。然后产生k个面积为1的锚框,锚框的长宽比分别对应于聚类产生的k个值,就得到k个形状不一的锚框。
(b)将彩色图片输入卷积神经网络,产生预测结果参数。预测结果参数为若干组五维向量参数,为n×k×(score,cx,cy,dw,dh),其中n表示卷积神经网络最后一层特征图上的像素点的个数,k表示锚框数量,score表示网络输出在当前位置区域的预测框存在物体的置信值,cx和cy分别表示预测框中心点的坐标,dw和dh表示在当前位置对于某个特定锚框长宽的修正量。利用以下公式,对锚框的形状进行修正,就可以得到一个面积为1的预测框:
其中pw和ph表示锚框的长和宽,
经过以上步骤,将彩色图片输入到卷积神经网络,得到一系列的预测框,每个预测框包含置信值,中心坐标和长宽。选取一个阈值,将置信值低于该阈值的预测框除去,就能滤除大量不包含物体的预测结果。
步骤(3):求解从深度值到目标物体尺寸的映射关系模型
利用卷积神经网络得到目标物体中心坐标,将其映射到深度图上。得到物体中心点深度值,也就是物体与摄像头沿相机光轴的距离h。假设摄像头的焦距为f,目标物体的尺寸为l,目标物体在相机成像平面上的投影为s,即为尺度因子。根据相似三角形的性质,得到s如下:
s与h之间存在反比关系,利用步骤(1)中得到的图库,得到多组(s,h)关系对,利用线性回归算法求得f与l的乘积值,得到一个从深度到物体尺寸的反比模型。
步骤(4):产生带尺度的预测框
利用步骤(2)中产生的目标物体的中心位置,找到深度图像上对应位置的深度信息,并利用步骤(3)中的模型关系得到尺度因子s。将s与步骤(2)中的面积为1的预测框的长宽相乘,得到带尺度的预测框。
步骤(5):利用soft-nms算法去除多余的预测框
经过以上步骤,在同一个物体上容易产生多个带尺度的预测框。利用soft-nms算法去除多余的带尺度的预测框,保留一个预测结果。设s1和s2分别为两个预测框的面积,δs为两个预测框重合的面积,定义iou为:
将预测结果中所有的预测框按置信值从大到小排序,依次选取目标框,并选取出排在当前预测框之后并且与当前预测框iou大于设定阈值的预测框,认为他们都是对于同一物体的预测。对所有同一物体的预测框做加权平均,公式如下:
其中boxj表示第j个预测框的参数,包括中心坐标和长宽。利用当前计算的box值作为最终预测框的信息,并去掉其他在当前这一物体上的预测框,就得到最终的预测结果。
步骤(6)得到最终目标物体的空间位置
再在深度图中找到目标框的位置,计算目标框中所有像素点的平均深度值,得到目标物体的深度。利用物体中心坐标和平均深度值,结合相机的内部参数,得到最终物体的空间位置。
本发明的有益效果:本发明结合深度图像的信息,改变了目标检测网络中锚框的结构,使网络的预测更具有针对性,提升了网络的检测精度,具有重要的工程实际意义。
附图说明
图1为本发明流程图;
图2为从深度值到目标物体尺寸的映射关系模型图。
具体实施方式
以下结合图1对本发明作进一步说明,本发明包括以下步骤:
步骤(1):利用rgb-d相机获取彩色图像和深度图像
使用rgb-d相机对于包含目标物体的场景进行拍摄,得到一张彩色图像和与彩色图像像素一一对应的深度图像。
步骤(2):利用卷积神经网络对于目标物体位置进行预测
(a)先收集包含目标物体的数据集,手工标定目标框,使目标框刚好能包含目标物体。统计数据集中目标框的长宽比,利用k均值聚类产生k个长宽比例值。然后产生k个面积为1的锚框,锚框的长宽比分别对应于聚类产生的k个值,就得到k个形状不一的锚框。
(b)将彩色图片输入卷积神经网络,产生预测结果参数。预测结果参数为若干组五维向量参数,为n×k×(score,cx,cy,dw,dh),其中n表示卷积神经网络最后一层特征图上的像素点的个数,k表示锚框数量,score表示网络输出在当前位置区域的预测框存在物体的置信值,cx和cy分别表示预测框中心点的坐标,dw和dh表示在当前位置对于某个特定锚框长宽的修正量。利用以下公式,对锚框的形状进行修正,就可以得到一个面积为1的预测框:
其中pw和ph表示锚框的长和宽,
经过以上步骤,将彩色图片输入到卷积神经网络,得到一系列的预测框,每个预测框包含置信值,中心坐标和长宽。选取一个阈值,将置信值低于该阈值的预测框除去,就能滤除大量不包含物体的预测结果。
步骤(3):求解从深度值到目标物体尺寸的映射关系模型
如图2所示,利用卷积神经网络得到目标物体中心坐标,将其映射到深度图上,得到物体中心点深度值,也就是物体与摄像头沿相机光轴的距离h。假设摄像头的焦距为f,目标物体的尺寸为l,目标物体在相机成像平面上的投影为s,即为尺度因子。根据相似三角形的性质,得到s如下:
s与h之间存在反比关系,利用步骤(1)中得到的图库,得到多组(s,h)关系对,利用线性回归算法求得f与l的乘积值,得到一个从深度到物体尺寸的反比模型。
步骤(4):产生带尺度的预测框
利用步骤(2)中产生的目标物体的中心位置,找到深度图像上对应位置的深度信息,并利用步骤(3)中的模型关系得到尺度因子s。将s与步骤(2)中的面积为1的预测框的长宽相乘,得到带尺度的预测框。
步骤(5):利用soft-nms算法去除多余的预测框
经过以上步骤,在同一个物体上容易产生多个带尺度的预测框。利用soft-nms算法去除多余的带尺度的预测框,保留一个预测结果。设s1和s2分别为两个预测框的面积,δs为两个预测框重合的面积,定义iou为:
将预测结果中所有的预测框按置信值从大到小排序,依次选取目标框,并选取出排在当前预测框之后并且与当前预测框iou大于设定阈值的预测框,认为他们都是对于同一物体的预测。对所有同一物体的预测框做加权平均,公式如下:
其中boxj表示第j个预测框的参数,包括中心坐标和长宽。利用当前计算的box值作为最终预测框的信息,并去掉其他在当前这一物体上的预测框,就得到最终的预测结果。
步骤(6)得到最终目标物体的空间位置
再在深度图中找到目标框的位置,计算目标框中所有像素点的平均深度值,得到目标物体的深度。利用物体中心坐标和平均深度值,结合相机的内部参数,得到最终物体的空间位置。
- 还没有人留言评论。精彩留言会获得点赞!