卷积神经网络的构建方法及系统与流程
本发明涉及机器学习(Machine Learning,ML)和人工智能(Artificial Intelligence,AI)技术领域,尤其涉及一种卷积神经网络(Convolutional Neural Network,CNN)的构建方法及系统。
背景技术:
深度学习(Deep Learning,DL)是模拟人脑的思维方式和处理问题的方法。人脑的计算神经元数量是百亿量级,即使是一个“小型”的CNN所需要的计算也非常庞大,而且几乎所有的深度学习网络均运行在CPU(或CPU集群),或GPU(或GPU集群)硬件平台之上,所需要的硬件资源非常巨大,导致成本和功耗都非常大,运行速度缓慢,很多CNN在高性能的芯片平台上运行时也只能达到几帧/每秒的速度,无法进行实时处理。
卷积神经网络包括卷积层和全连接层,其计算过程是逐层计算,所需要的计算非常庞大,而且特定的卷积神经网络网络只能实现特定的功能,当构建一个新的卷积神经网络以支持新的功能时,不能直接对之前的卷积神经网络进行配置更改以构建生成新的卷积神经网络。
上述技术方案的弊端是,卷积神经网络的构建过程效率低。
技术实现要素:
本发明的主要目的在于提供一种卷积神经网络的构建方法,旨在提高卷积神经网络的构建过程的效率,从而非常灵活地支持不同的功能或应用。
为实现上述目的,本发明提供的卷积神经网络的构建方法包括以下步骤:
接收单元化指令,根据所述单元化指令将用于进行卷积操作的硬件资源配置成卷积单元,将用于进行激活操作的硬件资源配置成激活单元,将用于进行池化操作的硬件资源配置成池化单元;
读取配置文件,所述配置文件包括卷积单元配置参数、激活单元配置参数及池化单元配置参数、卷积层的层数、全连接层的层数;
根据所述卷积单元配置参数配置所述卷积单元、根据所述激活单元配置参数配置所述激活单元、根据所述池化单元配置参数配置所述池化单元,以及配置卷积层的层数和全连接层的层数以构建卷积神经网络。
优选地,所述根据所述卷积单元配置参数配置所述卷积单元、根据所述激活单元配置参数配置所述激活单元、根据所述池化单元配置参数配置所述池化单元,以及配置卷积层的层数和全连接层的层数以构建卷积神经网络之后还包括:
读取权值数据、偏置数据、激活函数、池化函数及输入图像;
根据所述权值数据、所述偏置数据、所述激活函数、所述池化函数及所述输入图像进行卷积神经网络的计算。
优选地,所述根据所述权值数据、所述偏置数据、所述激活函数、所述池化函数及所述输入图像进行所述卷积神经网络的计算包括:
卷积层计算和全连接层计算;
所述卷积层计算包括:按照预设的并行分组规则将待处理的卷积层输入Map和/或卷积核分组至并行的Tc个卷积层并行处理模块;
每个所述卷积层并行处理模块完成对其组内的卷积层输入Map的卷积、加偏置、激活和池化计算,并存储计算获得的卷积层输出Map;
所述全连接层计算包括:
按照预设的并行分组规则将待处理的全连接层输入数据和/或权值数据分组至并行的Tf个全连接层并行处理模块;
每个所述全连接层并行处理模块完成对其组内的全连接层输入数据的乘加计算,以及乘加计算结果的加偏置和激活计算,并存储计算获得的全连接层输出数据;
其中,Tc、Tf均为大于1的自然数。
优选地,所述每个所述卷积层并行处理模块完成对其组内的卷积层输入Map的卷积、加偏置、激活和池化计算,并存储计算获得的卷积层输出Map包括:
读取卷积核参数及卷积层输入Map的数据,对所述卷积层输入Map进行若干次卷积操作直至完成所述卷积层输入Map的卷积操作;
将所述卷积层输入Map的卷积操作结果与偏置数据求和,并将求和结果进行激活操作及池化操作,以得到卷积层输出Map;
其中,所述卷积核参数为用于对所述卷积层输入Map进行卷积操作得到卷积层输出Map的卷积核的参数,在第c个卷积层中,卷积层输出Map数量为Kc,Kc为大于1的自然数,每个所述卷积层并行处理模块用于计算Kc/Tc个卷积层输出Map。
优选地,所述每个所述全连接层并行处理模块完成对其组内的全连接层输入数据的乘加计算,以及乘加计算结果的加偏置和激活计算,并存储计算获得的全连接层输出数据包括:
计算全连接层输入数据及对应的权值数据的乘积和累加计算;
获取每个所述全连接层输入数据与其对应的所述权值数据的乘积的累加结果,并将所述累加结果与偏置数据求和,对求和结果进行激活操作,以得到全连接层输出数据;
其中,在第f个全连接层中,全连接层输出数据的数量为Kf,Kf为大于1的自然数,每个所述全连接层并行处理模块用于计算Kf/Tf个全连接层输出数据。
此外,为实现上述目的,本发明还提供一种卷积神经网络的构建系统,所述卷积神经网络的构建系统包括:
单元化模块,用于接收单元化指令,根据所述单元化指令将用于进行卷积操作的硬件资源配置成卷积单元,将用于进行激活操作的硬件资源配置成激活单元,将用于进行池化操作的硬件资源配置成池化单元;
接口模块,用于读取配置文件,所述配置文件包括卷积单元配置参数、激活单元配置参数及池化单元配置参数、卷积层的层数、全连接层的层数;
网络解释器模块,用于根据所述卷积单元配置参数配置所述卷积单元、根据所述激活单元配置参数配置所述激活单元、根据所述池化单元配置参数配置所述池化单元,以及配置卷积层的层数和全连接层的层数以构建卷积神经网络。
优选地,所述卷积神经网络的构建系统还包括:
计算模块,用于读取权值数据、偏置数据、激活函数、池化函数及输入图像;并根据所述权值数据、所述偏置数据、所述激活函数、所述池化函数及所述输入图像进行所述卷积神经网络的计算。
优选地,所计算模块包括用于卷积层计算的卷积层单元和用于全连接层计算的全连接层单元;
所述卷积层单元具体用于,按照预设的并行分组规则将待处理的卷积层的输入Map和/或卷积核分组至并行的Tc个卷积层并行处理模块;
每个所述卷积层并行处理模块完成对其组内的卷积层输入Map的卷积、加偏置、激活和池化计算,并存储计算获得的卷积层输出Map;
所述全连接层单元具体用于,按照预设的并行分组规则将待处理的全连接层输入数据和/或权值数据分组至并行的Tf个全连接层并行处理模块;
每个所述全连接层并行处理模块完成对其组内的全连接层输入数据的乘加计算,以及乘加计算结果的加偏置和激活计算,并存储计算获得的全连接层输出数据;
其中,Tc、Tf均为大于1的自然数。
优选地,所述卷积层单元包括:
第一处理子单元,用于读取卷积核参数及卷积层输入Map的数据,对所述卷积层输入Map进行若干次卷积操作直至完成所述卷积层输入Map的卷积操作;
第二处理子单元,用于将所述卷积层输入Map的卷积操作结果与偏置数据求和,并将求和结果进行激活操作及池化操作,以得到卷积层输出Map;
其中,所述卷积核参数为用于对所述卷积层输入Map进行卷积操作得到卷积层输出Map的卷积核的参数,在第c个卷积层中,卷积层输出Map数量为Kc,Kc为大于1的自然数,每个所述卷积层并行处理模块用于计算Kc/Tc个卷积层输出Map。
优选地,所述全连接层单元包括:
第三处理子单元,用于计算全连接层输入数据及对应的权值数据的乘积;
第四处理子单元,用于获取每个所述全连接层输入数据与其对应的所述权值数据的乘积的累加结果,并将所述累加结果与偏置数据求和,对求和结果进行激活操作,以得到全连接层输出数据;
其中,在第f个全连接层中,全连接层输出数据的数量为Kf,Kf为大于1的自然数,每个所述全连接层并行处理模块用于计算Kf/Tf个全连接层输出数据。
在本发明的技术方案中,先根据单元化指令将硬件资源配置成所述卷积单元、所述激活单元及所述池化单元,在每次需要构建或构建新的所述卷积神经网络时,只需要读取所述配置文件,即可根据所述配置文件配置所述卷积单元、所述激活单元及所述池化单元、卷积层的层数和全连接层的层数等参数,因此,卷积神经网络的构建方法构建效率高,从而非常灵活地支持不同的功能或应用。
附图说明
图1为本发明卷积神经网络的构建方法一实施例的系统架构示意图;
图2为本发明卷积神经网络的构建方法第一实施例的流程示意图;
图3为本发明卷积神经网络的构建方法一实施例中基于主处理器FPGA加速的卷积神经网络实现框架图;
图4为本发明卷积神经网络的构建方法一实施例中卷积层单元并行处理流程示意图;
图5为本发明卷积神经网络的构建方法一实施例中卷积层并行处理模块内部的处理流程示意图;
图6为本发明卷积神经网络的构建方法一实施例中全连接层单元并行处理流程示意图;
图7为本发明卷积神经网络的构建方法一实施例中全连接层并行处理模块内部的处理流程示意图;
图8为本发明卷积神经网络的构建系统第一实施例的功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种卷积神经网络的构建方法。
请参照图1,为了实现卷积神经网络的构建方法,在本实施例中提供由三个核心器件:ARM协处理器、DDR存储器及FPGA主处理器构建的卷积神经网络的构建系统,其他辅助器件不一一列举。
所述ARM协处理器用于控制卷积层单元和全连接层单元逐层进行计算以及传输配置文件和权值数据(文件);所述DDR存储器用于存储计算数据及配置文件、权值数据及偏置数据等。
所述主处理器FPGA包括:
1、单元化模块,用于接收单元化指令,以将用于进行卷积操作的硬件资源配置成卷积单元,用于进行激活操作的硬件资源配置成激活单元,用于进行池化操作的硬件资源配置成池化单元。
2、接口模块,用于读取配置文件,所述配置文件包括卷积单元配置参数、激活单元配置参数、池化单元配置参数、卷积层的层数及全连接层的层数,具体的,所述接口模块包括处理器接口模块和存储器接口模块。
处理器接口模块,用于实现对FPGA主处理器内部模块的寻址和数据传输,包括对卷积神经网络的输入图像数据的传输,以及对卷积神经网络的配置文件的传输;对配置文件的传输包括:每层的输入Map尺寸、每层的输入Map的数目、每层的输出Map的尺寸、每层的输出Map的数目、权值数据(包括各层的卷积核和各层的偏置数据)、权值数据在DDR存储器中的存放地址、各层的输入/输出Map在DDR存储器中的存放地址。
存储器接口模块,卷积层单元和全连接层单元通过存储器接口模块从存储器中读取卷积神经网络的各层卷积核、各层偏置数据、卷积层各层的输入Map和全连接层各层的输入数据,并将输出Map或输出数据存入存储器。
3、网络解释器模块,用于根据所述卷积单元配置参数配置所述卷积单元、根据所述激活单元配置参数配置所述激活单元、根据所述池化单元配置参数配置所述池化单元,以及配置卷积层的层数和全连接层的层数以构建卷积神经网络。
具体的,所述网络解释器模块接收协处理器传输的卷积神经网络的配置参数,并控制卷积层单元和全连接层单元逐层进行计算。例如,对于第c个卷积层,控制卷积层单元从存储器对应的地址读取第c层计算需要的权值数据(包括卷积核和偏置数据)、激活函数、池化函数和输入Map,然后卷积层单元开始进行卷积、激活和池化操作,最后控制卷积层单元将输出Map存入存储器对应地址。
4、计算模块,用于读取权值数据、偏置数据、激活函数、池化函数及输入图像;并根据所述权值数据、所述偏置数据及所述输入图像进行所述卷积神经网络的计算。
本专利中提到的权值数据包括卷积层的权值数据和全连接层的权值数据,偏置数据包括卷积层的偏置数据及全连接层的偏置数据,激活函数包括卷积层的激活函数和全连接层的激活函数。
具体的,所述计算模块包括卷积层单元和全连接层单元。
其中,所述卷积层单元用于对所述卷积单元、所述激活单元及所述池化单元进行计算,即计算卷积层的输出,包括卷积、偏置、激活函数和池化功能;所述全连接层单元用于计算全连接层,包括矩阵乘法(用于实现全连接层的输入数据与权值数据之间的相乘操作)、偏置和激活函数。
应当注意的是,本专利所述的配置文件用于构建神经网络结构,属于可配参数。所述配置文件包含卷积层的配置数据和全连接层的配置数据,其中,所述卷积层的配置数据包括但不限于卷积核参数、卷积核尺寸、池化函数、池化尺寸、卷积层的激活函数、卷积层的偏置数据、以及卷积层的层数、卷积层的输入Map数量;全连接层的配置数据包括但不限于全连接层的层数以及全连接层的激活函数。
本专利还包括权值文件,所述权值文件为卷积神经网络的计算提供数据,所述权值文件包括全连接层的权值数据和全连接层的偏置数据。当然,所述卷积层的权值数据(例如,卷积核参数也可以看做卷积层的权值数据)和卷积层的偏置数据也可以存储在权值文件中,此时,卷积层的权值数据和卷积层的偏置数据就不作为可配参数存储在所述配置文件中。
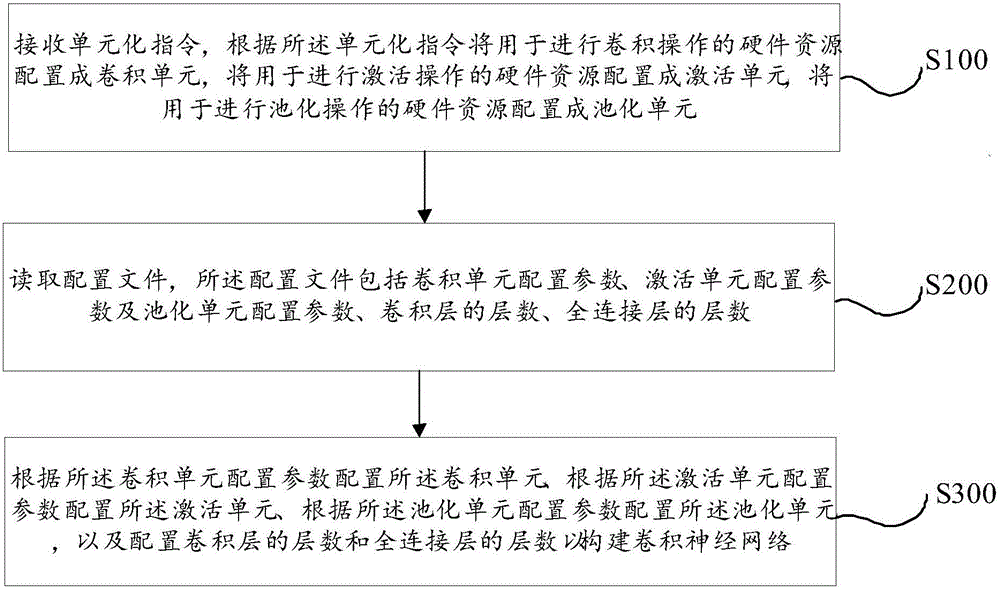
参照图2,提出了本发明卷积神经网络的构建方法第一实施例,该实施例中,卷积神经网络的构建方法包括以下步骤:
步骤S100,接收单元化指令,根据所述单元化指令将用于进行卷积操作的硬件资源配置成卷积单元,将用于进行激活操作的硬件资源配置成激活单元,将用于进行池化操作的硬件资源配置成池化单元;
步骤S200,所述配置文件包括卷积单元配置参数、激活单元配置参数及池化单元配置参数、卷积层的层数、全连接层的层数;
步骤S300,根据所述卷积单元配置参数配置所述卷积单元、根据所述激活单元配置参数配置所述激活单元、根据所述池化单元配置参数配置所述池化单元,以及配置卷积层的层数和全连接层的层数以构建卷积神经网络。
接收到所述单元化指令后,主处理器的硬件资源被配置成C个所述卷积单元、P个所述激活单元及A个所述池化单元,C个所述卷积单元、P个所述激活单元及A个所述池化单元共同形成卷积神经网络的结构参数。不同的卷积单元配置参数、激活单元配置参数及池化单元配置参数构建形成功能不同的卷积神经网络。
如果先将硬件资源按照功能分区形成所述卷积单元、所述激活单元及所述池化单元,那么,在构建卷积神经网络时,只需要相应更改每个单元的配置参数和/或单元的数量即可构建形成新的卷积神经网络结构,从而适配新的卷积神经网络功能,而不需要对整个卷积神经网络进行重建,因此,卷积神经网络的构建效率高,从而非常灵活地支持不同的功能或应用。
在本实施例中,所述配置文件写入存储器中,读取所述配置文件时,协处理器通过处理器接口模块将所述配置文件传送至所述主处理器内的网络解释器,所述网络解释器根据所述配置文件将所述主处理器的硬件资源配置为一个卷积神经网络。
所述卷积单元配置参数包括卷积层的层数、卷积核的参数、卷积核尺寸、Map的尺寸、输入Map数量、输出Map数量;所述激活单元配置参数包括激活函数;所述池化单元配置参数包括池化尺寸和池化函数,当池化函数能够体现或者对应池化尺寸时,可以只配置池化函数。以上各个单元的配置参数不限于此,此处仅对各单元的配置参数进行有限的列举,凡属用于构建卷积神经网络的配置参数均应列入所述配置文件。
因此,需要构建新的卷积神经网络时,只需将新的配置参数在所述配置文件中更新,并加载更新后的所述配置文件,即可实现卷积神经网络的构建。
在本发明的技术方案中,先根据单元化指令将硬件资源配置成所述卷积单元、所述激活单元及所述池化单元,在每次需要构建或构建新的所述卷积神经网络时,只需要读取所述配置文件,即可根据所述配置文件配置所述卷积单元、所述激活单元及所述池化单元、卷积层的层数和全连接层的层数等参数,因此,卷积神经网络的构建方法构建效率高,从而非常灵活地支持不同的功能或应用。
进一步地,参照图3,基于本发明卷积神经网络的构建方法第一实施例,在本发明第二实施例中,上述步骤S300之后还包括:
步骤S400,读取权值数据、偏置数据、激活函数、池化函数及输入图像;
步骤S500,根据所述权值数据、所述偏置数据、所述激活函数、所述池化函数及所述输入图像进行卷积神经网络的计算。
所述权值文件包括所述卷积层的权值数据及所述全连接层的权值数据,卷积层的权值数据是指卷积核的参数;
所述偏置数据和所述激活函数包括卷积层的偏置数据和激活函数,以及全连接层的偏置数据和激活函数;
所述池化函数是指卷积层的池化函数。
具体的,在完成卷积神经网络的构建之后,即可读取所述权值数据、所述偏置数据、所述激活函数、所述池化函数及所述输入图像,以进行所述卷积神经网络的计算,卷积层的计算主要包括卷积运算、偏置运算、激活运算和池化运算,卷积运算根据卷积核的参数完成,全连接层的计算主要包括乘加运算、偏置运算和激活运算。
协处理器通过处理器接口模块(异步总线或同步总线)将所述权值数据、所述偏置数据、所述激活函数及所述池化函数写入主处理器,主处理器通过存储器接口模块将所述权值数据、所述偏置数据、所述激活函数、所述池化函数写入存储器,协处理器通过处理器接口模块(异步总线或同步总线)将输入图像传入主处理器。
主处理器调取存储器中存储的卷积神经网络各层的权值数据等参数和数据,将卷积神经网络的输出数据通过处理器接口模块(异步总线或同步总线)返回给协处理器。
当然,卷积神经网络的各层计算结果也可以根据应用不同分别返回及存储。
需要说明,协处理器与主处理器之间的处理器接口模块不限于通过异步总线或同步总线,也可以根据需要采用其他接口,例如网口等。
进一步地,参照图4和图6,基于本发明卷积神经网络的构建方法第二实施例,在本发明第三实施例中,所述根据所述权值数据、所述偏置数据、激活函数、池化函数及所述输入图像进行所述卷积神经网络的计算包括:步骤S600卷积层计算和步骤S700全连接层计算;
步骤S600,所述卷积层计算包括:
步骤S610,按照预设的并行分组规则将待处理的卷积层输入Map和/或卷积核分组至并行的Tc个卷积层并行处理模块;
步骤S620,每个所述卷积层并行处理模块完成对其组内的卷积层输入Map的卷积、加偏置、激活和池化计算,并存储计算获得的卷积层输出Map;
步骤S700,所述全连接层计算包括:
步骤S710,按照预设的并行分组规则将待处理的全连接层输入数据和/或权值数据分组至并行的Tf个全连接层并行处理模块;
步骤S720,每个所述全连接层并行处理模块完成对其组内的全连接层输入数据的乘加计算,以及乘加计算结果的加偏置和激活计算,并存储计算获得的全连接层输出数据;
其中,Tc、Tf均为大于1的自然数。
具体的,对所述卷积层和所述全连接层按照并形分组规则进行并行分组,有利于加速每一层所述卷积层的计算速率,以提高卷积神经网络的计算速率。分组规则是指如何将计算按照某种规则来并行处理,并行可以按照输入Map来分,或按照卷积核的数量来分,也可以按照输出Map的来分。其中,按照输出Map的数量进行并行分组是最节省计算资源的技术方案,可以节省主处理器与存储器之间读取输入Map的次数,也节省了资源和功耗,提升效率。
在本实施例中,卷积核数量与输出Map数量相同,计算过程是采用一个卷积核对一个输入Map进行卷积计算以得到一个输出Map。
例如,当某一所述卷积层中包括20个所述输出Map时,可以将20个所述输出Map分成并行计算的10个所述卷积层并行处理模块,每一个所述卷积层并行处理模块包括2个所述输出Map。
卷积层的预设的分组规则可以是均匀分组规则或非均匀分组规则,并行计算的每一个所述卷积层并行处理模块包含的所述输入Map数量可以相同,也可以不同。其中,非均匀分组是指,需要并行处理的数据操作(例如,计算输出Map)的数目并不能被并行处理单元的数目整除。若,仍然是20个所述输出Map时,所述卷积层并行处理模块的数目为6,那么可以分别处理4、4、3、3、3、3个输出Map。
在本实施例中,卷积层输入Map数据缓存在双端口RAM1中,卷积层输入Map同时进入Tc个所述卷积层并行处理模块,一个卷积层并行处理模块计算一个卷积核与该输入Map之间的卷积运算,不同卷积层并行处理模块采用的卷积核的参数不同,进而得到Kc个不同的卷积层输出Map数据,并将其通过存储器接口模块存入存储器。将所有的卷积层输出Map分为Tc组,每组包括Kc/Tc个卷积层输出Map,每一个卷积层并行处理模块会串行输出这Kc/Tc个卷积层输出Map。
所述全连接层计算中,输入数据缓存在双端口RAM1中,同时进入Tf个全连接层并行处理模块,得到Kf组输出数据,并将其通过存储器接口模块存入存储器。将所有的输出分为Tf组,每组包括Kf/Tf组输出数据,每一个全连接层并行处理模块会串行输出这Kf/Tf组输出数据。
对每个所述全连接层的分组请参见对每个所述卷积层的分组。
卷积层的预设的分组规则与全连接层的预设的分组规则可以不相同。
进一步地,参照图5,基于本发明卷积神经网络的构建方法第三实施例,在本发明第四实施例中,所述每个所述卷积层并行处理模块完成对其组内的卷积层输入Map的卷积、加偏置、激活和池化计算,并存储计算获得的卷积层输出Map包括:
步骤S621,读取卷积核参数及卷积层输入Map的数据,对所述卷积层输入Map进行若干次卷积操作直至完成所述卷积层输入Map的卷积操作;
步骤S622,将所述卷积层输入Map的卷积操作结果与偏置数据求和,并将求和结果进行激活操作及池化操作,以得到卷积层输出Map;
其中,所述卷积核参数为用于对所述卷积层输入Map进行卷积操作得到卷积层输出Map的卷积核的参数,在第c个卷积层中,卷积层输出Map数量为Kc,Kc为大于1的自然数,每个所述卷积层并行处理模块用于计算Kc/Tc个卷积层输出Map。
具体的,步骤a.通过存储器接口模块从存储器中读取第f组卷积层输入Map对应的偏置数据,将其写入双端口RAM4中;
步骤b.将双端口RAM3清零;
步骤c.通过存储器接口模块从存储器中读取从所有卷积层输入Map到当前卷积层输入Map的卷积核参数,在本实施例中,卷积核的尺寸为3×3,因此对应9个双端口RAM(RAM2-1~RAM2-9);
步骤d.读取第c个输入Map的数据,并从双端口RAM2-1~RAM2-9中读取卷积核参数,通过卷积器完成2D卷积操作。
重复步骤a至步骤d,卷积结果和双端口RAM3的输出相加后存入双端口RAM3,此处加法器和双端口RAM3一起完成累加器的功能;遍历第c个卷积层输入Map之后,将双端口RAM3的输出和从双端口RAM4中读取的对应卷积层输入Map的偏置数据相加,利用查找表计算激活函数的输出值即可得到一个卷积层输出Map的中间过程数据;
将输出Map的中间过程数据存储到双端口RAM5中,当双端口RAM5中的数据存储了2行(在本实施例中,池化尺寸为2)之后,对已经存储的数据进行池化操作(例如,最大值池化);
将最大值池化的结果在双端口RAM6中缓存,得到一个最终的输出Map的数据,然后通过存储器接口模块存储到存储器中。
进一步地,参照图7,基于本发明卷积神经网络的构建方法第三实施例或第四实施例,在本发明第五实施例中,所述步骤S720包括:
步骤S721,计算全连接层输入数据及对应的权值数据的乘积和累加计算;
步骤S722,获取每个所述全连接层输入数据与其对应的所述权值数据的乘积的累加结果,并将所述累加结果与偏置数据求和,对求和结果进行激活操作,以得到全连接层输出数据;
其中,在第f个全连接层中,全连接层输出数据的数量为Kf,Kf为大于1的自然数,每个所述全连接层并行处理模块用于计算Kf/Tf个全连接层输出数据。
具体的,步骤e.通过存储器接口模块从存储器中读取所述第f个全连接层输入数据对应的偏置数据,将其写入双端口RAM3中;
步骤f.通过存储器接口模块从存储器中读取所述第f个输入全连接层Map对应的权值缓存到双端口RAM2中;
步骤g.输入数据和双端口RAM2的数据相乘后送入由加法器和延迟单元组成的累加器。
按照所述计算第f个输入数据的步骤,完成所述全连接层并行处理模块内的所有的所述全连接层输入数据的计算;
其中,每个所述全连接层并行处理模块内包括Kf/Tf个所述输入数据。
将累加器的输出和对应的偏置数据相加之后利用查找表计算激活函数的输出;
重复Kf/Tf次,得到Kf/Tf个全连接层输出数据,这些全连接层输出数据存储在双端口RAM4中;
将双端口RAM4中的数据通过存储器接口模块存储到存储器中。
此外,为实现上述目的,本发明还提供一种卷积神经网络的构建系统。
请参照图1,为了实现卷积神经网络的构建,在本实施例中提供由三个核心器件:ARM协处理器、DDR存储器及FPGA主处理器构建的卷积神经网络的构建系统,其他辅助器件不一一列举。
所述ARM协处理器用于控制卷积层单元和全连接层单元逐层进行计算以及传输配置文件和权值数据(文件);所述DDR存储器用于存储计算数据及配置文件、权值数据及偏置数据等。
所述主处理器FPGA包括:
1、单元化模块,用于接收单元化指令,以将用于进行卷积操作的硬件资源配置成卷积单元,用于进行激活操作的硬件资源配置成激活单元,用于进行池化操作的硬件资源配置成池化单元。
2、接口模块,用于读取配置文件,所述配置文件包括卷积单元配置参数、激活单元配置参数、池化单元配置参数、卷积层的层数及全连接层的层数,具体的,所述接口模块包括处理器接口模块和存储器接口模块。
处理器接口模块,用于实现对FPGA主处理器内部模块的寻址和数据传输,包括对卷积神经网络的输入图像数据的传输,以及对卷积神经网络的配置文件的传输;对配置文件的传输包括:每层的输入Map尺寸、每层的输入Map的数目、每层的输出Map的尺寸、每层的输出Map的数目、权值数据(包括各层的卷积核和各层的偏置数据)、权值数据在DDR存储器中的存放地址、各层的输入/输出Map在DDR存储器中的存放地址。
存储器接口模块,卷积层单元和全连接层单元通过存储器接口模块从存储器中读取卷积神经网络的各层卷积核、各层偏置数据、卷积层各层的输入Map和全连接层各层的输入数据,并将输出Map或输出数据存入存储器。
3、网络解释器模块,用于根据所述卷积单元配置参数配置所述卷积单元、根据所述激活单元配置参数配置所述激活单元、根据所述池化单元配置参数配置所述池化单元,以及配置卷积层的层数和全连接层的层数以构建卷积神经网络。
具体的,所述网络解释器模块接收协处理器传输的卷积神经网络的配置参数,并控制卷积层单元和全连接层单元逐层进行计算。例如,对于第c个卷积层,控制卷积层单元从存储器对应的地址读取第c层计算需要的权值数据(包括卷积核和偏置数据)、激活函数、池化函数和输入Map,然后卷积层单元开始进行卷积、激活和池化操作,最后控制卷积层单元将输出Map存入存储器对应地址。
4、计算模块,用于读取权值数据、偏置数据、激活函数、池化函数及输入图像;并根据所述权值数据、所述偏置数据及所述输入图像进行所述卷积神经网络的计算。
本专利中提到的权值数据包括卷积层的权值数据和全连接层的权值数据,偏置数据包括卷积层的偏置数据及全连接层的偏置数据,激活函数包括卷积层的激活函数和全连接层的激活函数。
具体的,所述计算模块包括卷积层单元和全连接层单元。
其中,所述卷积层单元用于对所述卷积单元、所述激活单元及所述池化单元进行计算,即计算卷积层的输出,包括卷积、偏置、激活函数和池化功能;所述全连接层单元用于计算全连接层,包括矩阵乘法(用于实现全连接层的输入数据与权值数据之间的相乘操作)、偏置和激活函数。
应当注意的是,本专利所述的配置文件用于构建神经网络结构,属于可配参数。所述配置文件包含卷积层的配置数据和全连接层的配置数据,其中,所述卷积层的配置数据包括但不限于卷积核参数、卷积核尺寸、池化函数、池化尺寸、卷积层的激活函数、卷积层的偏置数据、以及卷积层的层数、卷积层的输入Map数量;全连接层的配置数据包括但不限于全连接层的层数以及全连接层的激活函数。
本专利还包括权值文件,所述权值文件为卷积神经网络的计算提供数据,所述权值文件包括全连接层的权值数据和全连接层的偏置数据。当然,所述卷积层的权值数据(例如,卷积核参数也可以看做卷积层的权值数据)和卷积层的偏置数据也可以存储在权值文件中,此时,卷积层的权值数据和卷积层的偏置数据就不作为可配参数存储在所述配置文件中。
参照图8,提出了本发明卷积神经网络的构建系统第一实施例,该实施例中,本发明提供的卷积神经网络的构建系统包括:
单元化模块1,用于接收单元化指令,根据所述单元化指令将用于进行卷积操作的硬件资源配置成卷积单元,将用于进行激活操作的硬件资源配置成激活单元,将用于进行池化操作的硬件资源配置成池化单元;
接口模块2,用于读取配置文件,所述配置文件包括卷积单元配置参数、激活单元配置参数及池化单元配置参数、卷积层的层数、全连接层的层数;
网络解释器模块3,用于根据所述卷积单元配置参数配置所述卷积单元、根据所述激活单元配置参数配置所述激活单元、根据所述池化单元配置参数配置所述池化单元,以及配置卷积层的层数和全连接层的层数以构建卷积神经网络。
接收到所述单元化指令后,主处理器的硬件资源被配置成C个所述卷积单元、P个所述激活单元及A个所述池化单元,C个所述卷积单元、P个所述激活单元及A个所述池化单元共同形成卷积神经网络的结构参数。不同的卷积单元配置参数、激活单元配置参数及池化单元配置参数构建形成功能不同的卷积神经网络。
如果先将硬件资源按照功能分区形成所述卷积单元、所述激活单元及所述池化单元,那么,在构建卷积神经网络时,只需要相应更改每个单元的配置参数和/或单元的数量即可构建形成新的卷积神经网络结构,从而适配新的卷积神经网络功能,而不需要对整个卷积神经网络进行重建,因此,卷积神经网络的构建效率高,从而非常灵活地支持不同的功能或应用。
在本实施例中,所述配置文件写入存储器中,读取所述配置文件时,协处理器通过处理器接口模块将所述配置文件传送至所述主处理器内的网络解释器,所述网络解释器根据所述配置文件将所述主处理器的硬件资源配置为一个卷积神经网络。
所述卷积单元配置参数包括卷积层的层数、卷积核的参数、卷积核尺寸、Map的尺寸、输入Map数量、输出Map数量;所述激活单元配置参数包括激活函数;所述池化单元配置参数包括池化尺寸和池化函数,当池化函数能够体现或者对应池化尺寸时,可以只配置池化函数。以上各个单元的配置参数不限于此,此处仅对各单元的配置参数进行有限的列举,凡属用于构建卷积神经网络的配置参数均应列入所述配置文件。
因此,需要构建新的卷积神经网络时,只需将新的配置参数在所述配置文件中更新,并加载更新后的所述配置文件,即可实现卷积神经网络的构建。
在本发明的技术方案中,先根据单元化指令将硬件资源配置成所述卷积单元、所述激活单元及所述池化单元,在每次需要构建或构建新的所述卷积神经网络时,只需要读取所述配置文件,即可根据所述配置文件配置所述卷积单元、所述激活单元及所述池化单元、卷积层的层数和全连接层的层数等参数,因此,卷积神经网络的构建方法构建效率高,从而非常灵活地支持不同的功能或应用。
进一步地,基于本发明卷积神经网络的构建系统第一实施例,在本发明第二实施例中,所述卷积神经网络的构建系统还包括:
计算模块,用于读取权值数据、偏置数据、激活函数、池化函数及输入图像;并根据所述权值数据、所述偏置数据、所述激活函数、所述池化函数及所述输入图像进行所述卷积神经网络的计算。
所述权值文件包括所述卷积层的权值数据及所述全连接层的权值数据,卷积层的权值数据是指卷积核的参数;
所述偏置数据和所述激活函数包括卷积层的偏置数据和激活函数,以及全连接层的偏置数据和激活函数;
所述池化函数是指卷积层的池化函数。
具体的,在完成卷积神经网络的构建之后,即可读取所述权值数据、所述偏置数据、所述激活函数、所述池化函数及所述输入图像,以进行所述卷积神经网络的计算,卷积层的计算主要包括卷积运算、偏置运算、激活运算和池化运算,卷积运算根据卷积核的参数完成,全连接层的计算主要包括乘加运算、偏置运算和激活运算。
协处理器通过处理器接口模块(异步总线或同步总线)将所述权值数据、所述偏置数据、所述激活函数及所述池化函数写入主处理器,主处理器通过存储器接口模块将所述权值数据、所述偏置数据、所述激活函数、所述池化函数写入存储器,协处理器通过处理器接口模块(异步总线或同步总线)将输入图像传入主处理器。
主处理器调取存储器中存储的卷积神经网络各层的权值数据等参数和数据,将卷积神经网络的输出数据通过处理器接口模块(异步总线或同步总线)返回给协处理器。
当然,卷积神经网络的各层计算结果也可以根据应用不同分别返回及存储。
需要说明,协处理器与主处理器之间的处理器接口模块不限于通过异步总线或同步总线,也可以根据需要采用其他接口,例如网口等。
进一步地,基于本发明卷积神经网络的构建系统第二实施例,在本发明第三实施例中,所述计算模块包括用于卷积层计算的卷积层单元和用于全连接层计算的全连接层单元;
所述卷积层单元具体用于,按照预设的并行分组规则将待处理的卷积层的输入Map和/或卷积核分组至并行的Tc个卷积层并行处理模块;每个所述卷积层并行处理模块完成对其组内的卷积层输入Map的卷积、加偏置、激活和池化计算,并存储计算获得的卷积层输出Map;
所述全连接层单元具体用于,按照预设的并行分组规则将待处理的全连接层输入数据和/或权值数据分组至并行的Tf个全连接层并行处理模块;
每个所述全连接层并行处理模块完成对其组内的全连接层输入数据的乘加计算,以及乘加计算结果的加偏置和激活计算,并存储计算获得的全连接层输出数据;
其中,Tc、Tf均为大于1的自然数。
具体的,对所述卷积层和所述全连接层按照并形分组规则进行并行分组,有利于加速每一层所述卷积层的计算速率,以提高卷积神经网络的计算速率。分组规则是指如何将计算按照某种规则来并行处理,并行可以按照输入Map来分,或按照卷积核的数量来分,也可以按照输出Map的来分。其中,按照输出Map的数量进行并行分组是最节省计算资源的技术方案,可以节省主处理器与存储器之间读取输入Map的次数,也节省了资源和功耗,提升效率。
在本实施例中,卷积核数量与输出Map数量相同,计算过程是采用一个卷积核对一个输入Map进行卷积计算以得到一个输出Map。
例如,当某一所述卷积层中包括20个所述输出Map时,可以将20个所述输出Map分成并行计算的10个所述卷积层并行处理模块,每一个所述卷积层并行处理模块包括2个所述输出Map。
卷积层的预设的分组规则可以是均匀分组规则或非均匀分组规则,并行计算的每一个所述卷积层并行处理模块包含的所述输入Map数量可以相同,也可以不同。其中,非均匀分组是指,需要并行处理的数据操作(例如,计算输出Map)的数目并不能被并行处理单元的数目整除。若,仍然是20个所述输出Map时,所述卷积层并行处理模块的数目为6,那么可以分别处理4、4、3、3、3、3个输出Map。
在本实施例中,卷积层输入Map数据缓存在双端口RAM1中,卷积层输入Map同时进入Tc个所述卷积层并行处理模块,一个卷积层并行处理模块计算一个卷积核与该输入Map之间的卷积运算,不同卷积层并行处理模块采用的卷积核的参数不同,进而得到Kc个不同的卷积层输出Map数据,并将其通过存储器接口模块存入存储器。将所有的卷积层输出Map分为Tc组,每组包括Kc/Tc个卷积层输出Map,每一个卷积层并行处理模块会串行输出这Kc/Tc个卷积层输出Map。
所述全连接层计算中,输入数据缓存在双端口RAM1中,同时进入Tf个全连接层并行处理模块,得到Kf组输出数据,并将其通过存储器接口模块存入存储器。将所有的输出分为Tf组,每组包括Kf/Tf组输出数据,每一个全连接层并行处理模块会串行输出这Kf/Tf组输出数据。
对每个所述全连接层的分组请参见对每个所述卷积层的分组。
卷积层的预设的分组规则与全连接层的预设的分组规则可以不相同。
进一步地,基于本发明卷积神经网络的构建系统第三实施例,在本发明第四实施例中,所述卷积层单元包括:
第一处理子单元,用于读取卷积核参数及卷积层输入Map的数据,对所述卷积层输入Map进行若干次卷积操作直至完成所述卷积层输入Map的卷积操作;
第二处理子单元,用于将所述卷积层输入Map的卷积操作结果与偏置数据求和,并将求和结果进行激活操作及池化操作,以得到卷积层输出Map;
其中,所述卷积核参数为用于对所述卷积层输入Map进行卷积操作得到卷积层输出Map的卷积核的参数,在第c个卷积层中,卷积层输出Map数量为Kc,Kc为大于1的自然数,每个所述卷积层并行处理模块用于计算Kc/Tc个卷积层输出Map。
具体的,步骤a.通过存储器接口模块从存储器中读取第f组卷积层输入Map对应的偏置数据,将其写入双端口RAM4中;
步骤b.将双端口RAM3清零;
步骤c.通过存储器接口模块从存储器中读取从所有卷积层输入Map到当前卷积层输入Map的卷积核参数,在本实施例中,卷积核的尺寸为3×3,因此对应9个双端口RAM(RAM2-1~RAM2-9);
步骤d.读取第c个输入Map的数据,并从双端口RAM2-1~RAM2-9中读取卷积核参数,通过卷积器完成2D卷积操作。
重复步骤a至步骤d,卷积结果和双端口RAM3的输出相加后存入双端口RAM3,此处加法器和双端口RAM3一起完成累加器的功能;遍历第c个卷积层输入Map之后,将双端口RAM3的输出和从双端口RAM4中读取的对应卷积层输入Map的偏置数据相加,利用查找表计算激活函数的输出值即可得到一个卷积层输出Map的中间过程数据;
将输出Map的中间过程数据存储到双端口RAM5中,当双端口RAM5中的数据存储了2行(在本实施例中,池化尺寸为2)之后,对已经存储的数据进行池化操作(例如,最大值池化);
将最大值池化的结果在双端口RAM6中缓存,得到一个最终的输出Map的数据,然后通过存储器接口模块存储到存储器中。
进一步地,基于本发明卷积神经网络的构建系统第三实施例或第四实施例,在本发明第五实施例中,所述全连接层单元包括:
第三处理子单元,用于计算全连接层输入数据及对应的权值数据的乘积;
第四处理子单元,用于获取每个所述全连接层输入数据与其对应的所述权值数据的乘积的累加结果,并将所述累加结果与偏置数据求和,对求和结果进行激活操作,以得到全连接层输出数据;
其中,在第f个全连接层中,全连接层输出数据的数量为Kf,Kf为大于1的自然数,每个所述全连接层并行处理模块用于计算Kf/Tf个全连接层输出数据。
具体的,步骤e.通过存储器接口模块从存储器中读取所述第f个全连接层输入数据对应的偏置数据,将其写入双端口RAM3中;
步骤f.通过存储器接口模块从存储器中读取所述第f个输入全连接层Map对应的权值缓存到双端口RAM2中;
步骤g.输入数据和双端口RAM2的数据相乘后送入由加法器和延迟单元组成的累加器。
按照所述计算第f个输入数据的步骤,完成所述全连接层并行处理模块内的所有的所述全连接层输入数据的计算;
其中,每个所述全连接层并行处理模块内包括Kf/Tf个所述输入数据。
将累加器的输出和对应的偏置数据相加之后利用查找表计算激活函数的输出;
重复Kf/Tf次,得到Kf/Tf个全连接层输出数据,这些全连接层输出数据存储在双端口RAM4中;
将双端口RAM4中的数据通过存储器接口模块存储到存储器中。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!