一种基于卷积神经网络的单目标跟踪方法与流程
本发明涉及深度学习、目标跟踪、目标检测、图像预处理、特征表达等技术,属于计算机视觉跟踪技术领域。
背景技术:
视觉跟踪任务是计算机视觉领域中一个非常基础且重要的问题,受到越来越多的科研工作者的关注。视觉跟踪任务的要求是对于给定的一段视频片段,给出要跟踪对象在视频第一帧中的位置坐标,然后要求在随后的视频序列中能够自动的识别出要跟踪的目标对象,并将其在视频中的位置标出(用一个框框住目标)。由于要跟踪的目标对象的外观受到运动突变、形变、遮挡、光照变化等因素带来的影响,使得视觉跟踪任务依然是一个很具有挑战性的问题。之前的一些方法大多是利用手工提取的特征来描述目标对象,这在一定程度上解决了一些视觉跟踪的问题。但是由于这些手工特征是针对特定的问题而设计的,不能够很好的提取到目标对象的高层的语义信息,导致了它的泛化性能很差,而这往往会导致跟踪效果不理想甚至跟踪失败。因此,亟需一种高效的、泛化性能好的跟踪器来解决这些问题。
随着近年来机器学习、深度学习技术的不断发展,深度学习技术应用到越来越多的计算机视觉任务中。其中卷积神经网络(Convolution Neural Network,CNN)应用的最为广泛,CNN广泛应用在图像分类、图像识别、图像分割和目标检测等计算机视觉领域,取得了不错的效果。CNN所表现出来的出色的性能归功于它对视觉任务数据的强大的表达和描述能力。CNN的分层结构,使得它能够从原始的数据中学习到目标的不同层次的特征表达,靠近底层提取到的是目标的一些结构化的信息,而高层提取到的是目标的一些语义信息。这些经过CNN提取到的特征相对于之前人们手工设计的特征具有更好的鲁棒性,使得在处理计算机视觉任务上表现出较好的性能。
传统的目标跟踪算法是基于产生式和判别式的方式。产生式的方式利用一个生成模型来描述目标的外观,然后搜索候选区域中和当前目标最相似的目标。判别式的方法是建立一个区分目标和背景的模型,它的目的是将目标从背景中有效的区分开来。而在这两种方法中通常使用的特征都是一些手工提取的特征,这些低层的手工特征往往对于光照变化、遮挡、形变等动态情景是十分的不鲁棒的。
技术实现要素:
对于单目标跟踪来说,首先要知道跟踪的目标对象是什么,有哪些特点,然后在随后的视频中找到与之对应的目标对象。早期的基于手工特征的判别式模型只能够提取到目标对象的一些浅层的特征,并不能够很好的描述目标对象的本质。而卷积神经网络通过一个分层的结构,可以学习到目标对象不同层次的特征表达。底层能够学习到目标对象的一些结构特征,而高层则可以学习到目标对象的一些语义信息,而这些信息能够很好的描述目标对象。本发明的目的在于利用CNN强大的特征提取能力,提取到更加鲁棒的特征,使得能够更好的描述要跟踪的目标对象,然后使用一个判别式的模型,从视频序列中把要跟踪的目标找出来并标记目标的坐标位置,从而提高模型对于动态情景的鲁棒性。
本发明采用的技术方案为一种基于卷积神经网络的单目标跟踪方法。构建并训练网络模型;微调网络模型;提取候选区域块并计算跟踪结果;后处理优化跟踪结果;更新网络模型。
根据上述主要思路,本方法的具体实施包括以下几个步骤:
(一)构建并训练网络模型;
步骤一:准备训练数据集,本方法中使用的数据集包括Object Tracking Benchmark(OTB)数据集和Visual Object Tracking(VOT)数据集;
步骤二:准备预训练好的卷积神经网络模型,构建卷积神经网络模型并利用预训练的模型参数来初始化新构建的卷积神经网络的模型的初始参数;
步骤三:训练网络模型。网络模型参数初始化完毕之后,利用训练数据集训练整个网络模型,直到网络收敛;
(二)微调网络模型并训练Bounding Box回归模型;
步骤四:跟踪测试时,首先根据视频第一帧图像中的ground-truth提取正、负样本,将正、负样本输入网络中,微调网络模型参数,使其适应当前跟踪的视频序列;
步骤五:利用提取到的正样本的卷积层特征训练一个针对当前目标的Bounding Box回归模型,该Bounding Box回归模型用于对跟踪结果的精确化处理;
(三)提取候选区域块并计算跟踪结果;
步骤六:根据前一帧目标所处位置的坐标信息,以其坐标位置为中心,根据高斯分布模型在其周围提取适量的目标对象候选块;
步骤七:将提取到的目标对象候选块依次输入网络模型中,分别计算每一个候选块的得分,选取得分高于预先设定阈值的候选块作为最终的跟踪结果,即当前目标所在的位置;
(四)后处理优化跟踪结果;
步骤八:利用步骤五中训练好的Bounding Box回归模型对跟踪结果进行回归操作,得到目标更加精确的位置;
步骤九:根据当前跟踪的结果,根据高斯分布模型收集一定数量的正、负样本数据,收集到的正、负样本数据用来更新网络模型;
(五)更新网络模型;
步骤十:利用收集到的正、负样本数据适时、适当地更新网络模型参数,使其能够持久的保持良好的跟踪性能。
与现有技术相比,本发明具有如下优点:
本发明方法应用CNN来提取目标对象的特征,使得能够更好的表达目标,提高了目标表述的鲁棒性。在网络结构上,因为pooling操作的使用,会使物体丢失一些结构上的信息,本发明将原有的pooling层的大小变得更小(kernel size 2x2),这样能够提高目标定位的精度。同时,本发明在跟踪框架的基础上添加了一个用于检测目标的模块,在跟踪失败的时候,利用该模块在当前帧上对目标进行重检测,提高了跟踪器对于遮挡等动态情景的鲁棒性,从而提高了跟踪的准确率。
附图说明
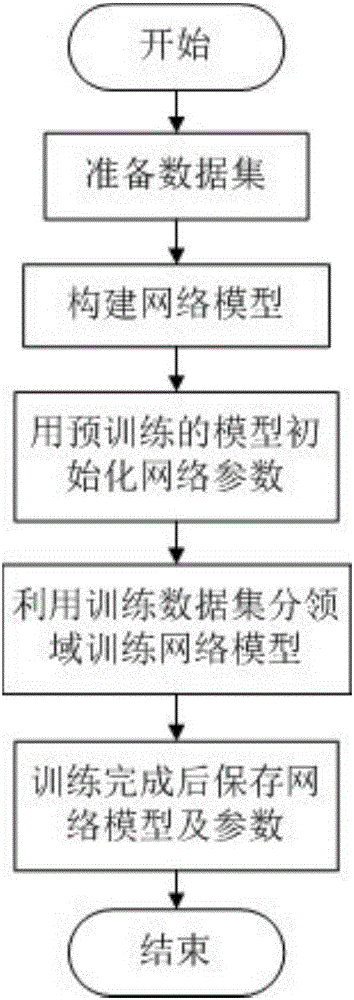
图1是本发明所涉及的方法的整体流程示意图;
图2是训练阶段的流程图
图3是测试阶段的流程图
图4是网络模型的整体框架图
具体实施方式
下面结合具体实施方式对本发明做进一步的说明。
(一)构建并训练网络模型
本方法是预先利用标注的数据集在线下预训练一个网络模型,该网络模型的作用是将每一个输入网络的候选区域进行特征提取、匹配,计算出每一个候选区域的得分,从而判别出输入的候选区域哪些是目标对象、哪些不是目标对象。然后在实际跟踪测试的时候,首先利用当前跟踪的视频信息在线微调网络,使其达到能够很好的适应跟踪当前目标的效果。
步骤一,首先准备线下预训练网络模型时要使用的数据集,本方法的测试数据集是OTB50数据集,训练数据集是VOT数据集。OTB是一个标准的跟踪基准数据集,它包含50个全部标注的视频序列,视频的长度在几百帧到上千帧之间,这些视频拍摄于不同的场景,内容相差较大。VOT数据集是一个视觉挑战赛使用的数据集,一共包含58个和OTB50中不同的视频序列。这些视频序列有光照变化、遮挡、形变、分辨率、运动模糊、快速移动、背景干扰等不同干扰因素。
步骤二,准备好训练数据集之后,需要构建网络模型。本方法使用的网络模型结构如图2所示,它是一个含有三个卷积层和三个全连接层的卷积神经网络,卷积神经网络各层的参数设置如表1中所示。首先利用在ImageNet分类数据集上预训练好的网络模型参数对新构建的网络模型进行参数初始化,这样做节省网络训练的时间,从而达到快速收敛的效果。
表1
步骤三,初始化网络模型参数后,利用标注好的VOT数据集对网络进行训练。在每一帧中收集50个正样本数据和200个负样本数据,这些样本数据的提取规则是,当提取的块跟Ground-truth的重合率大于0.7的时候,认为是正样本数据,当提取的块跟Ground-truth的重合率小于0.5的时候,认为是负样本数据。
此训练过程是一个分领域的分步训练,将每一段视频序列看作是一个独立的领域,用其单独训练一个分类器,之后对于每一段输入的训练视频,首先重新初始化倒数第二层和最后一层的网络连接参数,即重新初始化一个分类节点,然后训练这个对应的分类器,使其能够正确的区分当前视频序列中的目标和背景。当输入的图片中是目标对象时,网络的输出为1,当输入的图片为背景时,网络的输出为0。所有视频序列一次训练完成算作是一个大的迭代完成。然后重复迭代训练,直到网络收敛,本发明的实验中迭代训练100次后网络收敛。
训练完成后,将网络最后一层的所有分领域的分类节点去掉,并重新初始化一个新的二分类节点,同时重新初始化其与前一层的连接参数,保存好训练的网络模型。
(二)微调网络模型并训练Bounding Box回归模型
步骤四,测试时,首先加载训练好的模型,然后根据要跟踪的视频第一帧中给出的目标对象的Ground-truth的位置坐标,利用一个高斯分布模型以该位置坐标为中心,在其周围提取一些正、负训练样本数据集。微调网络时,在第一帧图像上分别收集500个正样本和5000个负样本进行微调网络操作,这些样本的提取规则是,当提取的块跟Ground-truth的重合率大于0.7的时候,则认为是正样本数据,当提取的块跟Ground-truth的重合率小于0.3的时候,则认为是负样本。
测试阶段微调网络参数时,将这些训练样本数据集依次输入网络中,固定网络模型的卷积层参数不动,只对网络的后面三个全连接层的参数进行微调训练。这个微调训练的目的是使该网络模型能够更好的适应当前跟踪的视频序列,即能够很好的区分当前视频序列中的目标和背景。同时在网络的最后接一个检测模块,在跟踪出现错误或者目标跟踪丢失的时候,利用该检测模块对当前帧进行目标重检测,重新检测到目标,然后对目标位置进行重新初始化,进而进行准确、长时间的跟踪。这个检测模块是基于RPN网络模型在当前帧上提取候选块,然后将这些候选块重新输入网络模型进行特征提取、匹配,判别出属于目标对象的候选块,然后使用这个检测到的目标候选块重新初始化目标的位置,将这个目标的位置当做下一帧提取候选块的中心位置,进行候选块的提取。
步骤五,网络微调训练完毕后,再利用高斯分布模型在Ground-truth的目标周围采取一些正样本,本方法中使用1000个训练样本,然后将这些正样本依次输入网络,提取这些正样本的最后一个卷积层的特征,利用这些卷积层的特征训练一个Bounding Box回归模型。对一帧视频跟踪完成后,利用预训练的Bounding Box回归模型对跟踪的结果进行更加精细的调优,使跟踪框能够更加紧致的框住目标对象,从而使跟踪结果更加精确。
(三)提取候选区域块并计算跟踪结果
步骤六,根据前一帧跟踪的结果,以前一帧视频的跟踪结果的坐标位置为中心,利用高斯分布模型进行候选块采样,提取一定数量的目标候选块。本方法中对于每一帧提取256个候选块。由于视频相邻帧中的目标对象的位置变化相对来说很小,所以,该采样的结果基本能够涵盖目标对象的可能出现的位置,即采样的候选块中包含下一帧目标出现的位置。
步骤七,将上述采样得到的目标候选块依次输入网络中,计算得到每一个候选块对应的输出得分,然后将这些候选块的得分按照降序的顺序排列,选取得分最高的目标候选块,并将该目标候选块的得分和预先设置的阈值进行比较,如果该得分大于预先设置的阈值0.5,则认为目标跟踪正确,将对应的目标候选块的位置坐标保存在跟踪结果中;否则,则认为目标跟踪失败,此时利用检测模块对该帧图像进行目标重检测,利用RPN网络模型在整个图像范围内生成目标候选块,将提取的目标候选块依次输入原网络模型中进行得分计算,并进行得分比较,从而得到跟踪的结果。
(四)后处理跟踪结果
步骤八,对于步骤七中得到的跟踪结果,对于能够正确跟踪的结果,利用步骤五中预训练的Bounding Box回归模型对其进行回归操作,使得目标对象候选块的框能够更加紧致的框住目标对象,从而使得跟踪的结果能够更加精确的趋近于Ground-truth,达到精确定位跟踪目标的目的。当跟踪的结果不正确时,即跟踪结果的得分小于阈值,则不再使用Bounding Box回归模型对跟踪结果进行回归操作。
步骤九,确定成功的跟踪结果之后,然后以该目标的位置坐标为中心,利用高斯分布模型在其周围提取一定数量的正样本和一定数量的负样本,本方法中第一帧收集的样本数量分别为正样本500个,负样本5000个。其余帧中收集的样本数量分别为正样本50个,负样本200个。并将它们分别加入正、负样本训练集中,该数据集用于对网络模型的更新训练。
(五)更新网络模型
步骤十,更新模型分为两种更新的方式,一种是定期更新模式,一种是随时更新模式。定期更新模式是设定一个规定的时间间隔(例如每间隔10帧),利用收集到的正、负样本数据微调网络模型,微调网络时只更新网络结构的后面三个全连接层的权值参数,卷积层的权值参数固定不动。在本发明中,定期更新的时间间隔是10帧,即每个十帧更新一次网络参数,用到的数据集为距离当前时刻100帧以内所收集的样本数据。
随时更新模式是当跟踪器跟踪目标失败的时候,就立即利用训练数据集更新网络模型,更新的方式也是只更新网络结构的后面三个全连接层的权值参数,卷积层的权值参数固定不变。通过网络模型的更新操作,使其能够更好的适应当前跟踪的视频序列的变化,从而达到更加鲁棒的跟踪效果。在本方法中,随时更新用到的数据集为距离当前时刻20帧以内所收集的样本数据。
- 还没有人留言评论。精彩留言会获得点赞!