一种基于堆叠Bi-LSTM网络和协同注意力的虚拟学习环境智能问答方法与流程
本发明属于自然语言处理和虚拟现实技术领域,涉及一种基于堆叠bi-lstm网络和协同注意力的虚拟学习环境智能问答方法。
背景技术:
近年来深度学习在自然语言处理(nlp)中的地位举足轻重,nlp的所有任务,诸如信息检索、智能问答、机器翻译、对话系统和语音操控等,其核心都可归结为对自然语言的理解与应用。相较于传统方法,深度学习可自动根据原始数据学习特征,从大量的样本中自动提取出词语之间的关系,并且它能够结合短语匹配中的结构信息和文本匹配的层次化特性,通过学习过程提取出不同水平和维度的有效表示,进一步提高不同抽象层次上的数据解释能力。
在特定领域的智能问答研究中,知识库中的语句特征提取与特征表示一直是其中难点。当前文献中已提出许多有效的基于深度学习的自然语句理解模型来解决该问题,其中有采用卷积神经网络(cnn)和长短时记忆网络(lstm)对句子建模的例子。卷积神经网络的卷积核结构具有平移不变性,可对局部化信息建模,而堆叠起来的卷积层可以便捷地体现语言层次化的特性。长短时记忆网络是处理自然语句的最佳手段,因为其内部单元三个“门”的构造存在,使得它能够很好地表达句子长距离的依存关系和复杂语义。诸如层次化建模匹配的深度cnn、cnn与lstm网络结合、双向lstm网络、融合注意力(attention)机制的bi-lstm网络等等,这些模型都在语句特征提取上取得了良好的实验效果。然而这些模型目前都存在着相应的短板,主要体现在以下方面:其一是现有的基于深度神经网络的模型都欠缺对问题和答案之间相互作用与影响的思考,尤其是答案语句对问题语句特征提取及生成的影响方面;其二是多数模型都将重心放在了特征提取与表示上面,忽视了最后的问答对向量匹配计算也是提升模型准确率的关键一步;其三是现有的多数网络模型都采用开放域的问答数据集进行训练学习,缺乏针对特定领域数据集的构建及使用,实际应用价值不大。
综上所述,虽然基于深度学习架构的智能问答模型在自然语言处理领域取得了一定程度的研究进展,但如何面向特定领域合理地架构深度神经网络实现问答对向量特征的有效提取;如何在神经网络的基础之上加入相关机制多角度地考虑问答对向量生成的影响因素;如何从字词嵌入、匹配度计算等其他方面着手改善模型效果;如何拓展智能问答模型的应用范围等都是呈现更智能、更实用的问答模型需要继续深究和实践的课题。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于堆叠bi-lstm网络和协同注意力的虚拟学习环境智能问答方法,解决问答对更深层次的交互理解与表示,同时引入特定域虚拟课堂来拓宽了智能问答的应用范围。
为达到上述目的,本发明提供如下技术方案:
一种基于堆叠bi-lstm网络和协同注意力的虚拟学习环境智能问答方法,该方法具体包括以下步骤:
s1:特定领域教学知识库的构建及数据预处理:采集并构建特定领域教学知识库;训练word2vec模型,使其学习到相关的知识结构和语法语义认知关系,将训练好的word2vec模型作为词嵌入层获取问题和答案语句的词向量表示;
s2:特征提取及向量表示:采用堆叠bi-lstm网络搭建并训练语句特征提取模型,在堆叠bi-lstm网络的输出后加入co-attention机制与attention机制,其中co-attention机制的关联矩阵用于捕获问答对向量之间的关联性,soft-max函数用于生成问答对隐层状态的注意力权重,attention机制用于进一步减少前两个单元特征提取过程中的重要信息丢失,遍历上述三个单元,得到问答对的最终向量表示;
s3:向量匹配度计算:余弦相似度是用向量空间中两个向量夹角的余弦值衡量两个个体间差异的大小,计算向量的值在[-1,1]区间,而欧氏距离是对空间各点的绝对距离进行衡量,与每个点所在的位置坐标直接相关,计算向量的值在[0,1]区间;从空间和位置的双重角度同时考虑,对余弦相似度与欧几里德距离进行函数调和,计算问答对向量间的匹配度;
s4:虚拟课堂应用:利用基于unity3d平台搭建虚拟学习环境并配置相应虚拟角色脚本程序,将训练好的特定域知识库教学问答系统通过unityapi接口引入虚拟学习环境,实现虚拟课堂中智能问答的可视化应用。
进一步,所述步骤s1中,所述特定领域教学知识库的构建及数据预处理具体包括:构建特定领域教学知识库并训练浅层神经网络word2vec模型,计算语句的词序列条件概率,把一个维数为所有词的数量的高维空间嵌入到一个低维的连续向量空间,其中每个单词或词组被映射为实数域上的向量。
进一步,所述步骤s2中,为实现问答对更深层次的交互理解与表示,在构建堆叠bi-lstm网络的模型中配置co-attention机制与attention机制,具体包括以下步骤:
s21:堆叠bi-lstm即双层双向长短时记忆网络,其运算传递过程为:将问答对向量序列分别输入单元lstm网络,得到的ht输入双向lstm网络,输出
s22:co-attention机制衔接堆叠bi-lstm网络,其核心组成为两部分,关联矩阵与soft-max函数;关联矩阵l=hathq∈rm*n用于捕捉问答对向量间的关联性,soft-max函数用于分配并生成问答对隐层状态的注意力权重aq=softmax(l)∈rm*n和
aa=softmax(lt)∈rn*m;
s23:attention机制首先采用maxpooling固定问答对输出的大小,再经过soft-max函数减少堆叠bi-lstm网络与co-attention机制特征提取过程中重要信息的丢失,最后得到问答对特征向量表示oq和oa。
进一步,所述步骤s3具体包括以下步骤:
s31:将余弦相似度与欧几里德距离进行结合,计算问答对特征向量oq和oa匹配度的调和函数公式为:
其中,
s32:采用hinge损失函数对模型进行训练优化,该函数同时输入答案的正负样本,其训练目标函数为:
l=max{0,m-socre(oq,oa+)+socre(oq,oa-)}+λ||θ||
其中,m为固定余量,λ,θ分别为正则化参数和神经网络参数;在训练过程中,采用反向传播算法计算梯度
s33:选用平均准确率map与平均召回率mrr作为模型的评价指标,map和mrr的值越高系统性能越好。
进一步,所述步骤s4具体包括以下步骤:
s41:结合特定的教学场景,利用虚拟现实技术在unity3d平台中搭建虚拟学习环境,创建虚拟课堂并配置虚拟教师等角色模型,模拟现实教学授课场景;
s42:通过unityapi应用程序接口将已训练好的特定域知识库问答系统导入到虚拟学习环境中,实现面向虚拟学习环境的智能教学问答,实时为学生进行问题答疑。
本发明的有益效果在于:
(1)本发明经由word2vec模型产生的问答对向量可在堆叠的bi-lstm网络实现有效的特征提取与编码表示,该模型不仅可以区分并提取上下文关键局部信息,同时能解决语句序列过长无法捕捉词语间依赖性的问题。
(2)与现有的基于智能问答的深度神经网络模型相比,本发明co-attention机制的加入使问答对矩阵的参数进行了共享,该机制可以有效捕获问答对语句之间互相产生的影响与关联性。attention机制的衔接则可以进一步弥补模型特征提取过程中重要信息的丢失,为模型呈现更具代表性的语句特征表示。两种注意力机制的联合进一步提高了在特定域教学知识库中的平均准确率(map)与平均召回率(mrr)。
(3)综合考虑向量间匹配度计算的原理,本发明调和余弦相似度与欧几里德距离计算问答对向量间的匹配度,两者的结合考虑并满足了两个向量的距离足够短的同时夹角足够小的问题,相比单一的余弦相似度计算,该方法可以提升特征向量匹配度计算的准确性,为模型输出精准答案贡献了价值。
(4)教学智能问答系统与虚拟学习环境的有机结合是自然语言处理和虚拟现实技术相融合的趋势之一,虚拟课堂中的应用角色能回答相关的专业理论知识将是虚拟学习环境的一大进步。教学知识库在虚拟课堂中的应用能有效地减轻人类教师的教学工作量、提高教学质量、增进人类对其自身认知过程的了解和带动相关学科的发展,同时也拓宽了智能问答系统的应用领域与开发价值。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
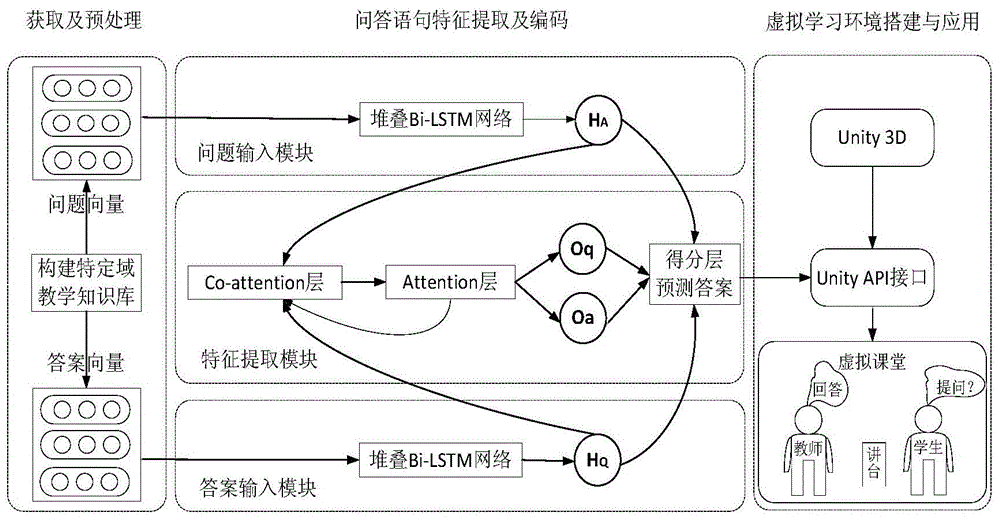
图1为本发明所述的虚拟学习环境智能问答方法系统框架图;
图2为本发明所述的堆叠bi-lstm网络框架图;
图3为本发明所述的协同注意力机制示意图;
图4为本发明所述的基于堆叠bi-lstm网络和协同注意力的虚拟学习环境智能问答方法实施流程图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
图1为本发明所述的虚拟学习环境智能问答方法系统框架图,该智能问答方法具体包括:首先,采集知识实体并构建特定领域知识库,训练word2vec模型,使其学习到相关语句的语义和语法关系,将训练好的word2vec模型作为词嵌入层获取问题和答案语句的词向量表示;然后,构建并训练堆叠bi-lstm网络模型以提取句子向量的隐含特征并编码,加入co-attention机制与attention机制捕捉问答对之间的关联特征并进一步获得更具代表性的向量表示;其次,调和余弦相似度与欧几里德距离以计算问答向量匹配度,排序并输出最佳答案;最后,采用unity3d平台架构虚拟学习学习环境并配置相应虚拟角色脚本程序,将训练好的特定域知识库教学问答系统通过unityapi接口引入虚拟学习环境,实现虚拟课堂中智能问答的可视化应用。
图4为本发明所述的基于堆叠bi-lstm网络和协同注意力的虚拟学习环境智能问答方法实施流程图,如图4所示,该智能问答方法具体实施步骤为:
步骤1:采集知识实体并构建特定领域的教学知识库,数据集经过预处理后用以训练word2vec模型。
步骤101:构建基于倒立摆实验的特定域教学知识库,通过网络爬虫技术和人工采集的方式获取1000条相关问答对文本,经过筛选、去重等操作,一般情况下一个问题对应5个答案,每个问题的答案列表中均包含一个最佳答案;
步骤102:将倒立摆实验教学知识库中20%的数据集训练word2vec模型,使模型具备表征相关语句的语义和语法关系的能力;
步骤103:训练好的word2vec模型即为词嵌入层,设置词向量维度为400维,通过模型获取问题和答案语句的词向量表示。
步骤2:搭建堆叠bi-lstm网络模型,将倒立摆实验教学知识库中60%的数据集训练深度网络模型,完成问答对语句向量的特征提取与表示工作。
步骤201:经由word2vec给定的问答对输入序列x=(x1,x2,...,xn)输送至lstm神经网络单元,历经输入门(it)、遗忘门(ft)和输出门(ot)三个全连接层,其中单元状态为ct,得到最后单元输出为ht。
ct=ft*ct-1+it*tanh(wxcxt+whcht-1+bc)(1)
ht=ot*tanh(ct)(2)
步骤202:为克服单个lstm单元只能捕获之前词语间关联性的弊端,如图2所示,现采用bi-lstm网络获取前后文的相关信息。bi-lstm从相反的方向计算前向隐藏序列
步骤203:相关实验表明,在神经网络中堆叠多个bi-lstm网络可以提高模型的分类与回归性能,同时深层模型较浅层模型表征能力更强。在bi-lstm的基础上架构堆叠bi-lstm网络,上一层bi-lstm网络的输出作为下一层bi-lstm网络的输入,最后得到堆叠bi-lstm网络的输出ht。
设定q=(q1,q2,...,qn)和a=(a1,a2,...,am)为问题和答案序列,hq和ha是问题和答案语句经堆叠bi-lstm网络输出的状态矩阵。
步骤3:由于倒立摆实验教学知识库中每条数据之间都存在着一定的关联性,模型加入co-attention机制捕捉问答对之间的相互作用与影响,可以获取更深层次的特定域问答对特征表示结果,如图3所示;
步骤301:通过关联矩阵l计算问答对状态矩阵的对应词语的关联度。
l=hathq∈rm*n(9)
步骤302:soft-max函数可处理概率分布问题,使用基于行和列的soft-max函数分别计算问题和答案的注意力权重。
aq=softmax(l)∈rm*n;aa=softmax(lt)∈rn*m(10)
步骤303:连接关联矩阵与注意力权重,获取问题和答案相互作用后的特征矩阵表示。
cq=haaq∈rd*n;ca=hqaa∈rd*m(11)
步骤4:在模型中加入attention机制以弥补堆叠bi-lstm网络特征提取过程中信息的丢失,得到问题和答案的最终向量表示oq和oa。在过程中,问题向量
其中,wam和wqm分别代表
步骤5:问答对向量匹配度计算,根据匹配度对候选答案序列进行排序,输出最佳答案。
步骤501:调和余弦相似度与欧几里德距离函数,得到向量匹配度计算模型score(oq,oa)。
将余弦相似度函数归一化处理至[0,1]区间。
scorecosine(oq,oa)=0.5scorecosine(oq,oa)+0.5(16)
根据匹配度计算模型计算问答对向量匹配度并排序,解码输出得分最高的答案向量。
步骤502:采用hinge损失函数对模型进行训练,该函数可同时输入候选答案序列的正负样本,训练目标函数如下。
l=max{0,m-socre(oq,oa+)+socre(oq,oa-)}+λ||θ||(19)
其中,m为固定余量,λ,θ分别为正则化参数和神经网络参数。
在训练过程中,我们利用反向传播算法计算梯度
步骤503:将平均准确率(map)与平均召回率(mrr)作为模型的评价指标,map和mrr的值越高系统性能越好。
其中,nq表示所有问题的个数,nai表示问题i相关正确答案的个数,pi(r)表示在召回率为r的情况下第i个问题查询的平均准确率,rankk表示问题i的第k个正确候选答案所在候选答案集的位置,ranki表示问题i的第一个正确候选答案所在候选答案集的位置。
步骤6:利用unity3d平台搭建虚拟学习环境,引入训练好的基于倒立摆实验教学知识库的问答系统模型,实现虚拟课堂中的智能问答可视化应用。主要包括以下步骤:
步骤601:根据具体的教学环境,利用虚拟现实技术在unity3d平台上搭建虚拟学习环境,创建基于虚拟课堂的倒立摆实验项目,在其中添加可进行人机交互的任务和虚拟角色的应用脚本程序;
步骤602:将已训练好的特定域知识库问答系统作为智能引擎通过unityapi接口导入到虚拟课堂的项目中,驱动对应虚拟角色与程序,实现基于倒立摆实验的智能教学问答。
步骤603:启动虚拟课堂项目,学生可通过外接设备驱动虚拟角色进行提问,进而触发模型进行回答,实现基于倒立摆实验的教学知识库问答演示。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!