一种基于Flink的实时轨迹co-movement运动模式检测方法与流程
本发明涉及计算机大数据领域中轨迹数据挖掘技术,特别是涉及一种基于flink和实时轨迹数据的co-movement运动模式检测方法。
背景技术:
随着定位设备的流行,使得大量的轨迹以时空序列记录形式从各种设备中持续不断地产生。实时轨迹数据区别于静态数据,是由多个移动对象持久不断生成的数据序列。目前对于静态轨迹数据的分析技术已趋于成熟,而实时轨迹数据由于其复杂性以及重要性,对其的分析技术成为了研究热点。
apacheflink是一个处理流数据以及批数据的开源系统,apacheflink的发起者认为无论批数据还是流数据,关于它们的很多实际应用场景都能够使用数据流进行表达与定义,因此很多实际应用都可以通过单一运行模型整合起来。它为实时轨迹流数据的处理提供了高吞吐以及低延时的保证。
运动模式检测是轨迹分析的一种重要类型,在基于位置的服务、动物行为研究、社会推荐等方面具有重要的应用价值,co-movement运动模式就是轨迹运动模式中的一种。现有的轨迹运动模式检测研究只关注历史数据,然而这些离线算法已经不能满足流数据实时分析的需要,因为针对历史静态数据的问题定义不能直接迁移到实时环境中。此外,对于实时轨迹数据,研究的问题主要是简单的范围查询以及最近邻求解,在分布式框架内对实时轨迹数据进行运动模式分析的工作存在大量空白。
技术实现要素:
针对现有技术的不足,本发明提供一种基于flink的实时轨迹co-movement运动模式检测方法,该方法基于flink分布式数据处理平台,先在聚类阶段对移动对象实时聚类,而后在枚举阶段根据实时聚类结果实时枚举出符合约束条件的轨迹co-movement运动模式。
为了达到上述目的,本发明所采用技术方案如下:一种基于flink的实时轨迹co-movement运动模式检测方法,该方法的步骤如下:
(1)对应用中某段时间的实时轨迹数据进行收集,得到样本数据;
(2)对得到的样本数据根据时间戳进行离散化得到多个快照;
(3)利用步骤(2)中得到的每个快照,对其数据构建gr-index,得到相应的空间划分;
(4)在聚类阶段,根据步骤(3)中得到的空间划分,对其中的数据进行范围查询以及使用dbscan方法聚类;
(5)在枚举阶段,对步骤(4)中得到的聚类后的每个快照使用基于id的分区技术,实时枚举,输出每个时间片符合约束条件的co-movement运动模式。
进一步的,所述步骤(2)具体为:
(2.1)将处于同一个时间段的移动对象数据聚集到一起,给定一个时间片长度和时间片起始时刻,将实际时间转换成时间片;
(2.2)将拥有相同时间片的移动对象放在一起处理,并且会追踪移动对象更新后的时间片信息lasttime;
(2.3)根据时间片信息确保移动对象有序的被处理,并且可以确认某一时间片的移动对象位置丢失是由于本身还是flink操作失误所致;最后得到多个快照,每个快照内的移动对象的时间片信息相同。
进一步的,所述步骤(3)具体为:
(3.1)对步骤(2)得到的每个快照,对其中的移动对象建立全局网格索引;
(3.2)对步骤(3.1)得到的每个网格计算其键的值,与flink中的分区相对应;
(3.3)对每个网格内的移动对象建立局部r树索引,叶子结点代表每个移动对象的实际位置;
(3.4)步骤(2)的每个快照经过网格索引与r树索引处理后得到空间划分结果。
进一步的,所述步骤(4)具体为:
(4.1)首先对步骤(3)得到的空间划分进行范围查询,找到符合dbscan要求的中心对象以及符合距离要求的可达对象,形成邻域;
(4.2)再使用dbscan聚类方法对每张移动对象快照进行聚类得到簇快照。
进一步的,所述步骤(5)具体为:
(5.1)在枚举阶段,对于每个簇快照,用基于id的分区技术进行分区,然后根据约束条件枚举出每个时间片对应的运动模式;
(5.2)利用两种压缩算法,即固定长度位压缩方法fba和不固定长度位压缩方法uba,减少基于id分区技术的时间复杂度以及存储开销。
进一步的,所述基于id的分区技术是指:对于每个簇快照t,将特定轨迹o的分区pt(o)分配给其相应的id,其余与o在相同簇的拥有更大id的移动对象分配给这个分区pt(o)。
进一步的,所述固定长度位压缩方法fba和不固定长度位压缩方法uba算法是指:固定长度位压缩方法fba通过给定某个分区pt(o)里的一个轨迹oi,一个固定的位串b[oi]用来表示oi,其中|b[oi]|=η,如果b[oi][j]=1(0≤j≤η-1)表示o与oi在时间t+j内属于同一个簇,b[oi][j]=0则表示o与oi在时间t+j内不属于同一个簇,该算法用来表示η个快照内该移动对象是否与同个id分区内的特定轨迹属于同一个簇;不固定长度位压缩方法uba则通过给定某个与轨迹o同属于一个子任务的轨迹oi,一个不固定的位串<sti,eti,b[oi]>来表示oi,sti代表起始时间片,eti代表终止时间片,如果b[oi][t-sti]=1表示o与oi在t∈[sti,eti]内属于同一个簇,b[oi][t-sti]=0则表示o与oi不属于同一个簇,该算法减少固定长度位压缩方法fba里不必要的快照验证,判断该时间片序列内该移动对象是否与同个id分区内的特定轨迹属于同一个簇。
本发明具有的有益效果是:本发明基于flink分布式流式计算引擎,设计了高效的实时轨迹co-movement运动模式检测算法icpe(indexedclusteringandpatternenumeration),对实时轨迹数据流进行高效的co-movement运动模式检测。本发明先在聚类阶段对移动对象进行实时聚类,而后在枚举阶段根据聚类结果实时枚举出符合约束条件的轨迹co-movement运动模式。在聚类阶段,本发明利用两层索引gr-index(网格和r树索引)对每个快照内的所有移动对象进行范围查询,避免不必要的范围查询;对进行范围查询后的每个快照使用dbscan(基于密度的聚类)方法进行聚类,加快了dbscan聚类方法对实时轨迹数据聚类的效率。在枚举阶段,本发明利用基于id的分区技术,实现对聚类后的每个快照进行运动模式枚举,此外,通过两种压缩算法fba(固定长度位压缩方法)和uba(不固定长度位压缩方法)减少基于id分区技术的时间复杂度以及存储开销,最后得到实时轨迹co-movement运动模式检测的结果。本发明极大地提高了运动模式检测的效率,提供了最佳的性能。
附图说明
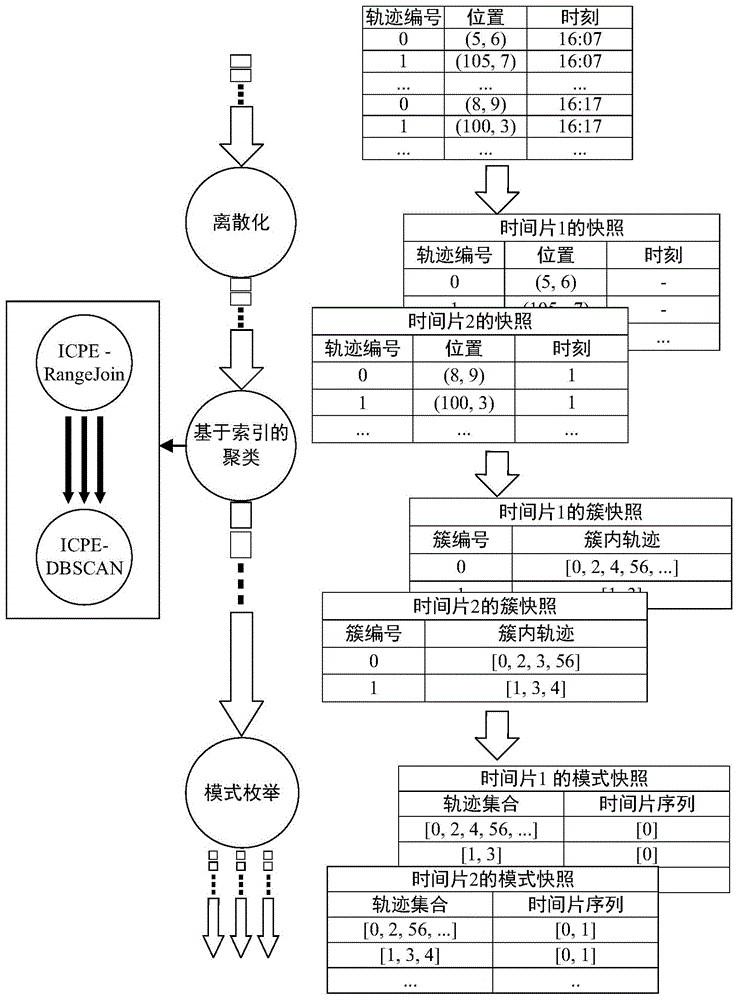
图1是本发明的实施步骤流程图;
图2是某个快照数据基于gr-index建立索引的例图;
图3是聚类阶段范围查询的过程图;
图4是枚举阶段对所有快照内数据分区的示意图;
图5是枚举阶段对轨迹使用fba(固定长度位压缩方法)和uba(不固定长度位压缩方法)进行位串压缩的示意图;
图6是实时轨迹数据运动模式枚举的示意图。
具体实施方式
现结合附图和具体实施对本发明的技术方案作进一步说明:
如图1所示,本发明具体实施过程和工作原理如下:
步骤(1):对应用中某段时间的实时轨迹数据进行收集,得到样本数据。
步骤(2):对得到的样本数据根据时间戳进行离散化得到多个快照,其离散的具体步骤为:
2.1)将处于同一个时间段的移动对象数据聚集到一起,给定一个时间片长度和时间片起始时刻,将实际时间转换成时间片;
2.2)将拥有相同时间片的移动对象放在一起处理,并且会追踪移动对象更新后的时间片信息lasttime;
2.3)根据时间片信息确保移动对象有序的被处理,并且可以确认某一时间片的移动对象位置丢失是由于本身还是flink操作失误所致。最后得到多个快照,每个快照内的移动对象的时间片信息相同。
步骤(3):利用步骤(2)中得到的每个快照,对其数据构建gr-index,得到相应的空间划分,建立索引的具体步骤为:
3.1)对步骤(2)得到的每个快照,对其中的移动对象建立全局网格索引,其中的g1,g2,...gn代表每个网格的标识,如图2(a)所示;
3.2)对步骤3.1)得到的每个网格,给定一个移动对象o的位置<x,y>以及网格的长度lg,则该网格的键值为
3.3)对每个网格内的移动对象建立局部r树索引,非叶子结点中的条目表示包含其孩子节点的最小边界盒子,叶子结点代表每个移动对象的实际位置,如图2(b)所示。
3.4)步骤(2)的每个快照经过网格索引与r树索引处理后得到空间划分结果。
步骤(4):在聚类阶段,根据步骤(3)中得到的空间划分,对其中的数据进行范围查询以及使用dbscan方法聚类,聚类的具体步骤为:
4.1)为了使用dbscan聚类方法,首先对步骤(3)得到的空间划分进行范围查询,找到符合dbscan要求的中心对象以及符合距离要求的可达对象,形成邻域;下面以图3为例对范围查询的过程进行说明:
(1)gridallocate算法使用网格索引对每个快照内的数据进行分区,并把移动对象转变成数据对象(位置在指定的网格里)和查询对象(位置范围与指定网格有相关性),其中在区分查询对象时,与该对象位置范围相交的网格内的其余对象也要重复操作,为了避免重复操作,我们只对与位置范围上半部分相交的网格里的对象进行此操作;查询对象形成流作为下一步的输入;
(2)gridquery算法为数据对象构建r树,对查询对象进行范围查询,基于单个数据集范围查询的对称属性可以知道只要对该数据集的每个对象进行范围查询,则可以确保查询后能形成完整邻域流;
(3)通过gridsync算法对所有网格各自形成的邻域流进行收集和同步。
4.2)再使用dbscan聚类方法对每张移动对象快照进行聚类得到簇快照,其聚类过程为:
(1)以邻域快照ns作为输入,它包含每一个位置u以及它的邻居集合,初始化变量c_num为0以及u.tag为-1,u.tag表示u属于哪一个簇,u.tag=-1表示u还没有被处理过;
(2)把每一个位置都分配到对应的簇中,如果u先前没有被处理过并且不是一个中心对象,那么u.tag=0;如果u先前没有被处理过并且是一个中心对象,那么它可以形成一个新簇,c_num←c_num+1且u.tag←c_num;
(3)对形成的新簇寻找其可达对象。
步骤(5):在枚举阶段,对步骤(4)中得到的聚类后的每个快照使用基于id的分区技术,实时枚举,输出每个时间片符合约束条件的co-movement运动模式,其中所述co-movement运动模式是指:一个co-movement运动模式cp(m,l,g,k)找到所有轨迹集合o,使得时间片序列t存在并且满足五个条件:紧密性(o里面的轨迹在每个时间t都属于同一个簇)、重要性(|o|≥m)、持续性(|t|≥k)、连续性(要求时间序列中的每一段连续片的长度都大于设定阈值l)、连接性(要求时间序列中,连续片段之间的时间差小于等于设定的阈值g)。
枚举的具体步骤为:
5.1)在枚举阶段,对于每个簇快照,用基于id的分区技术进行分区,然后根据条件枚举出每个时间片对应的运动模式;图4为分区的结果,下面进行具体描述:假定给定的时间片序列集合为s={s1,s2,...,s8}、对应的分区集合为p={p1,p2,...,p8}、轨迹集合为o={o1,o2,...o8}:
(1)分区结果如图4所示,例如,在时间片s1的簇快照为{(o1,o2),(o3,o4),(o5,o6,o7)},可以得到四个非空的分区:p1(o1)={o2},key=1;p1(o3)={o4},key=3;p1(o5)={o6,o7},key=5以及p1(o6)={o7},key=6;
(2)对于给定的分区pt(o),枚举出所有可能的运动模式以及找到它们有效的时间片序列,不满足给定运动模式cp(m,l,g,k)限制的即删除;首先计算
5.2)利用两种压缩算法fba(固定长度位压缩方法)和uba(不固定长度位压缩方法)减少基于id分区技术的时间复杂度以及存储开销,两种压缩算法结果如图5(a),(b)所示,具体步骤如下:
(1)对于fba(固定长度位压缩方法),给定某个分区pt(o)里的某个轨迹oi,一个长度为η(所有在此长度快照序列里找到的模式是不会遗漏的)固定的位串b[oi]可用来表示轨迹oi,b[oi][j]为1表示o和oi在t+j的时间片里属于同个簇,为0则不是。图5(a)列出了p2(o4)和p3(o4)在η=6的时间片序列里不同轨迹的位压缩;
(2)对于uba(不固定长度位压缩方法),给定某个与轨迹o同属于一个子任务的轨迹oi,一个不固定长度的位串<sti,eti,b[oi]〉可用来表示轨迹oi,其中sti表示开始的时间片,eti表示结束的时间片,b[oi][t-sti]为1表示o和oi在t+j的时间片里属于同个簇,为0则不是。图5(b)列出了p3(o4)与其他轨迹在不同时间片序列范围之内在某一时间片是否属于同一簇的位压缩。
最后,图6是样例轨迹数据co-movement运动模式枚举的一个结果图。
- 还没有人留言评论。精彩留言会获得点赞!