一种基于用户真实意图的语意模糊识别方法与流程
本发明涉及计算机自然语言处理技术领域,特别是一种基于用户真实意图的语意模糊识别方法。
背景技术:
随着信息技术的发展与人工智能概念的普及,越来越多的客户服务正朝着智能化的方向发展,人们可以通过简单的语音输入与智能设备进行人机交互。自然语言处理是计算机科学领域和人工智能领域中的一个重要方向,通过研究自然语言处理、语音语义识别及相关技术可以帮助人们更加方便有效地与智能设备进行交互,进而实现自己的真实意图。在语音人机交互的过程中,常见的方法是先将用户的语音信息转换为请求文本数据,然后对请求文本数据进行语义分析来理解用户的真实意图,然后将用户真实意图对应的内容传给终端设备进行后续处理。
目前语义识别存在的主要问题,一方面是由于用户说话语速快慢、声调高低、方言口音等问题引起的语音信号错误,导致请求文本数据失真,因此无法进行后续处理;另一方面,对语义的分析仅针对一条独立的语句,没有考虑情景的上文,缺少对用户真实意图的理解。由于上述缺陷,现阶段语义识别存在大量语义解析失败的请求文本,这些文本数据长度短、混淆性高、特征不明显、识别率低。
技术实现要素:
为解决现有技术中存在的问题,本发明的目的是提供一种基于用户真实意图的语意模糊识别方法,本发明针对语义解析失败的用户请求文本数据,根据已有的分类正确的历史数据进行特征提取,通过中文分词与词频矩阵,结合最大隶属度原则对解析失败的请求文本数据进行模糊模式识别,进而提高分类准确率。
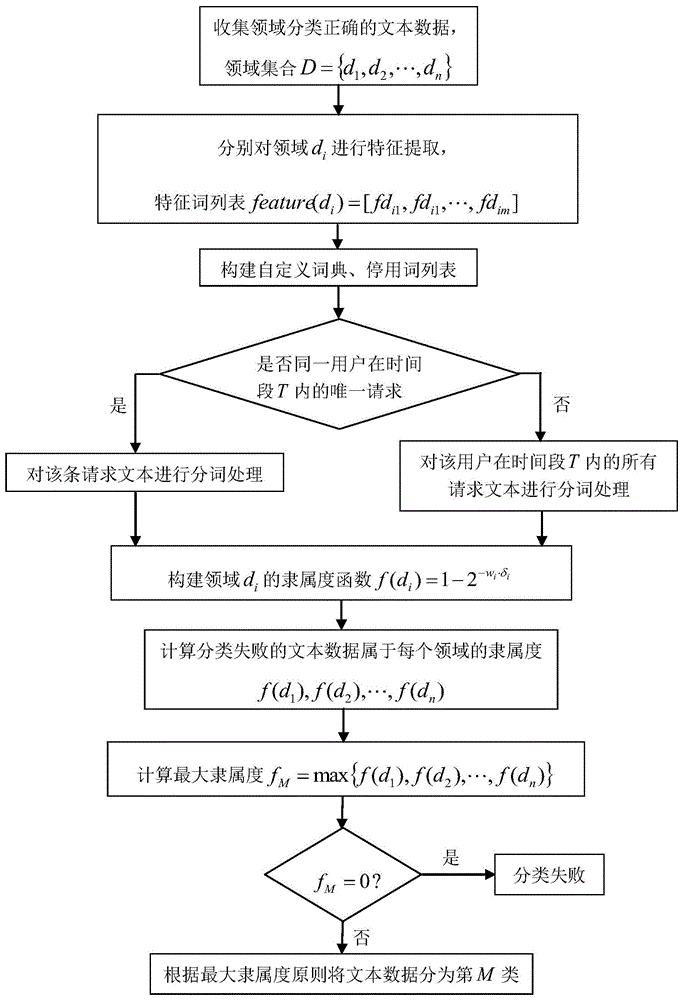
为实现上述目的,本发明采用的技术方案是:一种基于用户真实意图的语意模糊识别方法,包括以下步骤:
步骤s10、通过中文分词工具及词频矩阵对大量领域分类正确的历史数据进行特征提取,形成特征词列表;
步骤s20、对同一用户的单条请求文本数据及预设时间段内的多条请求文本数据进行分词,得到分词列表;
步骤s30、分别对不同领域构建隶属度函数,所述隶属度函数用于对分类失败的请求文本数据进行模糊模式识别;
步骤s40、分别计算分类失败的请求文本数据对不同领域的隶属度,根据最大隶属度的原则对分类失败的请求文本数据进行领域分类。
作为一种优选的实施方式,所述步骤s10具体包括:
步骤s11、收集项目日志数据中语义解析成功且分类正确的请求文本数据,将该请求文本数据分为n个不同的领域,并以集合的形式记为d={d1,d2,…,dn},其中di(1≤i≤n)代表第i个领域;
步骤s12、通过中文分词工具和词频矩阵分别对领域集合d中的每一个领域di进行特征词提取,得到代表每一个领域di的特征词列表feature(di)=[fdi1,fdi1,…,fdim]。
作为另一种优选的实施方式,所述步骤s20具体如下:
添加自定义词典和自定义停用词列表,然后判断分类失败的请求文本数据是否为同一用户在预设时间段内的唯一请求:如果是,则通过中文分词工具对该条请求文本数据tex进行分词,得到该条请求文本数据的分词列表segment(text)=[seg1,seg2,…,segr];如果不是预设时间段内的唯一请求,由于用户在与智能设备进行人机交互时的真实意图经常是连贯的、与前文相关的,因此将预设时间段内的所有请求文本数据进行分词,得到该时间段内的请求文本数据分词列表,这样使得一条请求文本数据的解析结果对用户之前的请求有一定依赖,更能反映用户的真实意图。
作为另一种优选的实施方式,所述步骤s30具体如下:
构建每个领域di的隶属度函数
作为另一种优选的实施方式,所述步骤s40具体如下:
分别计算分类失败的请求文本数据属于领域di(1≤i≤n)的隶属度f(d1),f(d2),…,f(dn),然后计算fm=max{f(d1),f(d2),…,f(dn)},若fm≠0,则根据最大隶属度的原则将该请求文本数据分类到第m类领域,再进行后续处理;若fm=0,则该请求文本数据领域分类失败。
作为另一种优选的实施方式,通过用户端的mac地址来确定是否为同一用户。
本发明的有益效果是:
本发明针对语义解析失败的用户请求文本数据,根据已有的分类正确的历史数据,通过中文分词与词频矩阵提取每个领域的文本特征,得到每个领域的特征词列表,进而构建每个领域的隶属度函数,然后对分类失败的请求文本数据进行两个阶段的中文分词处理:第一阶段仅对同一用户的单条请求文本数据进行分词;第二阶段对同一用户在预设时间段内所有请求文本数据进行分词,最后通过最大隶属度原则对分类失败的请求文本数据进行模糊模式识别,从而进行领域分类,提高分类准确率,进而提高语义解析的准确率。
附图说明
图1为本发明实施例的流程框图。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
如图1所示,一种基于用户真实意图的语意模糊识别方法,包括以下步骤:
(1)首先,收集日志数据,将其中解析成功且领域分类正确的请求文本数据分为不同的领域,如在本实施例中将用户对智能电视的语音请求文本数据分为video,music,tv三个领域,则
d={video,music,tv}
(2)通过分词工具和词频矩阵分别对video,music,tv三个领域进行高频特征词提取,得到三个领域的特征词列表:
f(video)=[我想看,我要看,电影,电视剧,点播,播放,的电影,周星驰]
f(music)=[我想听,我要听,歌曲,音乐,老歌,的歌,播放,主题曲,周杰伦]
f(tv)=[关机,音量,我想看,我要看,中央,卫视,频道,声音,调到,切换]
(3)添加自定义词典userdict和停用词列表stopword_list。
(4)假设分类失败的请求文本数据为text1=[播放于文文的歌体面],text1是同一用户在1分钟内的唯一请求,则通过分词工具对该条请求文本数据进行分词,得到分词列表segment1=[播放,于文文,的歌,体面];如果分类失败的请求文本数据为text2=[播放画儿与少年啊],并且text2不是同一用户在1分钟内的唯一请求,假设该用户在1分钟内的所有请求文本数据为total=[我要看花儿与笑脸,我要看福南卫视的画儿与少年,湖南卫视,播放画儿与少年啊],则将该用户1分钟内的所有请求文本数据进行分词,得到分词列表segment2=[我要看,花儿,笑脸,我要看,福南,卫视,画儿,少年,湖南,卫视,播放,画儿,少年]。
(5)分别构建video,music,tv三个领域的隶属度函数如下:
f(video)=1-2-0.4|feature(video)∩segment(text)|,
f(music)=1-2-0.35|feature(music)∩segment(text)|,
f(tv)=1-2-0.25|feature(tv)∩segment(text)|,
首先分析请求文本数据text1,计算可得f(video)=0.1294,f(music)=0.3050,f(tv)=0,由于fmusic=max{f(video),f(music),f(tv)}=0.3050>0,因此根据最大隶属度原则,将分类失败的请求文本数据text1分类为music领域。
现在分析请求文本数据text2,结合同一用户在1分钟内的多条请求文本,计算可得f(video)=0.3402,f(music)=0.1142,f(tv)=0.4547,由于
ftv=max{f(video),f(music),f(tv)}=0.4547>0,
因此根据最大隶属度原则,将分类失败的文本数据text2分类为tv领域。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!