基于随机森林的图文数据融合情感分类方法和装置与流程
本发明属于信息技术领域,具体涉及一种基于随机森林的图文数据融合情感分类方法和装置。
背景技术:
目前互联网上存在海量的图、文融合数据,针对这些数据进行情感分类能有效的帮助进行商业决策、进行舆情分析等。但是当前的情感分类研究主要针对单个模态上的数据,很少有针对多模态数据进行的情感分类研究。比如针对文本的情感分类,有基于情感词典的方法,或者是基于机器学习的方法;针对图片的情感分类,有基于像素级颜色分布的方法,基于视觉特征词袋的方法,或者是基于深度神经网络的方法。也有少部分针对多个模态进行情感分类的方法,比如跨模态一致性回归模型(cross-modalityconsistentregression,ccr)通过绑定多个模态之间的分类损失来完成多模态的情感分类任务(youq,luoj,jinh,etal.cross-modalityconsistentregressionforjointvisual-textualsentimentanalysisofsocialmultimedia[c]//proceedingsoftheninthacminternationalconferenceonwebsearchanddatamining.[s.l.]:acm,2016:13–22.)。还有基于视觉特征词袋的方式,通过图片的视觉特征词袋统一图文间的特征进行情感分类(caod,jir,lind,etal.across-mediapublicsentimentanalysissystemformicroblog[j].multimediasystems,2016,22(4):479–486.)。
针对单一模态上的情感分类,无论是基于图片的情感分类或者是基于文本的情感分类,都无法有效的表达图文整体的情感,因此这类方法本身有限制。跨模态一致性回归模型虽然能考虑到图文共同的特征进行情感分类,但是模型难以训练,并且对训练数据和测试数据的质量要求很高。典型相关分析的核方法也能用来获取多模态数据的关联信息。虽然典型相关分析及其核扩展能够对不同特征间的关联进行建模,但是其在捕获特征间高层抽象间的关联性时具有局限性。
技术实现要素:
本发明旨在提供一种有效的融合图片、文本来进行情感分类的方法,能够有效的将图文多模态信息融合在一起进行情感分类。
分别提取图片、文本的特征,并将提取到的特征合并起来,作为最终分类器的输入进行情感分类,称之为中融合。但是普通的中融合只是简单的将特征合并起来,不能处理多个模态特征间的权重问题。本发明提出了一种基于随机森林的融合方法,可以有效的获取到单个模态上的特征,并且可以将二者的特征向量合并起来,作为一个整体的特征放入随机森林进行分类学习并进行情感分类。
本发明采用的技术方案如下:
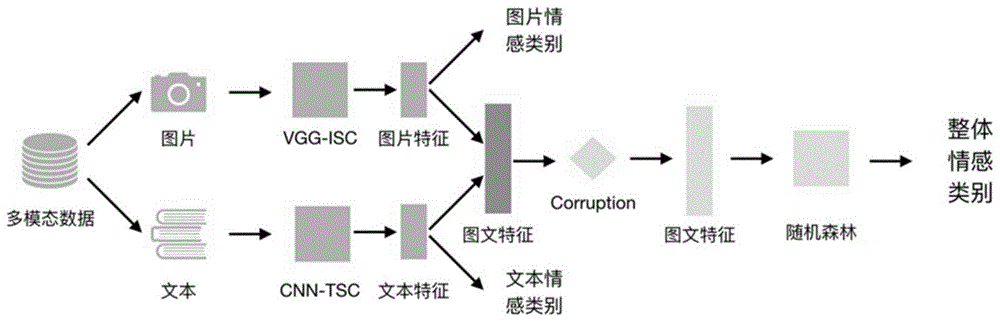
一种基于随机森林的图文数据融合情感分类方法,包括以下步骤:
1)提取多模态数据中图片的特征和文本的特征;
2)将提取的图片的特征与文本的特征进行合并,得到图文整体特征;
3)通过corruption机制对图文整体特征进行特征选择;
4)通过随机森林分类器对进行特征选择后的图文整体特征进行分类,得到情感分类结果。
进一步地,步骤1)通过vgg-isc网络提取多模态数据中图片的特征,通过cnn-tsc网络提取多模态数据中文本的特征。
进一步地,所述vgg-isc网络的训练方式为:首先在ilsvrc-2012数据集上预训练vgg-19网络;训练好vgg-19网络之后,修改其最后两层的维度,即第二个全连接层的维度为k,softmax的输出类别为2类或者3类;最后冻结所有的卷积层参数,使用训练数据集里的图片作为输入,图片的情感类别作为输出,继续训练vgg-isc网络的最后三层的参数;训练好vgg-isc网络后,将第二个全连接层作为图片的特征输出。
进一步地,所述cnn-tsc网络使用文本的分词后的词表达矩阵作为输入,利用预训练好的word2vec将分词后的词语映射成向量,将每个词的向量转置后形成的矩阵作为cnn-tsc的输入,之后使用多个不同大小的卷积核对该词表达矩阵进行卷积操作,并且通过随时间的最大池化、变平、dropout、全连接、softmax层后输出文本的特征类别。
进一步地,所述cnn-tsc和vgg-isc网络采用领域迁移的方式进行训练。
进一步地,所述corruption机制对图文整体特征f的每一维按照概率q重写为0,将其他维度改为原值的1/(1-q)倍。
进一步地,所述corruption机制中,重写概率q在序列{0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9}中取值。
进一步地,所述随机森林分类器通过有放回的采样获取一棵决策树的训练子集,并通过随机的选择特征作为决策树的输入,使每棵决策树关注的特征不同,从而使每棵决策树的结构不同,以提高分类的准确率。
进一步地,所述随机森林分类器中,决策树数量为600,每颗决策树使用的特征比重从序列{0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5}中取值。
与上面方法对应地,本发明还提供一种基于随机森林的图文数据融合情感分类装置,其包括:
图片特征提取模块,负责提取多模态数据中图片的特征;
文本特征提取模块,负责提取多模态数据中文本的特征;
特征合并模块,负责将提取的图片的特征与文本的特征进行合并,得到图文整体特征;
特征选择模块,负责通过corruption机制对图文整体特征进行特征选择;
分类模块,负责通过随机森林分类器对进行特征选择后的图文整体特征进行分类,得到情感分类结果。
本发明的有益效果如下:
1)本发明可以有效的获取到单个模态上的特征,并且可以将二者的特征向量合并起来,作为一个整体的特征放入随机森林进行分类学习并进行情感分类。
2)在二、三分类的情况下,在几种特征层面的融合模型中,本发明的情感分类网络表现相对更好。在二分类情况下,本发明的分类准确率达到了83.42%,高于多重深度卷积神经网络的80.19%和跨模态一致性回归模型的83.16%,三分类的准确率达到了74.21%,高于多重深度卷积神经网络的71.69%和跨模态一致性回归模型的73.15%。
附图说明
图1是本发明方法的步骤流程图。
图2是cnn-tsc网络的结构示意图。
图3是vgg-isc网络的结构示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施例和附图,对本发明做进一步详细说明。
图1是本发明方法的步骤流程图。本发明基于vgg-19的vgg-isc网络来提取图片的特征向量,并且使用基于cnn的cnn-tsc网络来提取文本的特征向量。cnn-tsc网络(cnntextsentimentclassification,基于cnn的文本情感分类网络)和vgg-isc网络(vggimagesentimentclassification,基于vgg的图片情感分类网络)的结构分别如图2和图3所示。对于cnn-tsc网络和vgg-isc网络的训练均使用了额外的其他大规模的数据进行预训练,以便获得更好的模型的参数。首先在大量的情感打标的训练文字上训练网络,之后再通过使用微博训练集中的文字微调参数来让网络适应微博文本的分布。
将图片的特征与文本的特征合并起来后,通过corruption机制(chenm.efficientvectorrepresentationfordocumentsthroughcorruption[j].arxivpreprintarxiv:1707.02377,2017.)选择特征。corruption实质上是对合并后得到的图文整体特征f的每一维按照概率q进行重写为0,对于其他维度,为了保证无偏向,将其改为原值的1/(1-q)倍。其中q表示重写为0的概率。
模型在单个模态上的分类准确率越高,模型在该维度上对特征的抽取性能越好,而模型在整体的情感类别则代表了模型整体的性能。本发明使用随机森林来得到最终体的情感类别,这就是中融合,即基于图、文单独的特征的融合。
本发明为了取得更好的分类结果,采用随机森林分类器。随机森林由多个决策树组成,每个样本都有大约36.8%的概率不被采样到,这些不被采样到的大约36.8%的数据,常被称为袋外数据,由于袋外数据没有参与模型的训练,所以可以用来检测模型的泛化能力。在决策树数量不同时,模型对于特征的利用性能有区别,在决策树数量为600时效果最好。为了提高模型的性能,使用了较小的特征比重,并用corruption机制选择了较少的特征,加快模型训练速度。
本发明的技术关键点在于:
1)本发明基于深度神经网络的方法自动获取到图文的融合特征。
2)通过corruption机制处理合并后的特征,可以挑选需要的特征,防止过拟合,并且其是一种更加高效的降维过程,减少参数,对重复多次的相似特征惩罚。通过这种方式进行有效的降维,能够有效地获取单个模态的特征并且将特征合理地组合起来进行情感分类。
3)采用随机森林进行分类,引入了两个随机性:样本随机、特征随机。通过有放回的采样获取一棵决策树的训练子集,这个子集中,既有重复的数据,又有其他决策树训练子集中没有的数据,并且还有一部分数据可能永远不属于任意的决策树的训练子集。通过随机的选择特征作为决策树的输入,可以使每棵树关注的特征不同,从而使每棵决策树的结构不同,提高了分类的准确率。
利用本发明提供的分类网络,具有如下优点:
训练多模态情感分类器的数据主要使用已经打好标签的微博图文数据。数据集中一共有10269条打标的图文微博,对其中图片、文本和微博整体打了三分类的情感标签,即正向情感、中性情感以及负向情感。预训练vgg-19网络还使用了其它大规模数据集。在训练文本的分布式词表达过程中,还使用了微信公众号文章数据和微博的文本数据,属于多领域中文平衡语料。语料库包含800万篇微信公众号文章和约80万条微博数据,总共约652亿词。在二、三分类的情况下,在几种特征层面的融合模型中,本发明的情感分类网络表现相对更好。在二分类情况下,本发明的分类准确率达到了83.42%,高于多重深度卷积神经网络的80.19%和跨模态一致性回归模型的83.16%,三分类的准确率达到了74.21%,高于多重深度卷积神经网络的71.69%和跨模态一致性回归模型的73.15%。
下面提供一个采用本发明方法的具体实例。以微博数据二分类任务为例,包括以下步骤:
1)对于图片特征的提取,使用vgg-isc网络提取特征。vgg-isc网络的结构如图3所示,其训练方式为,首先在ilsvrc-2012数据集上预训练vgg-19网络,训练好了vgg-19之后,修改其最后两层的维度,即第二个全连接层的维度与softmax的分类层的维度。设置第二个全连接层的维度为k,并且将softmax的输出类别变为2类或3类。最后冻结所有的卷积层参数,使用微博数据集里的图片作为输入,图片的情感类别作为输出,继续训练上面网络的最后三层的参数。训练好vgg-isc网络后,将第二个全连接层作为图片的特征输出。
2)对于文本特征,使用基于cnn的cnn-tsc网络提取文本的特征表达。cnn-tsc网络的结构如图2所示,使用文本的分词后的词表达矩阵作为输入,词表达的方式使用分布式词表达法,利用预训练好的word2vec将分词后的词语映射成向量,将每个词的向量转置后形成的矩阵作为cnn-tsc的输入,之后使用多个不同大小的卷积核对这个词表达矩阵进行卷积操作,并且通过随时间的最大池化、变平、dropout、全连接、softmax层后输出文本的特征类别。cnn-tsc采用领域迁移的方式进行训练。训练好的cnn-tsc网络中,全连接层的输出可以看做是文本的情感特征。文本特征提取网络中,卷积核的大小分别为2,3,4,5,每种大小的卷积核都有256个,dropout设置为0.5。
3)将前述过程提取到的文本特征与图片特征做一次归一化后直接拼接,即得到了图文整体的特征。图、文特征均是128维,即图文整体特征为256维。
4)为了得到更加有效的图文特征,加入corruption机制来丢弃一部分已获得的特征。corruption机制中,重写概率p的取值在序列{0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9}中取值。通过这样的操作,将文本、图片的特征分别提取出来。
5)构建随机森林,设置决策树数量为600,每颗决策树使用的特征比重从序列{0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5}中取值。
6)将上面提取到的图文特征作为上述随机森林的输入。即,将提取到的特征作为一个整体放入随机森林情感分类器中进行情感分类。
7)将分类器输出的结果和标签比对,与标签一致的结果数和总结果数的比值即为分类准确率。
本发明中,文本特征提取也可以使用其它网络结构,如cnn,rnn,lstm,gru等,图片特征提取也可以使用vgg等网络结构。
本发明另一实施例提供一种基于随机森林的图文数据融合情感分类装置,其包括:
图片特征提取模块,负责提取多模态数据中图片的特征;
文本特征提取模块,负责提取多模态数据中文本的特征;
特征合并模块,负责将提取的图片的特征与文本的特征进行合并,得到图文整体特征;
特征选择模块,负责通过corruption机制对图文整体特征进行特征选择;
分类模块,负责通过随机森林分类器对进行特征选择后的图文整体特征进行分类,得到情感分类结果。
其中,各模块的具体实现参见前文对本发明方法的说明。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的原理和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!