一种多级无序索引方法与系统与流程
本发明涉及大数据处理技术及存储索引技术领域,尤其涉及一种快速的多级无序索引方法与系统。
背景技术:
随着大数据时代的到来,键值系统(key-valuestoragesystem,kv)迎来了飞速的发展。键值系统在首次执行写操作时,为每个值(value)分配一个全局唯一的键(key)。在后续的读操作和删除操作时,均需首先获取该键。因此,键的快速索引速度直接影响甚至决定了键值系统的性能。
现有的快速索引方法主要有hash索引和b+树索引两种:hash索引不支持范围查找、存在哈希冲突,因此应用范围较窄。b+树索引支持范围查找,且不存在哈希冲突的问题,因此成为目前主流的一种方法。
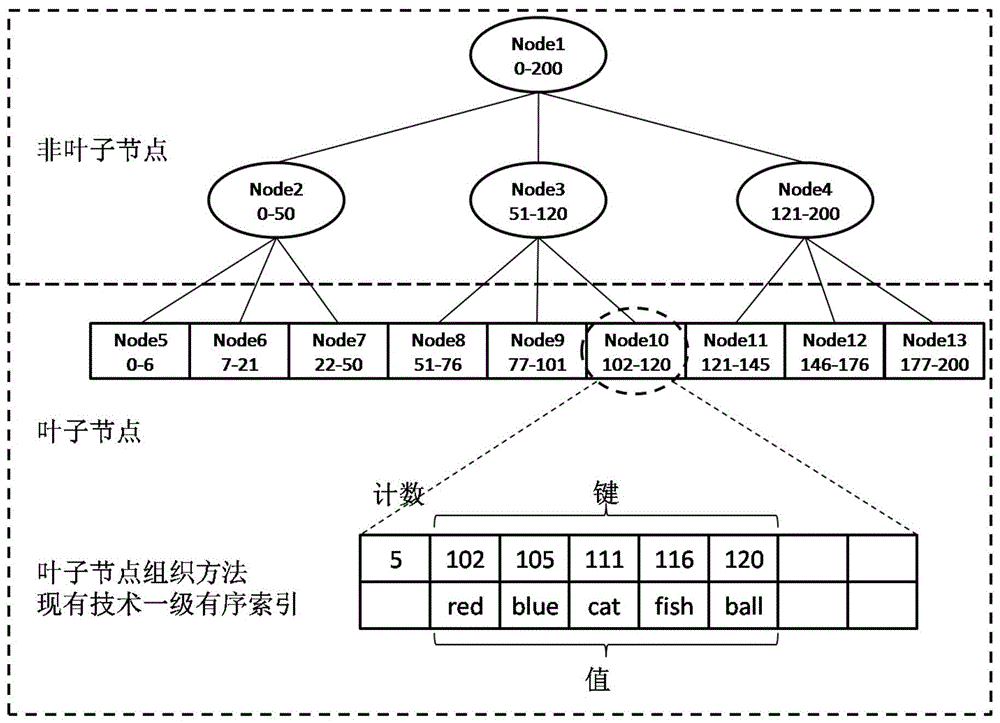
b+树索引的精神实质是:将所有键组织成一棵b+树,非叶子节点用于对键的索引,叶子节点保存键和值,在每一层非叶子节点进行一次二分查找(或称折半查找),即可快速地完成对键的索引。
但是,针对叶子节点组织的两种现有技术存在严重弊端,无法同时满足读、写、删操作的高性能需求。其一是有序索引,其原理最为简单、最为人们熟知、应用范围最为广泛,已成为本领域的公知常识,如图1所示,其优点是读操作的性能高,缺点是写和删操作的性能低;其二是无序索引,例如cn201310456838.7,如图2所示,其优点是写和删除操作的性能高,缺点是读操作的性能低。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种多级无序索引方法与系统,通过多级无序的叶子节点,巧妙地实现了有序的索引,从而兼具“有序索引”和“无序索引”的优点,同时满足了读、写、删除操作对高性能的需求和效果。
本发明提供的技术方案是:
一种快速的多级无序索引方法,在基于存储器件构建的键值系统中,将所有键组织成b+树,通过多级无序的叶子节点实现有序的索引,包括如下步骤:
1)将所有键组织成一棵b+树;其中:
11)非叶子节点用于对键的索引,每一层非叶子节点都是有序的;
12)叶子节点用于存储所有键和值;
具体实施时,叶子节点包括第一无序队列、第二无序队列和第三无序队列;第一无序队列包括位图元素和普通元素。位图元素以二进制方式呈现,各个位只能是1或0。某位是1代表第二无序队列对应的元素非空闲,某位是0时代表第二无序队列对应的元素是空闲。典型的位图占用1个字节,共有8位。通过位图可以计算出该叶子节点的键数量,计算方法是将各位相加。普通元素是无序的,通过普通元素能够查找到键在第二无序队列的元素序号,以及值在第三无序队列中的元素序号。第二无序队列包含普通元素,其内容为键。第二无序队列也是无序的。第三无序队列包含普通元素,其内容为值。键和值是成对关联出现的,关联的键和值在第二无序队列和第三无序队列的元素序号是相同的。
2)对键进行快速索引,查找叶子节点中特定的键keyp及其值地址,p为字母a~z;由此实现键值系统多级无序的快速索引。
本发明对键进行快速索引的方法包括顺序法(包括正序法和逆序法)或二分法(也称折半法);二分法更适用于对特定键的索引操作,例如读键、写键、删键。顺序法更适用于对特定范围键的索引操作,例如范围读。
其中,正序遍历叶子节点中所有键和值地址包括如下过程:
2a1)首先读取第一无序队列的第一个元素,其内容记为a;
2a2)然后读取第二无序队列的第a个元素,其内容记为keya,代表键keya。其次读取第三无序队列的第a个元素,其内容为valuea,代表值valuea。
2a3)其次读取第一无序队列的第二个元素,其内容记为b,然后读取第二无序队列的第b个元素,其内容记为keyb,代表键keyb;其次读取第三无序队列的第b个元素,其内容记为valueb,代表值valueb;
以此类推,直至读取第一无序队列的最后一个元素,其内容记为z;然后读取第二无序队列的第z个元素,其内容记为keyz,代表键keyz。其次读取第三无序队列的第z个元素,其内容记为valuez,代表值valuez,即可实现键值系统多级无序的快速遍历。
采用改进的二分查找法查找叶子节点中特定的键keyp对应的值valuep,包括如下步骤:
2b1)假设第一无序队列共有k个元素,首先读取第一无序队列的第k/2个元素,其内容记为c;
2b2)然后读取第二无序队列的第c个元素,其内容记为keyc;
2b3)对比keyp和keyc;如果相等则找到;如果keyp大于keyc,那么继续查找k*3/4,如果keyp小于keyc,那么继续查找k/4;以此类推,直至找到或确认不存在;
2b4)假设最终找到第二无序队列的第d个键为keyp,则第三无序队列的第d个元素的内容即为所查找的valuep。
利用上述多级无序的快速索引方法,实现对键值系统中键的四个基本操作,主要包括:写操作(set)、单键读操作(get)、范围读操作(scan)、删操作(delete)。具体实施如下:
一、写操作(set),执行如下步骤:
步骤1:为值valuen分配全局唯一的键keyn,keyn为数字。
值的形态包括但不限于:数值、图片、文本、表情、文件、邮件、字符串、地址等。键的分配方法包括但不限于:顺序分配法、倒序分配法、随机分配法、求余数分配法等。
步骤2:由b+树的根节点起,逐层检索子节点,直至确定该键应存储的叶子节点,标记为叶子节点nodek。在非叶子节点均按照有序的形式进行组织。
在非叶子节点检索的方法包括但不限于:顺序法、逆序法、二分查找法,优选地应使用二分查找法。
逆序遍历的过程是正序遍历过程的逆过程。
步骤3:在叶子节点nodek中:
步骤3.1:读取第一无序队列中的位图元素,得出节点存储的键的个数count,并且找到第x个元素为0。找到为0的元素的方法包括但不限于:顺序法、逆序法、随机法。
步骤3.2:将位图中第x个元素由0修改为1,将键keyn写入第二无序队列的第x元素,将值valuen写入第三无序队列的第x元素。
步骤3.3:将x写入第一无序队列中第y个元素,原第y个位置及其之后位置的元素依次后移。y为对第二无序队列中的所有元素的排序后,键keyn的顺序。
辨别y的方法包括但不限于:(1)在第一无序队列中由前至后依次查找相应的第二无序队列中的值。(2)在第一无序队列中由后至前依次查找相应的第二无序队列中的值。(3)在第一无序队列中折半查找相应的第二无序队列中的值。
步骤4:写入操作结束。
二、单键读操作(get),执行如下步骤:
步骤1:读取一个键的值,键的编号为keyn,keyn为数字;
由b+树的根节点起,逐层检索子节点,直至确定该键应存储的叶子节点,标记为叶子节点nodek。
步骤2:读取第一无序队列中的位图元素,得出叶子节点nodek存储的键的个数count。
步骤3:遍历第一无序队列中的所有count个元素,及其在第二无序队列中的相应键。遍历方法包括但不限于:顺序法、逆序法、二分查找法。
步骤4:假设在第一无序队列的第b个元素的内容为c,第二无序队列的第c个键的内容恰好等于keyn,则停止遍历。
步骤5:第三无序队列的第c个元素的内容,记为valuec,将其作为读取结果反馈给调用程序。
步骤6:如果在步骤3中的遍历结束后仍未找到,则反馈给调用程序:该键值不存在。
步骤7:单键读操作结束。
三、范围读操作(scan),读取键范围对应的值,执行如下步骤:
步骤1:确定某一范围的键应存储的叶子节点;
具体地,读取键范围为keyn-keym的值,其中keyn和keym为数字。由b+树的根节点起,逐层检索子节点,直至确定该键范围应存储的叶子节点。分为三类叶子节点:最左侧的节点记为nodex,中间的节点记为nodey,最右侧的节点记为nodez,其中,中间的节点可能存在多个,均采用相同的处理方法。
步骤2:在叶子节点nodex中,由后至前进行遍历,当遇到第一个不在keyn-keym范围的键时即停止遍历,将已遍历的键和值记录在内存。
步骤3:在叶子节点nodey中,由前至后进行遍历,将所有键和值记录在内存。
步骤4:在叶子节点nodez中,由前至后进行遍历,当遇到第一个不在keyn-keym范围的键时即停止遍历,将已遍历的键和值记录在内存。
步骤5:将上述记录在内存中的键和值,反馈给调用程序。
四、删操作(delete),执行如下步骤:
步骤1:设待删除键为keyn的键值对,keyn为数字;
由b+树的根节点起,逐层检索子节点,直至确定该键应存储的叶子节点,标记为叶子节点nodek。
步骤2:读取第一无序队列中的位图元素,得出叶子节点nodek存储的键的个数count。
步骤3:遍历第一无序队列中的count个元素,及其在第二无序队列中的相应键。遍历方法包括但不限于:顺序法、逆序法、二分查找法。
步骤4:假设在第一无序队列的第b个元素为c,第二无序队列的第c个元素的内容恰好等于keyn,则停止遍历。
步骤5:在第三无序队列中,第c个元素的内容,记为valuec,将其删除。
步骤6:在第二无序队列中,将第c个元素的内容keyn删除。
步骤7:在第一无序队列中,将位图的第c个位由1改为0。
步骤8:在第一无序队列中,将第b个元素的内容删除,将第b个元素之后的所有元素依次前移。
步骤9:删除操作结束。
利用上述多级无序的快速索引方法,本发明还提供一种多级无序的快速索引系统,包括:第一存储器件、第二存储器件;
a.第一存储器件用于存储b+树的非叶子节点。所有的键组织成一颗b+树,非叶子节点用于对键的索引,每一层非叶子节点都是有序的。
b.第二存储器件用于存储b+树的叶子节点;包括:第一无序队列、第二无序队列和第三无序队列;
b1.第一无序队列,包括位图元素和普通元素。位图元素以二进制方式呈现,各个位只能是1或0。某位是1代表第二无序队列对应的元素非空闲,某位是0时代表第二无序队列对应的元素是空闲。典型的位图占用1个字节,共有8位。通过位图可以计算出该叶子节点的键数量,计算方法是将各位相加。普通元素是无序的,通过普通元素能够查找到在第二无序队列的元素序号。
b2.第二无序队列,用于存储键。第二无序队列也是无序的。
b3.第三无序队列,用于存储值。在第二无序队列中每一个非空的键都会在第三无序队列中存储值。第三无序队列也是无序的。
上述多级无序的快速索引系统中的第一存储器件、第二存储器件,既可以是不同的存储器件(如dram、nvm、ssd),也可以是同种存储器件(例如,有两个dram,分别是第一、第二存储器件),还可以是同一个存储器件(只有一个dram,划分为两个相互隔离的区域,分别是第一、第二存储器件)。
与现有技术相比,本发明的有益效果是:
本发明采用多级无序索引实现快速索引,与现有技术的一级无序索引或一级有序索引相比,能够对写、读、删、范围查找等操作都能更高效的完成。在实现快速索引的基础上,实现对存储器对键的快速读写操作。
采用本发明所述方法,与现有技术相比,兼具“有序索引”和“无序索引”的优点,同时满足了读、写、删除操作对高性能的需求,具有很强技术优势。
附图说明
图1是现有技术一级有序索引的示意图。
图2是现有技术一级无序索引的示意图。
图3是本发明提供的多级无序索引的示意图。
图4是本发明实施例写入键113的步骤图解。
图5是本发明实施例读键113的步骤图解。
图6是本发明实施例范围读键98至135的步骤图解。
图7是本发明实施例删键113的步骤图解。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明采用多级无序索引实现快速索引,与现有技术的一级无序索引或一级有序索引相比,能够更高效的完成写、读、删、范围查找等操作。
实施例场景描述:含有2种存储器件:dram内存、ssd固态硬盘,将b+树的非叶子节点放在dram中,叶子节点放在ssd中。在该实施用例中,值为字符串小单词,键的取值范围为0至200。
当新写入一个字符串pop时:
(1)为该字符串pop分配全局唯一的键113。
(2)读取该b+树的根节点,逐层遍历。由于键113介于51至120,因此逐一检查node3的子节点。由于键113介于102至120,因此最终需要进入叶子节点node10。
(3)在叶子节点node10中:
(3.1)读取第一无序队列的位图元素,逐一检查该位图的各个位,该叶子节点存有5个键;另外,检查到第3位是0,即表示第二无序队列和第三无序队列中的第3个元素都是空闲的。因此,将113写入第二无序队列的第3个元素,将字符串pop写入第三无序队列的第3个元素。最后,将位图第3位修改为1。
(3.2)读取第一无序队列的第3个元素为7,在第二无序队列的第7个键为112。由于113键大于112,因此在第一无序队列的第3个元素之后进一步查找。读取第一无序队列的第4个元素为4,在第二无序队列的第4个键为116。由于113键介于112和116之间,因此113号应写入第4个元素。
(3.3)在第一无序队列中,第5个元素的内容2移动到第6个元素,第4个元素的内容4移动到元素5,将3写入第4个元素。
(4)完成新写入操作。
当查找键113的字符串时:
(1)读取该b+树的根节点,逐层遍历。由于键113介于51至120,因此逐一检查node3的子节点。由于键113介于102至120,因此最终需要进入叶子节点node10。
(2)在叶子节点j中:
(2.1)读取第一无序队列的位图元素,逐一检查该位图的各位,得出该叶子节点存有6个键。
(2.2)读取第一无序队列的第3个元素为7,在第二无序队列的第7个键为112。由于键113大于112,因此在第一无序队列的第3个元素之后进一步查找。
(2.3)读取第一无序队列的第4个元素为3,在第二无序队列的第3个键为113,即找到。
(2.4)在第三无序队列中,将第3个元素的内容字符串“pop”返回给调用程序。
当范围查找键98至键135的字符串时:
(1)读取该b+树的根节点,逐层遍历。由于键范围98至135,因此需要进入三个叶子节点进一步检索:叶子节点node9的后半段,叶子节点node10的全部,叶子节点node11的前半段。
(2)在叶子节点node9中:
(2.1)读取第一无序队列的位图元素,逐一检查该位图的各个位,得到该叶子节点存有3个键。
(2.2)由后至前进行遍历:读取第一无序队列的第3个元素为2,读取第二无序队列的第2个元素为101,在第三无序队列中,将第2个元素字符串qq暂存在内存中。由于101大于98,因此继续。
(2.3)读取第一无序队列的第2个元素为5,读取第二无序队列的第5个元素为98,在第三无序队列中,将第5个元素字符串yy暂存在内存中,因找到键98,故不再继续。
(2.4)将内存中暂存的元素字符串yy标记为p1,将元素字符串qq标记为p2。
(3)在叶子节点node10中:
(3.1)读取第一无序队列的位图元素,逐一检查该位图的各个位,得出该叶子节点存有6个键。
(3.2)由前至后进行遍历:读取第一无序队列的第1个元素为1,在第三无序队列中,将第1个元素字符串red暂存在内存中,标记为p3。
(3.3)读取第一无序队列的第2个元素为6,在值的地址指针队列中,将第6个元素字符串blue暂存在内存中,标记为p4。
(3.4)读取第一无序队列的第3个元素为7,在值的地址指针队列中,将第7个元素字符串cat暂存在内存中,标记为p5。
(3.5)读取第一无序队列的第4个元素为3,在值的地址指针队列中,将第3个元素字符串pop暂存在内存中,标记为p6。
(3.6)读取第一无序队列的第5个元素为4,在值的地址指针队列中,将第4个元素字符串fish暂存在内存中,标记为p7。
(3.7)读取第一无序队列的第6个元素为2,在值的地址指针队列中,将第2个元素字符串ball暂存在内存中,标记为p8。
(4)在叶子节点node11中:
(4.1)读取第一无序队列的位图元素,逐一检查该位图的各个位,得出该叶子节点存有4个键。
(4.2)由前至后进行遍历,读取第一无序队列的第1个元素为4,读取第二无序队列的第4个元素为124。在值的地址指针队列中,将第4个元素字符串5c暂存在内存中,标记为p9。由于124小于135,因此继续。
(4.3)读取第一无序队列的第2个元素为2,读取第二无序队列的第2个元素为136,由于136大于135,因此结束。
(5)按照p1、p2……p9的顺序,返回调用程序。
当删除键113的字符串时:
(1)读取该b+树的根节点,逐层遍历。由于键113介于51至120,因此逐一检查node3的子节点。由于键113介于102至120,因此最终需要进入叶子节点node10。
(2)在叶子节点node10中:
(2.1)读取第一无序队列的位图元素,逐一检查该位图的各个为,该叶子节点共有6个键。
(2.2)读取第一无序队列的第3个元素为7,在第二无序队列的第7个元素读出键为112。由于键113大于112,因此在第一无序队列的第3元素之后进一步查找。
(2.3)读取第一无序队列的第4个元素为3,在第二无序队列的第3个元素读出键为113,即找到。在第三无序队列中,将第3个元素字符串“pop”删除。
(2.4)在第二无序队列中,将第3个元素113删除。
(2.5)在第一无序队列中,将第4个元素3删除,将第5个元素的内容4移动至第4个元素,将第6个元素的内容2移动至第5个元素。
(2.6)将位图中第3个位由1改为0。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!