一种基于局部流形判别分析投影网络的分类方法与流程
本发明涉及图像处理的模式识别技术领域,属于机器学习中流形学习的范畴,具体来说涉及了一种基于局部流形判别分析投影网络的分类方法。
背景技术:
在模式识别领域,提取有效的特征表达是解决分类任务的关键,同时,有效的特征表达可以提高图像识别算法的精度和鲁棒性。早期的特征提取方法可以分为两种:基于局部的和基于全局的,比如,基于局部特征的尺度不变特征转换sift和局部二值模式lbp;基于全局特征的主成分分析pca、线性判别分析lda以及这些方法的变体。虽然这些特征提取方法在提取图像特征时取得了不错的效果,但它们很难能够抓住图像潜在的局部流形判别信息。最近几年,基于深度学习的特征提取方法在一系列分类任务中取得了巨大的成功,由于其先进的网络结构,其分类精度达到了前所未有的水平。因此,大量的研究人员纷纷将视角转向了深度学习提取特征的方法。
深度学习提取特征的方法一般是指深度神经网络,它由多层神经网络构成,可以学习到不同层次特征表达,且不需要大量领域先验知识。自从1989年yanlecun等人在前人的基础上提出了具有bp结构的卷积神经网络(cnn),关于cnn模型的研究逐渐成为热点。在2012年krizhevsky等人将cnn改造成深度卷积神经网络(alexnet),在具有挑战性的imagenet标准数据库取得了不错的结果。后续出现了类似于alexnet的深度网络模型,这些网络相比之前的卷积神经网络具有更深的层次,更复杂的网络结构和更大规模的参数。
然而,卷积神经网络的“黑盒子”性质意味着人们不知道神经网络如何以及为什么产生某种输出。例如,当我们将狗的图像放入神经网络并将其预测为汽车时,很难理解是什么导致它产生这种预测,并且训练过程中涉及了大量的参数,而参数的调整又需要特别的调参技巧。为了提高模型的学习能力,karensimonyan等人在“iclr2015”发表的“verydeepconvolutionalnetworksforlarge-scaleimagerecognition”,christianszegedy等人在“cvpr2015”会议上发表的“goingdeeperwithconvolutions”,以及kaiminghe等人的“deepresiduallearningforimagerecognition”(arxiv:1512.03385)文章都传达一个共同点,即通过增加网络的深度或宽度来增加网络的学习能力。但学习能力不断提升则使模型容易出现过拟合的问题。nitishsrivastava等人在“dropout:asimplewaytopreventneuralnetworksfromoverfitting”一文中提出使用“dropout”解决过拟合问题。后续一些学者提出了其他的策略来解决过拟合问题,比如zeiler在“iclr2013”提出随机卷积策略的思想来代替传统的卷积过程。除了过拟合问题之外,深层卷积神经网络模型非常耗费计算资源,这样会导致在终端部署和低延迟需求场景下难以应用的问题,因此,songhan等人在“iclr2016”发表的“deepcompression:compressingdeepneuralnetworkwithpruning,trainedquantizationandhuffmancoding”一文中提到三种方式(网络剪枝、共享量化权重矩阵、量化值进行huffman编码)对深度神经网络进行压缩,forrestn.iandola1等人在“squeezenet:alexnet-levelaccuracywith50xfewerparametersand<0.5mbmodelsize”文章中提出一个新的模型压缩方法,通过提出的压缩层(squeezelayer)和filemodule单元将cnn模型参数降低50倍,但压缩之后的模型参数依然很大。
上述的深度学习模型可以看作由多层可参数化可微分的非线性模块所组成,通过bp算法来训练整个模型,网络的深度决定模型的复杂度和计算资源的消耗。因此,深度神经网络之所以能够成功离不了以下几个关键因素:1)逐层处理的过程;2)特征的不同层次的内部变化;3)模型要有足够的复杂度;4)拥有更大的训练数据和计算资源。
虽然深度神经网络在相应的分类任务中取得了不错的成绩,但本身固有的结构使其不得不面对由计算复杂度带来的时间消耗。上述也提及了一些模型压缩的方法,但压缩之后的模型参数量依然很大,因此需要找到这样一个模型使其能够在计算机复杂度和计算机资源之间取得一个平衡。
技术实现要素:
本发明的目的是提出一种基于局部流形判别分析投影网络的分类方法,该方法充分利用了样本的已知标签信息和样本点之间的局部结构,找到具有高敏感性的卷积核。本发明由若干阶段的特征卷积层和多尺度特征分析层、特征分类层构成,具体的实施步骤如下:
步骤1:给定ntrain个训练样本,学习判别嵌入空间v
a)根据训练样本xi的标签l(xi)将训练集n(xi)分为两个子集:nw(xi)和nb(xi),nw(xi)是由与xi具有相同标签的k个最近邻训练样本构成,nb(xi)则包含了与xi不同标签的k个最近邻训练样本;即:
b)构建nw(xi)和nb(xi)子集对应的类内子图gw和类间子图gb的权重矩阵:
对于每一类别c,
首先计算类内子图的散度矩阵sw:
其中,v为投影向量,vt是v的转置;x是由
同理,计算类间子图的散度矩阵sb:
因此,判别嵌入空间v通过最小化目标函数
xlbxtv=λxlwxtv
其中,lb是类间拉普拉斯矩阵;最大的l个特征值λ=[λ1,λ2,…,λl]对应的特征矩阵v=[v1,v2,…vl]为学习到的判别嵌入空间;在学习到的判别嵌入空间v中,最显著的特征被保留下来,即在低维判别嵌入空间中,同一类的相邻点彼此接近,不同类别的邻近点相距的更远;
步骤2:构造特征卷积层
a)构建邻接图
设mi是样本xi的k个最近邻集合
其中,上述构建的仿射弧是所要构建邻接图中的节点,在这里使用最近邻算法来构建邻接图;由于欧式距离不能很好的表示流形之间的距离,在寻找k个最近邻的时候使用定义的子空间到子空间的距离度量dssd,dssd定义如下:
其中,v是由步骤1中学习到的判别嵌入空间,vt为v的转置,β为合适的约束常数,ui和uj是横跨整个affinehull的标准正交基,u′j为uj的转置;
b)选择权重w
为了使局部保留映射之后,属于同一类的仿射弧离得更近,不同的类别的仿射弧离得更远,选择类内-类间的局部判别矩阵
其中,α、t为合适的约束常数;εi和εj是仿射弧所在流形的均值向量;um和un是横跨所有对应类别仿射弧的标准正交基,m、n为同一类别放射弧的个数,lb为类间拉普拉斯矩阵,lw为类内拉普拉斯矩阵;
c)优化线性嵌入
假设投影之后的集合是z,通过最小化下面的目标函数,来找合适的映射,在这个映射上属于同一个子空间的流形能够离得更近,不同子空间流形距离的更远;
上式可以化简为:
其中,
因此,具有约束的目标函数如下:
最后,求解投影向量,即:
设求解之后的最小的ni个特征值
步骤3:图像卷积
由步骤2学到的卷积核
以第一阶段的特征图作为第二阶段的输入,分别与第二阶段学习到的卷积核
步骤4:多尺度特征分析
a)二值哈希编码
对第二阶段得到的特征图
b)构建分块直方图
对于每一个特征图
步骤5:图像分类
将测试集经过图像卷积、多尺度分析步骤之后得到的特征fi,输入到由训练集训练得到svm模型进行分类。
本发明提出了一种基于局部流形判别分析投影网络的分类方法,它对卷积核进行改造,经过改造之后的卷积核能够发现原始图像最有代表性的特征,同时具有高敏感的判别能力。在小样本的情况下,该方法也能表现出较好的判别性和适应性。输入图像与改造之后的卷积核进行卷积并学习到具有代表性的判别特征,经过多尺度特征分析层输出特征,完成特征提取之后,特征表达被送入分类模型进行分类。由于图像识别易受拍摄的光照、角度和等因素的影响,本发明建立了一个基于仿射弧的子空间流形模型,使同一类的图像更紧凑的位于同一个流形上,不同类别的图像位于不同的流形上,在此基础上提出了一个新的流形子空间图像距离度量dssd,为子空间在构建邻接图提供了距离度量,同时判别嵌入空间v和类内-类间的局部判别矩阵giiwdm引入,增加了卷积核对不同类别的敏感度。
本发明与现有的技术相比具有较小的训练时间、较高的识别准确度,同时具有自适应性和良好的扩展性。
附图说明
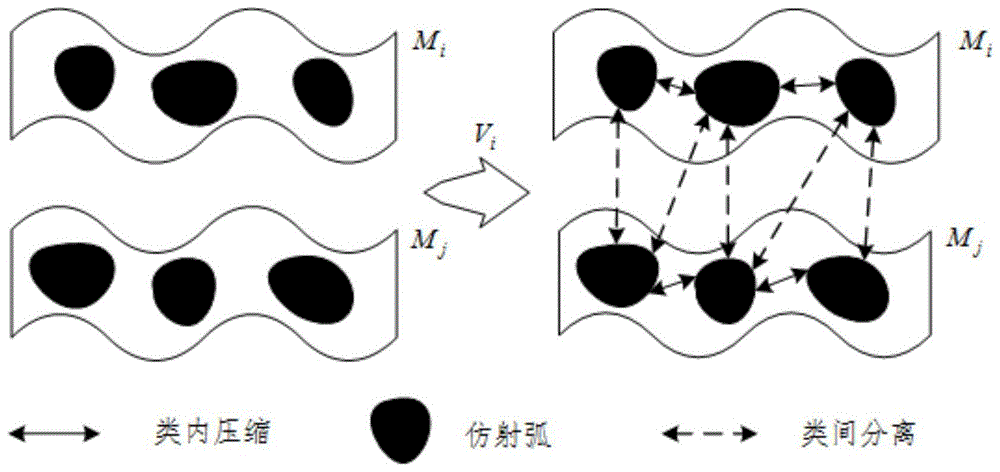
图1为本发明卷积之后不同流形之间的空间关系图;
图2为本发明的流程图。
具体实施方式
以下结合附图对本发明进行详细说明,实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公知常识,本发明没有特别限制内容。
本发明的基于局部流形判别分析投影网络的分类方法,首先,对输入图像构建判别嵌入空间v,设{(xi,li)i=1,2,…,ntrain}是训练集图像的集合,xi∈rm×n表示第i个训练图像,li=1,2,…,c代表训练图像xi的类别标签,从分类的角度考虑,本发明利用原始图像已知的标签信息构建一个类内-类间图的局部判别矩阵giiwdm,在这里构建的giiwdm和拉普拉斯特征映射找到最佳的投影向量不同,这里的类内-类间图的判别矩阵giiwdm保留了流形之间的结构信息,并在不同类样本点之间赋予了不同的权重因子,同时新定义一个子空间到子空间的度量距离dssd,具体的步骤如下:
根据训练样本xi的标签l(xi)将训练集n(xi)分为两个子集:nb(xi)和nw(xi),nw(xi)是由与xi具有相同标签的k个最近邻训练样本构成,nb(xi)则包含了与xi不同标签的k近邻训练样本。即,
其中nb(xi)∩nw(xi)=φ,nb(xi)∪nw(xi)=n(xi)。假设两个子集nb(xi)和nw(xi)构成的子图为
首先计算类内子图的散度矩阵sw:
其中,dw为对角矩阵,即
同理,计算类间子图的的散度矩阵sb:
因此,判别嵌入空间v可以通过最大化目标函数
xlbxtv=λxlwxtv
在这里定义类内-类间的局部判别矩阵giiwdm如下:
本发明使用改进的局部保留映射(localitypreservingprojecting,lpp)来构造卷积核。与从全局统计角度考虑的主成分分析(principlecomponentanalysis,pca)和线性判别分析(lineardiscriminatanalysis,lda)不同,本发明能够发现外围空间的子流形的潜在结构并保持原始空间数据点的局部信息,同时保持敏感的判别性。本发明构造的卷积核能够学习到数据低维流形的内在几何分布,对小样本同样具有适应性,由于判别嵌入空间v和类内-类间的局部判别矩阵giiwdm引入,使卷积核的具有了判别能力,同时本发明提出了一个新的距离度量dssd,与使用欧式距离作为距离度量相比,该距离度量增强了卷积核对不同类别样本之间的判别能力。
具体的构造卷积核的步骤如下:
设样本点xi最近的k个样本点nw位于的子空间流形为mi,为了更清楚的表示,图1描述了卷积之后不同流形之间的空间关系。在这里使用类内-类间图的判别矩阵giiwdm作为lpp的热核(heatkernel)输入,从而使同类流形之间的距离能够离得更近,不同类别流形之间的距离更远。
设mi是样本xi的k个最近邻集合
假设投影之后的集合是z,通过最小化下面的目标函数,来找的合适的映射,在这个映射上属于同一个子空间的流形能够离得更近,不同的子空间流形距离的更远。
上述可以化简为:
其中,
因此,得到具有约束的目标函数:
最后,求解投影向量,即:
设求解之后的最小的ni个特征值
图像卷积:
由学到的卷积核
以第一阶段的特征图作为第二阶段的输入,分别与第二阶段学习到的卷积核
多尺度特征分析:
a.二值哈希编码:
对第二阶段得到的特征图
b.构建分块直方图
对于每一个特征图
图像分类步骤:
将测试集经过图像卷积、多尺度分析步骤之后得到的特征fi,输入到由训练集训练得到svm模型进行分类。
实施例
以下结合具体实施例对本发明技术方案做详细说明。
如图2所示,本发明提出的模型包含了卷积层、多尺度特征分析层、特征分类层。但本模型只需要一次的前向的传播过程即可以学到合适的卷积核,简化了深度神经网络调参的过程,同时减少了模型的运行时间。
假设有ntrain个训练样本图像
1)第一阶段(构造图像集):对训练图像xj进行预处理生成多个原始图像的副本(imagesets),在这里将imagesets表示为
2)第一阶段(构造卷积核):将ntrain个训练样本图像,按照本发明给出的构造卷积核的方法得到第一阶段的n1卷积核
3)第一阶段(卷积操作)由第一阶段学到的卷积核为
4)第二阶段(构造卷积核):与第一阶段构造卷积核过程类似,将ntrain×n1个特征图
5)第二阶段(卷积操作)由第二阶段学到的卷积核为
6)输出阶段(多尺度特征分析):对于第二阶段输出的特征图
7)将于每一个特征图
8)将步骤7到的多尺度特征fi训练svm模型。
9)对利用训练阶段得到的svm模型对测试样本进行分类。
- 还没有人留言评论。精彩留言会获得点赞!