一种基于ELMAN神经网络的用户体验评价方法及系统与流程
本发明涉及大数据领域,具体涉及一种基于elman神经网络的用户体验评价方法及系统。
背景技术:
如今,各种app软件产品的开发层出不穷,一个app软件产品是否能够成功,用户体验逐渐变成了一个关键因素。大数据已成为提升用户体验的重要参考工具,有效的数据挖掘和分析可以被企业用来提升现有产品的用户体验,通过上述结果来开发新的产品和服务。有针对性的采取用户体验措施,从而使用户在心理上有一个良好的用户体验,但是用户体验结果很难用一种直观、真实的方式表达出来,然而表情是人类用来表达各种情绪状态最直观、最真实的一种方式,是一种十分重要的非语言交流手段。
现有技术在app软件研发过程中,采用传统用户调查的方式,无法快速准确获取新研发app软件的用户使用体验数据,研发效率较低。
技术实现要素:
为了解决现在产品研发过程中,研发人员不能快速获取新研发app用户体验数据的问题,本申请提供一种基于elman神经网络的用户体验评价方法,包括以下步骤
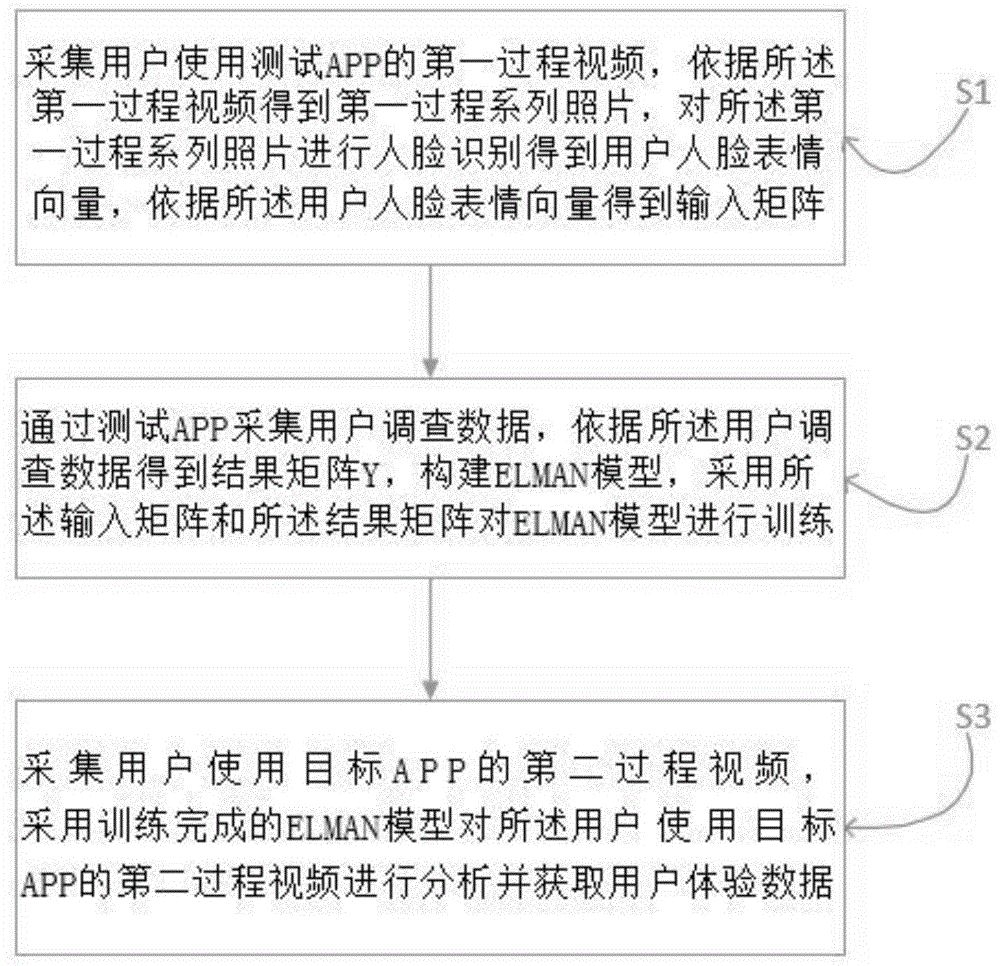
s1:采集用户使用测试app的第一过程视频,依据所述第一过程视频得到第一过程系列照片,对所述第一过程系列照片进行人脸识别得到用户人脸表情向量,依据所述用户人脸表情向量得到输入矩阵;
s2:通过测试app采集用户调查数据,依据所述用户调查数据得到结果矩阵y,构建elman模型,采用所述输入矩阵和所述结果矩阵对elman模型进行训练;
s3:采集用户使用目标app的第二过程视频,采用训练完成的elman模型对所述用户使用目标app的第二过程视频进行分析并获取用户体验数据。进一步的,所述步骤s1包括,
s11:以横坐标为时间,纵坐标为表情类型代码生成用户人脸表情向量随时间变化的二维表情谱,其中,“愤怒”对应的表情向量为[0,0,0,0,0,0,1]t、“厌恶”对应的表情向量为[0,0,0,0,0,2,0]t、“恐惧”对应的表情向量为[0,0,0,0,3,0,0]t、“高兴”对应的表情向量为[0,0,0,4,0,0,0]t、“伤心”对应的表情向量为[0,0,5,0,0,0,0]t、“惊讶”对应的表情向量为[0,6,0,0,0,0,0]t、“无情绪”对应的表情向量为[7,0,0,0,0,0,0]t,采用表情谱得到矩阵a=[e1,e2,e3,…,en]7×n;
s12:将矩阵a进行转置变换得到at=[e1,e2,e3,…,en]n×7;
s13:构造矩阵m=a·at;
s14:计算矩阵m的特征值,生成矩阵m的特征值矩阵λ=[λ1,λ2,λ3,…,λ7]1×7;
s15:生成输入矩阵x=[λ,n,b]1×9,其中n为年龄,b为性别。
进一步的,步骤s2中,设置xk=[xk1,xk2,…,xkm](k=1,2,…,s)为输入矢量,s为训练样本个数,wmi(g)为第g次迭代时输入层m与隐层i之间的权值矢量,wjp(g)为第g次迭代时隐层j与输出层p之间的权值矢量,wjc(g)为第g次迭代时隐层j与承接层c之间的权值矢量,yk(g)=[yk1(g),yk2(g),…,ykp(g)](k=1,2,…,s)为第g次迭代时网络的实际输出,dk=[dk1,dk2,…,dkp](k=1,2,…,s)为期望输出。
进一步的,所述步骤s2包括
s21:初始化,设迭代次数g初值为0,分别赋给wmi(0)、wjp(0)wjc(0)一个(0,1)区间的随机值;
s22:随机输入样本xk;
s23:对输入样本xk,前向计算神经网络每层神经元的输入信号和输出信号;
s24:根据期望输出dk和实际输出yk(g),计算误差e(g);
s25:判断误差e(g)是否满足要求,如不满足,则进入步骤s26,如满足,则进入步骤s29;
s26:判断迭代次数g+1是否大于最大迭代次数,如大于,则进入步骤s29,否则,进入步骤s27;
s27:对输入样本xk反向计算每层神经元的局部梯度δ;
s28:计算权值修正量δw,并修正权值;令g=g+1,跳转至步骤s23;
s29:判断是否完成所有的训练样本,如果是,则完成建模,否则,继续跳转至步骤s22。
进一步的,所述步骤s3还包括,
将用户体验数据发送至管理员移动终端并进行展示。
为了保证上述方法的实施,本发明还提供一种基于elman神经网络的用户体验评价系统,其特征在于,包括以下模块
采集模块,用于采集用户使用测试app的第一过程视频,依据所述第一过程视频得到第一过程系列照片,对所述第一过程系列照片进行人脸识别得到用户人脸表情向量,依据所述用户人脸表情向量得到输入矩阵;
训练模块,用于通过测试app采集用户调查数据,依据所述用户调查数据得到结果矩阵y,构建elman模型,采用所述输入矩阵和所述结果矩阵对elman模型进行训练;
结果输出模块,采集用户使用目标app的第二过程视频,采用训练完成的elman模型对所述用户使用目标app的第二过程视频进行分析并获取用户体验数据。
进一步的,所述采集模块采用以下步骤获取输入矩阵,
s11:以横坐标为时间,纵坐标为表情类型代码生成用户人脸表情向量随时间变化的二维表情谱,其中,“愤怒”对应的表情向量为[0,0,0,0,0,0,1]t、“厌恶”对应的表情向量为[0,0,0,0,0,2,0]t、“恐惧”对应的表情向量为[0,0,0,0,3,0,0]t、“高兴”对应的表情向量为[0,0,0,4,0,0,0]t、“伤心”对应的表情向量为[0,0,5,0,0,0,0]t、“惊讶”对应的表情向量为[0,6,0,0,0,0,0]t、“无情绪”对应的表情向量为[7,0,0,0,0,0,0]t,采用表情谱得到矩阵a=[e1,e2,e3,…,en]7×n;
s12:将矩阵a进行转置变换得到at=[e1,e2,e3,…,en]n×7;
s13:构造矩阵m=a·at;
s14:计算矩阵m的特征值,生成矩阵m的特征值矩阵λ=[λ1,λ2,λ3,…,λ7]1×7;
s15:生成输入矩阵x=[λ,n,b]1×9,其中n为年龄,b为性别。
进一步的,所述训练模块设置xk=[xk1,xk2,…,xkm](k=1,2,…,s)为输入矢量,s为训练样本个数,wmi(g)为第g次迭代时输入层m与隐层i之间的权值矢量,wjp(g)为第g次迭代时隐层j与输出层p之间的权值矢量,wjc(g)为第g次迭代时隐层j与承接层c之间的权值矢量,yk(g)=[yk1(g),yk2(g),…,ykp(g)](k=1,2,…,s)为第g次迭代时网络的实际输出,dk=[dk1,dk2,…,dkp](k=1,2,…,s)为期望输出。
进一步的,所述训练模块采用以下步骤对elman模型进行训练:
s21:初始化,设迭代次数g初值为0,分别赋给wmi(0)、wjp(0)wjc(0)一个(0,1)区间的随机值;
s22:随机输入样本xk;
s23:对输入样本xk,前向计算神经网络每层神经元的输入信号和输出信号;
s24:根据期望输出dk和实际输出yk(g),计算误差e(g);
s25:判断误差e(g)是否满足要求,如不满足,则进入步骤s26,如满足,则进入步骤s29;
s26:判断迭代次数g+1是否大于最大迭代次数,如大于,则进入步骤s29,否则,进入步骤s27;
s27:对输入样本xk反向计算每层神经元的局部梯度δ;
s28:计算权值修正量δw,并修正权值;令g=g+1,跳转至步骤s23;
s29:判断是否完成所有的训练样本,如果是,则完成建模,否则,继续跳转至步骤s22。
进一步的,所述结果输出模块还用于,将用户体验数据发送至管理员移动终端并进行展示。
本发明的有益效果是,
1遵循神经和肌肉等解剖学,具有共同特征;表情识别是一种无意识、自由状态下的数据获取方法,保证了数据的可靠性与客观性。
2容易整合到数据分析系统进行分析和可视化。
3允许其他软件实时访问面部表情分析系统的数据收集。
4能够分析所有种族的面部表情,包括儿童的面部表情。
5本发明通过训练完成的神经网络模型来对用户在使用app过程的视频进行分析快速得出用户体验数据,可以方便研发人员快速对新研发app进行评估,提高了app的研发效率。
附图说明
图1为本发明一种基于elman神经网络的用户体验评价方法流程图。
图2为本发明一种基于elman神经网络的用户体验评价系统结构示意图。
图3为本发明一实施例二维表情谱示意图。
图4为本发明一实施例elman神经网络示意图。
具体实施方式
在下面的描述中,出于说明的目的,为了提供对一个或多个实施例的全面理解,阐述了许多具体细节。然而,很明显,也可以在没有这些具体细节的情况下实现这些实施例。
针对产品研发过程中,研发人员不能快速获取新研发app用户体验数据的问题,本发明一种基于elman神经网络的用户体验评价方法及系统
本发明通过采集用户视频和用户调查数据对elman模型进行训练,通过训练完成的elman模型对用户使用新研发app的视频识别,快速获取用户的用户体验数据。
其中,需要说明的是,elman网络可以看作是一个具有局部记忆单元和局部反馈连接的递归神经网络。
以下将结合附图对本发明的具体实施例进行详细描述。
为了说明本发明提供的基于elman神经网络的用户体验评价方法,图1示出了本发明一种基于elman神经网络的用户体验评价方法流程图。
如图1所示,本发明提供的一种基于elman神经网络的用户体验评价方法包括以下步骤,s1:采集用户使用测试app的第一过程视频,依据所述第一过程视频得到第一过程系列照片,对所述第一过程系列照片进行人脸识别得到用户人脸表情向量,依据所述用户人脸表情向量得到输入矩阵;
s2:通过测试app采集用户调查数据,依据所述用户调查数据得到结果矩阵y,构建elman模型,采用所述输入矩阵和所述结果矩阵对elman模型进行训练;
s3:采集用户使用目标app的第二过程视频,采用训练完成的elman模型对所述用户使用目标app的第二过程视频进行分析并获取用户体验数据。
第一过程视频,第一过程系列照片均为用于训练神经网络模型的训练数据,第二过程视频为待检测数据,采用已经训练好的神经网络对第二过程视频进行分析获取第二过程视频对应的用户体验数据。
测试app安装于用户手机端用于获取用户使用测试app的第一过程视频和调查结果数据,测试app通过用户手机端的前置摄像头获取用户使用测试app的第一过程视频。测试app在完成测试后直接通过用户输入来获取用户使用测试app过程的调查结果数据。
目标app为待检测的新研发app,在用户使用目标app的过程中,测试app通过用户手机端的前置摄像头获取用户第二过程视频。
测试app的测试内容与目标app为同一类型的内容,例如,如果目标app为游戏类app,则测试app通过一段模拟游戏来获取用户玩游戏过程中的第一过程视频,若目标app为音乐播放类app,则测试app通过一段模拟音乐播放来获取用户听音乐过程中的第一过程视频,测试app使用与目标app同一类型的测试内容,使得神经网络训练更加有针对性,提高了通过神经网络获取目标app用户体验数据的准确性。
本发明采集用户的第一过程视频和调查结果来对神经网络进行训练,神经网络训练好后,输入同一用户的第二过程视频获取该用户的用户体验数据。相对于传统的采用多个用户数据进行神经网络训练,训练好的神经网络对多个不同用户数据进行测试的方式,本发明针对每一个用户训练一个神经网络,每个用户都有自已特定的神经网络参数,本发明相对于现有技术中的通用神经网络产品具有更高的结果检测准确性。
在本发明实施过程中步骤s1包括,获取用户在使用测试app的过程视频(可以通过手机app现场拍摄或者读取视频文件)传输到云端,在云端把该视频分解成连续的系列照片,应用人脸识别技术,识别该系列照片对应的人脸表情,获得表情随时间变化的代码向量(7种表情类型愤怒、厌恶、恐惧、高兴、伤心、惊讶、无情绪分别对应的代码为1、2、3、4、5、6、7)、年龄n(岁)、性别b(男/女对应代码为1/0)对该数据矩阵作以下处理,获得输入矩阵x;
具体的,在本发明一实施例中步骤s1包括,
s11:画出表情代码向量随时间变化的二维表情谱,其中,横坐标为时间,纵坐标为表情类型代码1-7,得到“愤怒”对应的表情向量为[0,0,0,0,0,0,1]t、“厌恶”对应的表情向量为[0,0,0,0,0,2,0]t、“恐惧”对应的表情向量为[0,0,0,0,3,0,0]t、“高兴”对应的表情向量为[0,0,0,4,0,0,0]t、“伤心”对应的表情向量为[0,0,5,0,0,0,0]t、“惊讶”对应的表情向量为[0,6,0,0,0,0,0]t、“无情绪”对应的表情向量为[7,0,0,0,0,0,0]t;利用表情谱得到矩阵a=[e1,e2,e3,…,en]7×n(en为七种表情向量之一)。例如,当n=10时,e=[5,7,6,6,4,4,4,4,6,7];画出表情代码矩阵随时间的表情谱如图3所示,由表情谱得到表情谱矩阵a:
s12:将矩阵a进行转置变换得到at=[e1,e2,e3,…,en]n×7;
s13:构造新的矩阵为m=a·at;
s14:计算出矩阵m的特征值,其征值矩阵为λ=[λ1,λ2,λ3,…,λ7]1×7;
s15:输入参数矩阵由矩阵特征值、性别、年龄构成x=[λ,n,b]1×9。
在本发明实施过程中步骤s2包括,调查用户该视频过程的真实用户体验,选择分数1分、2分、3分、4分、5分(分别对应体验过程很差、差、一般、好、很好)之一作为体验测试结果,并作为输出结果y;应用大量输入矩阵x与对应输出结果矩阵y,利用elman神经网络进行建模,elman在结构上由四层构成,分别为输入层、模式层、求和层和输出层。输入层神经元的数目等于学习样本中输入向量的维数,各神经元是简单的分布单元,直接将输入变量传递给模式层。模式层神经元数目等于学习样本的数目n,各神经元对应不同的样本。求和层中使用两种类型神经元进行求和。输出层中的神经元数目等于学习样本中输出向量的维数k,各神经元将求和层的输出相除,经元j的输出对应估计结果y(x)的第j个元素。
在本发明实施过程中,步骤s2中,设置xk=[xk1,xk2,…,xkm](k=1,2,…,s)为输入矢量,s为训练样本个数,wmi(g)为第g次迭代时输入层m与隐层i之间的权值矢量,wjp(g)为第g次迭代时隐层j与输出层p之间的权值矢量,wjc(g)为第g次迭代时隐层j与承接层c之间的权值矢量,yk(g)=[yk1(g),yk2(g),…,ykp(g)](k=1,2,…,s)为第g次迭代时网络的实际输出,dk=[dk1,dk2,…,dkp](k=1,2,…,s)为期望输出。
在本发明实施过程中步骤s2包括以下步骤,
s21:初始化,设迭代次数g初值为0,分别赋给wmi(0)、wjp(0)wjc(0)一个(0,1)区间的随机值;
s22:随机输入样本xk;
s23:对输入样本xk,前向计算神经网络每层神经元的输入信号和输出信号;
s24:根据期望输出dk和实际输出yk(g),计算误差e(g);
s25:判断误差e(g)是否满足要求,如不满足,则进入步骤s26,如满足,则进入步骤s29;
s26:判断迭代次数g+1是否大于最大迭代次数,如大于,则进入步骤s29,否则,进入步骤s27;
s27:对输入样本xk反向计算每层神经元的局部梯度δ;
s28:计算权值修正量δw,并修正权值;令g=g+1,跳转至步骤s23;
s29:判断是否完成所有的训练样本,如果是,则完成建模,否则,继续跳转至步骤s22。
在本发明实施过程中,步骤s3包括上述训练好的elman模型放入云端,把该过程开发成软件;对于新研发的app,只要录入视频即可自动获得该用户使用新研发app过程的用户体验评价结果,对公司进行产品升级优化结果进行评价。
应当指出的是,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的普通技术人员在本发明的实质范围内所做出的变化、改性、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!