一种人工神经网络压缩编码装置和方法与流程
本发明涉及人工神经网络处理技术领域,更具体地涉及一种人工神经网络压缩编码装置和方法,尤其是涉及执行人工神经网络算法方法的执行单元或包含这些执行单元的设备,以及多层人工神经网络运算、反向传播训练算法及其压缩编码的装置和方法的执行单元或包括这些执行单元的设备。
背景技术:
多层人工神经网络被广泛应用于模式识别、图像处理、函数逼近和优化计算等领域。特别是近年来由于反向传播训练算法,以及预训练算法的研究不断深入,多层人工神经网络由于其较高的识别准确度和较好的可并行性,受到学术界和工业界越来越广泛的关注。
随着人工神经网络计算量和访存量的急剧增大,现有技术中通常采用通用处理器来对多层人工神经网络运算、训练算法及其压缩编码进行处理,通过使用通用寄存器堆和通用功能部件执行通用指令来支持上述算法。采用通用处理器的缺点之一是单个通用处理器的运算性能较低,无法满足通常的多层人工神经网络运算的性能需求。而多个通用处理器并行执行时,通用处理器之间相互通讯又成为了性能瓶颈;此外,通用处理器需要把多层人工神经网络运算译码成一长列运算及访存指令序列,处理器前端译码带来了较大的功耗开销。另一种支持多层人工神经网络运算、训练算法及其压缩编码的已知方法是使用图形处理器(gpu)。该方法通过使用通用寄存器堆和通用流处理单元执行通用simd指令来支持上述算法。由于gpu是专门用来执行图形图像运算以及科学计算的设备,没有对多层人工神经网络运算的专门支持,仍然需要大量的前端译码工作才能执行多层人工神经网络运算,带来了大量的额外开销。另外gpu只有较小的片上缓 存,多层人工神经网络的模型数据(权值)需要反复从片外搬运,片外带宽成为了主要性能瓶颈,同时带来了巨大的功耗开销。
技术实现要素:
针对上述现有技术的不足,本发明的目的在于提供一种人工神经网络压缩编码装置和方法。
为了实现上述目的,作为本发明的一个方面,本发明提出了一种人工神经网络压缩编码装置,包括:
内存接口单元,用于输入数据和指令;
指令缓存,用于对指令进行缓存;
控制器单元,用于从所述指令缓存中读取指令,并将其译码成运算单元的指令;以及
运算单元,用于根据所述控制器单元的指令对来自所述内存接口单元的数据执行相应的运算;所述运算单元主要执行三步运算,第一步是将输入的神经元和权值数据相乘;第二步执行加法树运算,用于将第一步处理后的加权输出神经元通过加法树逐级相加,或者将输出神经元通过和偏置相加得到加偏置输出神经元;第三步执行激活函数运算,得到最终输出神经元。
其中,所述运算单元中对于输入的权值数据表示如下:
若是正向运算过程,则所述权值数据w1由k比特数据表示,其中包括1比特符号位、m比特控制位以及n比特数据位,即k=1+m+n;其中k、m、n均为自然数;
若是反向运算过程,则所述权值数据w2使用浮点数表示。
其中,所述w1是从w2转换而来,其中反向运算过程的权值数据w2具有len位有效数字,正向运算过程的权值数据w1中的n表示w1中的有效数字位数,n≤len;控制位m用于指定w1的有效数字在原权值数据中的起始位置。
作为本发明的另一个方面,本发明还提出了一种采用如上所述的用于压缩编码的人工神经网络计算装置进行的人工神经网络压缩编码方法,包括以下步骤;
步骤1:控制器单元从指令缓存中读取一条多层人工神经网络运算simd指令;
步骤2:所述控制器单元将所述指令译码成各个功能部件的微指令,包括输入神经元缓存是否读写以及读写次数、输出神经元缓存是否读写以及读写次数、权值神经元缓存是否读写以及读写次数、运算单元各个阶段执行何种操作;
步骤3:运算单元得到从输入神经元缓存和权值缓存的输入向量,根据阶段一的操作码,决定是否执行向量乘法运算,如果执行就将结果发送到下一阶段,否则直接将输入发送到下一阶段;
步骤4:所述运算单元根据阶段二的操作码,决定是否进行加法树运算,如果执行就将结果发送到下一阶段,否则直接将输入发送到下一阶段;
步骤5:所述运算单元根据阶段三的操作码,决定是否进行激活函数的运算,如果执行就将结果发送给输出神经元缓存。
作为本发明的再一个方面,本发明还提出了一种采用如上所述的用于压缩编码的人工神经网络计算装置进行的人工神经网络反向传播训练的方法,包括以下步骤;
步骤1:控制器单元从指令缓存中读取一条多层人工神经网络训练算法simd指令;
步骤2:所述控制器单元将所述指令译码成各个运算单元的微指令,包括输入神经元缓存是否读写以及读写次数、输出神经元缓存是否读写以及读写次数、权值神经元缓存是否读写以及读写次数、运算单元各个阶段执行何种操作;
步骤3:运算单元得到从输入神经元缓存和权值缓存的输入向量,根据阶段一的操作码,决定是否执行向量乘法运算,如果执行就将结果发送到下一阶段,否则直接将输入发送到下一阶段;
步骤4:所述运算单元根据阶段二的操作码,决定是否进行加法树运算、向量加法运算或权值更新运算。
作为本发明的还一个方面,本发明还提出了一种采用如上所述的用于压缩编码的人工神经网络计算装置进行的人工神经网络计算方法,包括以下步骤:
步骤1:将存储的浮点权值w1转换成位数较少的表示w2;
步骤2:使用w2进行正向运算;
步骤3:根据正向运算得到的误差结果进行反向运算更新w1;
步骤4:迭代执行上述三个步骤,直到得到所需要的模型。
基于上述技术方案可知,本发明提供了一种用于执行多层人工神经网络运算、反向传播训练算法及其压缩编码的装置和方法,提高了对于多层人工神经网络运算及其反向传播训练算法的性能,同时降低了权值数据表示的位数,以达到压缩编码的目的。本发明不仅能有效减小人工神经网络的模型大小,提高人工神经网络的数据处理速度,而且能有效降低功耗,提高资源利用率;相对于现有的技术,具有显著的性能和功耗改善,并能大幅压缩权值数据。
附图说明
图1是根据本发明一实施例的神经网络正向运算的示例框图;
图2是根据本发明一实施例的神经网络反向训练算法的示例框图;
图3是根据本发明一实施例的总体结构的示例框图;
图4是根据本发明一实施例的加速器芯片结构的示例框图;
图5是根据本发明一实施例的多层人工神经网络的运算流程图;
图6是根据本发明一实施例的多层人工神经网络反向传播训练算法的流程图;
图7是根据本发明一实施例的多层人工神经网络压缩编码算法的流程图。
具体实施方式
将参考以下所讨论的细节来描述本发明的各实施例和方面,并且所附附图将说明各实施例。下列描述和附图是用于说明本发明的,并且不应当被解释为限制本发明。描述许多具体的细节以提供对本发明的各实施例的透彻理解。然而,在某些实例中,不描述公知的或寻常的细节,以便提供本发明的实施例的简洁的讨论。
说明书中提到的“一个实施例”或“一实施例”意思是结合实施例所描述的特定的特征、结构或特性能够被包括在本发明的至少一个实施例中。在本说明书的多处出现的短语“在一个实施例中”不一定全部都指同一个实施例。
本发明涉及的多层人工神经网络运算及其压缩编码,包括两层或者两层以上的多个神经元。对于每一层来说,输入神经元向量首先和权值向量进行点积运算,结果经过激活函数得到输出神经元。其中激活函数可以是sigmoid函数、tanh函数、relu函数和softmax函数等。此外,多层人工神经网络的训练算法包括正向传播、反向传播和权值更新等步骤。
在正向运算过程中,神经网络权值w1由k比特数据表示,其中包括1比特符号位、m比特控制位以及n比特数据位(k=1+m+n)。
反向运算过程中的权值w2使用浮点数表示。
正向运算过程中使用的权值数据表示方法,从反向运算过程使用的浮点权值表示(len位有效数字)转换而来,数据位存储原权值数据中的n位有效数字,n小于等于len。控制位用于指定数据位在原有效数字中的起始位置;由于正向运算过程中使用的权值数据表示方法所使用的总数据位数少于反向训练运算过程中使用的权值表示的总数据位数,从而可以达到压缩编码的作用。
本发明的用于执行人工神经网络运算、反向传播训练算法及其压缩编码的人工神经网络压缩编码装置,包括指令缓存单元、输入神经元缓存单元、权值缓存单元、控制单元、运算单元、输出神经元缓存单元、内存接口单元和直接内存访问通道单元;
其中,指令缓存单元用于缓存指令;
输入神经元缓存单元用于缓存输入神经元数据;
权值缓存单元用于缓存权值;
控制单元用于从指令缓存中读取专用指令,并将其译码成微指令;
运算单元用于接受从控制器单元发出的微指令并进行算术逻辑运算;
输出神经元缓存单元用于缓存输出神经元数据;
内存接口单元用于数据读写通道;
直接内存访问通道单元用于从内存向各缓存中读写数据。
上述指令缓存单元、输入神经元缓存单元、权值缓存单元和输出神经元缓存单元等中使用的缓存可以为ram。
在上述运算单元中主要执行三步运算,第一步是将输入的神经元和权值数据相乘,表示如下:
将输入神经元(in)通过运算(f)得到输出神经元(out),过程为:out=f(in)2
将输入神经元(in)通过和权值(w)相乘得到加权输出神经元(out),过程为:out=w*in;
第二步执行加法树运算,用于将第一步处理后的加权输出神经元通过加法树逐级相加,或者将输出神经元通过和偏置相加得到加偏置输出神经元,表示如下:
将输出神经元(in)通过和偏置(b)相加得到加偏置输出神经元(out),过程为:out=in+b;
第三步执行激活函数运算,得到最终输出神经元,表示如下:
将输出神经元(in)通过激活函数(active)运算得到激活输出神经元(out),过程为:out=active(in),激活函数active可以是sigmoid函数、tanh函数、relu函数或softmax函数等;
将加权输出神经元(in)通过激活函数(active)运算得到激活输出神经元(out),过程为:out=active(in);
将加偏置输出神经元(in)通过激活函数(active)运算得到激活输出神经元(out),过程为:out=active(in)。
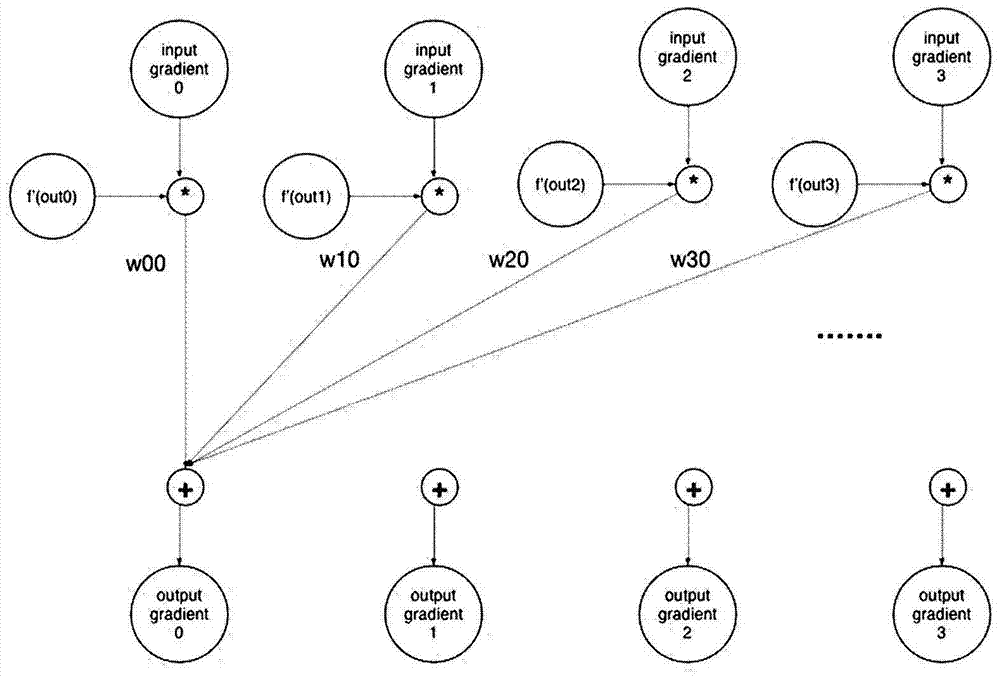
在执行人工神经网络反向训练运算时,运算过程表示如下:
将输入梯度(g)通过加权运算(f)得到输出梯度(g’),过程为:g’=f(g);
将输入梯度(g)通过更新运算(update)得到权值改变(deltaw),过程为:deltaw=update(g);
将输入权值(w)和权值改变(deltaw)相加得到输出权值(w’),过程为:w’=w+deltaw;
将输入梯度(g)通过更新运算(update)得到偏置改变(deltab),过程为:deltab=update(g);
将输入偏置(b)和偏置改变(deltab)相加得到输出偏置(b’),过程为:b’=b+deltab;
其中,在执行人工神经网络反向训练运算时,所有数据使用浮点数表示。
上述人工神经网络压缩编码装置,包括可执行卷积人工神经网络运算的装置、可执行池化人工神经网络运算的装置、可执行lrn人工神经网络运算的装置及可执行全连接人工神经网络运算的装置。
下面结合附图和具体实施例对本发明的技术方案进行进一步的阐释说明。
图3示出了根据本发明一实施例的总体结构的示意性框图。
i/o接口(1),用于i/o数据需要经过cpu(3)发给加速器芯片,然后由加速器芯片(4)写入内存,加速器芯片(4)需要的专用程序也是由cpu(3)传输到加速器芯片。
内存(2),用于暂存多层人工神经网络模型和神经元数据,特别是当全部模型无法在加速器片上缓存中放下时。
中央处理器cpu(3),用于进行数据搬运以及加速器芯片(4)启动停止等基本控制,作为加速器芯片(4)与外部控制的接口。
加速器芯片(4),用于执行多层人工神经网络运算及其反向传播训练算法模块,接受来自cpu(3)的数据和程序,执行上述多层人工神经网络运算及其反向传播训练算法,加速器芯片(4)执行结果将传输回cpu(3)。
通用系统架构。将加速器作为cpu或者gpu的协处理器来执行多层人工神经网络运算及其反向传播训练算法。
多加速器互联的系统结构。多个加速器可以通过pcie总线互联,以支持更大规模的多层人工神经网络运算,可以共用同一个宿主cpu或者分别有自己的宿主cpu,可以共享内存也可以每个加速器有各自的内存。此外其互联方式可以是任意互联拓扑。
图4示出了根据本发明一实施例的加速器芯片结构的示意性框图。
其中输入神经元缓存(2)存储一层运算的输入神经元。
其中输出神经元缓存(5)存储一层运算的输出神经元。
权值缓存(8)存储模型(权值)数据。
直接内存访问通道(7)用于从内存(6)向各ram中读写数据。
指令缓存(1)用于储存专用指令。
控制器单元(3)从指令缓存中读取专用指令,并将其译码成各运算单元的微指令。
运算单元(4)用于执行具体运算。运算单元主要被分为三个阶段,第一阶段执行乘法运算,用于将输入的神经元和权值数据相乘。第二阶段执行加法树运算,第一、二两阶段合起来完成了向量内积运算。第三阶段执行激活函数运算,激活函数可以是sigmoid函数、tanh函数等。第三阶段得到输出神经元,写回输出神经元缓存。
图5绘示出根据本发明一实施例的多层人工神经网络的运算流程图,图1为所执行运算的一个示例。
步骤1:控制器从指令缓存中读取一条多层人工神经网络运算simd指令,例如多层感知机(mlp)指令、卷积指令、池化(pooling)指令等执行专门神经网络算法的指令,或者矩阵乘指令、向量加指令、向量激活函数指令等用于执行神经网络运算的通用向量/矩阵指令。
步骤2:控制器将该指令译码成各个功能部件的微指令,包括输入神经元缓存是否读写以及读写次数,输出神经元缓存是否读写以及读写次数,权值神经元缓存是否读写以及读写次数,运算单元各个阶段执行何种操作。
步骤3:运算单元得到从输入神经元缓存和权值缓存的输入向量,根据阶段一的操作码,决定是否执行向量乘法运算,并将结果发送到下一阶段(如不进行乘法运算则直接将输入发到下一阶段)。
步骤4:运算单元得到阶段一的输出,根据阶段二的操作码,决定是否进行加法树运算,并将结果发送到下一阶段(如不进行加法树操作,则直接将输入发送到下一阶段)。
步骤5:运算单元得到阶段二的输出,根据阶段三的操作码,决定是否进行激活函数的运算,并将结果发送给输出神经元缓存。
图6绘示出根据本发明一实施例的多层人工神经网络反向传播训练算法的流程图,图2为所执行运算的一个示例。
步骤1:控制器从指令缓存中读取一条多层人工神经网络训练算法simd指令。
步骤2:控制器将该指令译码成各个运算单元的微指令,包括输入神经元缓存是否读写以及读写次数,输出神经元缓存是否读写以及读写次数,权值神经元缓存是否读写以及读写次数,运算单元各个阶段执行何种操作。
步骤3:运算单元得到从输入神经元缓存和权值缓存的输入向量,根据阶段一的操作码,决定是否执行向量乘法运算,并将结果发送到下一阶段(如不进行乘法运算则直接将输入发到下一阶段)。
步骤4:运算单元得到阶段一的输出,根据阶段二的操作码,决定是否进行加法树,向量加法或权值更新运算。
图7绘示出根据本发明一实施例的多层人工神经网络权值压缩算法的流程图。
步骤1:将存储的浮点权值w1转换成位数较少的表示w2。
步骤2:使用w2进行正向运算。
步骤3:根据正向运算得到的误差结果进行反向运算更新w1。
迭代执行上述三个步骤,直到得到所需要的模型。
前面的附图中所描绘的进程或方法可通过包括硬件(例如,电路、专用逻辑等)、固件、软件(例如,被具体化在非瞬态计算机可读介质上的软件),或两者的组合的处理逻辑来执行。虽然上文按照某些顺序操作描述了进程或方法,但是,应该理解,所描述的某些操作能以不同顺序来执行。此外,可并行地而非顺序地执行一些操作。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!