基于深度学习的全景片人工牙体识别的方法和装置与流程
本发明涉及计算机图像处理技术领域,特别地涉及一种基于深度学习的全景片人工牙体识别的方法和装置。
背景技术:
口腔全景片是进行口腔诊断的主要依据,其可以清晰、完整的显示上颌骨全貌、下颌骨全貌、上下颌牙列情况、牙槽骨情况、上颌窦腔、窦壁、窦底情况以及颞颌关节情况,并对颌骨周围疾病的诊断提供准确有效的帮助。
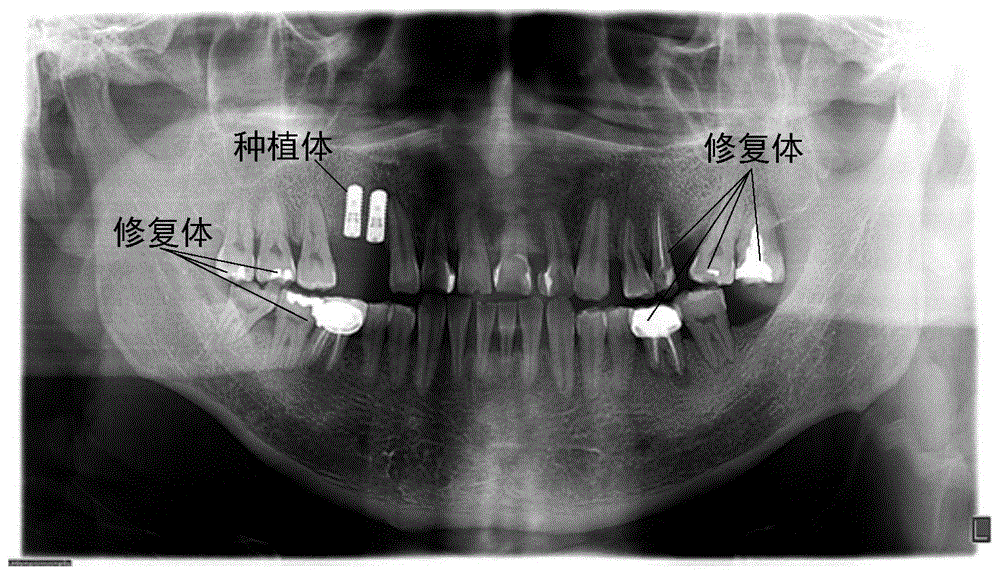
由于患者可能曾经接受牙体治疗,因此全景片中除了自然牙体之外还可能具有种植体和修复体,这两者总称人工牙体,如图1所示。目前的主要是基于全景片的人工识别,其缺点在于低效性以及存在一定的诊断不一致性。更何况我国医疗资源较稀缺,资深医学专家数量不足,倘若完全依靠人工作业会让作业人用眼疲劳,进一步降低判断结果的准确可信程度。在这种形势下,研发自动化处理全景片人工牙体识别的方法和装置的需求变得迫切。
技术实现要素:
有鉴于此,本发明提供一种基于深度学习的全景片人工牙体识别方法及装置,以克服现有技术中的上述缺点。
本发明实施例的基于深度学习的全景片人工牙体识别方法,包括:将原始全景片输入基于深度学习的牙槽骨线分割模型,以得到牙槽骨线分割结果;根据所述牙槽骨分割结果生成贴合矩形框,然后根据所述贴合矩形框生成扩展矩形框,然后根据所述扩展矩形框从所述原始全景片中剪裁出牙周区域图像块;将所述牙周区域图像块输入基于深度学习的人工牙体分割模型,以得到人工牙体分割结果,所述人工牙体分割结果包括人工修复牙体分割结果和人工种植牙体分割结果。
可选地,所述基于深度学习的牙槽骨线分割模型是通过如下方式得到的:(1)模型设计阶段:网络结构包含编码器部分和解码器部分,所述编码器部分采用xception网络结构,所述解码器部分采用fpn多尺度融合结构,并且从所述编码器部分抽取五个不同深度的卷积层作为输入;(2)模型训练阶段:对牙槽骨线分割训练数据进行尺寸归一化、灰度归一化、数据增强化、数据平衡化处理,编码器部分的参数采用大型公开图像数据集imagenet上预训练好的参数,解码器部分的参数采用随机初始化,采用梯度下降算法对模型进行迭代训练以取得网络最优解,根据在验证集上的dice值来确定模型的最优参数。
可选地,所述根据所述贴合矩形框生成扩展矩形框的步骤包括:所述贴合矩形框的左边界向左移动预设距离,以得到所述扩展矩形框的左边界;所述贴合矩形框的右边界向右移动所述预设距离,以得到所述扩展矩形框的右边界;所述贴合矩形框的上边界向上移动0.5倍贴合矩形框高度值,以得到所述扩展矩形框的上边界;所述贴合矩形框的下边界向上移动0.8倍贴合矩形框高度值,以得到所述扩展矩形框的下边界。
可选地,所述基于深度学习的人工牙体分割模型是通过如下方式得到的:(1)模型设计阶段:网络结构包含编码器部分和解码器部分,所述编码器部分采用xception网络结构并将其中的卷积层padding参数改为same,所述解码器部分采用fpn多尺度融合结构,并且从所述编码器部分抽取五个不同深度的卷积层作为输入,后接上采样层和卷积层,输出层使用softmax激活函数,输出通道使用双通道模式以同时输出人工种植牙体分割结果和人工修复牙体分割结果(2)模型训练阶段:对人工牙体分割训练数据进行尺寸归一化、灰度归一化、数据增强化、数据平衡化处理,编码器部分的参数采用大型公开图像数据集imagenet上预训练好的参数,解码器部分的参数采用随机初始化,采用梯度下降算法对模型进行迭代训练以取得网络最优解,根据在验证集上的dice值来确定模型的最优参数。
可选地,所述随机初始化的方法为:he_normal,lecun_uniform,glorot_normal,glorot_uniform或者lecun_normal。
可选地,所述梯度下降算法的方法为:adam,sgd,msprop或者adadelta。
可选地,在所述将所述牙周区域图像块输入基于深度学习的人工牙体分割模型,以得到人工牙体分割结果的步骤之后,还包括:对所述人工牙体分割结果进行形态学开运算处理。
本发明实施例的基于深度学习的全景片人工牙体识别装置,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明的任一所述的方法。
根据本发明的技术方案,基于人工智能技术,利用深度学习算法实现了人工种植牙体和人工修复牙体的识别,能够自动化地完成以往的人工作业,具有客观、快速、重复性好等优点。
附图说明
附图用于更好地理解本发明,不构成对本发明的不当限定。其中:
图1是人工牙体的示意图;
图2是本发明实施例的基于深度学习的全景片人工牙体识别的方法的流程示意图;
图3是本发明实施例的根据牙槽骨分割结果生成贴合矩形框和扩展矩形框的示意图;
图4是本发明实施例的人工牙体分割结果的示意图。
具体实施方式
图1为本发明实施例的基于深度学习的全景片人工牙体识别方法的流程示意图,包括如下的步骤a至步骤c。
步骤a:将原始全景片输入基于深度学习的牙槽骨线分割模型,以得到牙槽骨线分割结果。
可选地,步骤a中的基于深度学习的牙槽骨线分割模型是通过如下方式得到的:(1)模型设计阶段:网络结构包含编码器部分和解码器部分,编码器部分采用xception网络结构,解码器部分采用fpn多尺度融合结构,并且从编码器部分抽取五个不同深度的卷积层作为输入;(2)模型训练阶段:对牙槽骨线分割训练数据进行尺寸归一化、灰度归一化、数据增强化、数据平衡化处理,编码器部分的参数采用大型公开图像数据集imagenet上预训练好的参数,解码器部分的参数采用随机初始化,采用梯度下降算法对模型进行迭代训练以取得网络最优解,根据在验证集上的dice值来确定模型的最优参数。
步骤b:根据牙槽骨分割结果生成贴合矩形框,然后根据贴合矩形框生成扩展矩形框,然后根据扩展矩形框从原始全景片中剪裁出牙周区域图像块。需要说明的是,由于人工牙体(种植体和牙体修复)都只会出现在牙周区域,而且在原始全景片上的占比非常小,通常低于1%,所以使用提取到的牙周区域图像块作为训练样本,可以很大程度的提高人工牙体的占比,使得模型的训练更加容易,也能获得更高的分割表现,所以此步骤是非常必要的。
可选地,步骤b中的“根据贴合矩形框生成扩展矩形框”的步骤具体包括:贴合矩形框的左边界向左移动预设距离,以得到扩展矩形框的左边界;贴合矩形框的右边界向右移动预设距离,以得到扩展矩形框的右边界;贴合矩形框的上边界向上移动0.5倍贴合矩形框高度值,以得到扩展矩形框的上边界;贴合矩形框的下边界向上移动0.8倍贴合矩形框高度值,以得到扩展矩形框的下边界。
步骤c:将牙周区域图像块输入基于深度学习的人工牙体分割模型,以得到人工牙体分割结果,该人工牙体分割结果包括人工修复牙体分割结果和人工种植牙体分割结果。
可选地,步骤c中的基于深度学习的人工牙体分割模型是通过如下方式得到的:(1)模型设计阶段:网络结构包含编码器部分和解码器部分,编码器部分采用xception网络结构并将其中的卷积层padding参数改为same,解码器部分采用fpn多尺度融合结构,并且从编码器部分抽取五个不同深度的卷积层作为输入,后接上采样层和卷积层,输出层使用softmax激活函数,输出通道使用双通道模式以同时输出人工种植牙体分割结果和人工修复牙体分割结果。(2)模型训练阶段:对人工牙体分割训练数据进行尺寸归一化、灰度归一化、数据增强化、数据平衡化处理,编码器部分的参数采用大型公开图像数据集imagenet上预训练好的参数,解码器部分的参数采用随机初始化,采用梯度下降算法对模型进行迭代训练以取得网络最优解,根据在验证集上的dice值来确定模型的最优参数。
需要说明的是,上文中训练模型阶段中的随机初始化的方法可以为:he_normal,lecun_uniform,glorot_normal,glorot_uniform或者lecun_normal,最优选he_normal。上文中训练模型阶段中的梯度下降算法的方法可以为:adam,sgd,msprop或者adadelta,最优选adam。
可选地,在步骤c之后,还包括:对人工牙体分割结果进行形态学开运算处理。经过先膨胀后收缩的形态学开运算处理,能够有效地去除假阳性分割结果。
本发明实施例的基于深度学习的全景片人工牙体识别装置,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现本发明的任一的方法。
为使本领域技术人员更好地理解,下面结合具体实施例阐述本发明实施例的基于深度学习的全景片人工牙体识别方法。
(一)基于深度学习的牙槽骨线分割:
设计牙槽骨线分割网络模型结构包含encoder和decoder两部分。encoder部分使用xception网络结构,decoder部分使用fpn多尺度融合结构,从encoder部分抽取不同深度的5个卷积层做为输入;记该模型为panonet-s1。
对牙槽骨线分割训练数据进行尺长归一化和灰度归一化。具体地,首先对原始全景片图像的尺度(1200×2700左右)进行下采样,采样至448×896;然后对采样后的图像灰度值进行归一化处理,公式如下(其中,x表示原始灰度值,y表示归一化后的灰度值):
然后进行训练数据增强:通过对图像旋转(-10度至10度)和左右镜像方式,对原始数据集中的图像数据进行增加样本处理,以满足深度网络对数据量的需求。
接着进行模型训练,将牙槽骨线分割训练数据(包括原有的和增强的)输入模型panonet-s1进行训练,panonet-s1的encoder部分的参数使用在大型公开图像数据集imagenet上预训练好的参数,decoder部分的参数采用随机初始化。采用梯度下降算法adam对模型进行迭代训练,经过不断迭代,取得网络最优解。根据在验证集上的dice值来确定模型的最优参数。
将测试全景片输入训练好的panonet-s1,得到牙槽骨线分割结果mask1。
(二)提取牙周区域图像块
如图3所示,为牙槽骨线分割结果mask1生成一个贴合矩形框rect,再经过延展得到扩展矩形框rect’,延展公式如下:
w’=w+2*sw
h′=h+sh1+sh2
sh1=0.5*h
sh2=0.8*h
其中,sw可以取值为250。根据得到的扩展矩形框rect’从原图上裁剪出牙周区域图像块patch1。
(三)获取人工牙体分割结果
设计人工牙体分割网络模型结构包含encoder和decoder两部分。encoder部分使用xception网络结构,并将其中的卷积层的padding参数改为same。decoder部分使用fpn多尺度融合结构,从encoder部分抽取不同深度的5个卷积层做为输入,后接上采样层和卷积层,输出层使用softmax激活函数,输出通道使用双通道模式以同时输出人工种植牙体分割结果和人工修复牙体分割结果。记该模型为panonet-s2。
对人工牙体分割训练数据进行尺长归一化和灰度归一化。具体地,首先对原始全景片图像的采样至512×1024;然后对采样后的图像灰度值进行归一化处理(具体方法同上文)。然后进行训练数据增强:通过对图像旋转(-10度至10度)和左右镜像方式,对原始数据集中的图像数据进行增加样本处理,以满足深度网络对数据量的需求。
接着进行模型训练,将人工牙体分割训练数据(包括原有的和增强的)输入模型panonet-s2进行训练,panonet-s2的encoder部分的参数使用在大型公开图像数据集imagenet上预训练好的参数,decoder部分的参数采用he_normal随机初始化。采用梯度下降算法adam对模型进行迭代训练,经过不断迭代,取得网络最优解。根据在验证集上的dice值来确定模型的最优参数。
将牙周区域图像块patch1输入训练好的人工牙体分割模型panonet-s2,得到人工牙体分割结果mask2,如图4所示。优选地,对人工牙体分割结果mask2进行形态学开运算处理,其主要目的是平滑牙齿分割结果的轮廓。
根据本发明的技术方案,基于人工智能技术,利用深度学习算法实现了人工牙体的识别,能够自动化地完成以往的人工作业,具有客观、快速、重复性好等优点。
上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,取决于设计要求和其他因素,可以发生各种各样的修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!