一种基于文本数据的资料管理系统及方法与流程
本发明属于信息管理系统领域,具体涉及一种基于文本数据的资料管理系统及方法。
背景技术:
随着互联网技术的不断发展与数字化时代的到来,基于文本数据的电子文档的数量在过去的十几年中激增,各行各业在日常业务工作中都积累了大量的文档素材及稿件。由于在工作中需要经常查询或调阅往期同类型同主题的文档作为参考,然而,面对数量庞大,主题多样,格式各异,且分散在不同的人员手中的材料文档,难以进行统一检索,且目前市面上现有的文档管理系统,只是简单的存储功能和展示,需要耗费大量人工成本进行归纳整理。
因此,急需设计一套资料管理系统,能对文本材料进行自动归纳整理,对历史数据和新创作的素材进行统一的存储,并提供便捷的查询或调阅方式。
数据挖掘技术和数据库系统的迅猛发展,为文本数据的自动分类、篇章结构提取、存储和检索提供了基础。
技术实现要素:
本发明针对工作中产生的大量的各式各样的电子化文档,构建了一种基于文本数据的资料管理系统和方法,实现对素材的自动归档、分类、篇章结构提取、主题标注,并提供便捷的查询调阅方法。
所述的资料管理系统具体包括:数据上传模块,数据存储模块,数据解析模块,数据检索模块,数据可视化模块,工具箱和管理台。
数据上传模块能实现压缩上传和普通上传;压缩上传利用断点技术,解决大批量文本同时上传,并可以拓展。普通上传支持指定分类体系上传。
数据存储模块包括三种数据库:关系型数据库,全文索引搜索引擎数据库和文件服务器;其中关系型数据库采用sqlite集成框架,由底向上分别为:
connect:负责生成指定库的connection;
sql构建层:负责将各种条件组装为sqlite支持的sql语句;
result层:负责将原生检索结果转换为实体;
manager层:提供对外操作接口。
关系型数据库用于存储各种关系型数据,比如日志文件;全文索引搜索引擎数据库用于存储文件处理后的内容;文件服务器用于存储上传源文件。
数据解析模块能实现文档解析,自动分类和内容抽取;其中内容抽取包括主题词标引,文本自动摘要和实体抽取。
数据检索模块包括一般搜索和高级搜索,均采用相似性判断技术实现检索。
数据可视化模块包括统计展示,搜索推荐和分类列表。统计展示采用数据列表形式;搜索推荐采用关键词云和热点分析;分类列表对文章详情进行展示。
工具箱包括收藏夹,统计分析和资料导出管理。
管理台包括系统管理,用户管理,任务管理,资料管理和日志管理。
系统管理包括配置项管理和数据库管理;任务管理包括后台任务管理和adapter管理;日志管理采用高并发操作。
所述的资料管理方法步骤如下:
步骤一、针对多种格式的文档,用户将本地文件利用数据上传模块上传至数据存储模块中进行存储。
大批量文件断点上传的具体过程为:
首先,批量文件上传时发送前置请求q1,生成本批次文件上传的tokenkey;
tokenkey生成规则为:
tokenkey=md5(filename+uid+uuid);
filename为上传文件的文件名;uid为上传用户id;uuid为uuid算法生成值。
使用md5对所有参数的累加值进行散列计算,保证并发请求key值唯一。
然后,前端实现队列按照每个文件的顺序上传,携带key值发送前置请求q2,持久化当前文件的基本信息,处理成功之后给前端返回成功标识;
基本信息包括文件名称、文件大小、文件md5值和文件缓存路径等信息。
当后端接收文件切片后上传请求qs,对文件进行合并,并对合并后文件mergefile与原文件fr进行一致性校验;
最终确认请求,分以下两种情况:
a)、在上传任意阶段,前端发送qc取消请求,则终止并清空请求队列,对该tokenkey对应的批次数据进行清理,包含临时文件和sql记录等,返回指定状态码,并在清理完成之后再次对临时数据进行清理,从而防止极限情况下垃圾数据的生成,并对tokenkey进行销毁;
b)、在上传请求队列全部请求完成后,前端发送qs确定请求,应用根据q2记录的信息,对文件分发到ftp的生产目录,并销毁tokenkey;
自此,完成大批量的文件断点上传过程。
步骤二、数据解析模块对上传文件进行解析处理,得到上传文件的属性并存储到数据存储模块中。
文档解析包括解析上传文件的格式和抽取上传文件的字段;
自动分类是基于内容和基于规则相结合的方式对文档进行分类;
针对基于内容的分类,首先对文本进行分词和词性标注;使用特征提取技术,抽取有用的文本特征,将提取的文本特征表示成文本向量并送入分类器,分类器计算文本向量与分类模板之间的距离,确定该文本的类别。
具体为:首先获取文档中具有分类价值的词语作为分类知识,具体采用期望交叉熵作为特征评估函数对特征集中的每个特征独立计算评估值,然后进行排序,选取预定数目的最佳特征作为结果的特征子集,根据统计方法计算每个词对于分类的作用大小,选择其中分类作用大的作为分类知识,过滤掉无关特征词。
当获取分类知识后,采用集成学习的算法联合svm和knn模型构造多分类器引擎,从而提高系统的分类性能。
针对基于规则的分类:
从文本中抽取关键词,计算关键词之间的逻辑关系和数量关系,采用统计算法,对文本、规则、类别之间进行精确处理,确定文本的类别。
最后,将规则分类结果和内容分类结果进行合并,输出最后的类别。
内容抽取包括:主题词标引、文本自动摘要和实体抽取。
主题词标引包括实体标引、关键词标引、关键词组配和特殊符号标引。
实体标引:根据实体库(人名库、地名库、机构名库)和trs的人名地名机构名自动识别获得实体关键词,加入到候选关键词中;
关键词标引:根据关键词库获得关键词,加入到候选关键词中;
关键词组配:根据组配规则,对得到的关键词按句进行组配,将结果加入到候选关键词中;
特殊符号词标引:出现在《》等特殊符号的词,将满足条件的加入到候选关键词中。
文本自动摘要是将文本视为句子的线性序列,将句子视为词的线性序列。通常分以下几步进行:首先,分析文本的篇章结构,识别出段落、大小标题和句子等信息。然后,对文本进行分词和词性标注,根据语言知识统计词典,计算词在句子中的加权值。利用词权、篇章结构信息等特征计算句子的权值。对原文中的所有句子按权值高低降序排列,权值最高的若干句子被确定为文摘句。对文摘句进行片段去重分析,把重复的文摘句去掉。最后,对文摘句进行平滑处理,提高可读性。将所有文摘句按照它们在原文中的出现顺序输出。
实体抽取基于规则与统计相结合的技术,从非结构的文本信息中抽取有意义的事实信息,被抽取的事实信息以结构化的形式进行描述,并存入结构化数据库中。
抽取的信息包括命名实体和术语等信息。其中命名实体包括:人名、组织机构名、地点、时间、email、电话号码、身份证信息、银行帐号、护照信息、案件名称、qq、msn、email、车牌号等。其中术语主要指领域词汇。新增加简历抽取功能:可以抽取基本信息、教育背景、工作经历、培训经历、求职意愿等五类信息。
实体抽取的工作流程是:首先将输入文本分割为不同的块,将得到的文本块转换为句子序列,每个句子由词汇项(词或特定类型短语)及相关的属性(如词类)组成。然后,过滤掉不相关的句子,对过滤后的句子进行预分析:在词汇项序列中识别确定的结构,如名词短语、动词短语、并列结构等。最后分析文本,自动抽取出各种命名实体和术语。
上传文件的属性包括上传用户,上传文件大小、上传文件名和类型等属性标记。
步骤三、将解析后的资料内容及附件等数据分别存储在数据存储模块中的全文索引搜索引擎数据库和关系型数据库中。
关系型数据库中保存高并发下操作日志;
步骤四、采用相似性判断技术,利用数据检索模块对存储到数据库中的资料进行检索;
支持通过关键词、文档类型、文档属性、文档标签、文档分类等多维度进行检索。共包括两种相似文本的检索;
第一种是trs相似文本检索,工作流程是:
首先,对文本进行分词和词性标注;然后,使用特征提取技术,抽取有用的文本特征;将提取的文本特征表示成文档“指纹”。最后,到文档指纹库中检索与当前文档最相似的文档。
第二种是跨语言相似文本检索,工作流程是:
首先,对文本进行分词和词性标注;然后,使用特征提取技术,抽取有用的文本特征。然后,使用统计翻译模型,把文本特征映射到另一种语言的文本特征。最后,将得到的文本特征表示成文档“指纹”,到文档指纹库中检索与当前文档最相似的文档。
步骤五、利用数据可视化模块对所有资料内容按分类进行展示、文档操作功能和各种可视化展示;
本发明的优点在于:
1)、本发明一种基于文本数据的资料管理系统,是一套较为完备的资料管理系统,可以处理工作中产生的大量的各式各样的电子化文档,极大得提高了工作效率,并提升对战略研究素材的管理及沉淀能力。
2)、本发明一种基于文本数据的资料管理系统,sqlite集成框架依赖jdk原生jdbc与sqlite-jdbc,支持原生sql,支持方言转换;支持多种主键生成策略,支持自动建表,支持实体检索映射;提供多种常用检索api,使用便捷;支持线程兼容连接池,允许存在多个连接并发访问多个库;支持大批量数据插入。
3)、本发明一种基于文本数据的资料管理方法,涵盖了数据的接入、处理、存储、检索和各种统计分析与可视化,对实际工作中产生的大量电子化文档素材自动化归档、分类、篇章结构提取、主题标注,并能提供便捷的查询调阅方法,构建历史素材的分类体系。
4)、本发明一种基于文本数据的资料管理方法,能对历史数据和新创作的素材进行统一的存储,更具有鲁棒性,通过定制分类的类别,能应对客户的各种需求。
5)、本发明一种基于文本数据的资料管理方法,大批量文件断点上传,采用md5消息摘要算法确保了文件断点上传一致性,采用了nio技术提升io操作效率;文件的两次前置加载,对每个文件进行标记,后续可统一处理。
附图说明
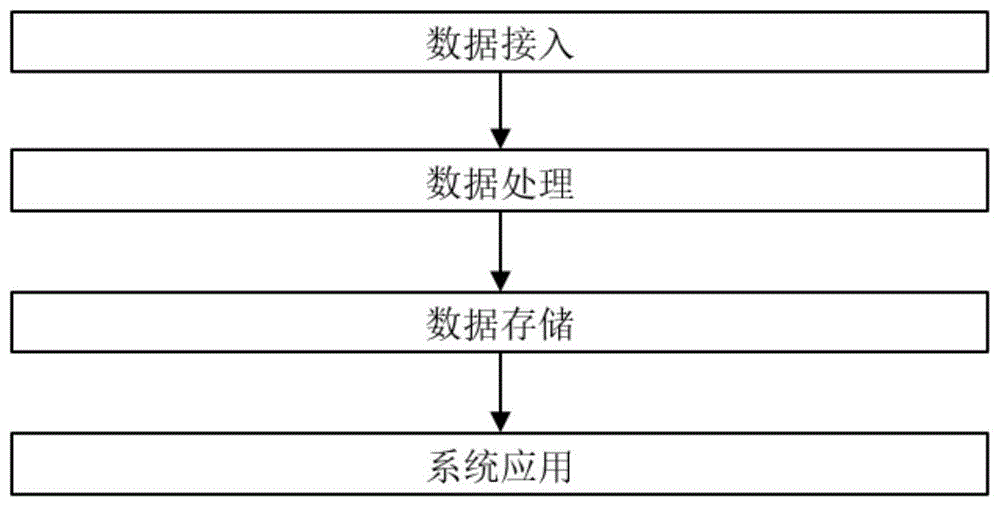
图1为本发明基于文本数据的资料管理系统的功能结构图。
图2为本发明基于文本数据的资料管理系统的整体框架图。
图3为本发明基于文本数据的资料管理方法的原理图。
图4为本发明基于文本数据的资料管理方法的流程图。
图5为本发明基于文本数据的资料管理方法的详细设计图。
图6为本发明基于文本数据的资料管理系统的首页设计示意图。
图7为本发明基于文本数据的资料管理系统的搜索页设计图。
图8为本发明基于文本数据的资料管理系统的上传文件页设计图。
图9为本发明基于文本数据的资料管理系统的工具箱页设计图。
图10为本发明基于文本数据的资料管理系统的管理台页设计图。
图11为本发明基于文本数据的资料管理系统的子页面设计图。
具体实施方案
下面将结合附图和实施例对本发明作进一步的详细说明。
本发明针对工作中产生的各式各样的电子化文档,构建了一种基于文本数据的资料管理系统和方法。如图1所示,包括数据接入,数据处理,数据存储和系统应用四部分。
数据接入是针对多种格式的文档系统自动进行抽取统一存储在全文检索数据库中。数据处理是当数据入库时对数据进行处理,包括内容解析、抽取、分类、主题标引、关键词抽取、相似性判断等。数据存储是将数据统一存储在全文检索数据库中。系统应用是系统提供管理台、数据检索、数据展示和工具箱等功能。
首先用户上传本地文件至资料库;然后对上传文件进行处理,具体包括内容解析、抽取、分类、主题标引和关键词抽取等,并将解析后的资料内容及附件等进行存储;最后系统提供对上传的所有资料快速准确有效的全文检索功能,支持所有资料内容按分类进行展示、文档操作功能和各种可视化展示,系统还提供工具箱功能,包括收藏、统计分析及资料导出功能。本发明实现对素材的自动归档、分类、篇章结构提取、主题标注,并提供便捷的查询调阅方法;具有高效性和易用性,在信息系统管理等领域有重要应用价值。
所述的基于文本数据的资料管理系统如图2所示,包括:数据上传模块,数据存储模块,数据解析模块,数据检索模块,数据可视化模块,工具箱和管理台。
系统应用:用户可在内网访问使用该系统,同时,支持单机版,用户可直接访问本地的服务使用系统。
数据上传模块能实现压缩上传和普通上传;压缩上传利用断点技术,解决大批量文本上传,可以拓展。普通上传支持指定分类体系上传。
数据存储模块包括三种数据库:关系型数据库,全文索引搜索引擎数据库和文件服务器;其中关系型数据库采用sqlite集成框架,由底向上分别为:
connect:负责生成指定库的connection;
sql构建层:负责将各种条件组装为sqlite支持的sql语句;
result层:负责将原生检索结果转换为实体;
manager层:提供对外操作接口。
关系型数据库用于存储各种关系型数据,比如日志文件;全文索引搜索引擎数据库用于存储文件处理后的内容;文件服务器用于存储上传源文件。
数据解析模块能实现文档解析,自动分类和内容抽取;其中内容抽取包括主题词标引,文本自动摘要和实体抽取。
数据检索模块包括一般搜索和高级搜索,均采用相似性判断技术实现检索。
数据可视化模块包括统计展示,搜索推荐和分类列表。统计展示采用数据列表形式;搜索推荐采用关键词云和热点分析;分类列表对文章详情进行展示。
工具箱包括收藏夹,统计分析和资料导出管理,为用户提供使用便利,辅助分析。
管理台为管理权提供各种权限管理,包括系统管理,用户管理,任务管理,资料管理和日志管理。用户可在内网访问使用该系统,同时,支持单机版,用户可直接访问本地的服务使用系统。
系统管理包括配置项管理和数据库管理;任务管理包括后台任务管理和adapter管理;日志管理采用高并发操作。
所述的资料管理方法,如图3所示,通过管理台监测到用户将数据上传,然后流转到数据处理,然后流转到数据存储,进一步进行数据检索和统计分析,并进行数据可视化。同时,管理台查看日志管理,进行监控。
如图4所示,具体步骤如下:
步骤一、针对多种格式的文档,用户将本地文件利用数据上传模块上传至数据存储模块中进行存储。
如图5所示,上传文档包括:zip压缩包上传;批量多个文件同时上传;指定文件分类上传,未分类文件上传等;格式包括:word、pdf或ppt等。
大批量文件断点上传的具体过程为:
首先,批量文件上传时发送前置请求q1,应用生成本批次文件上传的tokenkey;
tokenkey生成规则为:
tokenkey=md5(filename+uid+uuid);
filename为上传文件文件名;uid为上传用户id;uuid为uuid算法生成值。
使用md5对所有参数的累加值进行散列计算,保证并发请求key值唯一。
然后,前端实现队列按照每个文件的顺序上传,携带key值发送前置请求q2,持久化当前文件的基本信息,例如文件名称、文件大小、文件md5值、文件缓存路径等信息,处理成功之后给前端返回成功标识;
当后端接收文件切片后上传请求qs,对文件进行合并,并对合并后文件mergefile与原文件fr进行一致性校验;
最终确认请求,分以下两种情况:
a)、在上传任意阶段,前端发送qc取消请求,则终止并清空请求队列,对该tokenkey对应的批次数据进行清理,包含临时文件、sql记录等,返回指定状态码,并在清理完成之后再次对临时数据进行清理,从而防止极限情况下垃圾数据的生成,并对tokenkey进行销毁;
b)、在上传请求队列全部请求完成后,前端发送qs确定请求,应用根据q2记录的信息,对文件分发到ftp的生产目录,并销毁tokenkey;
自此,完成大批量的文件断点上传过程。
步骤二、数据解析模块对上传文件进行解析处理,得到上传文件的属性并存储到数据存储模块中。
通过adapter与ckm等工具对文件进行抽取解析,解析过程包括文档解析,自动分类和内容抽取。
如图5所示,文档解析包括解析格式和字段抽取;
自动分类是基于内容和基于规则相结合的方式对文档进行分类;包括自定义分类体系,自动分类与关键词规则分类结合,以及自动获取上传语料训练分类模板。
首先,对文本进行分词和词性标注;然后使用特征提取技术,抽取有用的文本特征,将提取的文本特征表示成文本向量并送入分类器,分类器计算文本向量与分类模板之间的距离,确定该文本的类别。如果是规则分类,则从文本中抽取关键词,计算关键词之间的逻辑关系和数量关系,确定文本的类别。对自动分类结果和规则分类结果进行合并,输出最后的分类结果。
具体如下:首先,获取分类知识;分类知识是指文档中具有分类价值的词语,如用国家名、地名识别国内新闻和国外新闻等。具体采用期望交叉熵作为特征评估函数对特征集中的每个特征独立计算评估值,然后进行排序,选取预定数目的最佳特征作为结果的特征子集,根据统计方法计算每个词对于分类的作用大小,选择其中分类作用大的作为分类知识,过滤掉无关特征词。
当获取分类知识后,采用集成学习的算法联合svm和knn模型构造多分类器引擎,从而提高系统的分类性能。
丰富的语言学资源是获取文本分类知识的一个有效途径。系统内置主题词典、分类词典、同义词词典等丰富的语言学资源,可以处理同义词、上下位词等语法现象,如“胃病”、“癌症”可归为疾病;“电脑”、“计算机”可归为一个词。
然后,设置统计分类规则,首先从文本中抽取关键词,计算关键词之间的逻辑关系和数量关系,采用统计算法,对文本、规则、类别之间进行精确处理,确定文本的类别。用户可根据实际需求随机增删规则,满足个性化需求。
最后,将规则分类结果和算法分类结果进行合并,输出最后的类别。
用户自定义分类树,为每个节点提供训练文档,利用预设定的规则和机器学习算法对文档进行分类。
内容抽取包括抽取关键词摘要和聚类、实体信息抽取。具体为主题词标引、文本自动摘要和实体抽取。
主题词标引包括实体标引、关键词标引、关键词组配和特殊符号标引。
实体标引:根据实体库(人名库、地名库、机构名库)和trs的人名地名机构名自动识别获得实体关键词,加入到候选关键词中;
关键词标引:根据关键词库获得关键词,加入到候选关键词中;
关键词组配:根据组配规则,对得到的关键词按句进行组配,将结果加入到候选关键词中;
特殊符号词标引:出现在《》等特殊符号的词,将满足条件的加入到候选关键词中。
文本自动摘要是将文本视为句子的线性序列,将句子视为词的线性序列。通常分以下几步进行:首先,分析文本的篇章结构,识别出段落、大小标题和句子等信息。然后,对文本进行分词和词性标注,根据语言知识统计词典,计算词在句子中的加权值。利用词权、篇章结构信息等特征计算句子的权值。对原文中的所有句子按权值高低降序排列,权值最高的若干句子被确定为文摘句。对文摘句进行片段去重分析,把重复的文摘句去掉。最后,对文摘句进行平滑处理,提高可读性。将所有文摘句按照它们在原文中的出现顺序输出。
实体抽取基于规则与统计相结合的技术,从非结构的文本信息中抽取有意义的事实信息,被抽取的事实信息以结构化的形式进行描述,并存入结构化数据库中。
抽取的信息包括命名实体和术语等信息。其中命名实体包括:人名、组织机构名、地点、时间、email、电话号码、身份证信息、银行帐号、护照信息、案件名称、qq、msn、email、车牌号等。其中术语主要指领域词汇。新增加简历抽取功能:可以抽取基本信息、教育背景、工作经历、培训经历、求职意愿等五类信息。
实体抽取的工作流程是:首先将输入文本分割为不同的块,将得到的文本块转换为句子序列,每个句子由词汇项(词或特定类型短语)及相关的属性(如词类)组成。然后,过滤掉不相关的句子,对过滤后的句子进行预分析:在词汇项序列中识别确定的结构,如名词短语、动词短语、并列结构等。最后分析文本,自动抽取出各种命名实体和术语。
上传文件的属性包括上传用户,上传文件大小、上传文件名和类型等属性标记。
步骤三、将解析后的资料内容及附件等数据分别存储在数据存储模块中的全文索引搜索引擎数据库和关系型数据库中。
文档原文件存入对应分类文件夹,文档数据结构化统一数据库存储。
将解析完成的数据通过adapter推送至trsserver全文检索数据库中;关系型数据库中保存高并发下操作日志;
高并发下操作日志支持高并发下即时的日志记录,架构清晰明了,使用及二次开发成本极低,支持mysql、日志文件(logbak、log4j等)等多种日志记录方式。
在最终日志记录之前增加缓存,负责记录即时日志,大量减少日志文件或库的记录及检索压力,并且可一次性处理日志格式,使日志记录更具可读性,减少运维成本;利用aop-aspect结合自定义注解(包含个性化日志记录配置)的切面编程方式,控制记录入口;通过分发key的方式,防止日志记录混淆;
具体过程如下:
设并发请求request1、2、3发送至后台,分别访问url1、2、3,其中url1、2被@operation注解标识(代表须记录日志),request3访问url3没有被标注:
aspect以@operation为切点,拦截所有标记的请求,request3不被拦截进入日志记录流程,request1、2进入日志记录流程;
分发唯一key值,并在cache中创建两条记录,用于后续日志记录;
key值生成方式表述:
key=md5(method+requestparams+uid+uuid)
method为请求的url接口名称,requestparams为当前请求的全部参数;uid为当前登录用户id;uuid为uuid算法生成的值。
即使用md5对所有参数的累加值进行散列计算,保证高并发下key值唯一。
在具体的功能服务中,根据key值将所需记录的内容放置cache所对应的记录中;
logparser解析器处理流程:
a)将cache中对应的缓存数据取出,并根据业务的不同进行merge和format,处理成为格式化数据,处理完成之后,清除缓存记录,同时key值生命周期结束;
b)chooserecorder根据url上@operation标记的不同,选择不同的日志记录持久化方式,目前支持mysql、日志文件两种方式。
步骤四、利用数据检索模块对存储到数据库中的资料进行检索;
利用trsserver高速准确有效的全文检索功能,对资料库中已存在数据提供统一检索功能;支持通过关键词、文档类型、文档属性、文档标签、文档分类等多维度进行检索;共包括两种相似文本的检索,检索到的文档可在线浏览全文查看。
第一种是trs相似文本检索,工作流程是:
首先,对文本进行分词和词性标注;然后,使用特征提取技术,抽取有用的文本特征;将提取的文本特征表示成文档“指纹”。最后,到文档指纹库中检索与当前文档最相似的文档。
第二种是跨语言相似文本检索,工作流程是:
首先,对文本进行分词和词性标注;然后,使用特征提取技术,抽取有用的文本特征。然后,使用统计翻译模型,把文本特征映射到另一种语言的文本特征。最后,将得到的文本特征表示成文档“指纹”,到文档指纹库中检索与当前文档最相似的文档。
步骤五、利用数据可视化模块对所有资料内容按分类进行展示、文档操作功能和各种可视化展示;
如图5所示,展示检索包括:按分类目录展示,按数据库字段组合检索,详情页自定义编辑属性和检索结果统计分析。
上传至系统的所有文档资料在进行基础处理之后按分类在前端页面进行展示,可分级展示分类列表、数据量统计、热搜词云图、搜索推荐、关键词词云、热点人物和文章详情等。并提供文档操作功能,其中,操作功能包括:自定义文档属性、标签;统计分析、下载、收藏、导出。
最后,离线版客户端使用,免安装一键启动,加载数据资源查看/检索。
图6到图11是本发明具体实施例采用的系统首页设计,搜索页面,上传文件页面,工具箱页面,管理台页面以及子页面的设计图。
本发明构建了一套较为完备的资料管理系统,系统涵盖了数据的接入、处理、存储、检索和各种统计分析与可视化。该系统可以自动处理工作中产生的大量的各式各样的电子化文档,极大得提高了工作效率,并提升对战略研究素材的管理及沉淀能力。本方法具有高效性和易用性,在信息系统管理等领域有重要应用价值。
- 还没有人留言评论。精彩留言会获得点赞!