一种超市智能售货系统的制作方法
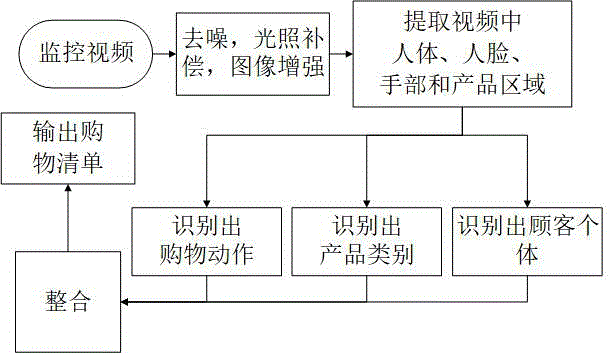
本发明涉及计算机视觉监控技术领域,目标检测、目标跟踪和模式识别领域,具体涉及用于对基于监控摄像头的货架前的个体进行检测、跟踪和动作识别的领域。
背景技术:
传统超市模式下结账是由人工扫描商品进行,这种模式非常容易造成拥堵,导致大量购物者排队在结账处,整个结账过程受到收银处的空间限制以及收银员的人数限制无法大幅度增加,因此由于传统收银模式的限制,结账拥堵无法避免;现有的顾客通过自主扫描商品结账的方式虽然能够将扫描商品的时间减少,但是出门仍然需要人工检查商品,仍然会造成拥堵。分析拥堵的原因,最耗时的工序是录入商品的过程,因此将商品录入过程提前到购物者取货时,能够将最耗时的过程提前并且能够并行操作,从而大幅度的提高了结账速度,提高了顾客的购物体验。
本发明所提出的系统就是利用监控摄像头在购物者选货的过程中进行识别并计数,从而提高了结账速度,通过对顾客的取货和放回商品的过程进行识别来进行取货数量的加减,通过在客户取放商品时对商品进行识别来得到商品类型,通过对顾客的异常行为识别来判断是否有偷盗行为,从而在不降低顾客在选货过程的购物体验的前提下实现自动统计功能。本发明涉及顾客的购物记账过程而不改变超市的原有组织结构,从而便于与现有超市组织架构无缝对接。
技术实现要素:
本发明所要解决的技术问题是为了克服传统超市模式下结账速度慢的情况,提出了一种超市智能售货系统。使用监控摄像头来完成顾客购物行为的识别以及商品的识别。
本发明解决其技术问题所采用的技术方案是:
一种超市智能售货系统,基于固定在超市内以及货架上的监控摄像头所摄的视频图像作为输入。包括图像预处理模块,目标检测模块,购物动作识别模块,产品识别模块,个体识别模块,识别结果处理模块。所述的图像预处理模块对监控摄像头所摄的视频图像进行预处理,首先对输入的图像中可能含的噪声进行去噪处理,然后对去噪后的图像进行光照补偿,然后对光照补偿后的图像进行图像增强,最后将图像增强后的数据传递给目标检测模块;所述的目标检测模块,对接收到的图像进行目标检测,分别检测出当前视频图像中的人体整体区域、人脸面部区域、手部区域和产品区域,然后将手部区域和产品区域发送给购物动作识别模块,把人体图像区域和人脸面部区域发送给个体识别模块,把产品区域传递给产品识别模块;所述的购物动作识别模块对接收到的手部区域信息进行静态动作识别,找到抓握视频的起始帧,然后持续的对动作进行识别直到找到放下物品的动作作为结束帧,然后对视频使用动态动作识别分类器进行识别,识别出当前动作是取出物品、放回物品、取出又放回、已取出物品未放回或者是可疑偷窃。然后将识别结果发送给识别结果处理模块,将只有抓握动作的视频和只有放下动作的视频发送给识别结果处理模块;所述的产品识别模块对接收到的产品区域的视频进行识别,识别出当前被移动的是哪一种产品,然后将识别结果发送给识别结果处理模块,产品识别模块也可以随时增加或删除某个产品;所述的个体识别模块对接收到的人脸区域和人体区域进行识别,结合人脸区域和人体区域信息,用于识别出当前个体是整个超市内的哪一位个体,然后将识别结果发送给识别结果处理模块;所述的识别结果处理模块对接收到的识别结果进行整合,根据个体识别模块传递来的顾客的id确定当前购物信息对应的顾客,根据产品识别模块传递来的识别结果来确定当前顾客的购物动作对应的产品,根据购物动作识别模块传递来的识别结果来确定当前购物动作是否对购物车进行修改。从而得到当前顾客的购物清单。对购物动作识别模块识别的可疑偷窃行为发出警报。
所述的图像预处理模块,其方法是:在初始化阶段该模块不工作;在检测过程中:第一步,对监控摄像头所摄的监控图像进行均值去噪,从而得到去噪后的监控图像;第二步,对去噪后的监控图像进行光照补偿,从而得到光照补偿后的图像;第三步,将光照补偿后的图像进行图像增强,将图像增强后的数据传递给目标检测模块。
所述的监控摄像头所摄的监控图像进行均值去噪,其方法是:设监控摄像头所摄的监控图像为xsrc,因为xsrc为彩色rgb图像,因此存在xsrc-r,xsrc-g,xsrc-b三个分量,对于每一个分量xsrc′,分别进行如下操作:首先设置一个3×3维的窗口,考虑该图像xsrc′的每个像素点xsrc′(i,j),以该点为中心点的3×3维矩阵所对应的像素值分别为[xsrc′(i-1,j-1),xsrc′(i-1,j),xsrc′(i-1,j+1),xsrc′(i,j-1),xsrc′(i,j),xsrc′(i,j+1),xsrc′(i+1,j-1),xsrc′(i+1,j),xsrc′(j+1,j+1)]进行从大到小排列,取其排在中间的值为去噪后图像xsrc″在像素(i,j)所对应滤波后值赋值给xsrc″(i,j);对于xsrc′的边界点,会出现其3×3维的窗口所对应的某些像素点不存在的情况,那么只需计算落在窗口内存在的像素点的中间值即可,若窗口内为偶数个点,将排在中间两个像素值的平均值作为该像素点去噪后的像素值赋值给xsrc″(i,j),从而,新的图像矩阵xsrc″即为xsrc在当前rgb分量的去噪后的图像矩阵,对于xsrc-r,xsrc-g,xsrc-b在三个分量分别进行去噪操作后,将得到的xsrc-r″,xsrc-g″,xsrc-b″分量,将这三个新的分量整合成一张新的彩色图像xden即为去噪后所得的图像。
所述的对去噪后的监控图像进行光照补偿,设去噪后的监控图像xden,因为xden为彩色rgb图像,因此xden存在rgb三个分量,对于每一个分量xden′,分别进行光照补偿,然后将得到的xcpst′整合得到彩色rbg图像xcpst,xcpst即为xden光照补偿后的图像,对每一个分量xden′分别进行光照补偿的步骤为:第一步,设xden′为m行n列,构造xden′sum和numden为同样m行n列的矩阵,初始值均为0,
所述的根据窗口大小为l和步长s确定每一个候选框,其步骤为:
设监控图像为m行n列,(a,b)为选定的区域的左上角坐标,(a+l,b+l)为选定区域的右下角坐标,该区域由[(a,b),(a+l,b+l)]表示,(a,b)的初始值为(1,1);
当a+l≤m时:
b=1;
当b+l≤n时:
选定的区域为[(a,b),(a+l,b+l)];
b=b+s;
内层循环结束;
a=a+s;
外层循环结束;
上述过程中,每次选定的区域[(a,b),(a+l,b+l)]均为候选框。
所述的对于xden′在候选框区域内所对应的图像矩阵进行直方图均衡化,设候选框区域为[(a,b),(a+l,b+l)]所围成的区域,xden″即为xden′在[(a,b),(a+l,b+l)]区域内的图像信息,其步骤为:第一步,构造向量i,i(ii)为xden″中像素值等于ii的个数,0≤ii≤255;第二步,计算向量
所述的将光照补偿后的图像进行图像增强,设光照补偿后的图像为xcpst,其对应的rgb通道分别为xcpstr,xcpstg,xcpstb,对xcpst图像增强后得到的图像为xenh。对其进行图像增强的步骤为:第一步,对于xcpst的所有分量xcpstr,xcpstg,xcpstb计算其按指定尺度进行模糊后的图像;第二步,构造矩阵lxenhr,lxenhg,lxenhb为与xcpstr相同维度的矩阵,对于图像xcpst的rgb通道中的r通道,计算lxenhr(i,j)=log(xcpstr(i,j))-lxcpstr(i,j),(i,j)的取值范围为图像矩阵中所有的点,对于图像xcpst的rgb通道中的g通道和b通道采用与r通道同样的算法得到lxenhg和lxenhb;第三步,对于图像xcpst的rgb通道中的r通道,计算lxenhr中所有点取值的均值meanr和均方差varr(注意是均方差),计算minr=meanr-2×varr和maxr=meanr+2×varr,然后计算xenhr(i,j)=fix((lxcpstr(i,j)-minr)/(maxr-minr)×255),其中fix表示取整数部分,若取值<0则赋值为0,取值>255则赋值为255;对于rgb通道中的g通道和b通道采用与r通道同样的算法得到xenhg和xenhb,将分别属于rgb通道的xenhr、xenhg、xenhb整合成一张彩色图像xenh。
所述的对于xcpst的所有分量xcpstr,xcpstg,xcpstb计算其按指定尺度进行模糊后的图像,对于rgb通道中的r通道xcpstr,其步骤为:第一步,定义高斯函数g(x,y,σ)=k×exp(-(x2+y2)/σ2),σ为尺度参数,k=1/∫∫g(x,y)dxdy,则对于xcpstr的每一个点xcpstr(i,j)计算,
所述的目标检测模块,在初始化过程中,使用带有已标定人体图像区域、人脸面部区域、手部区域和产品区域的图像对目标检测算法进行参数初始化;在检测过程中,接收图像预处理模块所传递来的图像,然后对其进行处理,对每一帧图像使用目标检测算法进行目标检测,得到当前图像的人体图像区域、人脸面部区域、手部区域和产品区域,然后将手部区域和产品区域发送给购物动作识别模块,把人体图像区域和人脸面部区域发送给个体识别模块,把产品区域传递给产品识别模块;
所述的使用带有已标定人体图像区域、人脸面部区域、手部区域和产品区域的图像对目标检测算法进行参数初始化,其步骤为:第一步,构造特征抽取深度网络;第二步,构造区域选择网络,第三步,根据所述的构造特征抽取深度网络中所使用的数据库中的每一张图像x和对应的人工标定的每个人体区域
所述的构造特征抽取深度网络,该网络为深度学习网络结构,其网络结构为:第一层:卷积层,输入为768×1024×3,输出为768×1024×64,通道数channels=64;第二层:卷积层,输入为768×1024×64,输出为768×1024×64,通道数channels=64;第三层:池化层,输入第一层输出768×1024×64与第三层输出768×1024×64在第三个维度上相连接,输出为384×512×128;第四层:卷积层,输入为384×512×128,输出为384×512×128,通道数channels=128;第五层:卷积层,输入为384×512×128,输出为384×512×128,通道数channels=128;第六层:池化层,输入第四层输出384×512×128与第五层384×512×128在第三个维度上相连接,输出为192×256×256;第七层:卷积层,输入为192×256×256,输出为192×256×256,通道数channels=256;第八层:卷积层,输入为192×256×256,输出为192×256×256,通道数channels=256;第九层:卷积层,输入为192×256×256,输出为192×256×256,通道数channels=256;第十层:池化层,输入为第七层输出192×256×256与第九层192×256×256在第三个维度上相连接,输出为96×128×512;第十一层:卷积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十二层:卷积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十三层:卷积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十四层:池化层,输入为第十一层输出96×128×512与第十三层96×128×512在第三个维度上相连接,输出为48×64×1024;第十五层:卷积层,输入为48×64×1024,输出为48×64×512,通道数channels=512;第十六层:卷积层,输入为48×64×512,输出为48×64×512,通道数channels=512;第十七层:卷积层,输入为48×64×512,输出为48×64×512,通道数channels=512;第十八层:池化层,输入为第十五层输出48×64×512与第十七层48×64×512在第三个维度上相连接,输出为48×64×1024;第十九层:卷积层,输入为48×64×1024,输出为48×64×256,通道数channels=256;第二十层:池化层,输入为48×64×256,输出为24×62×256;第二十一层:卷积层,输入为24×32×1024,输出为24×32×256,通道数channels=256;第二十二层:池化层,输入为24×32×256,输出为12×16×256;第二十三层:卷积层,输入为12×16×256,输出为12×16×128,通道数channels=128;第二十四层:池化层,输入为12×16×128,输出为6×8×128;第二十五层:全连接层,首先将输入的6×8×128维度的数据展开成6144维度的向量,然后输入进全连接层,输出向量长度为768,激活函数为relu激活函数;第二十六层:全连接层,输入向量长度为768,输出向量长度为96,激活函数为relu激活函数;第二十七层:全连接层,输入向量长度为96,输出向量长度为2,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2);设设该深度网络为fconv27,对于一幅彩色图像x,经过该深度网络所得到的特征图集合用fconv27(x)表示,该网络的评价函数为对(fconv27(x)-y)计算其交叉熵损失函数,收敛方向为取最小值,y输入对应的分类。数据库为在自然界采集的包含路人及非路人的图像,每张图像为768×1024维度的彩色图像,按照图像中是否包含行人分成两类,迭代次数为2000次。在训练结束后,取第一层到第十七层为特征抽取深度网络fconv,对于一幅彩色图像x,经过该深度网络所得到的输出用fconv(x)表示。
所述的构造区域选择网络,接收fconv深度网络提取出512个48×64特征图集合fconv(x),然后第一步经过卷积层得到conv1(fconv(x)),该卷积层的参数为:卷积核kernel大小=1,步长stride=(1,1),输入为48×64×512,输出为48×64×512,通道数channels=512;然后将conv1(fconv(x))分别输入到两个卷积层(conv2-1和conv2-2),conv2-1的结构为:输入为48×64×512,输出为48×64×18,通道数channels=18,该层得到的输出为conv2-1(conv1(fconv(x))),再对该输出使用激活函数softmax得到softmax(conv2-1(conv1(fconv(x))));conv2-2的结构为:输入为48×64×512,输出为48×64×36,通道数channels=36;该网络的损失函数有两个:第一个误差函数loss1为对wshad-cls⊙(conv2-1(conv1(fconv(x)))-wcls(x))计算softmax误差,第二个误差函数loss2为对wshad-reg(x)⊙(conv2-1(conv1(fconv(x)))-wreg(x))计算smoothl1误差,区域选择网络的损失函数=loss1/sum(wcls(x))+loss2/sum(wcls(x)),sum(·)表示矩阵所有元素之和,收敛方向为取最小值,wcls(x)和wreg(x)分别为数据库图像x对应的正负样本信息,⊙表示矩阵按照对应位相乘,wshad-cls(x)和wshad-reg(x)为掩码,其作用为选择wshad(x)中权值为1的部分进行训练,从而避免正负样本数量差距过大,每次迭代时重新生成wshad-cls(x)和wshad-reg(x),算法迭代1000次。
所述的构造特征抽取深度网络中所使用的数据库,对于数据库中的每一张图像,第一步:人工标定每个人体图像区域、人脸面部区域、手部区域和产品区域,设其在输入图像的中心坐标为(abas_tr,bbas_tr),中心坐标在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离左右边框的距离为wbas_tr,则其对应于conv1的位置为中心坐标为
所述的随机生成正负样本,其方法为:第一步,构造9个区域框,第二步,对于数据库的每一张图像xtr,设wcls为48×64×18维度,wreg为48×64×36维度,所有初始值均为0,对wcls和wreg进行填充。
所述的构造9个区域框,这9个区域框分别为:ro1(xro,yro)=(xro,yro,64,64),ro2(xro,yro)=(xro,yro,45,90),ro3(xro,yro)=(xro,yro,90,45),ro4(xro,yro)=(xro,yro,128,128),ro5(xro,yro)=(xro,yro,90,180),ro6(xro,yro)=(xro,yro,180,90),ro7(xro,yro)=(xro,yro,256,256),ro8(xro,yro)=(xro,yro,360,180),ro9(xro,yro)=(xro,yro,180,360),对于每一个区域块,roi(xro,yro)表示对于第i个区域框,当前区域框的中心坐标(xro,yro),第三位表示中心点距离上下边框的像素距离,第四位表示中心点距离左右边框的像素距离,i的取值从1到9。
所述的对wcls和wreg进行填充,其方法为:
对于每一个人工标定的人体区间,设其在输入图像的中心坐标为(abas_tr,bbas_tr),中心坐标在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离左右边框的距离为wbas_tr,则其对应于conv1的位置为中心坐标为
对于左上角
对于i取值从1到9:
对于点(xctr,yctr),其在数据库图像的映射区间为左上角点(16(xctr-1)+1,16(yctr-1)+1)右下角点(16xctr,16yctr)所围成的16×16区间,对于该区间的每一个点(xotr,yotr):
计算(xotr,yotr)所对应区域roi(xotr,yotr)与当前人工标定的区间的重合率;
选择当前16×16区间内重合率最高的点(xioumax,yioumax),若重合率>0.7,则wcls(xctr,yctr,2i-1)=1,wcls(xctr,yctr,2i)=0,该样本为正样本,wreg(xctr,yctr,4i-3)=(xotr-16xctr+8)/8,wreg(xctr,yctr,4i-2)=(yotr-16yctr+8)/8,wreg(xctr,yctr,4i-2)=down1(lbas_tr/roi的第三位),wreg(xctr,yctr,4i)=down1(wbas_tr/roi的第四位),down1(·)表示若值大于1则取值为1;若重合率<0.3,则wcls(xctr,yctr,2i-1)=0,wcls(xctr,yctr,2i)=1;否则wcls(xctr,yctr,2i-1)=-1,wcls(xctr,yctr,2i)=-1.
若当前人工标定的人体区域没有重合率>0.6的roi(xotr,yotr),则选择重合率最高的roi(xotr,yotr)对wcls和wreg赋值,赋值方法与重合率>0.7的赋值方法相同。
所述的计算(xotr,yotr)所对应区域roi(xotr,yotr)与当前人工标定的区间的重合率,其方法为:设人工标定的人体区间在输入图像的中心坐标为(abas_tr,bbas_tr),中心坐标在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离左右边框的距离为wbas_tr,设roi(xotr,yotr)的第三位为lotr,第四位为wotr,若满足|xotr-abas_tr|≤lotr+lbas_tr-1并且|yotr-bbas_tr|≤wotr+wbas_tr-1,说明存在重合区域,重合区域=(lotr+lbas_tr-1-|xotr-abas_tr|)×(wotr+wbas_tr-1-|yotr-bbas_tr|),否则重合区域=0;计算全部区域=(2lotr-1)×(2wotr-1)+(2abas_tr-1)×(2wbas_tr-1)-重合区域;从而得到重合率=重合区域/全部区域,|·|表示取绝对值。
所述的wshad-cls(x)和wshad-reg(x),其构造方法为:对于该图像x,其对应的正负样本信息为wcls(x)和wreg(x),第一步,构造wshad-cls(x)与和wshad-reg(x),wshad-cls(x)与wcls(x)维度相同,wshad-reg(x)与wreg(x)维度相同;第二步,记录所有正样本的信息,对于i=1到9,若wcls(x)(a,b,2i-1)=1,则wshad-cls(x)(a,b,2i-1)=1,wshad-cls(x)(a,b,2i)=1,wshad-reg(x)(a,b,4i-3)=1,wshad-reg(x)(a,b,4i-2)=1,wshad-reg(x)(a,b,4i-1)=1,wshad-reg(x)(a,b,4i)=1,正样本一共选择了sum(wshad-cls(x))个,sum(·)表示对矩阵的所有元素求和,若sum(wshad-cls(x))>256,随机保留256个正样本;第三步,随机选择负样本,随机选择(a,b,i),若wcls(x)(a,b,2i-1)=1,则wshad-cls(x)(a,b,2i-1)=1,wshad-cls(x)(a,b,2i)=1,wshad-reg(x)(a,b,4i-3)=1,wshad-reg(x)(a,b,4i-2)=1,wshad-reg(x)(a,b,4i-1)=1,wshad-reg(x)(a,b,4i)=1,若已选中的负样本数量为256-sum(wshad-cls(x))个,或者虽然负样本数量不足256-sum(wshad-cls(x))个但是在20次生成随机数(a,b,i)内都无法得到负样本,则算法结束。
所述的roi层,其输入为图像x和区域
对于iroi=1:到7:
对于jroi=1到7:
构造区间
roii(x)(iroi,jroi)=区间内最大点的值。
当512个48×64矩阵全部处理结束后,将输出拼接得到7×7×512维度的输出
所述的构建坐标精炼网络,其方法为:第一步,扩展数据库:扩展方法为对于数据库中的每一张图像x和对应的人工标定的每个区域
所述的两个全连接层fc2,其结构为:第一层:全连接层,输入向量长度为25088,输出向量长度为4096,激活函数为relu激活函数;第二层:全连接层,输入向量长度为4096,输出向量长度为512,激活函数为relu激活函数。
所述的对每一帧图像使用目标检测算法进行目标检测,得到当前图像的人体图像区域、人脸面部区域、手部区域和产品区域,其步骤为:
第一步,将输入图像xcpst分割成768×1024维度的子图;
第二步,对于每一个子图xs:
第2.1步,使用在初始化时构造的特征抽取深度网络fconv进行变换,得到512个特征子图集合fconv(xs);
第2.2步,对fconv(xs)使用区域选择网络中第一层conv1、第二层conv2-1+soffmax激活函数和conv2-2进变换,分别得到输出soffmax(conv2-1(conv1(fconv(xs))))和conv2-2(conv1(fconv(xs))),然后根据输出值得到该区间内的所有的初步候选区间;
第2.3步,对于当前帧图像的所有子图的所有的初步候选区间:
第2.3.1步,根据其当前候选区域的得分大小进行选取,选取最大的50个初步候选区间作为候选区域;
第2.3.2步,调整候选区间集合中所有的越界候选区间,然后剔除掉候选区间中重叠的框,从而得到最终候选区间;
第2.3.3步,将子图xs和每一个最终候选区间输入到roi层,得到对应的roi输出,设当前的最终候选区间为(abb(1),bbb(2),lbb(3),wbb(4)),然后计算fbbox(fc2(roi))得到四位输出(outbb(1),outbb(2),outbb(3),outbb(4))从而得到更新后的坐标(abb(1)+8×outbb(1),bbb(2)+8×outbb(2),lbb(3)+8×outbb(3),wbb(4)+8×outbb(4));然后计算fclass(fc2(roi))得到输出,若输出第一位最大则当前区间为人体图像区域,若输出第二位最大则当前区间为人脸面部区域,若输出第三位最大则当前区间为手部区域,若输出第四位最大则当前区间为产品区域,若输出第五位最大则当前区间为负样本区域并删除该最终候选区间。第三步,更新所有子图的精炼后的最终候选区间的坐标,更新的方法为设当前候选区域的坐标为(tlx,tly,rbx,rby),其对应的子图的左上角坐标为(seasub,sebsub),更新后的坐标为(tlx+seasub-1,tly+sebsub-1,rbx,rby)。
所述的将输入图像xcpst分割成768×1024维度的子图,其步骤为:设分割的步长为384和512,设窗口大小为m行n列,(asub,bsub)为选定的区域的左上角坐标,(a,b)的初始值为(1,1);当asub<m时:
bsub=1:
当bsub<n时:
选定的区域为[(asub,bsub),(asub+384,bsub+512)],将输入图像xcpst上该区间所对应的图像区域的信息复制到新的子图中,并附带左上角坐标(asub,bsub)作为位置信息;若选定区域超出输入图像xcpst区间,则将超出范围内的像素点对应的rgb像素值均赋值为0;
bsub=bsub+512:
内层循环结束;
asub=asub+384:
外层循环结束;
所述的根据输出值得到该区间内的所有的初步候选区间,其方法为:第一步:对于softmax(conv2-1(conv1(fconv(xs))))其输出为48×64×18,对于conv2-2(conv1(fconv(xs))),其输出为48×64×36,对于48×64维空间上的任何一点(x,y),softmax(conv2-1(conv1(fconv(xs))))(x,y)为18维向量ii,conv2_2(conv1(fconv(xs)))(x,y)为36维向量iiii,若ii(2i-1)>ii(2i),对于i取值从1到9,lotr为roi(xotr,yotr)的第三位,wotr为roi(xotr,yotr)的第四位,则初步候选区间为[ii(2i-1),(8×iiii(4i-3)+x,8×iiii(4i-2)+y,lotr×iiii(4i-1),wotr×iiii(4i))],其中第一位ii(2i-1)表示当前候选区域的得分,第二位(8×iiii(4i-3)+x,8×iiii(4i-2)+y,iiii(4i-1),iiii(4i))表示当前候选区间的中心点为(8×iiii(4i-3)+x,8×iiii(4i-2)+y),候选框的半长半宽分别为lotr×iiii(4i-1)和wotr×iiii(4i))。
所述的调整候选区间集合中所有的越界候选区间,其方法为:设监控图像为m行n列,对于每一个候选区间,设其[(ach,bch)],候选框的半长半宽分别为lch和wch,若ach+lch>m,则
所述的剔除掉候选区间中重叠的框,其步骤为:
若候选区间集合不为空:
从候选区间集合中取出得分最大的候选区间iout:
计算候选区间iout与候选区间集合中的每一个候选区间ic的重合率,若重合率>0.7,则从候选区间集合删除候选区间ic;
将候选区间iout放入输出候选区间集合;
当候选区间集合为空时,输出候选区间集合内所含的候选区间即为剔除掉候选区间中重叠的框后所得到的候选区间集合。
所述的计算候选区间iout与候选区间集合中的每一个候选区间ic的重合率,其方法为:设候选区间ic的坐标区间为中心点[(aic,bic)],候选框的半长半宽分别为lic和wic,候选区间ic的坐标区间为中心点[(aiout,bicout)],候选框的半长半宽分别为liout和wiout;计算xa=max(aic,aiout);ya=max(bic,biout);xb=min(lic,liout),yb=min(wic,wiout);若满足|aic-aiout|≤lic+liout-1并且|bic-biout|≤wic+wiout-1,说明存在重合区域,重合区域=(lic+liout-1-|aic-aiout|)×(wic+wiout-1-|bic-biout|),否则重合区域=0;计算全部区域=(2lic-1)×(2wic-1)+(2liout-1)×(2wiout-1)-重合区域;从而得到重合率=重合区域/全部区域。
所述的购物动作识别模块,其方法是:在初始化时,首先使用标准的手部动作图像对静态动作识别分类器进行初始化,从而使静态动作识别分类器能够识别出手的抓握、放下动作;然后使用手部动作视频对动态动作识别分类器进行初始化,从而使动态动作识别分类器能够识别出手的取出物品、放回物品、取出又放回、已取出物品未放回或者是可疑偷窃;在检测过程中:第一步,对接收到的每一个手部区域信息使用静态动作识别分类器进行识别,识别方法为:设每一次输入的图像为handp1,输出为staticn(handp1)为3位向量,若第一位最大则识别为抓握,若第二位最大则识别为放下,若第三位最大则识别为其他;第二步,当识别到抓握动作后,对当前抓握动作对应区域进行目标跟踪,若当前手部区域的下一帧跟踪框所对应的使用静态动作识别分类器的识别结果为放下动作时,目标跟踪结束,将当前得到的从识别到抓握动作为视频开始、识别到放下动作为视频结束,从而得到手部动作的连续视频,将该视频标记为完整视频。若跟踪过程中跟踪丢失,则将当前得到的从识别到抓握动作为视频开始、从跟踪丢失前的图像作为视频结束,从而得到只有抓握动作的视频,则将该视频标记为只有抓握动作的视频;当识别到放下动作,并且该动作不在目标跟踪所得到的图像中,说明该动作的抓握动作丢失,则以当前图像对应的手部区域为视频结束,使用目标跟踪方法从当前帧开始向前进行跟踪,直到跟踪丢失,则丢失帧的下一帧作为视频的起始帧,将该视频标记为只有放下动作的视频。第三步,将第二步所得到的完整视频使用动态动作识别分类器进行识别,识别方法为:设每一次输入的图像为handv1,输出为dynamicn(handv1)为5位向量,若第一位最大则识别为取出物品,若第二位最大则识别为放回物品,若第三位最大则识别为取出又放回,若第四位最大则识别为已取出物品未放回,若第五位最大则识别为可疑偷窃的动作,然后将该识别结果发送给识别结果处理模块,将只有抓握动作的视频和只有放下动作的视频发送给识别结果处理模块,将完整视频和只有抓握动作的视频发送给产品识别模块和个体识别模块。
所述的使用标准的手部动作图像对静态动作识别分类器进行初始化,其方法为:第一步,整理视频数据:首先,选取大量的人在超市里购物的视频,这些视频包含取出物品、放回物品、取出又放回、已取出物品未放回和可疑偷窃的动作;人工对每一段视频片段进行截取,以人手碰到商品为起始帧,以人手离开商品为结束帧,然后对于视频的每一帧使用目标检测模块提取其手部区域,然后将手部区域的每一帧图像缩放为256×256的彩色图像,将缩放后视频放入手部动作视频集合,并标记该视频为取出物品、放回物品、取出又放回、已取出物品未放回和可疑偷窃的动作中的一种;对于类别为取出物品、放回物品、取出又放回、已取出物品未放回的每一个视频,将该视频的第一帧放入手部动作图像集合并标记为抓握动作,将该视频的最后一帧放入手部动作图像集合并标记为放下动作,从该视频除第一帧和最后一针外随机取一帧放入手部动作图像集合并标记为其他。从而得到手部动作视频集合和手部动作图像集合;第二步,构造静态动作识别分类器staticn;第三步,对静态动作识别分类器staticn进行初始化,其输入为第一步所构造的手部动作图像集合,设每一次输入的图像为handp,输出为staticn(handp),其类别为yhandp,yhandp的表示方法为:抓握:yhandp=[1,0,0],放下:yhandp=[0,1,0],其他:yhandp=[0,0,1],该网络的评价函数为对(staticn(handp)-yhandp)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次。
所述的构造静态动作识别分类器staticn,其网络结构为:第一层:卷积层,输入为256×256×3,输出为256×256×64,通道数channels=64;第二层:卷积层,输入为256×256×64,输出为256×256×64,通道数channels=64;第三层:池化层,输入第一层输出256×256×64与第三层输出256×256×64在第三个维度上相连接,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;第二十二层:池化层,输入为4×4×128,输出为2×2×128;第二十三层:全连接层,首先将输入的2×2×128维度的数据展开成512维度的向量,然后输入进全连接层,输出向量长度为128,激活函数为relu激活函数;第二十四层:全连接层,输入向量长度为128,输出向量长度为32,激活函数为relu激活函数;第二十五层:全连接层,输入向量长度为32,输出向量长度为3,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。
所述的使用手部动作视频对动态动作识别分类器进行初始化,其方法为:第一步,构造数据集合:将所述的使用标准的手部动作图像对静态动作识别分类器进行初始化时第一步所构造的手部动作视频集合均匀提取10帧图像,作为输入;第二步,构造动态动作识别分类器dynamicn;第三步,对动态动作识别分类器dynamicn进行初始化,其输入为第一步对每一个视频提取的10帧图像所构成的集合,设每一次输入的10帧图像为handv,输出为dynamicn(handv),其类别为yhandv,yhandv的表示方法为:取出物品:yhandv=[1,0,0,0,0]、放回物品:yhandv=[0,1,0,0,0]、取出又放回:yhandv=[0,0,1,0,0]、已取出物品未放回:yhandv=[0,0,0,1,0]和可疑偷窃的动作:yhandv=[0,0,0,0,1],该网络的评价函数为对(dynamicn(handv)-yhandv)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次。
所述的均匀提取10帧图像,其方法为:对于一段视频图像,设其长度为nf帧。首先将视频图像的第1帧图像提取出来作为所提取的集合的第1帧,将视频图像的最后一帧图像提取出来作为所提取的集合的第10帧,所提取的集合的第ickt帧为视频图像的第
所述的构造动态动作识别分类器dynamicn,其网络结构为:
第一层:卷积层,输入为256×256×30,输出为256×256×512,通道数channels=512;第二层:卷积层,输入为256×256×512,输出为256×256×128,通道数channels=128;第三层:池化层,输入为256×256×128,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;第二十二层:池化层,输入为4×4×128,输出为2×2×128;第二十三层:全连接层,首先将输入的2×2×128维度的数据展开成512维度的向量,然后输入进全连接层,输出向量长度为128,激活函数为relu激活函数;第二十四层:全连接层,输入向量长度为128,输出向量长度为32,激活函数为relu激活函数;第二十五层:全连接层,输入向量长度为32,输出向量长度为3,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。
所述的当识别到抓握动作后,对当前抓握动作对应区域进行目标跟踪,其方法为:设当前识别到的抓握动作的图像为hgrab,当前跟踪区域为图像hgrab所对应的区域。第一步,提取图像hgrab的orb特征orbhgrab;第二步,对于hgrab的下一帧内的所有手部区域对应的图像计算其orb特征从而得到orb特征集合,并删掉被其他跟踪框选中的orb特征;第三步,将orbhgrab与orb特征集合的每一个值比较其汉明距离,选取与orbhgrab特征的汉明距离最小的orb特征为选中的orb特征,若选中的orb特征与orbhgrab特征的相似度>0.85,相似度=(1-两个orb特征的汉明距离/orb特征长度),则选中的orb特征对应的手部区域即为图像hgrab在下一帧的跟踪框,否则若相似度<0.85表明跟踪丢失。
所述的orb特征,从一个图像中提取orb特征的方法已经较为成熟,在opencv计算机视觉库里边已有实现;对一个图片提取其orb特征,输入值为当前图片,输出为若干组长度相同的字符串,每一组代表一个orb特征。
所述的以当前图像对应的手部区域为视频结束,使用目标跟踪方法从当前帧开始向前进行跟踪,直到跟踪丢失,其方法为:设当前识别到的放下动作的图像为hdown,当前跟踪区域为图像hdown所对应的区域。
若未跟踪丢失:
第一步,提取图像hdown的orb特征orbhdown,由于该过程在所述的当识别到抓握动作后,对当前抓握动作对应区域进行目标跟踪的过程中已经计算得到,所以此处不需要再次计算;
第二步,对于图像hdown的前一帧内的所有手部区域对应的图像计算其orb特征从而得到orb特征集合,并删掉被其他跟踪框选中的orb特征;
第三步,将orbhdown与orb特征集合的每一个值比较其汉明距离,选取与orbhdown特征的汉明距离最小的orb特征为选中的orb特征,若选中的orb特征与orbhdown特征的相似度>0.85,相似度=(1-两个orb特征的汉明距离/orb特征长度),则选中的orb特征对应的手部区域即为图像hdown在下一帧的跟踪框,否则若相似度<0.85表明跟踪丢失,算法结束。
所述的产品识别模块,其方法是:在初始化时,首先使用各个角度的产品图像集合对产品识别分类器进行初始化,并对产品图像生成产品列表;在变更产品列表时:若删除某产品,则从各个角度的产品图像集合中删除该产品的图像,并将产品列表中对应位置删除,若增加某产品,则将当前产品的各个角度的产品图像放入各个角度的产品图像集合,将产品列表最后一位的后边添加当前增加产品的名称,然后用新的各个角度的产品图像集合和新的产品列表更新产品识别分类器;在检测过程中,第一步,根据购物动作识别模块传递来的完整视频和只有抓握动作的视频,首先根据当前视频第一帧所对应的在目标检测模块所得到的位置,对该位置的输入视频图像从当前视频第一帧向前检测,检测到该区域没有被遮挡的帧,最后将帧所对应的区域的图像作为产品识别分类器的输入进行识别,从而得到当前产品的识别结果,识别方法为:设每一次输入的图像为goods1,输出为goodsn(goods1)为一个向量,设该向量的第igoods位最大,则表明当前识别结果为产品列表中的第igoods位的产品,将识别结果发送给识别结果处理模块;
所述的首先使用各个角度的产品图像集合对产品识别分类器进行初始化,并对产品图像生成产品列表,其方法为:第一步,构造数据集合和产品列表:该数据集合为产品各个角度的图像,产品列表listgoods为一个向量,向量的每一位对应一个产品名字;第二步,构造产品识别分类器goodsn;第三步,对构造产品识别分类器goodsn进行初始化,其输入为各个角度的产品图像集合,设输入图像为goods,输出为goodsn(goods),其类别为ygoods,ygoods为一组向量,长度等于产品列表中产品的个数,ygoods的表示方法为:若图像goods为第igoods位的产品,则ygoods的第igoods位为1,其他位为0.该网络的评价函数为对(goodsn(goods)-ygoods)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次。
所述的构造产品识别分类器goodsn,其网络层结构两组goodsn1和goodsn2,其中goodsn1的网络结构为:第一层:卷积层,输入为256×256×3,输出为256×256×64,通道数channels=64;第二层:卷积层,输入为256×256×64,输出为256×256×128,通道数channels=128;第三层:池化层,输入为256×256×128,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。goodsn2的网络结构为:输入为4×4×128,首先将输入的数据展开成2048维度的向量,然后输入进第一层;第一层:全连接层,输入向量长度为2048,输出向量长度为1024,激活函数为relu激活函数;第二层:全连接层,输入向量长度为1024,输出向量长度为1024,激活函数为relu激活函数;第三层:全连接层,输入向量长度为1024,输出向量长度为len(listgoods),激活函数为soft-max激活函数;len(listgoods)表示产品列表的长度。对于任一输入goods2,goodsn(goods2)=goodsn2(goodsn1(goods2))。
所述的用新的各个角度的产品图像集合和新的产品列表更新产品识别分类器,其方法为:第一步,修改网络结构:对于新构造的产品识别分类器goodsn′,其goodsn1′的网络结构不变,与初始化时的goodsn1网络结构相同,其goodsn2′网络结构的第一层和第二层结构保持不变,第三层的输出向量长度变为更新后的产品列表的长度;第二步,对于新构造的产品识别分类器goodsn′进行初始化:其输入为新的各个角度的产品图像集合,设输入图像为goods3,输出为goodsn′(goods3)=goodsn2′(goodsn1(goods3)),其类别为ygoods3,ygoods为一组向量,长度等于更新后的产品列表的个数,ygoods的表示方法为:若图像goods为第igoods位的产品,则ygoods的第igoods位为1,其他位为0.该网络的评价函数为对(goodsn(goods)-ygoods)计算其交叉熵损失函数,收敛方向为取最小值,在初始化过程中goodsn1中的参数值保持不变,迭代次数为500次。
所述的根据当前视频第一帧所对应的在目标检测模块所得到的位置,对该位置的输入视频图像从当前视频第一帧向前检测,检测到该区域没有被遮挡的帧,其方法为:设当前视频第一帧所对应的在目标检测模块所得到的位置为(agoods,bgoods,lgoods,wgoods),设当前当前视频第一帧为第icrgs帧,当前处理帧icr=icrgs:第一步,第icr帧在目标检测模块所得到的所有检测区域为taskicr;第二步,对于taskicr中的每一个区域框(atask,btask,ltask,wtask),计算其距离dgt=(atask-agoods)2+(btask-bgoods)2-(ltask+lgoods)2-(wtask+wgoods)2。若不存在距离<0,则第icr帧对应的(agoods,bgoods,lgoods,wgoods)区域即为检测到的检测到的该区域没有被遮挡的帧,算法结束;否则,若存在距离<0,则记录距离列表d中的d(icr)=最小距离,并icr=icr-1,若icr>0,则算法跳转至第一步,若icr≤0,则选择距离列表d中值最大的记录,取该记录对应帧对应的(agoods,bgoods,lgoods,wgoods)即为检测到的检测到的该区域没有被遮挡的帧,算法结束。
所述的个体识别模块,其方法是:在初始化时,首先使用各个角度的人脸图像集合对人脸特征提取器facen进行初始化并计算μface,然后使用各个角度的人体图像对人体特征提取器bodyn进行初始化并计算μbody;在检测过程中,当用户进入超市时,通过目标检测模块得到当前人体区域body1和人体区域内的人脸的图像face1,然后分别使用人体特征提取器bodyn和人脸特征提取器facen提取人体特征bodyn(body1)和人脸特征facen(face1),保存bodyn(body1)在bodyftu集合中,保存facen(face1)在faceftu集合中,并保存当前客户的id信息,id信息可以是用户在超市的账户或者是用户进入超市时随机分配的不重复的数字,id信息用来区分不同顾客,每当有顾客进入超市,则提取其人体特征和人脸特征;当超市内用户移动产品时,根据购物动作识别模块传递来的完整视频和只有抓握动作的视频,寻找到其对应的人体区域和人脸区域,使用人脸特征提取器facen和人体特征提取器bodyn进行人脸识别或人体识别方式,得到当前购物动作识别模块传递来的视频所对应的顾客的id。
所述的使用各个角度的人脸图像集合对人脸特征提取器facen进行初始化并计算μface,其方法为:第一步,选取各个角度的人脸图像集合构成人脸数据集;第二步,构造人脸特征提取器facen并使用人脸数据集进行初始化;第三步:
对于人脸数据集中的每一个人ipeop,得到人脸数据集中所有属于ipeop的人脸图像集合faceset(ipeop):
对于faceset(ipeop)中的每一张人脸图像face(jipeop):
计算人脸特征facen(face(jipeop));
统计当前人脸图像集合faceset(ipeop)中所有人脸特征的平均值作为当前人脸图像的中心center(facen(face(jipeop))),计算当前人脸图像集合faceset(ipeop)中所有人脸特征
与当前人脸图像的中心center(facen(face(jipeop)))的距离构成ipeop对应的距离集合。待人脸数据集中的所有人都得到其对应的距离集合,将距离集合从小到大排列后,设距离集合长度为ndiset,
所述的构造人脸特征提取器facen并使用人脸数据集进行初始化,设人脸数据集由nfaceset个人构成,其网络层结构facen25为:第一层:卷积层,输入为256×256×3,输出为256×256×64,通道数channels=64;第二层:卷积层,输入为256×256×64,输出为256×256×64,通道数channels=64;第三层:池化层,输入第一层输出256×256×64与第三层输出256×256×64在第三个维度上相连接,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;第二十二层:池化层,输入为4×4×128,输出为2×2×128;第二十三层:全连接层,首先将输入的2×2×128维度的数据展开成512维度的向量,然后输入进全连接层,输出向量长度为512,激活函数为relu激活函数;第二十四层:全连接层,输入向量长度为512,输出向量长度为512,激活函数为relu激活函数;第二十五层:全连接层,输入向量长度为512,输出向量长度为nfaceset,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。其初始化过程为:设对于每一张人脸face4,输出为facen25(face4),其类别为yface,yface为长度等于nfaceset的向量,yface的表示方法为:若人脸face4属于人脸图像集合中第iface4个人的人脸,则yface的第iface4位为1,其他位为0.该网络的评价函数为对(facen25(face4)-yface)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次;待迭代结束后,人脸特征提取器facen为facen25网络的从第一层到第二十四层。
所述的使用各个角度的人体图像对人体特征提取器bodyn进行初始化并计算μbody,其方法为:第一步,选取各个角度的人体图像集合构成人体数据集;第二步,构造人体特征提取器bodyn并使用人体数据集进行初始化;第三步:
对于人体数据集中的每一个人ipeop1,得到人体数据集中所有属于ipeop1的人体图像集合bodyset(ipeop1):
对于bodyset(ipeop1)中的每一张人体图像body(jipeop1):
计算人体特征bodyn(body(jipeop1));
统计当前人体图像集合bodyset(ipeop1)中所有人体特征的平均值作为当前人体图像的中心center(bodyn(body(jipeop1))),计算当前人体图像集合bodyset(ipeop1)中所有人体特征与当前人体图像的中心center(bodyn(body(jipeop1)))的距离构成ipeop1对应的距离集合。
待人体数据集中的所有人都得到其对应的距离集合,将距离集合从小到大排列后,设距离集合长度为ndiset1,
所述的构造人体特征提取器bodyn并使用人体数据集进行初始化,设人体数据集由nbodyset个人构成,其网络层结构bodyn25为:第一层:卷积层,输入为256×256×3,输出为256×256×64,通道数channels=64;第二层:卷积层,输入为256×256×64,输出为256×256×64,通道数channels=64;第三层:池化层,输入第一层输出256×256×64与第三层输出256×256×64在第三个维度上相连接,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;第二十二层:池化层,输入为4×4×128,输出为2×2×128;第二十三层:全连接层,首先将输入的2×2×128维度的数据展开成512维度的向量,然后输入进全连接层,输出向量长度为512,激活函数为relu激活函数;第二十四层:全连接层,输入向量长度为512,输出向量长度为512,激活函数为relu激活函数;第二十五层:全连接层,输入向量长度为512,输出向量长度为nfaceset,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。其初始化过程为:设对于每一张人体body4,输出为bodyn25(body4),其类别为ybody,ybody为长度等于nbodyset的向量,ybody的表示方法为:若人体body4属于人体图像集合中第ibody4个人的人体,则ybody的第ibody4位为1,其他位为0.该网络的评价函数为对(bodyn25(body4)-ybody)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次;待迭代结束后,人体特征提取器bodyn为bodyn25网络的从第一层到第二十四层。
所述的根据购物动作识别模块传递来的完整视频和只有抓握动作的视频,寻找到其对应的人体区域和人脸区域,使用人脸特征提取器facen和人体特征提取器bodyn进行人脸识别或人体识别方式,得到当前购物动作识别模块传递来的视频所对应的顾客的id。其过程为:根据购物动作识别模块传递来的视频,从视频的第一帧开始寻找到对应的人体区域和人脸区域,直到算法终止或者已经处理完视频的最后一帧:
将对应的人体区域图像body2和人脸区域图像face2分别使用人体特征提取器bodyn和人脸特征提取器facen提取人体特征bodyn(body2)和人脸特征facen(face2);
然后首先使用人脸识别信息:比较facen(face2)与faceftu集合中所有人脸特征的欧氏距离dface,选择欧氏距离最小时所对应的faceftu集合中的特征,设该特征为facen(face3),若dface<μface,则识别出当前人脸图像属于facen(face3)所对应人脸图像的客户id即为购物动作识别模块传递来的视频动作所对应的id,当前识别过程结束;
若dface≥μface,表明无法仅用人脸识别方式对当前个体进行识别,则比较bodyn(body2)与bodyftu集合中所有人体特征的欧氏距离dbody,选择欧氏距离最小时所对应的bodyftu集合中的特征,设该特征为bodyn(face3),若dbody+dface<μface+μbody,则识别出当前人体图像属于bodyn(face3)所对应人体图像的客户id即为购物动作识别模块传递来的视频动作所对应的id。
若在处理完视频的所有帧后仍然没有找到视频动作所对应的id,为了避免错误识别购物主体造成错误的记账,因此对当前购物动作识别模块传递来的视频不再进行处理。
所述的根据购物动作识别模块传递来的视频,从视频的第一帧开始寻找到对应的人体区域和人脸区域,其方法为:根据购物动作识别模块传递来的视频,从视频的第一帧进行处理。设当前处理到第ifrg帧,设该帧对应视频在目标检测模块所得到的位置为(aifrg,bifrg,lifrg,wifrg),该帧对应的在目标检测模块所得到的人体区域集合为bodyframesetifrg人体区域集合为faceframesetifrg,对于bodyframesetifrg中的每一个人体区域(abfsifrg,bbfsifrg,lbfsifrg,wbfsifrg),计算其距离dgbt=(abfsifrg-aifrg)2+(bbfsifrg-bifrg)2-(lbfsifrg-lifrg)2-(wbfsifrg-wifrg)2,选择所有人体区域集合中距离最小的人体区域为当前视频对应的人体区域,设选中的人体区域为位置为(abfs1,bbfs1,lbfs1,wbfs1),对于人脸区域集合为faceframesetifrg中的每一个人脸区域(affsifrg,bffsifrg,lffsifrg,wffsifrg),计算其距离dgft=(abfs1-affsifrg)2+(bbfs1-bffsifrg)2-(lbfs1-lffsifrg)2-(wbfs1-wffsifrg)2,选择所有人脸区域集合中距离最小的人脸区域为当前视频对应的人脸区域。
所述的识别结果处理模块,在初始化时不工作。在识别过程中,对接收到的识别结果进行整合从而生成每一位顾客对应的购物清单:首先根据个体识别模块传递来的顾客的id确定当前购物信息对应的顾客,从而选中被修改的购物清单号为id,然后根据产品识别模块传递来的识别结果来确定当前顾客的购物动作对应的产品设产品为gooda,然后根据购物动作识别模块传递来的识别结果来确定当前购物动作是否对购物车进行修改,若识别为取出物品则在购物清单id上增加产品gooda,增加数量为1个,若识别为放回物品则在购物清单id上减少产品gooda,减少数量为1个,若识别为“取出又放回”或者“已取出物品未放回”则购物清单不改变,若识别结果为“可疑偷窃”则向超市监控发送报警信号和当前视频对应的位置信息。
本发明的有益效果是,将商品录入过程提前到购物者取货时,能够将购物过程中最耗时的过程提前到购物过程中,从而去掉结账时扫描商品的时间消耗,大幅度的提高了结账速度,提高了顾客的购物体验。本发明利用模式识别算法对购物者选货的过程中的动作进行识别并计数,对客户取放商品时商品的图片进行识别来获取商品种类,对顾客进行人脸识别并在人脸识别不理想的时候使用人体图像识别来获取顾客的身份,对顾客的异常行为识别来判断是否有偷盗行为。本系统能够在不降低顾客购物体验的前提下实现自动统计功能。本发明涉及顾客的购物记账过程而不改变超市的原有组织结构,从而便于与现有超市组织架构无缝对接。
附图说明
图1是本发明的功能流程图
图2是本发明整体的功能模块及其相互关系框图
具体实施方式
下面结合附图对本发明作进一步的说明。
所述的一种超市智能售货系统,其功能流程图如图1所示,其模块之间的相互关系如图2所示。
下面提供三个具体实施例对本发明所述的一种超市智能售货系统的具体过程进行说明:实施例1:
本实施例实现了一种超市智能售货系统的参数初始化的过程。
1.图像预处理模块,在初始化阶段该模块不工作;
2.人体目标检测模块,在初始化过程中,使用带有已标定人体图像区域、人脸面部区域、手部区域和产品区域的图像对目标检测算法进行参数初始化。
所述的使用带有已标定人体图像区域、人脸面部区域、手部区域和产品区域的图像对目标检测算法进行参数初始化,其步骤为:第一步,构造特征抽取深度网络;第二步,构造区域选择网络,第三步,根据所述的构造特征抽取深度网络中所使用的数据库中的每一张图像x和对应的人工标定的每个人体区域
所述的构造特征抽取深度网络,该网络为深度学习网络结构,其网络结构为:第一层:卷积层,输入为768×1024×3,输出为768×1024×64,通道数channels=64;第二层:卷积层,输入为768×1024×64,输出为768×1024×64,通道数channels=64;第三层:池化层,输入第一层输出768×1024×64与第三层输出768×1024×64在第三个维度上相连接,输出为384×512×128;第四层:卷积层,输入为384×512×128,输出为384×512×128,通道数channels=128;第五层:卷积层,输入为384×512×128,输出为384×512×128,通道数channels=128;第六层:池化层,输入第四层输出384×512×128与第五层384×512×128在第三个维度上相连接,输出为192×256×256;第七层:卷积层,输入为192×256×256,输出为192×256×256,通道数channels=256;第八层:卷积层,输入为192×256×256,输出为192×256×256,通道数channels=256;第九层:卷积层,输入为192×256×256,输出为192×256×256,通道数channels=256;第十层:池化层,输入为第七层输出192×256×256与第九层192×256×256在第三个维度上相连接,输出为96×128×512;第十一层:卷积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十二层:卷积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十三层:卷积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十四层:池化层,输入为第十一层输出96×128×512与第十三层96×128×512在第三个维度上相连接,输出为48×64×1024;第十五层:卷积层,输入为48×64×1024,输出为48×64×512,通道数channels=512;第十六层:卷积层,输入为48×64×512,输出为48×64×512,通道数channels=512;第十七层:卷积层,输入为48×64×512,输出为48×64×512,通道数channels=512;第十八层:池化层,输入为第十五层输出48×64×512与第十七层48×64×512在第三个维度上相连接,输出为48×64×1024;第十九层:卷积层,输入为48×64×1024,输出为48×64×256,通道数channels=256;第二十层:池化层,输入为48×64×256,输出为24×62×256;第二十一层:卷积层,输入为24×32×1024,输出为24×32×256,通道数channels=256;第二十二层:池化层,输入为24×32×256,输出为12×16×256;第二十三层:卷积层,输入为12×16×256,输出为12×16×128,通道数channels=128;第二十四层:池化层,输入为12×16×128,输出为6×8×128;第二十五层:全连接层,首先将输入的6×8×128维度的数据展开成6144维度的向量,然后输入进全连接层,输出向量长度为768,激活函数为relu激活函数;第二十六层:全连接层,输入向量长度为768,输出向量长度为96,激活函数为relu激活函数;第二十七层:全连接层,输入向量长度为96,输出向量长度为2,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernelsize=2,步长stride=(2,2);设设该深度网络为fconv27,对于一幅彩色图像x,经过该深度网络所得到的特征图集合用fconv27(x)表示,该网络的评价函数为对(fconv27(x)-y)计算其交叉熵损失函数,收敛方向为取最小值,y输入对应的分类。数据库为在自然界采集的包含路人及非路人的图像,每张图像为768×1024维度的彩色图像,按照图像中是否包含行人分成两类,迭代次数为2000次。在训练结束后,取第一层到第十七层为特征抽取深度网络fconv,对于一幅彩色图像x,经过该深度网络所得到的输出用fconv(x)表示。
所述的构造区域选择网络,接收fconv深度网络提取出512个48×64特征图集合fconv(x),然后第一步经过卷积层得到conv1(fconv(x)),该卷积层的参数为:卷积核kernel大小=1,步长stride=(1,1),输入为48×64×512,输出为48×64×512,通道数channels=512;然后将conv1(fconv(x))分别输入到两个卷积层(conv2-1和conv2-2),conv2-1的结构为:输入为48×64×512,输出为48×64×18,通道数channels=18,该层得到的输出为conv2-1(conv1(fconv(x))),再对该输出使用激活函数softmax得到softmax(conv2-1(conv1(fconv(x))));conv2-2的结构为:输入为48×64×512,输出为48×64×36,通道数channels=36;该网络的损失函数有两个:第一个误差函数loss1为对wshad-cls⊙(conv2-1(conv1(fconv(x)))-wcls(x))计算softmax误差,第二个误差函数loss2为对wshad-reg(x)⊙(conv2-1(conv1(fconv(x)))-wreg(x))计算smoothl1误差,区域选择网络的损失函数=loss1/sum(wcls(x))+loss2/sum(wcls(x)),sum(·)表示矩阵所有元素之和,收敛方向为取最小值,wcls(x)和wreg(x)分别为数据库图像x对应的正负样本信息,⊙表示矩阵按照对应位相乘,wshad-cls(x)和wshad-reg(x)为掩码,其作用为选择wshad(x)中权值为1的部分进行训练,从而避免正负样本数量差距过大,每次迭代时重新生成wshad-cls(x)和wshad-reg(x),算法迭代1000次。
所述的构造特征抽取深度网络中所使用的数据库,对于数据库中的每一张图像,第一步:人工标定每个人体图像区域、人脸面部区域、手部区域和产品区域,设其在输入图像的中心坐标为(abas_tr,bbas_tr),中心坐标在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离左右边框的距离为wbas_tr,则其对应于conv1的位置为中心坐标为
所述的随机生成正负样本,其方法为:第一步,构造9个区域框,第二步,对于数据库的每一张图像xtr,设wcls为48×64×18维度,wreg为48×64×36维度,所有初始值均为0,对wcls和wreg进行填充。
所述的构造9个区域框,这9个区域框分别为:ro1(xro,yro)=(xro,yro,64,64),ro2(xro,yro)=(xro,yro,45,90),ro3(xro,yro)=(xro,yro,90,45),ro4(xro,yro)=(xro,yro,128,128),ro5(xro,yro)=(xro,yro,90,180),ro6(xro,yro)=(xro,yro,180,90),ro7(xro,yro)=(xro,yro,256,256),ro8(xro,yro)=(xro,yro,360,180),ro9(xro,yro)=(xro,yro,180,360),对于每一个区域块,roi(xro,yro)表示对于第i个区域框,当前区域框的中心坐标(xro,yro),第三位表示中心点距离上下边框的像素距离,第四位表示中心点距离左右边框的像素距离,i的取值从1到9。
所述的对wcls和wreg进行填充,其方法为:
对于每一个人工标定的人体区间,设其在输入图像的中心坐标为(abas_tr,bbas_tr),中心坐标在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离左右边框的距离为wbas_tr,则其对应于conv1的位置为中心坐标为
对于左上角
对于i取值从1到9:
对于点(xctr,yctr),其在数据库图像的映射区间为左上角点(16(xctr-1)+1,16(yctr-1)+1)右下角点(16xctr,16yctr)所围成的16×16区间,对于该区间的每一个点(xotr,yotr):
计算(xotr,yotr)所对应区域roi(xotr,yotr)与当前人工标定的区间的重合率;
选择当前16×16区间内重合率最高的点(xioumax,yioumax),若重合率>0.7,则wcls(xctr,yctr,2i-1)=1,wcls(xctr,yctr,2i)=0,该样本为正样本,wreg(xctr,yctr,4i-3)=(xotr-16xctr+8)/8,wreg(xctr,yctr,4i-2)=(yotr-16yctr+8)/8,wreg(xctr,yctr,4i-2)=down1(lbas_tr/roi的第三位),wreg(xctr,yctr,4i)=down1(wbas_tr/roi的第四位),down1(·)表示若值大于1则取值为1;若重合率<0.3,则wcls(xctr,yctr,2i-1)=0,wcls(xctr,yctr,2i)=1;否则wcls(xctr,yctr,2i-1)=-1,wcls(xctr,yctr,2i)=-1.
若当前人工标定的人体区域没有重合率>0.6的roi(xotr,yotr),则选择重合率最高的roi(xotr,yotr)对wcls和wreg赋值,赋值方法与重合率>0.7的赋值方法相同。
所述的计算(xotr,yotr)所对应区域roi(xotr,yotr)与当前人工标定的区间的重合率,其方法为:设人工标定的人体区间在输入图像的中心坐标为(abas_tr,bbas_tr),中心坐标在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离左右边框的距离为wbas_tr,设roi(xotr,yotr)的第三位为lotr,第四位为wotr,若满足|xotr-abas_tr|≤lotr+lbas_tr-1并且|yotr-bbas_tr|≤wotr+wbas_tr-1,说明存在重合区域,重合区域=(lotr+lbas_tr-1-|xotr-abas_tr|)×(wotr+wbas_tr-1-|yotr-bbas_tr|),否则重合区域=0;计算全部区域=(2lotr-1)×(2wotr-1)+(2abas_tr-1)×(2wbas_tr-1)-重合区域;从而得到重合率=重合区域/全部区域,|·|表示取绝对值。
所述的wshad-cls(x)和wshad-reg(x),其构造方法为:对于该图像x,其对应的正负样本信息为wcls(x)和wreg(x),第一步,构造wshad-cls(x)与和wshad-reg(x),wshad-cls(x)与wcls(x)维度相同,wshad-reg(x)与wreg(x)维度相同;第二步,记录所有正样本的信息,对于i=1到9,若wcls(x)(a,b,2i-1)=1,则wshad-cls(x)(a,b,2i-1)=1,wshad-cls(x)(a,b,2i)=1,wshad-reg(x)(a,b,4i-3)=1,wshad-reg(x)(a,b,4i-2)=1,wshad-reg(x)(a,b,4i-1)=1,wshad-reg(x)(a,b,4i)=1,正样本一共选择了sum(wshad-cls(x))个,sum(·)表示对矩阵的所有元素求和,若sum(wshad-cls(x))>256,随机保留256个正样本;第三步,随机选择负样本,随机选择(a,b,i),若wcls(x)(a,b,2i-1)=1,则wshad-cls(x)(a,b,2i-1)=1,wshad-cls(x)(a,b,2i)=1,wshad-reg(x)(a,b,4i-3)=1,wshad-reg(x)(a,b,4i-2)=1,wshad-reg(x)(a,b,4i-1)=1,wshad-reg(x)(a,b,4i)=1,若已选中的负样本数量为256-sum(wshad-cls(x))个,或者虽然负样本数量不足256-sum(wshad-cls(x))个但是在20次生成随机数(a,b,i)内都无法得到负样本,则算法结束。
所述的roi层,其输入为图像x和区域
对于iroi=1:到7:
对于jroi=1到7:
构造区间
roii(x)(iroi,jroi)=区间内最大点的值。
当512个48×64矩阵全部处理结束后,将输出拼接得到7×7×512维度的输出
所述的构建坐标精炼网络,其方法为:第一步,扩展数据库:扩展方法为对于数据库中的每一张图像x和对应的人工标定的每个区域
所述的两个全连接层fc2,其结构为:第一层:全连接层,输入向量长度为25088,输出向量长度为4096,激活函数为relu激活函数;第二层:全连接层,输入向量长度为4096,输出向量长度为512,激活函数为relu激活函数。
3.购物动作识别模块,在初始化时,首先使用标准的手部动作图像对静态动作识别分类器进行初始化,从而使静态动作识别分类器能够识别出手的抓握、放下动作;然后使用手部动作视频对动态动作识别分类器进行初始化,从而使动态动作识别分类器能够识别出手的取出物品、放回物品、取出又放回、已取出物品未放回或者是可疑偷窃。
所述的使用标准的手部动作图像对静态动作识别分类器进行初始化,其方法为:第一步,整理视频数据:首先,选取大量的人在超市里购物的视频,这些视频包含取出物品、放回物品、取出又放回、已取出物品未放回和可疑偷窃的动作;人工对每一段视频片段进行截取,以人手碰到商品为起始帧,以人手离开商品为结束帧,然后对于视频的每一帧使用目标检测模块提取其手部区域,然后将手部区域的每一帧图像缩放为256×256的彩色图像,将缩放后视频放入手部动作视频集合,并标记该视频为取出物品、放回物品、取出又放回、已取出物品未放回和可疑偷窃的动作中的一种;对于类别为取出物品、放回物品、取出又放回、已取出物品未放回的每一个视频,将该视频的第一帧放入手部动作图像集合并标记为抓握动作,将该视频的最后一帧放入手部动作图像集合并标记为放下动作,从该视频除第一帧和最后一针外随机取一帧放入手部动作图像集合并标记为其他。从而得到手部动作视频集合和手部动作图像集合;第二步,构造静态动作识别分类器staticn;第三步,对静态动作识别分类器staticn进行初始化,其输入为第一步所构造的手部动作图像集合,设每一次输入的图像为handp,输出为staticn(handp),其类别为yhandp,yhandp的表示方法为:抓握:yhandp=[1,0,0],放下:yhandp=[0,1,0],其他:yhandp=[0,0,1],该网络的评价函数为对(staticn(handp)-yhandp)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次。
所述的构造静态动作识别分类器staticn,其网络结构为:第一层:卷积层,输入为256×256×3,输出为256×256×64,通道数channels=64;第二层:卷积层,输入为256×256×64,输出为256×256×64,通道数channels=64;第三层:池化层,输入第一层输出256×256×64与第三层输出256×256×64在第三个维度上相连接,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;第二十二层:池化层,输入为4×4×128,输出为2×2×128;第二十三层:全连接层,首先将输入的2×2×128维度的数据展开成512维度的向量,然后输入进全连接层,输出向量长度为128,激活函数为relu激活函数;第二十四层:全连接层,输入向量长度为128,输出向量长度为32,激活函数为relu激活函数;第二十五层:全连接层,输入向量长度为32,输出向量长度为3,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。
所述的使用手部动作视频对动态动作识别分类器进行初始化,其方法为:第一步,构造数据集合:将所述的使用标准的手部动作图像对静态动作识别分类器进行初始化时第一步所构造的手部动作视频集合均匀提取10帧图像,作为输入;第二步,构造动态动作识别分类器dynamicn;第三步,对动态动作识别分类器dynamicn进行初始化,其输入为第一步对每一个视频提取的10帧图像所构成的集合,设每一次输入的10帧图像为handv,输出为dynamicn(handv),其类别为yhandv,yhandv的表示方法为:取出物品:yhandv=[1,0,0,0,0]、放回物品:yhandv=[0,1,0,0,0]、取出又放回:yhandv=[0,0,1,0,0]、已取出物品未放回:yhandv=[0,0,0,1,0]和可疑偷窃的动作:yhandv=[0,0,0,0,1],该网络的评价函数为对(dynamicn(handv)-yhandv)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次。
所述的均匀提取10帧图像,其方法为:对于一段视频图像,设其长度为nf帧。首先将视频图像的第1帧图像提取出来作为所提取的集合的第1帧,将视频图像的最后一帧图像提取出来作为所提取的集合的第10帧,所提取的集合的第ickt帧为视频图像的第
所述的构造动态动作识别分类器dynamicn,其网络结构为:
第一层:卷积层,输入为256×256×30,输出为256×256×512,通道数channels=512;第二层:卷积层,输入为256×256×512,输出为256×256×128,通道数channels=128;第三层:池化层,输入为256×256×128,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;第二十二层:池化层,输入为4×4×128,输出为2×2×128;第二十三层:全连接层,首先将输入的2×2×128维度的数据展开成512维度的向量,然后输入进全连接层,输出向量长度为128,激活函数为relu激活函数;第二十四层:全连接层,输入向量长度为128,输出向量长度为32,激活函数为relu激活函数;第二十五层:全连接层,输入向量长度为32,输出向量长度为3,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。
4.产品识别模块,在初始化时,首先使用各个角度的产品图像集合对产品识别分类器进行初始化,并对产品图像生成产品列表。
所述的首先使用各个角度的产品图像集合对产品识别分类器进行初始化,并对产品图像生成产品列表,其方法为:第一步,构造数据集合和产品列表:该数据集合为产品各个角度的图像,产品列表listgoods为一个向量,向量的每一位对应一个产品名字;第二步,构造产品识别分类器goodsn;第三步,对构造产品识别分类器goodsn进行初始化,其输入为各个角度的产品图像集合,设输入图像为goods,输出为goodsn(goods),其类别为ygoods,ygoods为一组向量,长度等于产品列表中产品的个数,ygoods的表示方法为:若图像goods为第igoods位的产品,则ygoods的第igoods位为1,其他位为0.该网络的评价函数为对(goodsn(goods)-ygoods)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次。
所述的构造产品识别分类器goodsn,其网络层结构两组goodsn1和goodsn2,其中goodsn1的网络结构为:第一层:卷积层,输入为256×256×3,输出为256×256×64,通道数channels=64;第二层:卷积层,输入为256×256×64,输出为256×256×128,通道数channels=128;第三层:池化层,输入为256×256×128,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。goodsn2的网络结构为:输入为4×4×128,首先将输入的数据展开成2048维度的向量,然后输入进第一层;第一层:全连接层,输入向量长度为2048,输出向量长度为1024,激活函数为relu激活函数;第二层:全连接层,输入向量长度为1024,输出向量长度为1024,激活函数为relu激活函数;第三层:全连接层,输入向量长度为1024,输出向量长度为len(listgoods),激活函数为soft-max激活函数;len(listgoods)表示产品列表的长度。对于任一输入goods2,goodsn(goods2)=goodsn2(goodsn1(goods2))。
5.个体识别模块,在初始化时,首先使用各个角度的人脸图像集合对人脸特征提取器facen进行初始化并计算μface,然后使用各个角度的人体图像对人体特征提取器bodyn进行初始化并计算μbody。
所述的使用各个角度的人脸图像集合对人脸特征提取器facen进行初始化并计算μface,其方法为:第一步,选取各个角度的人脸图像集合构成人脸数据集;第二步,构造人脸特征提取器facen并使用人脸数据集进行初始化;第三步:
对于人脸数据集中的每一个人ipeop,得到人脸数据集中所有属于ipeop的人脸图像集合faceset(ipeop):
对于faceset(ipeop)中的每一张人脸图像face(jipeop):
计算人脸特征facen(face(jipeop));
统计当前人脸图像集合faceset(ipeop)中所有人脸特征的平均值作为当前人脸图像的中心center(facen(face(jipeop))),计算当前人脸图像集合faceset(ipeop)中所有人脸特征与当前人脸图像的中心center(facen(face(jipeop)))的距离构成ipeop对应的距离集合。
待人脸数据集中的所有人都得到其对应的距离集合,将距离集合从小到大排列后,设距离集合长度为ndiset,
所述的构造人脸特征提取器facen并使用人脸数据集进行初始化,设人脸数据集由nfaceset个人构成,其网络层结构facen25为:第一层:卷积层,输入为256×256×3,输出为256×256×64,通道数channels=64;第二层:卷积层,输入为256×256×64,输出为256×256×64,通道数channels=64;第三层:池化层,输入第一层输出256×256×64与第三层输出256×256×64在第三个维度上相连接,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;第二十二层:池化层,输入为4×4×128,输出为2×2×128;第二十三层:全连接层,首先将输入的2×2×128维度的数据展开成512维度的向量,然后输入进全连接层,输出向量长度为512,激活函数为relu激活函数;第二十四层:全连接层,输入向量长度为512,输出向量长度为512,激活函数为relu激活函数;第二十五层:全连接层,输入向量长度为512,输出向量长度为nfaceset,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。其初始化过程为:设对于每一张人脸face4,输出为facen25(face4),其类别为yface,yface为长度等于nfaceset的向量,yface的表示方法为:若人脸face4属于人脸图像集合中第iface4个人的人脸,则yface的第iface4位为1,其他位为0.该网络的评价函数为对(facen25(face4)-yface)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次;待迭代结束后,人脸特征提取器facen为facen25网络的从第一层到第二十四层。
所述的使用各个角度的人体图像对人体特征提取器bodyn进行初始化并计算μbody,其方法为:第一步,选取各个角度的人体图像集合构成人体数据集;第二步,构造人体特征提取器bodyn并使用人体数据集进行初始化;第三步:
对于人体数据集中的每一个人ipeop1,得到人体数据集中所有属于ipeop1的人体图像集合bodyset(ipeop1):
对于bodyset(ipeop1)中的每一张人体图像body(jipeop1):
计算人体特征bodyn(body(jipeop1));
统计当前人体图像集合bodyset(ipeop1)中所有人体特征的平均值作为当前人体图像的中心center(bodyn(body(jipeop1))),计算当前人体图像集合bodyset(ipeop1)中所有人体特征与当前人体图像的中心center(bodyn(body(jipeop1)))的距离构成ipeop1对应的距离集合。
待人体数据集中的所有人都得到其对应的距离集合,将距离集合从小到大排列后,设距离集合长度为ndiset1,
所述的构造人体特征提取器bodyn并使用人体数据集进行初始化,设人体数据集由nbodyset个人构成,其网络层结构bodyn25为:第一层:卷积层,输入为256×256×3,输出为256×256×64,通道数channels=64;第二层:卷积层,输入为256×256×64,输出为256×256×64,通道数channels=64;第三层:池化层,输入第一层输出256×256×64与第三层输出256×256×64在第三个维度上相连接,输出为128×128×128;第四层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第五层:卷积层,输入为128×128×128,输出为128×128×128,通道数channels=128;第六层:池化层,输入第四层输出128×128×128与第五层128×128×128在第三个维度上相连接,输出为64×64×256;第七层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第八层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第九层:卷积层,输入为64×64×256,输出为64×64×256,通道数channels=256;第十层:池化层,输入为第七层输出64×64×256与第九层64×64×256在第三个维度上相连接,输出为32×32×512;第十一层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十二层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十三层:卷积层,输入为32×32×512,输出为32×32×512,通道数channels=512;第十四层:池化层,输入为第十一层输出32×32×512与第十三层32×32×512在第三个维度上相连接,输出为16×16×1024;第十五层:卷积层,输入为16×16×1024,输出为16×16×512,通道数channels=512;第十六层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十七层:卷积层,输入为16×16×512,输出为16×16×512,通道数channels=512;第十八层:池化层,输入为第十五层输出16×16×512与第十七层16×16×512在第三个维度上相连接,输出为8×8×1024;第十九层:卷积层,输入为8×8×1024,输出为8×8×256,通道数channels=256;第二十层:池化层,输入为8×8×256,输出为4×4×256;第二十一层:卷积层,输入为4×4×256,输出为4×4×128,通道数channels=128;第二十二层:池化层,输入为4×4×128,输出为2×2×128;第二十三层:全连接层,首先将输入的2×2×128维度的数据展开成512维度的向量,然后输入进全连接层,输出向量长度为512,激活函数为relu激活函数;第二十四层:全连接层,输入向量长度为512,输出向量长度为512,激活函数为relu激活函数;第二十五层:全连接层,输入向量长度为512,输出向量长度为nfaceset,激活函数为soft-max激活函数;所有卷积层的参数为卷积核kernel大小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区间大小kernel_size=2,步长stride=(2,2)。其初始化过程为:设对于每一张人体body4,输出为bodyn25(body4),其类别为ybody,ybody为长度等于nbodyset的向量,ybody的表示方法为:若人体body4属于人体图像集合中第ibody4个人的人体,则ybody的第ibody4位为1,其他位为0.该网络的评价函数为对(bodyn25(body4)-ybody)计算其交叉熵损失函数,收敛方向为取最小值,迭代次数为2000次;待迭代结束后,人体特征提取器bodyn为bodyn25网络的从第一层到第二十四层。
6.识别结果处理模块,在初始化时不工作。
实施例2:
本实施例实现了一种超市智能售货系统的检测过程。
1.图像预处理模块,在检测过程中:第一步,对监控摄像头所摄的监控图像进行均值去噪,从而得到去噪后的监控图像;第二步,对去噪后的监控图像进行光照补偿,从而得到光照补偿后的图像;第三步,将光照补偿后的图像进行图像增强,将图像增强后的数据传递给目标检测模块。
所述的监控摄像头所摄的监控图像进行均值去噪,其方法是:设监控摄像头所摄的监控图像为xsrc,因为xsrc为彩色rgb图像,因此存在xsrc-r,xsrc-g,xsrc-b三个分量,对于每一个分量xsrc′,分别进行如下操作:首先设置一个3×3维的窗口,考虑该图像xsrc′的每个像素点xsrc′(i,j),以该点为中心点的3×3维矩阵所对应的像素值分别为[xsrc′(i-1,j-1),xsrc′(i-1,j),xsrc′(i-1,j+1),xsrc′(i,j-1),xsrc′(i,j),xsrc′(i,j+1),xsrc′(i+1,j-1),xsrc′(i+1,j),xsrc′(j+1,j+1)]进行从大到小排列,取其排在中间的值为去噪后图像xsrc″在像素(i,j)所对应滤波后值赋值给xsrc″(i,j);对于xsrc′的边界点,会出现其3×3维的窗口所对应的某些像素点不存在的情况,那么只需计算落在窗口内存在的像素点的中间值即可,若窗口内为偶数个点,将排在中间两个像素值的平均值作为该像素点去噪后的像素值赋值给xsrc″(i,j),从而,新的图像矩阵xsrc″即为xsrc在当前rgb分量的去噪后的图像矩阵,对于xsrc-r,xsrc-g,xsrc-b在三个分量分别进行去噪操作后,将得到的xsrc-r″,xsrc-c″,xsrc-b″分量,将这三个新的分量整合成一张新的彩色图像xden即为去噪后所得的图像。
所述的对去噪后的监控图像进行光照补偿,设去噪后的监控图像xden,因为xden为彩色rgb图像,因此xden存在rgb三个分量,对于每一个分量xden′,分别进行光照补偿,然后将得到的xcpst′整合得到彩色rbg图像xcpst,xcpst即为xden光照补偿后的图像,对每一个分量xden′分别进行光照补偿的步骤为:第一步,设xden′为m行n列,构造xden′sum和numden为同样m行n列的矩阵,初始值均为0,
所述的根据窗口大小为l和步长s确定每一个候选框,其步骤为:
设监控图像为m行n列,(a,b)为选定的区域的左上角坐标,(a+l,b+l)为选定区域的右下角坐标,该区域由[(a,b),(a+l,b+l)]表示,(a,b)的初始值为(1,1);
当a+l≤m时:
b=1;
当b+l≤n时:
选定的区域为[(a,b),(a+l,b+l)];
b=b+s;
内层循环结束;
a=a+s;
外层循环结束;
上述过程中,每次选定的区域[(a,b),(a+l,b+l)]均为候选框。
所述的对于xden′在候选框区域内所对应的图像矩阵进行直方图均衡化,设候选框区域为[(a,b),(a+l,b+l)]所围成的区域,xden″即为xden′在[(a,b),(a+l,b+l)]区域内的图像信息,其步骤为:第一步,构造向量i,i(ii)为xden″中像素值等于ii的个数,0≤ii≤255;第二步,计算向量
所述的将光照补偿后的图像进行图像增强,设光照补偿后的图像为xcpst,其对应的rgb通道分别为xcpstr,xcpstg,xcpstb,对xcpst图像增强后得到的图像为xenh。对其进行图像增强的步骤为:第一步,对于xcpst的所有分量xcpstr,xcpstg,xcpstb计算其按指定尺度进行模糊后的图像;第二步,构造矩阵lxenhr,lxenhg,lxenhb为与xcpstr相同维度的矩阵,对于图像xcpst的rgb通道中的r通道,计算lxenhr(i,j)=log(xcpstr(i,j))-lxcpstr(i,j),(i,j)的取值范围为图像矩阵中所有的点,对于图像xcpst的rgb通道中的g通道和b通道采用与r通道同样的算法得到lxenhg和lxenhb;第三步,对于图像xcpst的rgb通道中的r通道,计算lxenhr中所有点取值的均值meanr和均方差varr(注意是均方差),计算minr=meanr-2×varr和maxr=meanr+2×varr,然后计算xenhr(i,j)=fix((lxcpstr(i,j)-minr)/(maxr-minr)×255),其中fix表示取整数部分,若取值<0则赋值为0,取值>255则赋值为255;对于rgb通道中的g通道和b通道采用与r通道同样的算法得到xenhg和xenhb,将分别属于rgb通道的xenhr、xenhg、xenhb整合成一张彩色图像xenh。
所述的对于xcpst的所有分量xcpstr,xcpstg,xcpstb计算其按指定尺度进行模糊后的图像,对于rgb通道中的r通道xcpstr,其步骤为:第一步,定义高斯函数g(x,y,σ)=k×exp(-(x2+y2)/σ2),σ为尺度参数,k=1/∫∫g(x,y)dxdy,则对于xcpstr的每一个点xcpstr(i,j)计算,
2.目标检测模块,在检测过程中,接收图像预处理模块所传递来的图像,然后对其进行处理,对每一帧图像使用目标检测算法进行目标检测,得到当前图像的人体图像区域、人脸面部区域、手部区域和产品区域,然后将手部区域和产品区域发送给购物动作识别模块,把人体图像区域和人脸面部区域发送给个体识别模块,把产品区域传递给产品识别模块;
所述的对每一帧图像使用目标检测算法进行目标检测,得到当前图像的人体图像区域、人脸面部区域、手部区域和产品区域,其步骤为:
第一步,将输入图像xcpst分割成768×1024维度的子图;
第二步,对于每一个子图xs:
第2.1步,使用在初始化时构造的特征抽取深度网络fconv进行变换,得到512个特征子图集合fconv(xs);
第2.2步,对fconv(xs)使用区域选择网络中第一层conv1、第二层conv2-1+softmax激活函数和conv2-2进变换,分别得到输出softmax(conv2-1(conv1(fconv(xs))))和conv2-2(conv1(fconv(xs))),然后根据输出值得到该区间内的所有的初步候选区间;
第2.3步,对于当前帧图像的所有子图的所有的初步候选区间:
第2.3.1步,根据其当前候选区域的得分大小进行选取,选取最大的50个初步候选区间作为候选区域;
第2.3.2步,调整候选区间集合中所有的越界候选区间,然后剔除掉候选区间中重叠的框,从而得到最终候选区间;
第2.3.3步,将子图xs和每一个最终候选区间输入到roi层,得到对应的roi输出,设当前的最终候选区间为(abb(1),bbb(2),lbb(3),wbb(4)),然后计算fbbox(fc2(roi))得到四位输出(outbb(1),outbb(2),outbb(3),outbb(4))从而得到更新后的坐标(abb(1)+8×outbb(1),bbb(2)+8×outbb(2),lbb(3)+8×outbb(3),wbb(4)+8×outbb(4));然后计算fclass(fc2(roi))得到输出,若输出第一位最大则当前区间为人体图像区域,若输出第二位最大则当前区间为人脸面部区域,若输出第三位最大则当前区间为手部区域,若输出第四位最大则当前区间为产品区域,若输出第五位最大则当前区间为负样本区域并删除该最终候选区间。第三步,更新所有子图的精炼后的最终候选区间的坐标,更新的方法为设当前候选区域的坐标为(tlx,tly,rbx,rby),其对应的子图的左上角坐标为(seasub,sebsub),更新后的坐标为(tlx+seasub-1,tly+sebsub-1,rbx,rby)。
所述的将输入图像xcpst分割成768×1024维度的子图,其步骤为:设分割的步长为384和512,设窗口大小为m行n列,(asub,bsub)为选定的区域的左上角坐标,(a,b)的初始值为(1,1);
当asub<m时:
bsub=1;
当bsub<n时:
选定的区域为[(asub,bsub),(asub+384,bsub+512)],将输入图像xcpst上该区间所对应的图像区域的信息复制到新的子图中,并附带左上角坐标(asub,bsub)作为位置信息;若选定区域超出输入图像xcpst区间,则将超出范围内的像素点对应的rgb像素值均赋值为0;
bsub=bsub+512;
内层循环结束;
asub=asub+384;
外层循环结束;
所述的根据输出值得到该区间内的所有的初步候选区间,其方法为:第一步:对于softmax(conv2-1(conv1(fconv(xs))))其输出为48×64×18,对于conv2-2(conv1(fconv(xs))),其输出为48×64×36,对于48×64维空间上的任何一点(x,y),softmax(conv2-1(conv1(fconv(xs))))(x,y)为18维向量ii,conv2-2(conv1(fconv(xs)))(x,y)为36维向量iiii,若ii(2i-1)>ii(2i),对于i取值从1到9,lotr为roi(xotr,yotr)的第三位,wotr为roi(xotr,yotr)的第四位,则初步候选区间为[ii(2i-1),(8×iiii(4i-3)+x,8×iiii(4i-2)+y,lotr×iiii(4i-1),wotr×iiii(4i))],其中第一位ii(2i-1)表示当前候选区域的得分,第二位(8×iiii(4i-3)+x,8×iiii(4i-2)+y,iiii(4i-1),iiii(4i))表示当前候选区间的中心点为(8×iiii(4i-3)+x,8×iiii(4i-2)+y),候选框的半长半宽分别为lotr×iiii(4i-1)和wotr×iiii(4i))。
所述的调整候选区间集合中所有的越界候选区间,其方法为:设监控图像为m行n列,对于每一个候选区间,设其[(ach,bch)],候选框的半长半宽分别为lch和wch,若ach+lch>m,则
所述的剔除掉候选区间中重叠的框,其步骤为:
若候选区间集合不为空:
从候选区间集合中取出得分最大的候选区间iout:
计算候选区间iout与候选区间集合中的每一个候选区间ic的重合率,若重合率>0.7,则从候选区间集合删除候选区间ic;
将候选区间iout放入输出候选区间集合;
当候选区间集合为空时,输出候选区间集合内所含的候选区间即为剔除掉候选区间中重叠的框后所得到的候选区间集合。
所述的计算候选区间iout与候选区间集合中的每一个候选区间ic的重合率,其方法为:设候选区间ic的坐标区间为中心点[(aic,bic)],候选框的半长半宽分别为lic和wic,候选区间ic的坐标区间为中心点[(aiout,bicout)],候选框的半长半宽分别为liout和wiout;计算xa=max(aic,aiout);ya=max(bic,biout);xb=min(lic,liout),yb=min(wic,wiout);若满足|aic-aiout|≤lic+liout-1并且|bic-biout|≤wic+wiout-1,说明存在重合区域,重合区域=(lic+liout-1-|aic-aiout|)×(wic+wiout-1-|bic-biout|),否则重合区域=0;计算全部区域=(2lic-1)×(2wic-1)+(2liout-1)×(2wiout-1)-重合区域;从而得到重合率=重合区域/全部区域。
3.购物动作识别模块,在检测过程中:第一步,对接收到的每一个手部区域信息使用静态动作识别分类器进行识别,识别方法为:设每一次输入的图像为handp1,输出为staticn(handp1)为3位向量,若第一位最大则识别为抓握,若第二位最大则识别为放下,若第三位最大则识别为其他;第二步,当识别到抓握动作后,对当前抓握动作对应区域进行目标跟踪,若当前手部区域的下一帧跟踪框所对应的使用静态动作识别分类器的识别结果为放下动作时,目标跟踪结束,将当前得到的从识别到抓握动作为视频开始、识别到放下动作为视频结束,从而得到手部动作的连续视频,将该视频标记为完整视频。若跟踪过程中跟踪丢失,则将当前得到的从识别到抓握动作为视频开始、从跟踪丢失前的图像作为视频结束,从而得到只有抓握动作的视频,则将该视频标记为只有抓握动作的视频;当识别到放下动作,并且该动作不在目标跟踪所得到的图像中,说明该动作的抓握动作丢失,则以当前图像对应的手部区域为视频结束,使用目标跟踪方法从当前帧开始向前进行跟踪,直到跟踪丢失,则丢失帧的下一帧作为视频的起始帧,将该视频标记为只有放下动作的视频。第三步,将第二步所得到的完整视频使用动态动作识别分类器进行识别,识别方法为:设每一次输入的图像为handv1,输出为dynamicn(handv1)为5位向量,若第一位最大则识别为取出物品,若第二位最大则识别为放回物品,若第三位最大则识别为取出又放回,若第四位最大则识别为已取出物品未放回,若第五位最大则识别为可疑偷窃的动作,然后将该识别结果发送给识别结果处理模块,将只有抓握动作的视频和只有放下动作的视频发送给识别结果处理模块,将完整视频和只有抓握动作的视频发送给产品识别模块和个体识别模块。
所述的当识别到抓握动作后,对当前抓握动作对应区域进行目标跟踪,其方法为:设当前识别到的抓握动作的图像为hgrab,当前跟踪区域为图像hgrab所对应的区域。第一步,提取图像hgrab的orb特征orbhgrab;第二步,对于hgrab的下一帧内的所有手部区域对应的图像计算其orb特征从而得到orb特征集合,并删掉被其他跟踪框选中的orb特征;第三步,将orbhgrab与orb特征集合的每一个值比较其汉明距离,选取与orbhgrab特征的汉明距离最小的orb特征为选中的orb特征,若选中的orb特征与orbhgrab特征的相似度>0.85,相似度=(1-两个orb特征的汉明距离/0rb特征长度),则选中的orb特征对应的手部区域即为图像hgrab在下一帧的跟踪框,否则若相似度<0.85表明跟踪丢失。
所述的orb特征,从一个图像中提取orb特征的方法已经较为成熟,在opencv计算机视觉库里边已有实现;对一个图片提取其orb特征,输入值为当前图片,输出为若干组长度相同的字符串,每一组代表一个orb特征。
所述的以当前图像对应的手部区域为视频结束,使用目标跟踪方法从当前帧开始向前进行跟踪,直到跟踪丢失,其方法为:设当前识别到的放下动作的图像为hdown,当前跟踪区域为图像hdown所对应的区域。
若未跟踪丢失:
第一步,提取图像hdown的orb特征orbhdown,由于该过程在所述的当识别到抓握动作后,对当前抓握动作对应区域进行目标跟踪的过程中已经计算得到,所以此处不需要再次计算;
第二步,对于图像hdown的前一帧内的所有手部区域对应的图像计算其orb特征从而得到orb特征集合,并删掉被其他跟踪框选中的orb特征;
第三步,将orbhaown与orb特征集合的每一个值比较其汉明距离,选取与orbhdown特征的汉明距离最小的orb特征为选中的orb特征,若选中的orb特征与orbhdown特征的相似度>0.85,相似度=(1-两个orb特征的汉明距离/0rb特征长度),则选中的orb特征对应的手部区域即为图像hdown在下一帧的跟踪框,否则若相似度<0.85表明跟踪丢失,算法结束。
4.产品识别模块,在检测过程中,第一步,根据购物动作识别模块传递来的完整视频和只有抓握动作的视频,首先根据当前视频第一帧所对应的在目标检测模块所得到的位置,对该位置的输入视频图像从当前视频第一帧向前检测,检测到该区域没有被遮挡的帧,最后将帧所对应的区域的图像作为产品识别分类器的输入进行识别,从而得到当前产品的识别结果,识别方法为:设每一次输入的图像为goods1,输出为goodsn(goods1)为一个向量,设该向量的第igoods位最大,则表明当前识别结果为产品列表中的第igoods位的产品,将识别结果发送给识别结果处理模块;
所述的根据当前视频第一帧所对应的在目标检测模块所得到的位置,对该位置的输入视频图像从当前视频第一帧向前检测,检测到该区域没有被遮挡的帧,其方法为:设当前视频第一帧所对应的在目标检测模块所得到的位置为(agoods,bgoods,lgoods,wgoods),设当前当前视频第一帧为第icrgs帧,当前处理帧icr=icrgs:第一步,第icr帧在目标检测模块所得到的所有检测区域为taskicr;第二步,对于taskicr中的每一个区域框(atask,btask,ltask,wtask),计算其距离dgt=(atask-agoods)2+(btask-bgoods)2-(ltask+lgoods)2-(wtask+wgoods)2。若不存在距离<0,则第icr帧对应的(agoods,bgoods,lgoods,wgoods)区域即为检测到的检测到的该区域没有被遮挡的帧,算法结束;否则,若存在距离<0,则记录距离列表d中的d(icr)=最小距离,并icr=icr-1,若icr>0,则算法跳转至第一步,若icr≤0,则选择距离列表d中值最大的记录,取该记录对应帧对应的(agoods,bgoods,lgoods,wgoods)即为检测到的检测到的该区域没有被遮挡的帧,算法结束。
5.个体识别模块,在检测过程中,当用户进入超市时,通过目标检测模块得到当前人体区域body1和人体区域内的人脸的图像face1,然后分别使用人体特征提取器bodyn和人脸特征提取器facen提取人体特征bodyn(body1)和人脸特征facen(face1),保存bodyn(body1)在bodyftu集合中,保存facen(face1)在faceftu集合中,并保存当前客户的id信息,id信息可以是用户在超市的账户或者是用户进入超市时随机分配的不重复的数字,id信息用来区分不同顾客,每当有顾客进入超市,则提取其人体特征和人脸特征;当超市内用户移动产品时,根据购物动作识别模块传递来的完整视频和只有抓握动作的视频,寻找到其对应的人体区域和人脸区域,使用人脸特征提取器facen和人体特征提取器bodyn进行人脸识别或人体识别方式,得到当前购物动作识别模块传递来的视频所对应的顾客的id。
所述的根据购物动作识别模块传递来的完整视频和只有抓握动作的视频,寻找到其对应的人体区域和人脸区域,使用人脸特征提取器facen和人体特征提取器bodyn进行人脸识别或人体识别方式,得到当前购物动作识别模块传递来的视频所对应的顾客的id。其过程为:根据购物动作识别模块传递来的视频,从视频的第一帧开始寻找到对应的人体区域和人脸区域,直到算法终止或者已经处理完视频的最后一帧:
将对应的人体区域图像body2和人脸区域图像face2分别使用人体特征提取器bodyn和人脸特征提取器facen提取人体特征bodyn(body2)和人脸特征facen(face2);
然后首先使用人脸识别信息:比较facen(face2)与faceftu集合中所有人脸特征的欧氏距离dface,选择欧氏距离最小时所对应的faceftu集合中的特征,设该特征为facen(face3),若dface<μface,则识别出当前人脸图像属于facen(face3)所对应人脸图像的客户id即为购物动作识别模块传递来的视频动作所对应的id,当前识别过程结束;
若dface≥μface,表明无法仅用人脸识别方式对当前个体进行识别,则比较bodyn(body2)与bodyftu集合中所有人体特征的欧氏距离dbody,选择欧氏距离最小时所对应的bodyftu集合中的特征,设该特征为bodyn(face3),若dbody+dface<μface+μbody,则识别出当前人体图像属于bodyn(face3)所对应人体图像的客户id即为购物动作识别模块传递来的视频动作所对应的id。
若在处理完视频的所有帧后仍然没有找到视频动作所对应的id,为了避免错误识别购物主体造成错误的记账,因此对当前购物动作识别模块传递来的视频不再进行处理。
所述的根据购物动作识别模块传递来的视频,从视频的第一帧开始寻找到对应的人体区域和人脸区域,其方法为:根据购物动作识别模块传递来的视频,从视频的第一帧进行处理。设当前处理到第ifrg帧,设该帧对应视频在目标检测模块所得到的位置为(aifrg,bifrg,lifrg,wifrg),该帧对应的在目标检测模块所得到的人体区域集合为bodyframesetifrg人体区域集合为faceframesetifrg,对于bodyframesetifrg中的每一个人体区域(abfsifrg,bbfsifrg,lbfsifrg,wbfsifrg),计算其距离dgbt=(abfsifrg-aifrg)2+(bbfsifrg-bifrg)2-(lbfsifrg-lifrg)2-(wbfsifrg-wifrg)2,选择所有人体区域集合中距离最小的人体区域为当前视频对应的人体区域,设选中的人体区域为位置为(abfs1,bbfs1,lbfs1,wbfs1),对于人脸区域集合为faceframesetifrg中的每一个人脸区域(affsifrg,bffsifrg,lffsifrg,wffsifrg),计算其距离dgft=(abfs1-affsifrg)2+(bbfs1-bffsifrg)2-(lbfs1-lffsifrg)2-(wbfs1-wffsifrg)2,选择所有人脸区域集合中距离最小的人脸区域为当前视频对应的人脸区域。
6.识别结果处理模块,在识别过程中,对接收到的识别结果进行整合从而生成每一位顾客对应的购物清单:首先根据个体识别模块传递来的顾客的id确定当前购物信息对应的顾客,从而选中被修改的购物清单号为id,然后根据产品识别模块传递来的识别结果来确定当前顾客的购物动作对应的产品设产品为gooda,然后根据购物动作识别模块传递来的识别结果来确定当前购物动作是否对购物车进行修改,若识别为取出物品则在购物清单id上增加产品gooda,增加数量为1个,若识别为放回物品则在购物清单id上减少产品gooda,减少数量为1个,若识别为“取出又放回”或者“已取出物品未放回”则购物清单不改变,若识别结果为“可疑偷窃”则向超市监控发送报警信号和当前视频对应的位置信息。
实施例3:
本实施例实现了一种超市智能售货系统的更新产品列表的过程。
1.本过程只使用了产品识别模块。在变更产品列表时:若删除某产品,则从各个角度的产品图像集合中删除该产品的图像,并将产品列表中对应位置删除,若增加某产品,则将当前产品的各个角度的产品图像放入各个角度的产品图像集合,将产品列表最后一位的后边添加当前增加产品的名称,然后用新的各个角度的产品图像集合和新的产品列表更新产品识别分类器。
所述的用新的各个角度的产品图像集合和新的产品列表更新产品识别分类器,其方法为:第一步,修改网络结构:对于新构造的产品识别分类器goodsn′,其goodsn1′的网络结构不变,与初始化时的goodsn1网络结构相同,其goodsn2′网络结构的第一层和第二层结构保持不变,第三层的输出向量长度变为更新后的产品列表的长度;第二步,对于新构造的产品识别分类器goodsn′进行初始化:其输入为新的各个角度的产品图像集合,设输入图像为goods3,输出为goodsn′(goods3)=goodsn2′(goodsn1(goods3)),其类别为ycoods3,ygoods为一组向量,长度等于更新后的产品列表的个数,ygoods的表示方法为:若图像goods为第igoods位的产品,则ygoods的第igoods位为1,其他位为0.该网络的评价函数为对(goodsn(goods)-ygoods)计算其交叉熵损失函数,收敛方向为取最小值,在初始化过程中goodsn1中的参数值保持不变,迭代次数为500次。
- 还没有人留言评论。精彩留言会获得点赞!