一种视频显著性检测方法与流程
本发明涉及图像处理、计算机视觉领域,尤其涉及一种视频显著性检测方法。
背景技术:
人类的视觉系统可在大范围、复杂的场景中快速定位出最吸引注意的内容。受此机制的启发,研究人员也希望计算机可以模拟人类的视觉注意机制,具备自动定位场景中显著性内容的能力,进而为后续处理提供有效的辅助信息,这样“视觉显著性检测”任务应运而生。作为一个跨计算机科学、神经学、生物学、心理学的交叉学科方向,视觉显著性检测已经被广泛应用于诸多研究领域,如:检测、分割、裁剪、检索、压缩编码、质量评价、以及推荐系统等,具有十分广阔的市场发展和应用前景。
大数据时代的来临,使得数据形式发生了翻天覆地的变化,传统的图像数据已不足以满足人们日益增长的感官需求,视频数据量增长迅速,如何准确、一致地提取视频数据中的显著性目标成为亟待解决的新课题。视频显著性检测旨在通过联合空间和时间信息实现视频序列中与运动相关的显著性目标的连续提取,已被广泛应用于视频目标检测、视频摘要、基于内容的视频检索等领域。不同于图像显著性检测,视频显著性检测需要同时结合时间信息和空间信息,连续地定位视频序列中与运动相关的显著性目标。与协同显著性检测相比,视频显著性检测还需考虑运动信息和时序特性,而且具有“相邻视频帧之间相关性较大”的先验。由于视频数据量大、场景变化明显、目标大小不一致等问题,使得视频显著性检测研究难度较大,算法性能整体较低。
wang等人提出了一种基于局部梯度流估计和全局修正的视频显著性检测算法。xi等人将图像显著性检测中的背景先验扩展至视频领域,提出了一种基于空时背景先验的视频显著性目标检测算法。chen等人提出了一种基于空时融合和低秩一致性扩散的视频显著性检测方法。liu等人提出了一种基于超像素和空时传播的视频显著性检测方法。
发明人在实现本发明的过程中,发现现有技术中至少存在以下缺点和不足:
现有视频检测技术对于噪声等干扰都较为敏感,导致检测精度不高,鲁棒性较差;视频中目标的运动特性在显著性检测任务中具有十分重要的作用,但现有算法并未充分挖掘运动信息;现有算法在对帧间一致性进行优化时并未考虑全局信息约束,导致结果的整体一致性有待改善。
技术实现要素:
本发明提供了一种视频显著性检测方法,本发明通过深入挖掘视频序列中目标的运动信息和帧间约束关系,设计一种有效的视频显著性检测模型,连续提取视频序列中的显著性目标,详见下文描述:
一种视频显著性检测方法,所述方法包括以下步骤:
考虑背景线索、颜色紧致性和颜色独特性确定背景候选区域,构成静态重建字典对每个视频帧中的超像素进行重建,获取静态显著性图;
考虑运动紧致性和运动独特性确定背景种子点集合,构成运动重建字典对每个视频帧中的超像素进行重建,获取运动显著性图;
将静态显著性图和运动显著性图融合,获取单帧显著性结果;
利用双向稀疏传播获取帧间显著性图;
构建由一元数据项、空时平滑项、空间互斥项、以及全局项组成的能量函数,通过能量函数对单帧、及帧间显著性结果进行优化。
其中,所述考虑运动紧致性和运动独特性确定背景种子点集合具体为:
选择若干个具有较大光流域空间变化参量的超像素作为基于运动紧致性先验的背景候选种子点集合;
选择若干个具有较小运动独特性值的超像素作为基于运动独特性先验的背景候选种子点集合;
将通过运动紧致性和运动独特性确定的背景候选种子点集合合并,得到最终的运动空间背景种子点集合。
进一步地,所述运动重建字典对每个视频帧中的超像素进行重建,获取运动显著性图具体为:所有背景种子点集合中的超像素的特征向量组合得到运动重建字典,该重建字典对视频帧进行稀疏重建,以重建误差度量超像素区域的运动显著性,得到运动显著性图。
进一步地,所述利用双向稀疏传播获取帧间显著性图具体为:
在前向传播中,利用前一视频帧构建前景字典,对当前视频帧进行稀疏重建,获得前向帧间显著性结果,从第一帧开始,连续处理至最后一帧;
后向传播过程以视频序列的后一帧构建前景字典,对当前帧进行稀疏重建,从最后一帧处理至第一帧。
进一步地,
所述一元数据项用于约束优化后的显著性结果不与初始显著性结果相差太大;
所述空时平滑项用于约束具有像素特性的相邻超像素的显著性值保持一致;
所述空间互斥项用于约束当前超像素近似的邻域超像素与当前超像素具有一致的显著性值;
所述全局项用于约束前景超像素与整个视频的前景模型具有相似的显著性值。
所述能量函数的表达式及矩阵形式如下:
其中,
本发明提供的技术方案的有益效果是:
1、本发明设计了一种基于稀疏重建与传播的视频显著性检测模型,可以准确提取视频序列中的显著性目标,背景抑制能力强,显著性目标轮廓清晰;
2、本发明设计的模型具有较好的鲁棒性,能够处理许多挑战性场景,如遮挡、小目标等,同时算法运算速度较快,时效性较好;
3、本发明采用双向传播重建机制,通过两次帧间传播,进一步挖掘更加全面的视频帧间对应关系,获取更加准确的帧间显著性结果。
附图说明
图1为一种视频显著性检测方法的流程图;
图2为本发明提出的检测结果的示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
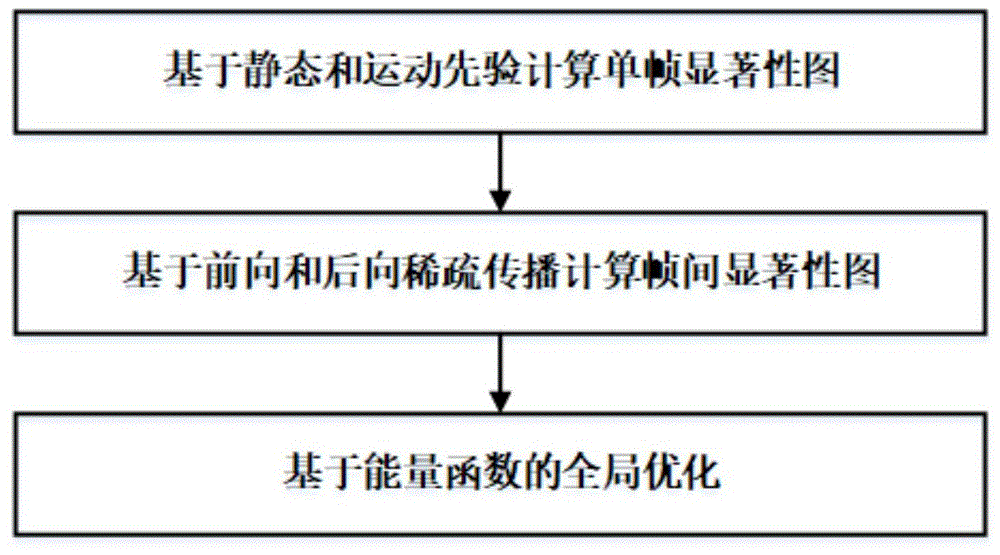
本发明实施例提出了一种视频显著性检测方法,参见图1,该方法包括以下步骤:
101:在静态线索和运动先验的基础上,通过稀疏重建模型来计算视频序列中每个帧的空间显著性;
102:通过渐进的稀疏传播模型,捕获时间域的时序对应关系,生成帧间显著性图;
103:将两个显著性结果融合到一个全局优化模型中,以改善整个视频中显著性对象的时空平滑性和全局一致性。
综上所述,本发明实施例通过深入挖掘视频序列中目标的运动信息和帧间约束关系,设计一种有效的视频显著性检测模型,连续提取视频序列中的显著性目标。
实施例2
下面结合具体的实例、图1对实施例1中的方案进行进一步地介绍,详见下文描述:
201:单帧显著性重建;
其中,对于视频显著性检测任务,检测到的目标应该在每个视频帧中且相对于背景区域是显著的、运动的。为此,基于静止和运动先验,构建了两个稀疏重建模型来检测每一个视频帧中的显著性目标。第一个是静态显著性先验,它利用三种颜色显著性线索来构建基于颜色的重建字典(dc),第二个是运动显著性先验,它集成了运动独特性线索和运动紧致性线索,构建了基于运动的字典(dm)。
设一个视频序列
202:静态显著性先验:
具体实现时,考虑背景线索、颜色紧致性和颜色独特性确定背景候选区域,构成静态重建字典,并利用该字典对每个视频帧中的超像素进行重建,得到静态显著性图。
边界先验用来描述背景区域的空间位置特性,选择位于图像边界的超像素区域作为边界先验背景候选种子点集合
颜色紧致性先验用来描述背景区域的空间分布特性。在颜色空间,背景区域颜色分布较为分散,紧致性较小。因此,选择颜色紧致性较小的超像素区域作为紧致性先验候选种子点集合
其中,
颜色独特性先验用来描述背景区域的全局外貌特性。图像中的显著性目标往往具有独特的外貌等特性,而背景区域独特性程度较低,可以以此选择背景候选种子点。首先,利用k均值聚类算法将单个视频帧中的超像素区域聚类成20类,然后计算显著性约束的两两类中心之间的距离,并确定出类中心距离最大的两类,最后考虑超像素的背景概率和空间变动参量确定出基于颜色紧致性的背景候选种子点集合,记为
将三种颜色先验信息得到的背景候选种子点集合合并,得到最终的颜色空间背景种子点集合
考虑颜色分量、空间位置和纹理分布将每个超像素区域(含确定的背景种子点)表示为一个26维的特征向量,记为
所有背景种子点集合中的超像素的特征向量组合得到静态背景重建字典,记为
203:运动显著性先验;
考虑运动紧致性和运动独特性确定背景种子点,构成运动重建字典,并利用该字典对每个视频帧中的超像素进行重建,得到运动显著性图。
观察光流数据可以看出,运动目标的光流分布较为集中,而静止区域的光分布较为分散,称之为“运动紧致性”。因此,运动紧致性来描述光流数据的分布特性。同样地,本发明实施例定义了超像素
其中,
光流幅度描述了光流信息的幅度特性,光流幅度图类似于深度图,即运动目标的光流幅度特性明显区别于背景区域。因此,可以通过计算光流幅度的全局对比特性描述光流幅度的独特性。那么,运动独特性定义为:
其中,
将通过运动紧致性和运动独特性确定的背景候选种子点集合合并,得到最终的运动空间背景种子点集合
考虑颜色分量和运动特征将每个超像素区域(含确定的背景种子点)表示为一个12维的特征向量,记为
最后,将静态显著性和运动显著性融合,得到单帧显著性结果,公式如下:
其中,
204:帧间显著性传播;
帧间关系的获取在视频显著性检测中具有十分重要的作用。在整个视频序列中,视频显著性目标是一致的,并且重复出现在多数视频帧中的。因此,本发明实施例利用前一帧的视频数据构建前景字典对后一帧视频数据进行前向重建,并利用后一帧的视频数据构建前景字典对前一帧视频数据进行后向重建,进而建立起不同视频帧的显著性目标之间的对应关系,有效抑制背景,获得帧间显著性结果。
值得一提的是,为了更加充分的挖掘视频帧间关系,本发明实施例采用了双向传播重建机制(即包括后续步骤2041中的前向传播、以及步骤2042中的后向传播),通过两次帧间传播,进一步挖掘更加全面的视频帧间对应关系。
2041:前向传播;
在前向传播中,利用前一视频帧构建前景字典,对当前视频帧进行稀疏重建,获得前向帧间显著性结果,该过程从第一帧开始,连续处理至最后一帧。设当前视频帧为第t帧,即需要处理的是视频帧ft。
首先,根据上一步求得的单帧显著性结果,在第t-1帧中选择前50个具有较大显著性值的超像素作为前向传播过程的前景种子点。然后,考虑颜色分量、空间位置、纹理分布、运动特征和单帧显著性结果,将对应视频帧中的每个超像素区域表示为一个30维的特征向量,记为
其中,
2042:后向传播;
后向传播过程与正向传播过程正好相反,即以视频序列的后一帧构建前景字典,对当前帧进行稀疏重建,该过程从最后一帧处理至第一帧。首先,分别根据单帧显著性结果和前向显著性结果在第t+1帧中选择前25个具有较大显著性值的超像素作为前向传播过程的候选前景种子点,然后取两个集合的并集得到最终的后向传播前种子点。然后,考虑颜色分量、空间位置、纹理分布、运动特征、单帧显著性结果和前向显著性结果,将对应视频帧中的每个超像素区域表示为一个31维的特征向量,记为
式中,
205:全局优化;
为了获得更加一致的视频显著性结果,本发明实施例采用能量函数优化的方法对显著性结果优化,考虑了四部分内容组成能量函数:一元数据项用于约束优化模型的更新程度,即要求优化后的显著性结果不能与初始显著性结果相差太大;空时平滑项用于保持视频帧的空间平滑性,即约束具有像素特性的相邻超像素(空时相邻)的显著性值应尽量保持一致;空间互斥项用于约束显著性区域和背景区域应该具有各自的主导区域,即与当前超像素近似的邻域超像素应该与当前超像素具有较为一致的显著性值;全局项用于保证整个视频序列的全局一致性,即约束前景超像素应该与整个视频的前景模型具有相似的显著性值。能量函数的表达式及矩阵形式如下:
其中,
对能量函数进行求导后置0即可求解该能量方程,其显示解如下:
其中,i表示na×na大小的单位矩阵。
综上所述,本发明实施例通过上述步骤可以准确提取视频序列中的显著性目标,背景抑制能力强,显著性目标轮廓清晰,算法鲁棒性和时效性都较好。
实施例3
下面结合具体的实例对实施例1和2中的方案进行可行性验证,详见下文描述:
图2给出了一个视频序列的显著性检测结果,其中视频中的女性是显著性目标。第一行为不同视频帧的rgb图像,第二行为视频显著性检测的真值图,第三行为本方法得到的结果。从结果可以看出,本方法可以准确提取视频序列中的显著性目标,对背景区域和非运动的显著性区域(如长椅)抑制效果好,轮廓清晰。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!