POI别名的确定方法、装置、计算机设备和存储介质与流程
本发明实施例涉及数据处理技术,尤其涉及一种poi别名的确定方法、装置、计算机设备和存储介质。
背景技术:
随着科技的发展和互联网技术的不断进步,移动终端提供的服务不断升级。目前基于位置的服务(locationbasedservices,lbs)是当前移动终端服务中的热点。
在lbs中,兴趣点(pointofinterest,poi)已成为衡量lbs价值的标准。其中,poi是一个区域活力的重要组成部分,具体可以包括零售商铺、餐饮门店、娱乐场所或大学等。实际上不同的poi具备不同的名称,名称用于标识poi。同样的,类似于人有姓名同时也有小名,poi也具有标准名称和别名。,越是熟悉的人喜欢称呼我们的小名,同样的越是对poi熟悉的人,越喜欢通过别名来称呼poi,通过对poi别名的研究能对poi进行更好的刻画,并适用于服务与地图检索、出行打车等相关场景。
目前对poi别名的获取方式,主要包括以下三种方式:用户上传用户生成内容(usergeneratedcontent,ugc)、上传专业生产内容(professionally-generatedcontent,pgc)和网络爬虫方式。其中,ugc方式的缺陷在于:首先需要通过运营活动调取用户上传的积极性,其次由于用户层次的随机性,数据质量不可控,很大概率数据质量较差,需要耗费较高的人力进行审核;pgc方式的缺陷在于:首先成本较高,需要付出较高的人工成本和设备成本、交通成本。同时采集的覆盖率较低,同样的由于代价较高,时效也往往较低;网络爬虫方式的缺陷在于:由于poi和别名一般比较少存在与网络上,导致覆盖率较低。
技术实现要素:
本发明实施例提供一种poi别名的确定方法、装置、计算机设备和存储介质,可以提高poi的别名获取效率,降低poi的别名获取成本,提高poi的覆盖率。
第一方面,本发明实施例提供了一种poi别名的确定方法,包括:
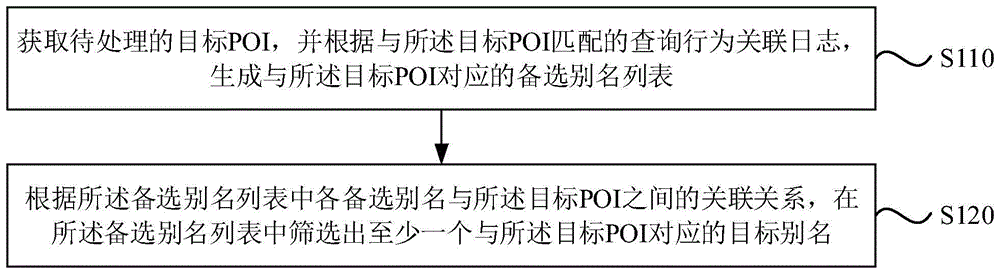
获取待处理的目标poi,并根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表;
根据所述备选别名列表中各备选别名与所述目标poi之间的关联关系,在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名。
第二方面,本发明实施例还提供了一种poi别名的确定装置,包括:
备选别名列表生产模块,用于获取待处理的目标poi,并根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表;
目标别名筛选模块,用于根据所述备选别名列表中各备选别名与所述目标poi之间的关联关系,在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名。
第三方面,本发明实施例还提供了一种设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序所述处理器执行所述程序时实现如本发明实施例中任一所述的poi别名的确定方法。
第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本发明实施例中任一所述的poi别名的确定方法。
本发明实施例通过获取目标poi匹配的查询行为关联日志,查询行为关联日志中包括针对目标poi的查询数据,随着互联网的普及,可以获取到的大量的网络用户针对目标poi的查询数据,在此基础上,根据查询行为关联日志生成备选别名列表,大大增加备选别名的覆盖率,同时,根据各备选别名与目标poi之间的关联关系,筛选出至少一个与目标poi对应的目标别名,实现准确确定poi的别名,解决了现有技术中poi别名生成的效率低、准确性低、成本高和覆盖率低的问题,可以提高poi备选别名的覆盖率,同时从大量的poi备选别名中进行筛选,可以提高目标别名在备选别名列表中的概率,从而提高poi别名确定的准确性,而且,避免人工生成poi别名,提高poi别名确定的效率,以及降低poi别名确定的成本。
附图说明
图1a是本发明实施例一中的一种poi别名的确定方法的流程图;
图1b是本发明实施例一中所适用应用场景的示意图;
图2a是本发明实施例二中的一种poi别名的确定方法的流程图;
图2b是本发明实施例二中所适用应用场景的示意图;
图3a是本发明实施例三中的一种poi别名的确定方法的流程图;
图3b是本发明实施例三中所适用应用场景的示意图;
图4是本发明实施例四中的一种poi别名的确定装置的结构示意图;
图5是本发明实施例五中的一种计算机设备的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1a为本发明实施例一中的一种poi别名的确定方法的流程图,本实施例可应用于确定poi的别名的情况。该方法可以由本发明实施例提供的poi别名的确定装置来执行,该装置可采用软件和/或硬件的方式实现,并一般可集成在提供确定poi的别名服务的计算机设备中,例如智能手机、平板电脑、车载终端或服务器等。如图1a所示,本实施例的方法具体包括:
s110,获取待处理的目标poi,并根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表。
其中,poi可以是指电子地图上的某个点,用于表示该点代表的职能,例如,可以标识出该点代表的政府部门、商业机构(加油站、百货公司、超市、餐厅、酒店或便利商店等)、旅游景点、基础设施(公园、公共厕所或医院等)、交通设施(车站、停车场或速限标示牌)等处所。通常,poi包括下述至少一项:名称、类别、经度、纬度和海拔等信息。
在本实施例中,poi的完整且通用的名称作为标准名称,其他可用于标识该poi的名称为别名。示例性的,a街道上的中学的标准名称为第十一中学,别名可以为11中学和十一中学等。
查询行为关联日志用于记录网络用户在提供lbs的应用程序中,针对目标poi的查询行为的数据。备选别名用于表示可能为目标poi别名的名称。备选别名列表用于存储备选别名。
根据查询行为关联日志,可以获取网络用户输入的检索关键词以及选择的查询结果中的关键词。若检索关键词与查询结果的关键词不同,可以根据查询结果中的关键词确定目标poi,并将检索关键词作为该目标poi的别名。此外,还可以通过其他方式实现,对此,本发明实施例不作具体限制。
可选的,所述根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表,包括下述至少一项:在地图类应用程序中,筛选出用户在第一查询结果页面中选择的导航至所述目标poi的第一类查询行为关联日志,并根据所述第一类查询行为关联日志中与所述第一查询结果页面匹配的第一查询式,生成所述备选别名列表;在点评类应用程序中,筛选出用户在第二查询结果页面中选择的购买与所述目标poi对应的服务商品的第二类查询行为关联日志,并根据所述第二类查询行为关联日志中与所述第二查询结果页面匹配的第二查询式,生成所述备选别名列表;以及在打车类应用程序中,筛选出用户在第三查询结果页面中选择的打车至与所述目标poi的第三类查询行为关联日志,并根据所述第三类查询行为关联日志中与所述第三查询结果页面匹配的第三查询式,生成所述备选别名列表。
其中,查询结果页面用于显示应用程序针对用户输入的查询式提供的查询结果。查询式用于应用程序进行查询。可以理解的是,用户通常会输入目标poi的惯用名称,用户在查询结果页面中最终选择的结果包括目标poi的标准名称,由此,可以通过查询结果页面中用户选择的结果中确定目标poi,同时将用户输入的名称作为该目标poi的别名添加至备选别名列表中。
第一类查询行为关联日志用于记录地图类应用程序中导航关联的查询数据。第一查询式用于地图类应用程序查询用户输入的导航目的地。示例性的,第一查询式为11中学,同时用户在查询结果页面中选择的导航至第十一中学,由此,确定目标poi的标准名称为第十一中学,对应的备选别名为11中学,从而,可以将11中学添加到目标poi为第十一中学的备选别名列表中。
第二类查询行为关联日志用于记录点评类应用程序中服务商品的购买关联的查询数据。第二查询式用于点评类应用程序查询用户输入的购买商品。示例性的,第二查询式为小羊皮,同时用户在查询结果页面中选择的购买的服务商品为纪梵希口红,由此,确定目标poi的标准名称为纪梵希口红,对应的备选别名为小羊皮,从而,可以将小羊皮添加到目标poi为纪梵希口红的备选别名列表中。
第三类查询行为关联日志用于记录打车类应用程序中打车关联的查询数据。第三查询式用于打车类应用程序查询用户输入的打车出发地和打车目的地。示例性的,第三查询式为kfc,同时用户在查询结果页面中选择的打车至肯德基,由此,确定目标poi的标准名称为肯德基,对应的备选别名为kfc,从而,可以将kfc添加到目标poi为肯德基的备选别名列表中。
通过获取用户的查询行为数据,并基于查询行为的查询结果,获取目标poi以及对应的备选别名,实现快速生成备选别名列表,而且,随着互联网的普及,查询行为数据的规模越来越大,从大量查询行为数据中筛选备选别名,可以大大提高备选别名的覆盖率。
需要说明的是,应用程序还可以是其他能够提供lbs服务的应用程序,例如,旅游类应用程序,对此,本发明实施例不作具体限制。
s120,根据所述备选别名列表中各备选别名与所述目标poi之间的关联关系,在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名。
其中,关联关系用于评价备选别名与目标poi的相关密切程度,具体的,可以计算备选别名与目标poi的标准名称之间的相似度,以表示备选别名与目标poi之间的关联关系。目标别名用于标识目标poi,通常,目标别名是指除目标poi的标准名称之外的名称。
可选的,在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名之前,还包括:在所述备选别名列表中,筛除与所述目标poi的标准名称一致的备选别名,和/或在所述备选别名列表中,筛除在所述查询行为关联日志中的出现次数小于设定次数阈值的备选别名。
具体的,可以预先对备选别名列表进行初步筛选。实际上,别名是大多数人使用,但并非是标准名称的名称。示例性的,可以通过构建序列确定目标poi以及对应的备选别名列表。例如,从查询行为关联日志中提取<query1,query2,poi1,poi2>的序列,queryn代表备选别名,poin代表标准名称,分别构成候选集<query1,poi1>和<query2,poi2>,可以通过预设规则,去除query和poi名称一致的,去除关系对低频出现的。
通过筛除目标poi的标准名称,和/或筛除使用次数低的别名,将不可能是poi别名的标准名称以及仅有少数用户知道且通用性不高的别名滤除,实现对备选别名列表的筛选,减少备选别名的判别的数据量,提高目标别名确定的效率。
在一个具体的例子中,如图1b所示,根据目标poi获取查询行为关联日志,由此筛选备选别名列表,并基于预设的规则进行过滤,得到过滤后的备选别名列表,从过滤后的备选别名列表中筛选目标别名,提高别名确定的准确率。
本发明实施例通过获取目标poi匹配的查询行为关联日志,查询行为关联日志中包括针对目标poi的查询数据,随着互联网的普及,可以获取到的大量的网络用户针对目标poi的查询数据,在此基础上,根据查询行为关联日志生成备选别名列表,大大增加备选别名的覆盖率,同时,根据各备选别名与目标poi之间的关联关系,筛选出至少一个与目标poi对应的目标别名,实现准确确定poi的别名,解决了现有技术中poi别名生成的效率低、准确性低、成本高和覆盖率低的问题,可以提高poi备选别名的覆盖率,同时从大量的poi备选别名中进行筛选,可以提高目标别名在备选别名列表中的概率,从而提高poi别名确定的准确性,而且,避免人工生成poi别名,提高poi别名确定的效率,以及降低poi别名确定的成本。
实施例二
图2a为本发明实施例二中的一种poi别名的确定方法的流程图,本实施例以上述实施例为基础进一步具体化,将所述根据所述备选别名列表中各备选别名与所述目标poi之间的关联关系,在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名,具体化为:获取与所述备选别名列表中各个备选别名对应的至少一项别名描述特征;将各所述备选别名的至少一项别名描述特征分别输入至预先训练的poi别名识别模型中,并获取所述poi别名识别模型输出的,与各所述备选别名对应的别名概率;根据各所述备选别名的别名概率,在所述备选别名列表中筛选出至少一个目标别名。该方法具体包括:
s210,获取待处理的目标poi,并根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表。
本实施例中的目标poi、查询行为关联日志、查询行为关联日志、关联关系、标准名称和目标别名等具体可以参考上述实施例的描述。
其中,所述根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表,包括下述至少一项:在地图类应用程序中,筛选出用户在第一查询结果页面中选择的导航至所述目标poi的第一类查询行为关联日志,并根据所述第一类查询行为关联日志中与所述第一查询结果页面匹配的第一查询式,生成所述备选别名列表;在点评类应用程序中,筛选出用户在第二查询结果页面中选择的购买与所述目标poi对应的服务商品的第二类查询行为关联日志,并根据所述第二类查询行为关联日志中与所述第二查询结果页面匹配的第二查询式,生成所述备选别名列表;以及在打车类应用程序中,筛选出用户在第三查询结果页面中选择的打车至与所述目标poi的第三类查询行为关联日志,并根据所述第三类查询行为关联日志中与所述第三查询结果页面匹配的第三查询式,生成所述备选别名列表。
s220,通过预设的词向量模型,获取所述目标poi的标准名称以及所述备选别名列表中每个备选别名的词向量。
其中,词向量模型用于确定名称的词向量。具体的,词向量模型可以是词向量的集合,也可以是预先训练用于计算文本的词向量的机器学习模型,例如连续词袋(continuousbag-of-words,cbow)模型或向量空间模型(vectorspacemodels,vsms)等。
当词向量模型为词向量的集合时,可选的,在通过预设的词向量模型,获取所述目标poi的标准名称以及所述备选别名列表中每个备选别名的词向量之前,还包括:根据与所述目标poi匹配的点评类数据,和/或检索类数据生成文本语料库;采用分词词典,对所述文本语料库中包括的文档进行分词处理,得到多个分词,其中,所述分词词典中包括:所述目标poi的标准名称以及所述备选别名列表中包括的各备选别名;按照预设的词向量计算方法,计算各所述分词的词向量作为所述词向量模型。
其中,点评类数据可以是指针对poi进行评论的数据,示例性的,poi是餐厅,点评类数据包括针对poi的服务质量评价。检索类数据可以是指针对poi进行查询的相关数据,示例性的,poi是餐厅,检索类数据包括针对poi包含的菜谱的检索。可以理解的是,点评类数据通常包括poi的名称(标准名称或别名)以及针对poi的点评数据;检索类数据通常包括poi的名称(标准名称或别名)以及针对poi的查询数据。文本语料库用于存储包含poi名称的关联数据,其中,各poi分别存储与文档中,不同poi对应不同文档。
分词词典用于分词。具体的,从待分词的文本中筛选目标字符串与分词词典中的词语进行匹配,若在分词词典中查询到与目标字符串相同的字符串,则可以将目标字符串从待分词的文本中切分出来,并从剩余的文本中继续筛选目标字符串在分词词典中进行查询。
其中,预设词向量计算方法用于计算各分词的词向量,可以包括基于统计的方法或基于语言模型的方法。计算文本语料库中各分词的词向量,实际是基于文本语料库采用词嵌入(wordembedding)方法,实现文本语料库中的所有分词都得到对应的词向量,由此得到的词向量可以用于描述各分词在文本语料库中与其他分词之间的关系。同时,分词中包括poi的标准名称和备选别名,从而,基于文本语料库计算的词向量可以准确描述标准名称与备选别名之间的关系。
通过获取poi的点评类数据和/或检索类数据,并采用分词方法获取poi的标准名称以及至少一个备选别名,实现从海量网络数据中搜集poi的名称,并采用词向量计算方法,分别计算文本语料库中各分词的词向量,以表示各分词之间的关系,用于后续准确确定标准名称与备选别名的关系。
其中,可选的,所述根据与所述目标poi匹配的点评类数据,和/或检索类数据生成文本语料库,包括下述至少一项:在点评类网站中,获取所述目标poi的点评页面,并将所述点评界面中包括的评论数据构成文档,以生成所述文本语料库;将所述第一类查询行为关联日志中的所述第一查询式与所述目标poi组合成文档,以生成所述文本语料库;将所述第二类查询行为关联日志中的所述第二查询式与所述目标poi组合成文档,以生成所述文本语料库;以及将所述第三类查询行为关联日志中的所述第三查询式与所述目标poi组合成文档,以生成所述文本语料库。
具体的,点评类数据可以从点评类网站中获取,具体可以确定包括poi的点评页面,并从该点评页面中获取与poi对应的点评数据,由此生成包括poi以及对应的点评数据的文档,并添加至文本语料库。
检索类数据可以从提供lbs应用程序所记录的用户查询数据中获取,其中,提供lbs应用程序可以包括下述至少一项:前述地图类应用程序、点评类应用程序和打车类应用程序等应用程序。获取应用程序中用户输入的查询式以及poi组合成文档,实现生成包括poi以及对应查询式的文档,并添加至文本语料库中。
通过获取poi以及对应的数据,并生成文档,保证文档至少包括poi以及poi对应的相关数据,并将文档添加至文本语料库,实现文本语料库包括与poi相关的数据,从而后续基于文本语料库中的分词计算词向量时,可以准确计算用于描述poi标准名称和备选别名的关系的词向量。
s230,分别计算所述目标poi的标准名称与每个所述备选别名之间的向量相似度。
根据标准名称的词向量和对应的备选别名的词向量,计算向量相似度。具体计算方法可以是计算两个词向量之间夹角的余弦值。
s240,根据向量相似度计算结果,在所述备选别名列表中筛选出至少一个目标别名。
示例性的,筛选方式可以是将向量相似度计算结果超过预设阈值的备选别名作为目标别名。
在一个具体的例子中,如图2b所示,根据目标poi获取查询行为关联日志,由此筛选备选别名列表,并基于预设的规则进行过滤,得到过滤后的备选别名列表,基于过滤后的备选别名列表中各备选别名的词向量与目标poi的标准名称的词向量之间的向量相似度筛选目标别名。
本发明实施例通过获取目标poi的标准名称的词向量以及备选别名的词向量,并计算标准名称与每个备选别名之间的向量相似度,准确描述标准名称与每个备选别名之间关系,同时,基于向量相似度度量标准名称与每个备选别名之间关系,实现准确描述标准名称与每个备选别名之间关系,并根据关系筛选目标别名,实现准确筛选别名。
实施例三
图3a为本发明实施例三中的一种poi别名的确定方法的流程图,本实施例以上述实施例为基础进一步具体化,将所述根据所述备选别名列表中各备选别名与所述目标poi之间的关联关系,在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名,具体化为:获取与所述备选别名列表中各个备选别名对应的至少一项别名描述特征;将各所述备选别名的至少一项别名描述特征分别输入至预先训练的poi别名识别模型中,并获取所述poi别名识别模型输出的,与各所述备选别名对应的别名概率;根据各所述备选别名的别名概率,在所述备选别名列表中筛选出至少一个目标别名。该方法具体包括:
s310,获取待处理的目标poi,并根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表。
本实施例中的目标poi、查询行为关联日志、查询行为关联日志、关联关系、标准名称和目标别名等具体可以参考上述实施例的描述。
s320,获取与所述备选别名列表中各个备选别名对应的至少一项别名描述特征。
其中,别名描述特征用于确定与标准名称之间的关系。
可选的,所述别名描述特征包括下述至少一项:标准别名与对应标准名称之间的向量相似度、标准别名与对应标准名称分别在设定语料库中的词频、标准别名与对应标准名称的中文编辑距离、标准别名与对应标准名称的英文编辑距离、标准别名与对应标准名称的中英文缩写编辑距离、标准别名与对应标准名称的品牌名编辑距离、对应标准样本poi的热度、对应标准样本poi功能区特征、对应标准样本poi的周边poi的类型、和对应标准样本poi的周边poi密度。
其中,标准别名可以是指已经认证的目标poi的别名。
标准别名与对应标准名称之间的向量相似度用于表示标准别名与标准名称之间的相似程度。
标准别名与对应标准名称分别在设定语料库中的词频用于表示标准别名在设定语料库中的出现的频率,以及标准名称在设定语料库中的出现的频率。
编辑距离可以是指两个字符串之间,由一个转换成另外一个所需的最小编辑操作次数。
标准别名与对应标准名称的中文编辑距离用于表示中文标准别名与对应中文标准名称之间的相似程度。
标准别名与对应标准名称的英文编辑距离用于表示英文标准别名与对应英文标准名称之间的相似程度。
标准别名与对应标准名称的中英文缩写编辑距离用于表示中英文缩写标准别名与对应中英文缩写标准名称之间的相似程度。
标准别名与对应标准名称的品牌名编辑距离用于表示标准别名与标准名称对应的品牌名之间的相似程度。
对应标准样本poi的热度用于表示标准别名对应标准样本poi的使用率,例如,检索次数和/或查询次数等。
此外,poi还可以用于代表一个功能区,例如商圈、广场、学院、住宅区或科技园等具备较大区域范围的场所,poi功能区通常包括多个场所,示例性的,一个科技园poi包括写字楼、公司企业、停车场和交通设施等。
对应标准样本poi功能区特征用于表示代表功能区的标准样本poi的数量特征(如包括的商铺的数量)和/或属性特征(如包括的场所的类型)等。
对应标准样本poi的周边poi的类型用于表示标准样本poi附近的poi的类型。示例性的,poi漏洞类型包括商业机构、旅游景点、交通站点或基础设施(如医院)等。
对应标准样本poi的周边poi密度用于表示标准样本poi附近的poi的密集程度。
通过预设多个描述特征,可以准确描述别名的特征,可以提高描述特征的代表性,从而,提高poi别名识别模型的鉴别准确率。
s330,将各所述备选别名的至少一项别名描述特征分别输入至预先训练的poi别名识别模型中,并获取所述poi别名识别模型输出的,与各所述备选别名对应的别名概率。
其中,别名概率用于评价poi的备选别名为poi别名的概率值,例如,例如,80%或者90%等。
poi别名识别模型是预先训练的机器学习模型,用于计算备选别名为poi别名的别名概率。具体的,机器学习模型可以包括支撑向量机、逻辑回归、决策树、梯度提升决策树(gradientboostingtrees)或神经网络等模型。
s340,根据各所述备选别名的别名概率,在所述备选别名列表中筛选出至少一个目标别名。
具体的,可以通过预设别名阈值条件筛选目标别名。别名阈值条件用于判断备选别名是否为poi的别名,例如别名阈值条件限定了一个具体的阈值,例如,70%或者80%等。
在上述实施例的基础上,可选的,在获取与所述备选别名列表中各个备选别名对应的至少一项别名描述特征之前,还包括:获取至少一个标准样本数据,所述标准样本数据包括:标准样本poi的标准名称,以及与所述标准样本poi对应的标准别名;获取与每个标准样本数据中的标准别名分别对应的至少一项别名描述特征;将与每个样本数据中的标准别名分别对应的至少一项别名描述特征,输入至标准机器学习模型中对所述标准机器学习模型进行训练,得到所述poi别名识别模型。
具体的,根据poi的标准名称,以及对应的标准别名构造的标准样本poi,并将标准样本poi的至少一项poi描述特征作为训练样本,对标准机器学习模型进行训练,以得到poi别名识别模型。通过将由标准名称和标准别名构造的标准样本poi对应的至少一项poi描述特征作为训练样本,训练得到poi别名识别模型,提高poi别名识别模型的计算准确率。
需要说明的是,除了标准样本poi,还可以构建随机生成的包括目标poi与目标poi无关的别名的负样本作为训练样本对模型进行训练。
其中,获取至少一个标准样本数据可以是pgc的方式标注数据,得到用于构造标准样本数据的标准名称和对应标准别名。或者还可以通过用户的查询行为数据构建。
可选的,所述获取至少一个标准样本数据,包括:根据与位置服务类应用程序对应的查询行为关联日志,生成多个样本组数据,包括:用户查询式、用户点击poi以及用户实际到访poi;在所述样本组数据中,筛选出用户查询式与用户点击poi不同,且用户点击poi与用户实际到访poi相同的目标样本组;以所述目标样本组中包括的用户查询式作为备选别名,以用户点击poi的标准名称作为备选样本poi的标准名称,构造备选样本数据;分别获取各所述备选样本数据中备选别名以及备选样本poi的词向量,并计算备选别名与对应备选样本poi的标准名称之间的向量相似度;根据各所述备选样本数据对应的向量相似度,在所述备选样本数据中筛选出标准样本数据。
其中,样本组数据用于表示样本组的数据。样本组数据包括多个样本组的数据。每个样本组包括用户查询式、用户点击poi以及用户实际到访poi等数据。用户查询式用于表示用户输入的针对poi的查询文本。用户点击poi用于表示用户从针对poi的查询结果中选择的结果。用户实际到访poi用于表示用户发生执行操作的poi,示例性的,打车类应用程序中,用户输入打车目的地,用户查询式poi为kfc,用户点击poi为肯德基,用户实际到访poi为用户到达目的地肯德基。可以理解的是,当用户输入poi的别名时,出现用户输入文本与用户点击的查询结果中的poi的名称不同,同时查询结果中的poi的名称与用户最终实现的poi的名称相同的情况,也即用户查询式与用户点击poi不同,且用户点击poi与用户实际到访poi相同。由此,可以根据用户查询式与用户点击poi不同,且用户点击poi与用户实际到访poi相同的条件,确定用户查询式作为备选别名,以及用户点击poi作为备选样本poi,并构造备选样本数据。
为了保证备选样本数据的代表性,可以通过计算备选别名的词向量和对应标准名称的词向量之间的向量相似度,筛选出的标准样本数据。
通过根据查询行为关联日志生成多个样本组数据,并筛选出用户查询式与用户点击poi不同,且用户点击poi与用户实际到访poi相同的目标样本组,构造备选样本数据,同时,计算备选样本数据中备选别名的词向量和对应标准名称的词向量之间的向量相似度,筛选出的标准样本数据,提高标准样本数据的代表性,从而,提高poi别名识别模型的计算准确率。
在一个具体的例子中,针对一个poi,获取大量用户搜索一个query(用户查询式),点击该poi,并线下到访该poi,由此,可以构建大量的<useri,queryi,cpoii,apoii>的样本组,其中,cpoii用于描述用户在提供lbs的应用程序上进行了点击操作,cpoii用于描述通过用户定位或支付等操作数据判断用户真实到达了该poi。当该样本组满足如下条件时:queryi!=name(cpoii),name(cpoii)=name(apoii),其中,name()函数表示取对应poi的标准名称,而且<queryi,poii>的向量相似度超过设定阈值,将<queryi,poii>作为标准样本数据用于训练模型。
在一个具体的例子中,如图3b所示,根据目标poi获取查询行为关联日志,由此筛选备选别名列表,并基于预设的规则进行过滤,得到过滤后的备选别名列表,将过滤后的备选别名列表中各备选别名的至少一个别名描述特征输入到poi别名识别模型中,得到poi别名识别模型输出的各备选别名的别名概率,并基于各备选别名的别名概率筛选目标别名。
本发明实施例通过基于备选别名的描述特征,采用poi别名识别模型实现poi的备选别名判断,提高poi别名判断的准确性,降低人工成本,提高poi别名判断的效率。
实施例四
图4是本发明实施例四中的一种poi别名的确定装置的结构示意图,如图4所示,所述装置具体包括:
备选别名列表生产模块410,用于获取待处理的目标poi,并根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表;
目标别名筛选模块420,用于根据所述备选别名列表中各备选别名与所述目标poi之间的关联关系,在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名。
本发明实施例通过获取目标poi匹配的查询行为关联日志,查询行为关联日志中包括针对目标poi的查询数据,随着互联网的普及,可以获取到的大量的网络用户针对目标poi的查询数据,在此基础上,根据查询行为关联日志生成备选别名列表,大大增加备选别名的覆盖率,同时,根据各备选别名与目标poi之间的关联关系,筛选出至少一个与目标poi对应的目标别名,实现准确确定poi的别名,解决了现有技术中poi别名生成的效率低、准确性低、成本高和覆盖率低的问题,可以提高poi备选别名的覆盖率,同时从大量的poi备选别名中进行筛选,可以提高目标别名在备选别名列表中的概率,从而提高poi别名确定的准确性,而且,避免人工生成poi别名,提高poi别名确定的效率,以及降低poi别名确定的成本。
进一步的,所述备选别名列表生产模块410,具体用于下述至少一项:在地图类应用程序中,筛选出用户在第一查询结果页面中选择的导航至所述目标poi的第一类查询行为关联日志,并根据所述第一类查询行为关联日志中与所述第一查询结果页面匹配的第一查询式,生成所述备选别名列表;在点评类应用程序中,筛选出用户在第二查询结果页面中选择的购买与所述目标poi对应的服务商品的第二类查询行为关联日志,并根据所述第二类查询行为关联日志中与所述第二查询结果页面匹配的第二查询式,生成所述备选别名列表;以及在打车类应用程序中,筛选出用户在第三查询结果页面中选择的打车至与所述目标poi的第三类查询行为关联日志,并根据所述第三类查询行为关联日志中与所述第三查询结果页面匹配的第三查询式,生成所述备选别名列表。
进一步的,所述poi别名的确定装置,具体还可以包括:备选别名筛除单元,用于在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名之前,在所述备选别名列表中,筛除与所述目标poi的标准名称一致的备选别名,和/或在所述备选别名列表中,筛除在所述查询行为关联日志中的出现次数小于设定次数阈值的备选别名。
进一步的,所述目标别名筛选模块420,具体用于:通过预设的词向量模型,获取所述目标poi的标准名称以及所述备选别名列表中每个备选别名的词向量;分别计算所述目标poi的标准名称与每个所述备选别名之间的向量相似度;根据向量相似度计算结果,在所述备选别名列表中筛选出至少一个目标别名。
进一步的,所述poi别名的确定装置,具体还可以包括:文本语料库生成单元,用于在通过预设的词向量模型,获取所述目标poi的标准名称以及所述备选别名列表中每个备选别名的词向量之前,根据与所述目标poi匹配的点评类数据,和/或检索类数据生成文本语料库;分词处理单元,用于采用分词词典,对所述文本语料库中包括的文档进行分词处理,得到多个分词,其中,所述分词词典中包括:所述目标poi的标准名称以及所述备选别名列表中包括的各备选别名;词向量计算单元,用于按照预设的词向量计算方法,计算各所述分词的词向量作为所述词向量模型。
进一步的,所述文本语料库生成单元,具体用于下述至少一项:在点评类网站中,获取所述目标poi的点评页面,并将所述点评界面中包括的评论数据构成文档,以生成所述文本语料库;将所述第一类查询行为关联日志中的所述第一查询式与所述目标poi组合成文档,以生成所述文本语料库;将所述第二类查询行为关联日志中的所述第二查询式与所述目标poi组合成文档,以生成所述文本语料库;以及将所述第三类查询行为关联日志中的所述第三查询式与所述目标poi组合成文档,以生成所述文本语料库。
进一步的,所述目标别名筛选模块420,具体用于:获取与所述备选别名列表中各个备选别名对应的至少一项别名描述特征;将各所述备选别名的至少一项别名描述特征分别输入至预先训练的poi别名识别模型中,并获取所述poi别名识别模型输出的,与各所述备选别名对应的别名概率;根据各所述备选别名的别名概率,在所述备选别名列表中筛选出至少一个目标别名。
进一步的,所述poi别名的确定装置,具体还可以包括:标准样本数据获取单元,用于在获取与所述备选别名列表中各个备选别名对应的至少一项别名描述特征之前,获取至少一个标准样本数据,所述标准样本数据包括:标准样本poi的标准名称,以及与所述标准样本poi对应的标准别名;别名描述特征获取单元,用于获取与每个标准样本数据中的标准别名分别对应的至少一项别名描述特征;poi别名识别模型训练单元,用于将与每个样本数据中的标准别名分别对应的至少一项别名描述特征,输入至标准机器学习模型中对所述标准机器学习模型进行训练,得到所述poi别名识别模型。
进一步的,所述别名描述特征包括下述至少一项:标准别名与对应标准名称之间的向量相似度、标准别名与对应标准名称分别在设定语料库中的词频、标准别名与对应标准名称的中文编辑距离、标准别名与对应标准名称的英文编辑距离、标准别名与对应标准名称的中英文缩写编辑距离、标准别名与对应标准名称的品牌名编辑距离、对应标准样本poi的热度、对应标准样本poi功能区特征、对应标准样本poi的周边poi的类型、和对应标准样本poi的周边poi密度。
进一步的,所述标准样本数据获取单元,具体用于:根据与位置服务类应用程序对应的查询行为关联日志,生成多个样本组数据,包括:用户查询式、用户点击poi以及用户实际到访poi;在所述样本组数据中,筛选出用户查询式与用户点击poi不同,且用户点击poi与用户实际到访poi相同的目标样本组;以所述目标样本组中包括的用户查询式作为备选别名,以用户点击poi的标准名称作为备选样本poi的标准名称,构造备选样本数据;分别获取各所述备选样本数据中备选别名以及备选样本poi的词向量,并计算备选别名与对应备选样本poi的标准名称之间的向量相似度;根据各所述备选样本数据对应的向量相似度,在所述备选样本数据中筛选出标准样本数据。
上述poi别名的确定装置可执行本发明任意实施例所提供的poi别名的确定方法,具备执行的poi别名的确定方法相应的功能模块和有益效果。
实施例五
图5为本发明实施例五提供的一种计算机设备的结构示意图。图5示出了适于用来实现本发明实施方式的示例性计算机设备512的框图。图5显示的计算机设备512仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
如图5所示,计算机设备512以通用计算设备的形式表现。计算机设备512的组件可以包括但不限于:一个或者多个处理器或者处理单元516,系统存储器528,连接不同系统组件(包括系统存储器528和处理单元516)的总线518。计算机设备512可以是车载设备。
总线518表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器,外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(industrystandardarchitecture,isa)总线,微通道体系结构(microchannelarchitecture,mca)总线,增强型isa总线、视频电子标准协会(videoelectronicsstandardsassociation,vesa)局域总线以及外围组件互连(peripheralcomponentinterconnect,pci)总线。
计算机设备512典型地包括多种计算机系统可读介质。这些介质可以是任何能够被计算机设备512访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
系统存储器528可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(ram)530和/或高速缓存存储器532。计算机设备512可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统534可以用于读写不可移动的、非易失性磁介质(图5未显示,通常称为“硬盘驱动器”)。尽管图5中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如紧凑磁盘只读存储器(compactdiscread-onlymemory,cd-rom),数字视盘(digitalvideodisc-readonlymemory,dvd-rom)或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线518相连。存储器528可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本发明各实施例的功能。
具有一组(至少一个)程序模块542的程序/实用工具540,可以存储在例如存储器528中,这样的程序模块542包括——但不限于——操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块542通常执行本发明所描述的实施例中的功能和/或方法。
计算机设备512也可以与一个或多个外部设备514(例如键盘、指向设备、显示器524等)通信,还可与一个或者多个使得用户能与该计算机设备512交互的设备通信,和/或与使得该计算机设备512能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(input/output,i/o)接口522进行。并且,计算机设备512还可以通过网络适配器520与一个或者多个网络(例如局域网(localareanetwork,lan),广域网(wideareanetwork,wan)通信。如图所示,网络适配器520通过总线518与计算机设备512的其它模块通信。应当明白,尽管图5中未示出,可以结合计算机设备512使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、(redundantarraysofinexpensivedisks,raid)系统、磁带驱动器以及数据备份存储系统等。
处理单元516通过运行存储在系统存储器528中的程序,从而执行各种功能应用以及数据处理,例如实现本发明实施例所提供的一种poi别名的确定方法。
实施例六
本发明实施例六还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本申请所有发明实施例提供的poi别名的确定方法:所述方法包括:获取待处理的目标poi,并根据与所述目标poi匹配的查询行为关联日志,生成与所述目标poi对应的备选别名列表;根据所述备选别名列表中各备选别名与所述目标poi之间的关联关系,在所述备选别名列表中筛选出至少一个与所述目标poi对应的目标别名。
本发明实施例的计算机存储介质,可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、ram、只读存储器(readonlymemory,rom)、可擦式可编程只读存储器(erasableprogrammablereadonlymemory,eprom)、闪存、光纤、便携式cd-rom、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括——但不限于——电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括——但不限于——无线、电线、光缆、无线电频率(radiofrequency,rf)等等,或者上述的任意合适的组合。
可以以一种或多种程序设计语言或其组合来编写用于执行本发明操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、smalltalk、c++,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络——包括lan或wan——连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!