Kinect深度相机的标记物及基于该标记物的虚拟标记物跟踪方法与流程
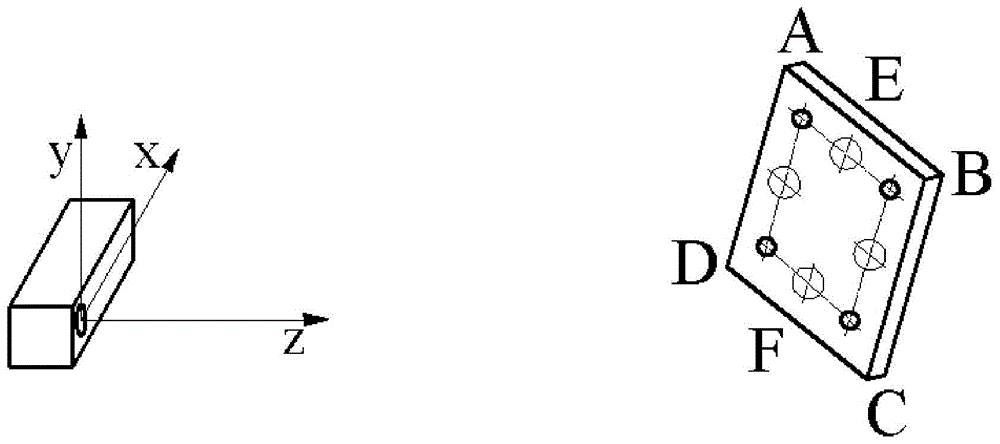
本发明属于计算机视觉测量技术领域,尤其涉及利用标记物进行视觉跟踪的方法。
背景技术:
在图像工程的应用中,经常利用目标物体的特征点来表示目标物体的本身。一个完整的特征点能够为目标物体提供足够的约束,而且表示这些特征仅仅需要很少的数据量。描述目标物体的特征点一般指的是目标区域的拐角点、封闭轮廓线的中心、纹理特征或者其他的突出点。另外,人为设计的特征,也称之为标记物,用以将特定物体和其他物体区别出来,这样可以提高目标物体识别和定位的实时性和稳定性。因此,基于标记物的跟踪算法在单目、双目相机中都有广泛应用。但是,传统深度相机的分辨率较低,难以获取精细的图像特征,所以通常将其与rgb相机一起使用。但是rgb相机对环境光的变化敏感,其与深度相机的标定也易引入误差。
技术实现要素:
本发明是为了解决传统深度相机的分辨率较低,难以获取精细的图像特征;而与rgb相机使用时,标定还容易引入误差的问题,现提供kinect深度相机的标记物及基于该标记物的虚拟标记物跟踪方法。
kinect深度相机的标记物,所述标记物包括表面均匀覆盖有近红外反光粉末的基质,所述标记物厚度小于等于0.2mm。所述基质为圆片或球形结构。
基于上述标记物的虚拟标记物跟踪方法,包括以下步骤:
s1:利用kinect深度相机对粘贴有n个标记物的平面进行拍摄、并获得近红外图像和深度数据帧,n为大于等于2的正整数,所述平面法向量与kinect深度相机的光轴夹角小于等于40度,所述平面为白色哑光平面、且反射率大于0.8;
s2:在近红外图像中分别提取每个标记物的几何中心坐标;
s3:在深度数据帧中,根据透视投影过程和平面性质获取每个标记物几何中心坐标对应的深度值;
s4:将相邻的两个标记物作为一组,每组中在两个标记物几何中心连线上取深度值有效的一点作为一个虚拟标记物,取m个虚拟标记物,当n=2时,m=1,当n≥3时,m≥3且任意3个虚拟标记物不共线,然后利用每个标记物的几何中心坐标和深度值分别获得m个虚拟标记物的图像坐标;
s5:利用m个虚拟标记物的图像坐标分别获取m个虚拟标记物的深度值;
s6:对m个虚拟标记物的图像坐标及深度值进行降噪;
s7:将s6中降噪后的m个虚拟标记物的图像坐标及其对应的深度值、通过透视投影逆过程变换至kinect深度相机局部坐标系下的三维空间中,获得m个虚拟标记物的实时三维坐标,完成虚拟标记物的跟踪。
上述s2中在近红外图像中分别提取每个标记物的几何中心坐标的具体步骤为:
s21:对近红外图像进行阈值分割获得二值图像,所述阈值能够将标记物和背景区分开;
s22:遍历二值图像中的每个像素,利用区域增长算法提取每个标记物的像素集合;
s23:对每个标记物的像素集合进行平均,获得每个标记物的几何中心坐标。
上述s3中获取每个标记物几何中心坐标对应的深度值的具体步骤为:
s31:分别获取与每个标记物相邻的四个像素
s32:在深度数据帧中,对四个像素对应的深度值进行插值,获得每个标记物对应的四个像素的深度值
s33:根据s32获得的四个像素的深度值、插值获得每个标记物几何中心坐标对应的深度值。
上述s4中,将相邻的两个虚拟标记物作为一组,每组中两个虚拟标记物连线上的任意一点也能够作为一个虚拟标记物。
上述s6中利用卡尔曼滤波器进行降噪。
上述s7中虚拟标记物的实时三维坐标[xyd]的表达式通过下式获得:
[xyd]t=k-1[dudvd]t
其中,k表示kinect深度相机的内参矩阵,[uv]表示虚拟标记物的图像坐标,d表示虚拟标记物的深度值。
本发明所述的供kinect深度相机的标记物区域在近红外接收器上接收到幅值饱和的近红外反射光线,使其在kinect深度相机输出的近红外图像中显示为高亮区域。
本发明所述的基于上述标记物的虚拟标记点跟踪方法,在kinect深度相机输出的近红外图像上,识别和提取标记物区域,并求其几何中心像素坐标;利用对应的深度图,根据相机透视投影模型和平面性质插值计算标记物几何中心相对kinect深度相机的深度值;虚拟标记点指两个标记物几何中心连线上的点,采用基于深度图的像素插值算法求得虚拟标记点的图像坐标;在深度图中对虚拟标记点的深度值进行索引并滤波;使用卡尔曼滤波器对虚拟标记点的图像坐标和深度进行滤波,再通过透视投影逆过程得到虚拟标记点的三维坐标,完成对虚拟标记点的跟踪。本发明使用飞行时间(time-of-flight,tof)相机,所实现的虚拟标记点跟踪,较直接跟踪粘贴标记物具有更高的精度,适用于其它tof相机,实现低成本、快速、鲁棒性的运动物体跟踪。
附图说明
图1为kinect深度相机拍摄对粘贴有4个标记物的平面进行拍摄时的示意图,其中点a、b、c和d分别为四个标记物,e和f分别为两个虚拟标记物;
图2为标记物的近红外图像和其对应的深度点云的对比示意图;
图3为基于平面信息和深度图像的深度插值过程示意图;
图4为基于平面信息和深度图像的像素插值过程示意图;
图5为平面深度信息示意图。
具体实施方式
kinectv2是微软2014年发布rgb-d类型传感器。kinectv2包含一个普通光学相机以及一个tof相机,能够以每秒30帧的速率实时返回拍摄场景的深度信息。由于kinectv2的深度相机的较高分辨率,单独为该相机设计标记物可以使系统更加紧凑。另外,该深度相机采用主动近红外成像原理,对环境光不敏感,甚至可以在无光的环境下工作。
本发明的目的是针对kinectv2深度相机设计一种人工标记物,利用该标记物对近红外反光的特性,在红外图像中快速分割、提取标记物。结合深度相机获取的深度信息,实现对人工标记物进行实时跟踪的目的,具体如以下实施方式。
具体实施方式一:本实施方式所述的kinect深度相机的标记物,所述标记物包括表面均匀覆盖有近红外反光粉末的基质。
实际操作时,将高反射率材料制成的粉末平铺于具有双面胶性基质的表面,并要求近红外反光粉末均匀覆盖该基质的表面,能够很好地反射kinect深度相机所发射的红外光,在近红外传感器上接收到幅值饱和的红外反射光线,使其在kinect深度相机输出的近红外图像中显示为高亮区域。
具体的,基质为圆片或球形结构;基质为圆片,即制成可粘贴的二维反光的物理标记物,且该带反光材料的胶性基质整体厚度不超过0.2mm。
具体实施方式二:参照图1至5具体说明本实施方式,本实施方式是基于具体实施方式一所述的kinect深度相机的标记物的虚拟标记物跟踪方法,本实施方式中,包括以下步骤:
s1:如图1和图2所示,取4个具体实施方式一所述的标记物,分别记为a、b、c、d,并将4个标记物粘贴于白纸上,且四个标记物分别位于边长为60mm正方形的四个角上,然后将白纸粘贴在平整的表面上;
利用kinect深度相机对粘贴有4个标记物的白纸平面进行拍摄、并获得近红外图像和深度数据帧;
所述平面法向量与kinect深度相机的光轴夹角小于等于40度,kinect深度相机与平面距离为760mm-1400mm,所述平面为哑光平面、且反射率大于0.8,n为大于等于2的正整数;
上述步骤中,白纸要求表面哑光,具有良好的漫反射特性,厚度不超过0.2mm。
s2:在近红外图像中分别提取4个标记物的几何中心坐标,具体步骤如下:
s21:对近红外图像进行阈值分割获得二值图像,所述阈值能够将标记物和背景区分开;
s22:遍历二值图像中的每个像素,利用区域增长算法分别提取4个标记物的像素集合na={ai|i=1,2,3,...,a}、nb={bi|i=1,2,3,...,b}、nc={ci|i=1,2,3,...,c}、nd={di|i=1,2,3,...,d},a、b、c和d分别为4个标记物像素集合中的像素个数,ai、bi、ci和di分别表示4个标记物在近红外图像中的第i个像素坐标;
s23:对每个标记物的像素集合进行平均;
以标记物a为例,利用以下公式对标记物a的像素集合的集合中心进行平均,其中ai=[uivi],标记物a的几何中心坐标
s3:在深度数据帧中,根据透视投影过程和平面性质获取每个标记物几何中心坐标对应的深度值,如图3所示,以标记物a为例,具体步骤如下:
s31:分别获取与标记物a相邻的四个像素
s32:在深度数据帧中,对四个像素对应的深度值进行插值,获得标记物a对应的四个像素的深度值
其中,dp表示像素p的深度值,
s33:根据s32获得的四个像素的深度值、插值获得标记物a几何中心坐标对应的深度值dq:
其中,中间变量
其中,za和zb分别表示深度数据帧中标记物集合中心a和b所对应的深度值,α=|ac|/|ab|,c表示标记物集合中心a和b连线上任一点的坐标,则zc表示深度数据帧中c所对应的深度值。
s4:将相邻的两个标记物作为一组,每组中两个标记物连线的中点作为虚拟标记物,取4个虚拟标记物,然后利用每个标记物的几何中心坐标和深度值分别获得4个虚拟标记物的图像坐标;
实际应用时,还能够将相邻的两个虚拟标记物作为一组,每组中两个虚拟标记物连线上的任意一点也能够作为一个虚拟标记物,或者将两个虚拟标记物连线的中点作为一个虚拟标记物;
上述虚拟标记物个数的选取规则为:如果使用虚拟标记物进行六自由度(位置和姿态)的刚体跟踪,则虚拟标记物应不共线且至少3个。实际应用时,对于多个标记物的情况,虚拟标记物的个数可由用户指定和组合。
如图4所示,a和b连线的中点为虚拟标记物e,c和d连线的中点为虚拟标记物f。
上述虚拟标记物的图像坐标[uvvv]为,
其中,d1和d2分别表示一组中的两个标记物所对应的深度值,[u1v1]和[u2v2]分别表示一组中的两个标记物的像素坐标,设两个标记物的三维坐标分别为a和b,则虚拟标记物e的位置由γ=|ae|/|ab|确定,当γ=1/2时,上式可变换为:
s5:利用m个虚拟标记物的图像坐标分别获取m个虚拟标记物的深度值。
s6:利用卡尔曼滤波器对m个虚拟标记物的图像坐标及深度值进行降噪。
s7:将s6中降噪后的m个虚拟标记物的图像坐标及其对应的深度值、通过透视投影逆过程变换至kinect深度相机局部坐标系下的三维空间中,获得m个虚拟标记物的实时三维坐标,完成虚拟标记物的跟踪;
虚拟标记物的实时三维坐标[xyz]的表达式通过下式获得:
[xyd]t=k-1[dudvd]t
其中,k表示kinect深度相机的内参矩阵,[uv]表示z。
本实施方式的标记物采用近红外反光材料,可在近红外图像中根据高亮特征快速提取。根据标记物所在平面,对其深度值进行插值,再将插值结果用于虚拟标记点的图像定位中。最后,通过透视投影逆变换对虚拟标记点进行三维重建,实现对虚拟标记点跟踪。
- 还没有人留言评论。精彩留言会获得点赞!