一种基于隐藏关联网络的多领域文本隐式特征抽取方法与流程
本发明涉及计算机自然语言处理领域,具体涉及一种基于隐藏关联网络的多领域文本隐式特征抽取方法。
背景技术:
随着电子商务、社交网络的兴起,带有用户主观情绪色彩的信息或者短文本,例如微博、商品评论的数量正在高速增长,这些用户产生的信息是宝贵的资源,其中的主观性情感和意见等信息能够帮助人们做出决策,因此挖掘这种带有用户主观情绪文本中所表达的观点吸引了人们大量的研究。其中,越来越多的研究者开始关注更细致的意见挖掘,这些研究挖掘人们对事物某一方面的观点,它们在这些研究中被称为特征层面的观点。
该领域内的研究大多数都是着眼于发现文本中的显式的特征,然而许多情况下特征词是由观点词隐含表达的,比如:“电脑便宜”隐含的是主体——“电脑”的特征——“价格”具有观点——“便宜”,这种不显式出现在文本中的特征被称为隐式特征。针对隐式特征的研究大多只考虑文本中特征词与观点词之间的关联,通过语料中特征词与观点词的同现频率矩阵挖掘它们之间的隐藏关联,利用这种隐藏关联能够在得到观点词的情况下预测可能的隐式特征。
但如今很多文本都是混合领域文本,包含多种领域的内容,比如:政治、生物、经济等等。前人提出的隐式特征识别方法只考虑文本中特征词与观点词之间的关联,没有考虑在多领域文本中的应用,对如今日益增多的混合领域文本不能得到很好的效果。
技术实现要素:
本发明的目的在于克服上述隐式特征识别方法在多领域文本效果不佳的问题,提供一种基于隐藏关联网络进行多领域文本隐式特征抽取的方法。本发明加入主体词作为文本所属领域的先验知识约束,参与隐藏关联网络的构建,考虑了主体-特征-观点三方间的隐藏关联,使得本发明在多领域文本的隐式特征抽取中也能得到很好的应用。
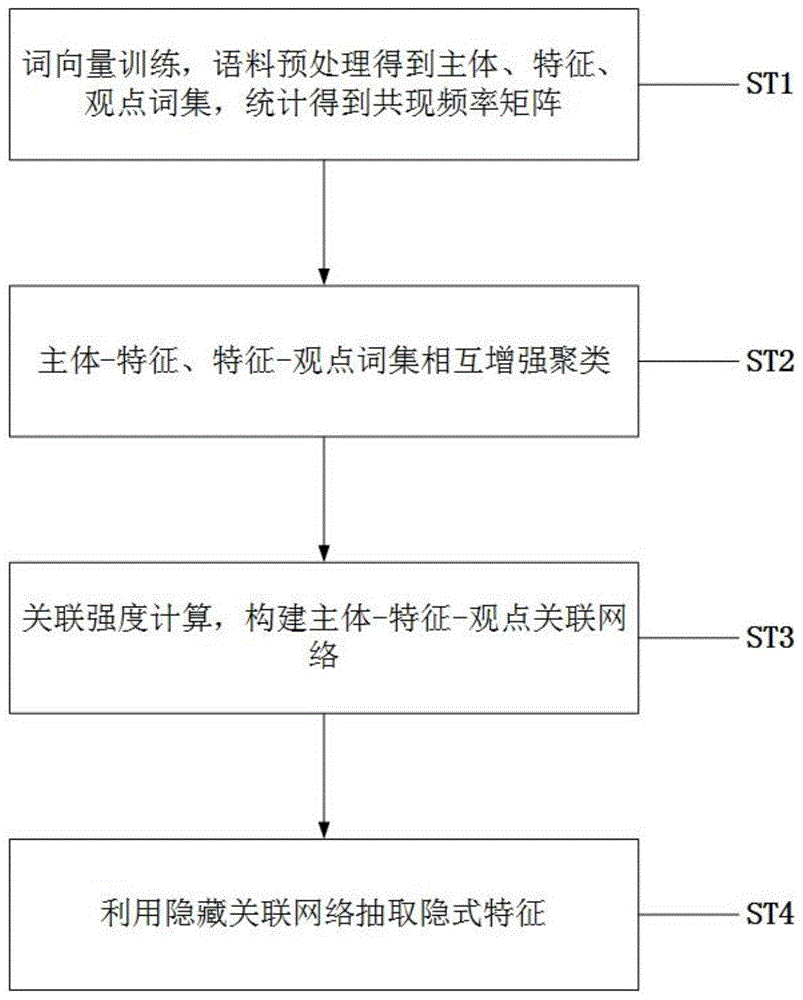
为实现本发明目的,本发明公开了一种基于隐藏关联网络的多领域文本隐式特征抽取方法,包括以下步骤:
步骤1:使用语料进行词向量训练得到语料中每个词的词向量,对语料进行预处理得到主体、特征、观点词集,统计得到词集之间各个词在语料中的同现频率矩阵;
步骤2:根据同现频率矩阵对主体-特征、特征-观点词集之间进行双向增强聚类,然后重新聚类得到每个词集内部的聚类结果;
步骤3:利用同现频率矩阵计算两个词集的类之间的互信息作为类之间的关联强度,构造主体与特征、特征与观点词集之间的二部图,形成主体-特征-观点关联网络;
步骤4:对于需要进行隐式特征抽取的句子,首先得到其中的主体、观点词,然后判断在各自词集中所属类,根据主体-特征-观点关联网络确定可能的隐式特征类,最终从该类中得到最可能的隐式特征词。
所述步骤1中使用语料进行词向量训练得到语料中每个词的词向量,通过对语料进行分句分词、词性标注、依存分析预处理得到每个句子的主体词、特征词、观点词,最终得到语料的主体、特征、观点词集合,同时统计得到主体-特征词集、特征-观点词集之间各个词在语料中的同现频率矩阵。
所述步骤2中首先根据步骤1中训练得到的词向量在三个词集内部进行初步聚类,然后在主体-特征词集、特征-观点词集之间考虑一个词集的每个词与固定的另一个词集内聚类类之间的关联,得到相互关联矩阵,利用词与词之间的关联相似度和内容相似度进行两个词集之间的相互增强聚类,最终收敛得到主体-特征词集、特征-观点词集的聚类结果。利用主体-特征词集相互增强聚类得到的主体词集聚类结果,对特征-观点词集相互增强聚类得到的特征词集聚类结果进行重新聚类,保证最后得到的特征词集聚类结果同时包含主体和观点信息。
聚类时,词之间的相似度度量定义如下:
其中,scontent(wi,wj)表示词wi和词wj之间的内容相似度(词的词向量相似度),srel(wi,wj)表示词wi和词wj之间的关联相似度(关联矩阵中对应的关联向量相似度),
两个词集f和o之间进行双向增强聚类的过程为:
a.只考虑内部相似度,即词向量间的余弦相似度,将集合f中的词聚类成k个类;
b.根据集合f的聚类结果更新集合o的相互关联矩阵m1,
c.根据更新的集合o和集合f之间的相互关联矩阵m1,将集合o中的数据对象聚类成l个类;
d.根据集合o的聚类结果更新集合f的相互关联矩阵m2,
e.根据更新的集合f和集合o之间的相互关联矩阵m2,将集合f中的数据对象重新聚类为k个类;
f.迭代上述步骤b-e,直到两个对象类型的聚类结果收敛。
对特征词集聚类结果进行重新聚类的流程为:对于需要重新聚类的特征词集聚类结果fr,
所述步骤3中根据步骤2中得到的聚类结果,利用同现频率矩阵计算主体-特征、特征-观点词集各个聚类类之间的关联强度,最终构建出主体-特征-观点关联网络。关联强度由两个类之间的pmi表示,定义为:
这里的p(c1)和p(c2)是类c1和类c2中的词语在语料库中出现的频率,p′(c1,c2)是类c1中所有词语和类c2中所有词语,在语料库中的句子层面上的同现频率之和。利用互信息pmi作为类之间的关联强度,关联主体-特征词集、特征-观点词集,构造出主体-特征-观点关联网络。
所述步骤4中利用主体-特征-观点关联网络对句子中可能的隐式特征进行抽取,基本流程是:对于需要进行隐式特征抽取的句子,利用分词、词性标注、依存分析等技术得到句子中的主体词和观点词,考虑与该主体词和观点词属于的的主体类和观点类,根据主体-特征-观点关联网络得到与这两个主体类和观点类加权关联度最高的特征类,最终预测最可能的特征词作为隐式特征。因为考虑了与主体词之间的关联,所以这种隐式特征识别对多领域文本也有较好的效果。
附图说明
图1为本发明的流程示意图;
图2为主体-特征-观点关联网络图;
图3为主体-特征-观点关联网络的构建流程;
图4为利用主体-特征-观点关联网络进行隐式特征识别的示例。
具体实施方式
下面结合附图和实施例对本发明内容作进一步详细说明,但不是对本发明的限定。
参照图1,一种基于隐藏关联网络的多领域文本隐式特征抽取方法,包括以下步骤:
st1:使用语料进行词向量训练得到语料中每个词的词向量,对语料进行预处理得到主体、特征、观点词集,统计得到词集之间各个词在语料中的同现频率矩阵。具体流程如下:
a.对语料进行分句、分词处理得到训练数据,使用训练数据进行词向量训练得到语料中每个词对应的词向量。
b.对语料进行分句、分词、词性标注、依存分析。如果句子中的名词与标注的句子所属主体进行词向量相似度比较,若二者词向量相似度大于阈值t,则该名词作为主体词加入主体词集,否则作为特征词候选,句子中的形容词作为观点词候选。根据依存分析得到的句子依存树,挑选在依存树上被特定关系连接的候选特征词和候选观点词加入特征词集、观点词集,比如观点词和特征词之间常常被关系为“amod”和“nsubj”的边连接,选择这些关系连接的候选特征词和候选观点词进入特征词集、观点词集,最终得到语料的主体、特征、观点词集合。
c.在确定了主体词s的句子中按照上述方法确定特征词f和观点词o,统计出主体词s和特征词f、特征词f和观点词o在语料中的同现频率,遍历语料中所有句子最终得到主体-特征词集、特征-观点词集之间各个词在语料中的同现频率矩阵msf和mfo。
st2:根据st1中统计得到的同现频率矩阵msf和mfo在主体-特征、特征-观点词集之间进行双向增强聚类,然后重新聚类得到每个词集内部的聚类结果。具体
首先根据st1中训练得到的词向量在三个词集内部进行初步聚类,然后在主体-特征词集、特征-观点词集之间使用同现频率矩阵msf和mfo考虑一个词集的每个词与另一个词集内聚类类之间的关联,得到相互关联矩阵。利用词与词之间的关联相似度和内容相似度进行两个词集之间的相互增强聚类,最终收敛得到主体-特征词集、特征-观点词集的双向增强聚类结果。
聚类时,词之间的相似度度量定义如下:
其中,scontent(wi,wj)表示词wi和词wj之间的内容相似度,即词的词向量相似度,srel(wi,wj)表示词wi和词wj之间的关联相似度(关联矩阵中对应的关联向量相似度),
两个词集f和o之间进行相互增强聚类的具体流程为:
a.只考虑内部相似度,即词向量间的余弦相似度,将集合f中的词聚类成k个类;
b.根据集合f的聚类结果更新集合o的相互关联矩阵m1,
c.根据更新的集合o和集合f之间的相互关联矩阵m1,将集合o中的数据对象聚类成l个类;
d.根据集合o的聚类结果更新集合f的相互关联矩阵m2,
e.根据更新的集合f和集合o之间的相互关联矩阵m2,将集合f中的数据对象重新聚类为k个类;
f.迭代上述步骤b-e,直到两个对象类型的聚类结果收敛或相对误差减小到一定程度。
最后利用主体-特征词集相互增强聚类得到的主体词集聚类结果sr,对特征-观点词集相互增强聚类得到的特征词集聚类结果fr进行重新聚类,保证最后得到的特征词集聚类结果ffr同时包含主体和观点信息。重新聚类过程如下:
对于需要重新聚类的特征词集聚类结果fr,即已经被特征-观点词集之间相互增强聚类完成的特征词集,
st3:利用同现频率矩阵计算两个词集的类之间的互信息作为类之间的关联强度,构造主体与特征、特征与观点词集之间的二部图,形成主体-特征-观点关联网络。
主体-特征-观点关联网络参考图2,其中词语被分为三个部分:主体词集、特征词集、观点词集。三个词集通过st2中的聚类得到最终聚类结果,每个词集被聚类为若干个类,图中每个虚线圈定的部分表示一个类,主体-特征词集、特征-观点词集的各个类之间含有关联,类之间的关联在图中使用虚线表示,代表两个类中的词在语料中的句子里共同出现过。
图2中类之间的关联由类之间的虚线表示,本方法利用类之间的点互信息pmi作为类之间的关联强度,pmi的计算公式为:
这里的p(c1)和p(c2)是类c1和类c2中的词语在语料库中出现的频率,p′(c1,c2)是类c1中所有词语和类c2中所有词语,在语料库中的句子层面上的同现频率之和。
参照图3,主体-特征-观点关联网络的具体构造流程如下:
a.仅根据内部相关度,即词向量间的余弦相似度,特征词集f内容聚类成k个类,得到初步聚类后的特征词集f1;
b.根据st2中的相互增强的聚类方法,在特征词集f1与主体词集s之间进行双向增强聚类得到聚类后的主体词集s1,在特征词集f1与观点词集o之间进行双向增强聚类得到聚类后的观点词集o1和特征词集f2;
c.由于f2中某些类中含有多领域的特征,因此需要根据与主体词集s1之间的关联权重矩阵对f2进行重新聚类,重新聚类方法如st2所述,最终得到重新聚类后的特征词集f3;
d.根据从语料中统计得到的主体-特征、特征-观点共现频率矩阵msf和mfo,构造主体词集s1与特征词集f3、特征词集f3与观点词集o1之间类与类的关联强度,关联强度由上述的pmi表示。利用点互信息pmi作为类之间的关联强度,关联主体-特征词集、特征-观点词集,得到三个词集的聚类结果以及关联信息:类的个数、每个类的类中心向量、每个词所属类的标号、类之间的关联强度等,这些信息构成了主体-特征-观点关联网络。
st4:对于需要进行隐式特征抽取的句子,首先得到其中的主体、观点词,然后判断在各自词集中所属类,根据主体-特征-观点关联网络确定可能的隐式特征类,最终从该类中得到最可能的隐式特征词。具体的流程参照图4:
a.对要识别隐式特征的句子进行分词、词性标注和依存分析,将名词作为主体词候选,形容词作为观点词,查询在依存树上存在被特定关系连接的名词和形容词,则判断该名词是否存在于特征词集中,若是特征词则作为显式特征被抽取,否则把该名词当做主体词;
b.判断识别出的主体词和观点词所属的主体类s和观点类o,根据关联网络里存储的主体-特征词集、特征-观点词集各个类之间的关联强度,选择与主体类s和观点类o的平均关联强度最强的特征类s;
c.从特征类s中抽取最可能的词作为隐式特征词,这里我们抽取类中在语料里出现次数最多的词作为隐式特征词w。
一个具体的示例参考图4,以句子“张子枫还很小,但是她的演技已经得到了认可”为例进行隐式特征抽取:
a.对句子“张子枫还很小,但是她的演技已经得到了认可”进行分词、词性标注和依存分析,人名“张子枫”与形容词“小”在依存树上存在指定关系“nsubj”的连接,判断“张子枫”不存在与特征词集中,将“张子枫”作为主体词,形容词“小”作为观点词;
b.根据a中识别出的主体词“张子枫”和观点词“小”,将它们的词向量分别和主体词集的各个类中心向量、观点词集的各个类中心向量计算相似度,选择与其相似度最高的主体类——“人”和观点类——“大小”作为它们所属的类别,根据构建的主体-特征-观点关联网络,选择与主体类——“人”和观点类——“大小”关联强度最高的特征类,这里通过选择与主体类——“人”和观点类——“大小”都存在的关联的特征类,然后计算与两个类的平均关联强度最高的特征类作为最可能的特征类;
c.从b中得到的最可能的特征类中选择最可能的特征词作为预测的隐式特征,这里选择该特征类中在语料里出现频率最高的特征词作为隐式特征词。
- 还没有人留言评论。精彩留言会获得点赞!