一种基于服务端编码的安全阅读方法和系统与流程
本发明属于计算机技术领域,涉及一种阅读方法,尤其涉及一种基于服务端编码的安全阅读方法和系统。
背景技术:
信息化办公给人们的日常工作带来革命性变革,其中应用最为广泛的是基于b/s(browser/server,浏览器/服务器)架构的业务信息系统。
信息时代,信息资源成为最重要的资源之一,往往能决定成败,因此信息安全问题不容忽视。信息化办公在带来便捷的同时也伴随着信息安全隐患。b/s架构的信息系统中,阅读正文或附件的常用模式是将对应文件下载到浏览器进行本地磁盘缓存,然后使用插件将其加载显示。磁盘缓存是可能造成数据信息泄露最突出的安全隐患。
在b/s架构中,解决安全隐患的一种方法是禁止用户端磁盘缓存,改用内存缓存的方式,但实则重要信息已在用户端“落地”,未从根本上消除b/s架构的安全隐患。
因此,一种能从根源杜绝安全隐患的安全阅读方法是目前亟待解决的技术问题。
技术实现要素:
鉴于上述问题,本发明提出了一种基于服务端编码的安全阅读方法和系统,旨在解决由于文件在用户端缓存带来的安全隐患,使用户端只具备文件显示功能,而不对文件进行缓存和编码处理,从根源上杜绝b/s架构带来信息泄露隐患。
本发明的基于服务端编码的安全阅读方法,主要包含以下步骤:
步骤1,用户端的浏览器向服务端发起文件阅读请求,请求中封装用户端浏览器支持的页面编码格式;
步骤2,服务端接收文件阅读请求,根据请求查找文件,将找到的文件根据请求中的编码格式进行编码并将编码文件传输给用户端浏览器;
步骤3,用户端浏览器从服务端接收编码文件并显示;
步骤4,用户端浏览器的阅读页面关闭后,清空所有编码文件。
进一步地,服务端将查找到的文件根据编码格式进行编码的步骤包括:
服务端根据浏览器支持的编码格式,将整个文件编码生成完整的编码文件,并将编码文件存入服务端的磁盘空间中,调用用于记录编码文件信息的功能模块,在服务端分配一块内存空间,用于记录编码文件的信息,在这一步骤中记录编码文件的缓存地址信息;
服务端调用用于对编码文件进行分页的功能模块,对编码文件进行分页,在记录的编码文件信息中,追加记录页码索引信息。
进一步地,所述用于对编码文件进行分页的功能模块,根据编码文件的文件格式匹配相应的文件开始标识符、分页标识符和结束标识符,对编码文件进行检索,将检索到的标识符的磁盘地址排列成一段完整的序列,并以此建立页码索引表。
进一步地,用户端从首页开始阅读,包括以下步骤:
1)服务端将分页完成后的首页内容发送给浏览器;
2)浏览器将收到的编码文件首页加载到用户端内存;浏览器读取编码文件首页并在阅读页面展示;
3)编码文件首页读完后,用户决定是否继续阅读,如果继续阅读,浏览器再次请求服务端,请求中包含下一页页码信息,进入步骤4);如果不继续阅读,直接进入步骤7);
4)服务端接收到请求,根据存储的编码文件的位置信息,查找到完整的编码文件,根据浏览器请求中的页码信息检索页码索引,获取到下一页的内容并发送给浏览器;
5)浏览器接收到服务端返回的页面内容,将之前编码文件内容覆盖掉;
6)如果用户还要继续阅读,浏览器再次请求服务端,请求中包含请求页的页码信息;并返回步骤4);如果不继续阅读,直接进入步骤7);
7)阅读页面关闭;浏览器、服务端启用垃圾回收机制,清理文件缓存。
进一步地,用户端从指定页码开始阅读,包括以下步骤:
1)服务端收到请求中的指定页码,然后检索页码索引,找到指定页码的编码文件内容;
2)服务端将指定页面内容发送给浏览器;
3)浏览器将收到的指定页码编码文件加载到用户端内存;浏览器读取指定页码编码文件并在阅读页面展示;
4)指定页码编码文件读完后,用户决定是否继续阅读,如果继续阅读,浏览器再次请求服务端,请求中包含当前页码的上/下一页页码或者用户通过浏览器控件输入的指定页码,进入步骤1);如果不继续阅读,直接进入步骤5);
5)阅读页面关闭;浏览器、服务端启用垃圾回收机制,清理文件缓存。
一种安全阅读用户端,包括浏览器,所述浏览器包括:
请求模块,用于向服务端发起文件阅读请求;
接收模块,用于从服务端接收所请求的文件的编码文件;所述编码文件是由所述服务端获取浏览器支持的页面编码格式后,查找到浏览器请求的文件并根据编码格式对其进行编码而得到;
显示模块,用于显示从服务端接收的编码文件;
清空模块,用于在阅读页面关闭后,清空所有编码文件缓存。
一种安全阅读服务端,其包括:
接收请求模块,用于从用户端的浏览器接收文件阅读请求,并获取浏览器支持的页面编码格式;
编码模块,用于根据接收的阅读文件请求查找文件,将查找到的文件根据编码格式进行编码并传输给用户端的浏览器;以便用户端的浏览器显示从服务端接收的编码文件,并在阅读页面关闭后清空所有编码文件。
进一步地,所述安全阅读服务端还包括:
编码文件记录模块,用于记录编码文件信息,包括编码文件的位置信息、页码索引;
分页模块,用于对编码文件进行分页,建立页码索引。
一种基于服务端编码的安全阅读系统,其包括上面所述的安全阅读用户端和安全阅读服务器。
本发明的有益效果是:文件在阅读过程中无需下载到用户端进行缓存及编码,用户端实际只具备显示功能,保证文件自始至终“不落地”,从根源上杜绝了b/s架构带来的信息安全隐患。
附图说明
图1是本发明安全阅读方法的步骤流程图;
图2是本发明安全阅读方法实例一的步骤流程图;
图3是本发明安全阅读方法实例二的步骤流程图;
图4是本发明安全阅读系统的分页模块功能示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合实例和附图对本发明进行详细描述。
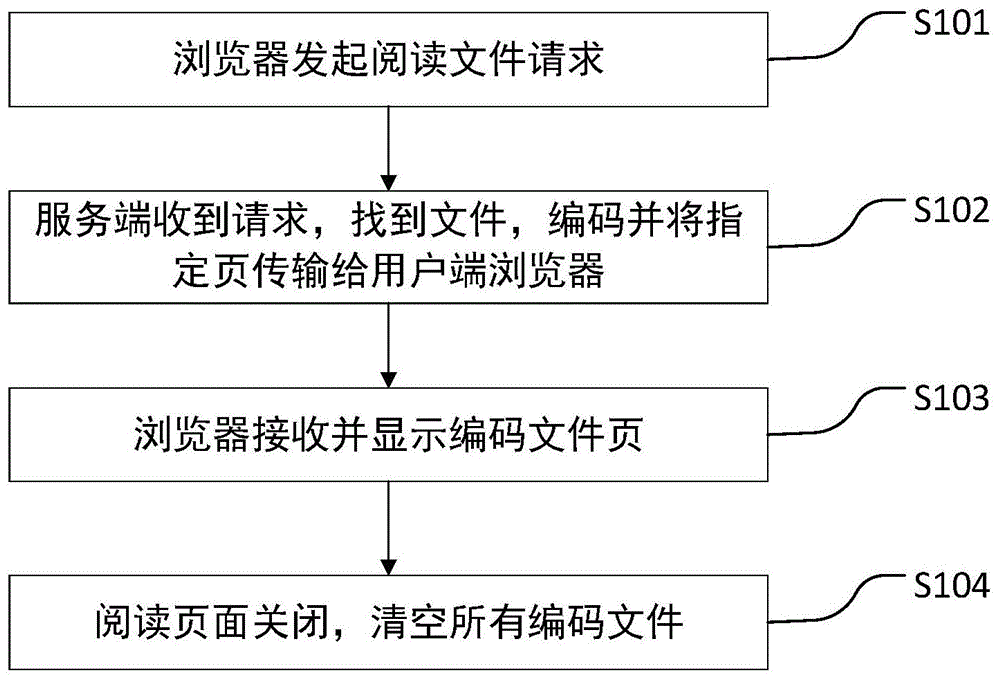
图1是本发明的基于服务端编码的安全阅读方法的步骤流程图,包括以下步骤:
s101用户端浏览器向服务端发起阅读指定文件的请求,请求中包含浏览器支持的页面编码格式;
s102服务端收到请求,查找文件,根据请求中的编码格式对文件进行编码生成编码文件并缓存到服务端磁盘中,记录编码文件的缓存位置,并将指定页的编码文件传输给浏览器;
s103浏览器接收并显示编码文件页;
s104阅读页面关闭;浏览器、服务端启用垃圾回收机制,清除编码文件缓存数据。
图2是本发明的基于服务端编码的安全阅读方法的实例一的步骤流程图。本实例描述用户从首页开始按顺序阅读。包括以下步骤:
s201浏览器向服务端发起阅读某个指定文件的请求,请求中包含浏览器支持的页面编码格式。
s202服务端收到请求,查找到文件;
s203服务端根据浏览器支持的编码格式,将整个文件编码生成完整的编码文件,并将编码文件存入服务端的磁盘空间中,调用用于记录编码文件信息的功能模块(可称为“编码文件记录模块”),在服务端分配一块内存空间,用于记录编码文件信息,在这一步骤中记录编码文件的缓存地址信息。
s204服务端调用用于对编码文件进行分页的功能模块(可称为“分页模块”),在记录的编码文件信息中,追加记录每一页的地址范围,建立页码索引。分页模块根据编码文件的文件格式匹配相应的文件开始标识符、分页标识符和结束标识符,对编码文件进行检索,将检索到的标识符的磁盘地址排列成一段完整的序列,并以此建立页码索引表。如图4所示,将开始标识符的磁盘地址与第一个分页标识符的磁盘地址标为页码1的索引,将第一、第二个分页标识符的磁盘地址标为页码2的索引,以此类推;将页码索引信息追加到编码文件信息中。
s205服务端将分页完成后的首页内容发送给浏览器。
s206浏览器将收到的编码文件首页加载到用户端内存;浏览器读取编码文件首页并在阅读页面展示。
s207编码文件首页读完后,用户决定是否继续阅读,如果继续阅读,浏览器再次请求服务端,请求中包含下一页页码信息,进入步骤s208;如果不继续阅读,直接进入步骤s211;
s208服务端接收到请求,按照请求中的页码检索页码索引,获取到下一页的内容。服务端将获取到的内容发送给浏览器。
s209浏览器接收到服务端返回的页面内容,将之前编码文件内容覆盖掉;
s210如果用户还要继续阅读,浏览器再次请求服务端,请求中包含请求的页码信息;并返回步骤s208;如果不继续阅读,直接进入下一步骤;
s211阅读页面关闭;浏览器、服务端启用垃圾回收机制,清除缓存文件。
图3是本发明的基于服务端编码的安全阅读方法的实例二的步骤流程图。本实例描述用户需要阅读长篇文件并已知需要阅读的文件页码,需要从指定页码开始阅读,阅读过程中需要顺序阅读或者跳转页码;实例二包括以下步骤:
s301用户通过浏览器控件输入指定页码,浏览器向服务端发起阅读某个指定文件的请求,请求中包含浏览器支持的页面编码格式以及用户指定页码;
s302服务端收到请求,查找到文件;
s303服务端根据浏览器支持的编码格式,将整个文件编码生成完整的编码文件,并将编码文件存入服务端的磁盘空间中,调用用于记录编码文件信息的功能模块,在服务端分配一块内存空间,在这一步骤中记录编码文件的缓存位置信息。
s304服务端调用用于对编码文件进行分页的功能模块,对编码文件进行分页,在记录的编码文件信息中,追加页码索引信息。
s305服务端按照请求中的指定页码,检索页码索引,找到指定页码的编码文件地址范围。
s306服务端将文件内容发送给浏览器。
s307浏览器将收到的指定页码编码文件加载到用户端内存;浏览器读取指定页码编码文件并在阅读页面展示;
s308指定页码编码文件读完后,用户决定是否继续阅读,如果继续阅读上/下一页文件内容,浏览器再次请求服务端,请求中包含当前页上/下一页的页码,或者用户通过浏览器控件输入指定页页码封装到阅读请求中,进入步骤s309;如果不继续阅读,直接进入s311步骤;
s309服务端接收到请求,根据存储的编码文件的位置信息,查找到完整的编码文件,根据浏览器请求中的页码信息,获取指定页内容。服务端将获取到的内容发送给浏览器;
s310浏览器接收到服务端返回的页面内容,将之前编码文件内容覆盖掉,并显示页面内容;
s311如果用户还要继续阅读,浏览器再次请求服务端,请求中包含请求的页码信息;并返回步骤s309;如果不继续阅读,直接进入下一步骤;
s312阅读页面关闭;浏览器、服务端启用垃圾回收机制,清理编码文件缓存。
本发明另一实施例提供一种安全阅读用户端,包括浏览器,所述浏览器包括:
请求模块,用于向服务端发起文件阅读请求;
接收模块,用于从服务端接收所请求的文件的编码文件;所述编码文件是由所述服务端获取浏览器支持的页面编码格式后,查找到浏览器请求的文件并根据编码格式对其进行编码而得到;
显示模块,用于显示从服务端接收的编码文件;
清空模块,用于在阅读页面关闭后,清空所有编码文件缓存。
本发明另一实施例提供一种安全阅读服务端,其包括:
接收请求模块,用于从用户端的浏览器接收文件阅读请求,并获取浏览器支持的页面编码格式;
编码模块,用于根据接收的阅读文件请求查找文件,将查找到的文件根据编码格式进行编码并传输给用户端的浏览器;以便用户端的浏览器显示从服务端接收的编码文件,并在阅读页面关闭后清空所有编码文件;
编码文件记录模块,用于记录编码文件信息,包括编码文件的位置信息、页码索引;
分页模块,用于对编码文件进行分页,建立页码索引。
本发明另一实施例提供一种基于服务端编码的安全阅读系统,其包括上面所述的安全阅读用户端和安全阅读服务器。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的原理和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!