基于角度损失函数的行为识别方法与流程
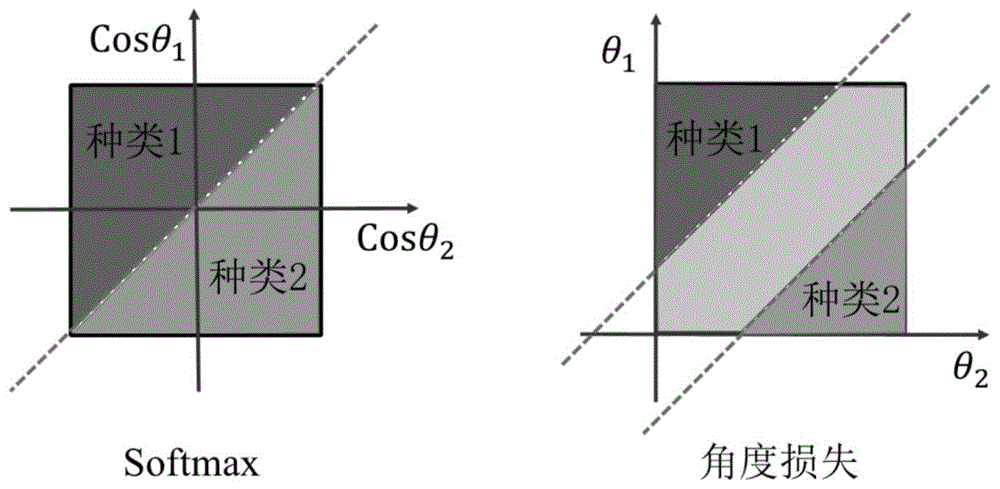
本发明属于视频信号处理与机器学习领域,主要用于视频行为片段分类工作。技术背景人体行为识别是计算机视觉研究的一个热点,要求算法能够从一个未知的视频或者是图像序列中自动分析正在进行的行为。简单的行为识别即动作分类,给定一段视频,只需将其正确分类到已知的几个动作类别;复杂点的识别是视频中不仅仅只包含一个动作类别,而是有多个,系统需自动的识别出动作的类别以及动作的起始时刻。行为识别的最终目标是分析视频中哪些人在什么时刻什么地方干什么事情,在智能视频监控,病人监护系统,人机交互,虚拟现实,基于内容的视频检索和智能图像压缩等方面具有广阔的应用前景和潜在的经济价值和社会价值。目前主流的行为识别是通过训练神经网络完成分类,其实现流程与传统图像识别类似,先使用神经网络进行特征提取,再结合softmax分类函数进行分类。在目前基于深度学习的行为识别算法中,常使用卷积神经网络提取视频的特征x,再使用softmax分类函数对特征进行分类,对于输入特征x,softmax分类函数完成如式(1)所示的操作后输出为f(x)=p=[p1,…,pc],输出向量p中包含c个元素,c表示总的分类类别数目,pi(i=1,2,...,c)表示分类为第i类的概率,w=[w1,...,wc]为权重向量,i表示分类序号,j表示用于累加时的分类序号。训练过程中使用交叉熵损失函数,对输出与标签y进行对比得到如式(2)所示损失,交叉熵与softmax结合的方式又被称作softmax损失函数,式中l(y,p)表示在训练过程中一组大小为n的训练数据x=[x1,...,xn]的损失函数值,y=[y1,...,yn]与p=[f(x1),...,f(xn)]分别表示这组数据的真实标签与预测的概率向量,其中标签yn(n=1,2,...,n)的取值范围是1到c的整数,表示该段视频数据中的真实行为类别的索引值,f(·)表示模型预测的过程。在测试阶段,对于单个测试样本可以得到softmax输出的向量p,p中元素值最大的为pk=maxipi,则可以认为模型将该段视频预测为第k类。为了描述简单,这里以二分类为例,在二分类中,softmax的分类边界如式(3)所示,化简后可得式(4),分类决策边界是一条线。w1,w2为两个分类的权重向量。由于行为本身具有特殊性,具有类内距离远、类间距离近的问题。在式(4)中,二分类情况下的softmax决策面是一条线,如图1所示,可见softmax函数并未对类间间隔进行约束,不能很好的解决行为分类任务中存在的类内间隔大,类间间隔小的问题。技术实现要素:本发明所要解决的技术问题是,提供一种增强不同行为类别之间的区分度,让易混淆的类别能够被正确识别的方法。本发明为解决上述技术问题所采用的技术方案是,基于角度损失函数的行为识别方法,包括以下步骤:1)训练步骤:将训练数据输入行为softmax分类模型进行模型训练,训练过程中使用加入角度约束的softmax损失函数l(y,p),使得类内间隔增大;训练完成后得到每一个分类的类中心;2)分类步骤:2-1)将待分类视频的特征输入训练好的softmax分类模型得到分类向量vsoftmax;同时将待分类视频的特征使用knn聚类算法得到该特征与每一个类中心的距离,并构造一个维度与类中心个数相同的向量vknn,向量vknn每一个维度对应一个类中心,取特征与类中心的距离最小的三个类在向量vknn的对应距离最小的三个类按设置值进行赋值,对其余类的对应位置赋值为0;2-2)将分类向量vsoftmax与向量vknn相加,取相加后值最大的元素所对应的类为最终的行为分类结果。本发明的有益效果是,能够真实的提升行为识别的性能。角度损失函数实现简单,能在基本不增加计算量的同时极大提高分类效果。附图说明图1为带约束的softmax与角度损失函数在二分类情况下的分类边界。图2为金字塔采样过程。具体实施方式下面对角度损失函数进行说明:首先对softmax函数加以约束,约束条件如式(5)所示,即对原权重向量进行二范数归一化:同时对于输入的特征也进行相似的约束,如式(6)所示。||wi||=1fori=1,2,…,c(5)||x||=1(6)根据向量乘法的原则,二分类中softmax分类边界可表示为如式(7)所示,由于w与x需满足上述的约束条件,分界面可以简化为:cosθ1=cosθ2。加上约束的softmax损失函数可表示为式(8)所示。||w1||||x||cosθ1=||w2||||x||cosθ2(7)为了加大分类间隔,在计算损失的时候对标签类的角度加上约束条件后得到如式(9)所示的角度损失函数,式中θ0表示角度区分间隔,控制着不同类别间的区分度。如图1所示,在二分类中角度损失函数的分界面变为cos(θ1+θ0)=cos(θ2),两个分界面有一个明显的间距,在行为识别任务中能将不同的行为更好的进行区分。实施例1.数据预处理对于待分类视频数据v,首先对视频进行时间序列金字塔采样,得到一系列如式(10)所示的采样于该段视频的子视频集vs,式中vm表示第m个子视频。vs={v1,v2,…,vs}(10)下面对采样过程进行详细说明:对于一段包含m帧的视频v,首先将整段视频使用时间轴均匀采样的方式,采样得到16帧的图像序列v′,采样间隔为整个金字塔使用三级结构分别进行采样,采样过程如图2.所示。首先对整段视频使用上述采样过程得到采样子视频v1;在第二级中将视频v均匀切分为两个子视频,分别为v1与v2,然后分别对这两个子视频采样得到新的采样视频v2与v3;在第三级中再分别将v1与v2进一步均分并采样,得到新的采样子视频v4~v7。最终得到的采样子视频集合为vs={v1,v2,…,v7}。2.使用角度损失训练模型对于标记过的视频片段,使用上文所示的预处理得到训练数据集,训练深度学习模型。本文使用三维残差网络(harak,kataokah,satohy.canspatiotemporal3dcnnsretracethehistoryof2dcnnsandimagenet?[c]//proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2018:6546-6555.)来构建深度学习行为识别骨干模型。三维残差模型的输入为16帧分辨率为112×112的图像序列。在训练过程中,首先对数据集中的子视频提取图像帧,然后将图像短边缩放至128后再随机裁剪出分辨率为112×112的图像。将裁剪后的图像序列传入三维残差模型得到2048维的特征向量,使用本文提出的角度损失对模型进行训练。将标签与特征传入角度损失,可以得到对应的损失值,使用该损失函数对模型中的参数求梯度,并使用梯度下降算法对模型参数进行迭代更新。3.计算类别中心对于训练数据中的视频vm,使用训练好的模型提取每段视频的特征fm,然后根据视频的标签将其归类,其中每一类i(i=1,...,c)中只包含视频标签ym=i的视频特征fm,共计ni个,并按照式(11)计算每一类的类中心ci。4.测试过程测试视频使用前文所示的预处理过程得到7段子视频,将其分别送入训练好的模型中提取特征,得到特征集合f=[f1,…,f7],按照式(12)得到测试视频对应的特征并对该特征分别使用softmax与knn聚类算法对其进行处理。根据得到的类别中心使用如式(13)所示的距离函数得到视频特征与每类中心ci的距离di,并按照大小排序得到其中最小的三项,分别记作dn、dm与dp(dn<dm<dp),构建如式(14)所示的一个维度与类别数c相等的向量其中vknn中的元素只有在vn、vm与vp三个位置非0,这三个位置的值分别为:vn=0.5、vm=0.3、vp=0.2。d(x,y)=||x-y||2(13)vknn=[0,…,0,vn,0,…,0,vm,0,…,0,vp,0,…,0](14)同时将softmax函数的输出分类向量vsoftmax与vknn相加并取最大的元素作为最终的分类结果,如式(15)所示,其中argmax(·)表示取向量中最大元素的索引下标。效果展示与总结本文在liunx平台上进行实验,使用ucf101行为识别数据集对行为识别效果进行验证。分别构建了50层与101层的三维残差网络,在ucf101数据集的测试集上的测试效果如表1所示。表1.ucf101数据集上不同损失的分类结果模型种类softmax损失角度损失3d-resnet5089.390.63d-resnet10188.991.0可见相对于通用的softmax损失函数,本文提出的角度损失函数能够真实的提升行为识别的性能。同时本文提出的角度损失函数实现简单,能在基本不增加计算量的同时极大提高分类效果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1