一种自然场景下端到端文本识别方法与流程
本发明涉及一种基于近邻相关性边界优化算法的自然场景下端到端文本识别方法,涉及自然场景下端到端文本识别,特别适用于检测区域边界不精确导致识别失败的问题。
背景技术:
自然场景下的端到端文本识别任务目的为,输入一张包含文本区域的自然场景图片,既要检测出图片位置,也要识别出相应位置文本内容。在端到端文本识别任务中,识别阶段的精确度受检测阶段精确度的影响很高,只有检测阶段精确地框住了文本中所有的字母,识别阶段才能输出精确的识别结果。特别的,现有端到端文本框架对于长文本或大文本区域的边界预测不准确,这给后续的识别任务带来了一定的困难。
现有常用的后处理算法如非极大抑制(non-maximumsuppression,简称nms)算法,或局部感知非极大抑制(locality-awarenms,简称lanms)算法,只能将相邻且交并比大的区域做合并,未对边界的精确性做要求,这就导致了检测过程可能得到不精确的边界,从而影响识别结果。
技术实现要素:
发明目的:目前的端到端文本识别框架中,并未对检测结果的边界精确性做明确要求,现有框架对于长文本、大文本的检测结果通常边界不精确,甚至没有将文本完整框出,这导致了识别结果的不准确。针对上述问题,本发明设计了基于近邻相关性的边界优化算法,发明了采用该算法的端到端文本识别深度学习框架,方法表述了框架结构、框架训练过程、框架测试过程,以此来解决边界预测不精确的问题,提高端到端任务的精度。
技术方案:一种自然场景下端到端文本识别方法,包括基于近邻相关性边界优化算法的端到端文本识别深度学习框架训练,以及利用训练好的框架对自然场景中文本区域及内容进行端到端识别的测试过程。
所述基于近邻相关性边界优化算法的端到端文本识别深度学习框架训练的具体步骤为:
步骤100,输入自然场景图像、真实标记区域、真实标记串至数据处理平台;
步骤101,对输入自然场景图片做预处理,进行随机旋转、采样、正规化等操作;
步骤102,使用真实标记区域生成真实类图与真实几何图以作为训练监督信息;
步骤103,初始化整个框架的共享特征部分、检测部分、识别部分各部分的权重;
步骤104,在数据处理平台上,使用自然场景图像、真实类图、真实几何图、真实标记串,用端到端的方法训练整个框架;其步骤为:自然场景图像首先经过共享特征部分,得到共享特征图;检测部分利用共享特征图生成检测结果;近邻相关性边界优化算法优化检测结果;作用在共享特征图上的双线性插值将检测区域采样得到识别特征;识别部分利用输入的识别特征得到识别结果;
步骤105,输出并保存框架各部分权重至数据处理平台的存储系统。
利用训练好的基于近邻相关性边界优化算法的端到端文本识别深度学习框架,对自然场景中文本区域及内容进行端到端识别的测试,测试具体步骤为:
步骤200,输入自然场景图像至数据处理平台;
步骤201,读取已保存的训练好的框架各部分权重,包括共享特征部分、检测部分、识别部分各部分的权重;
步骤202,自然场景图像首先经过共享特征部分,得到共享特征图;检测部分利用共享特征图生成检测结果;近邻相关性边界优化算法优化检测结果;作用在共享特征图上的双线性插值将检测区域采样得到识别特征;识别部分利用输入的识别特征得到识别结果。
所述的基于近邻相关性边界优化算法的端到端文本识别深度学习框架,其中共享特征部分,采用基于残差神经网络的u型框架提取共享特征;u型框架采用第一编码模块与第一解码模块相继连接的方式获得共享特征;
所述第一编码模块包括多层卷积结构以及相邻层的卷积结构间的下采样结构,所述下采样结构用于对相邻层的卷积结构中的上层卷积结构输出的特征图进行下采样并将下采样的特征图输入相邻卷积结构中的下层卷积结构;
所述第一解码模块包括多层卷积结构以及相邻层的卷积结构间的上采样结构,所述上采样结构用于对相邻层的卷积结构中的下层卷积结构输出的特征图进行上采样并将上采样的特征图输入相邻卷积结构中的上层卷积结构。
所述的检测部分在共享特征上分别采用数次卷积生成预测的类图与几何图。
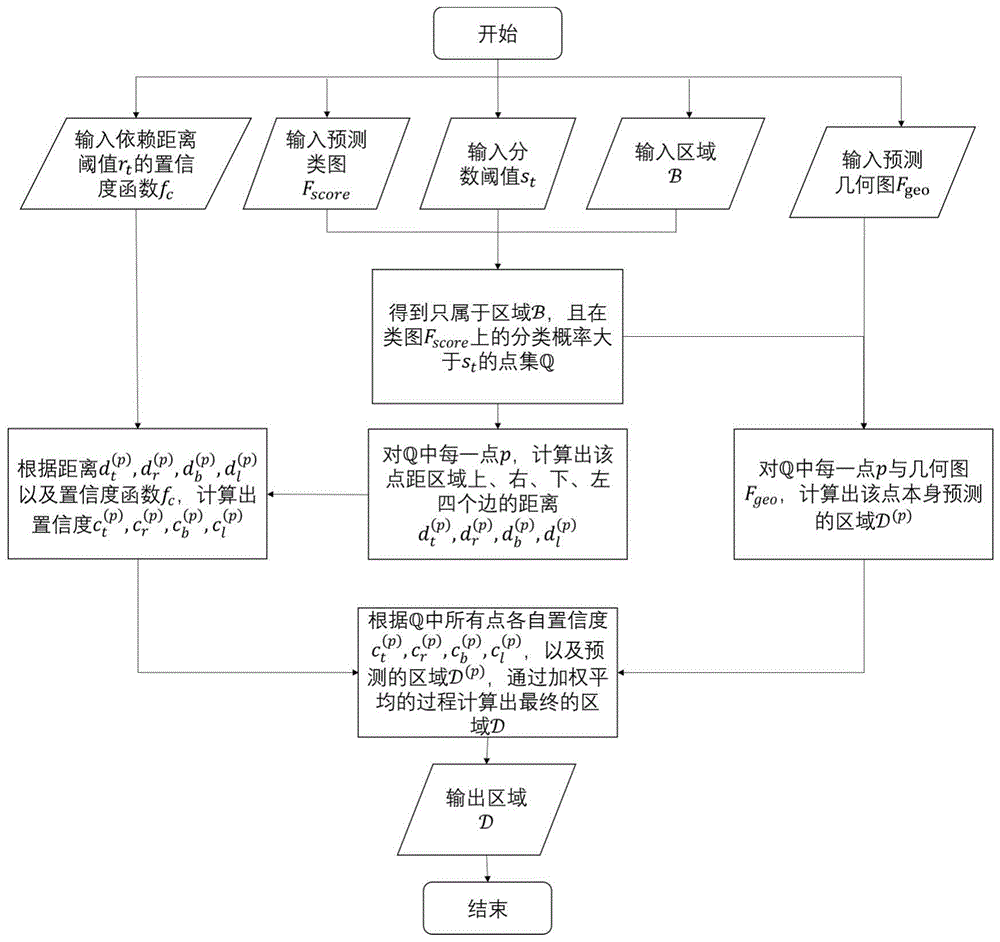
所述的基于近邻相关性的边界优化算法,考虑了特征图上的点对相近。输入为检测部分预测的类图fscore与几何图fgeo,根据类图与几何图得到的单个文本区域
步骤501,对于单个文本区域
步骤502,对
步骤503,根据距离
步骤504,对
步骤505,根据
算法所述的加权平均过程计算最终区域
算法所述的置信度函数fc设计,可采用如下形式:
所述的识别部分采用第二编码模块与第二解码模块相继连接的方式获得预测文本串;其中第二编码模块包括多层卷积结构以及相邻卷积结构间的下采样结构,第二解码模块采用基于长短时记忆神经网络结构。
所述的双线性插值采样部分,针对一个检测结果区域,在共享特征图上找到相应的位置,对其进行双线性插值采样,获得识别特征图。
有益效果:与现有技术相比,本发明提供的基于近邻相关性边界优化算法的端到端文本识别方法,利用到了特征图上点对近邻预测准确的性质,提高了检测结果边界的精度,从而提高了端到端任务的结果。
附图说明
图1为本发明实施的基于近邻相关性边界优化算法的流程图;
图2为本发明设计的基于近邻相关性边界优化算法的端到端文本识别深度学习框架的共享特征层中,第一解码模块以及u型网络示意图;
图3为本发明设计的基于近邻相关性边界优化算法的端到端文本识别深度学习框架训练过程流程图;
图4为具体使用学习算法训练的所述框架的流程图;
图5为本发明设计的基于近邻相关性边界优化算法的端到端文本识别深度学习框架测试过程流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
基于近邻相关性边界优化算法的端到端文本识别深度学习框架,结构分为共享特征部分、检测部分、边界优化算法部分、双线性插值采样部分、识别部分等几个部分。
共享特征部分可采用基于残差神经网络的u型框架提取共享特征;u型框架采用第一编码模块与第一解码模块相继连接的方式获得共享特征;第一编码模块包括多层卷积结构以及相邻层的卷积结构间的下采样结构,下采样结构用于对相邻层的卷积结构中的上层卷积结构输出的特征图进行下采样并将下采样的特征图输入相邻卷积结构中的下层卷积结构;第一解码模块包括多层卷积结构以及相邻层的卷积结构间的上采样结构,上采样结构用于对相邻层的卷积结构中的下层卷积结构输出的特征图进行上采样并将上采样的特征图输入相邻卷积结构中的上层卷积结构。
检测部分在共享特征上分别采用数次卷积生成预测的类图与几何图。
基于近邻相关性的边界优化算法核心思想在于,对某边界的预测,只取该边界附近的点作为置信度高的点做加权平均。流程如图1所示。输入为检测部分预测的类图fscore与几何图fgeo,根据类图与几何图得到的单个文本区域
对于单个文本区域
对
根据距离
对
根据
其中加权平均过程计算最终区域
置信度函数fc设计,可采用如下形式:
阈值参数可根据实际问题选取,例如可取st=0.7,rt=0.01。
识别部分采用第二编码模块与第二解码模块相继连接的方式获得预测文本串;其中第二编码模块包括多层卷积结构以及相邻卷积结构间的下采样结构,第二解码模块采用基于长短时记忆神经网络结构。
双线性插值采样部分,针对一个检测结果区域,在共享特征图上找到相应的位置,对其进行双线性插值采样,获得识别特征图。
表1为基于近邻相关性边界优化算法的端到端文本识别深度学习框架共享卷积层的第一编码模块,模块由一系列的多层卷积结构以及相邻层的卷积结构间的下采样结构组成:图中输出大小为特征图在空间尺度的大小;[n×n,m]代表当前卷积核的卷积核大小为[n×n],通道数为m;层2、3、4、5的残差卷积块会各自重复3次。
表1
图2为基于近邻相关性边界优化算法的端到端文本识别深度学习框架共享卷积层第一解码模块及u型网络,解码模块包括多层卷积结构以及相邻层的卷积结构间的上采样结构,u型网络采用第一编码模块与第一解码模块相继连接的方式获得共享特征:图中u型网络的左侧为第一编码模块,右侧为第一解码模块,conv、concat、upsampling分别代表卷积、通道连接、上采样的过程。
表2为基于近邻相关性边界优化算法的端到端文本识别深度学习框架识别部分的第二编码模块,模块由一系列的多层卷积结构以及相邻层的卷积结构间的下采样结构组成:图中input、conv、pool层分别代表输入层、卷积层、池化层。
表2
基于近邻相关性边界优化算法的端到端文本识别深度学习框架识别部分的第二解码模块可采用基于双向长短时记忆神经网络结构,以此输入识别特征从而得到预测串。
图3为基于近邻相关性边界优化算法的端到端文本识别深度学习框架训练过程的流程图,训练过程描述如下:在训练开始时,框架首先初始化共享特征部分、检测部分、识别部分三部分的参数(权重);输入一系列对应的自然场景图片、真实区域位置、真实文本串至数据处理平台后,对输入自然场景图片做预处理,进行随机旋转、采样、正规化等操作;根据真实区域位置生成真实类图与真实几何图;共享特征层根据输入的自然场景图片获得共享特征;共享特征经过检测部分,得到预测类图与预测几何图,据此得到检测区域;边界优化算法作用在检测区域上,得到边界优化后的检测区域;根据边界优化后的检测区域,双线性插值采样作用在共享特征上,得到识别特征;识别特征经过识别部分,得到预测文本串;预测类图与真实类图、预测几何图与真实几何图、预测文本串与真实文本串分别计算损失,回传梯度并更新参数;如上训练直到达到终止条件(如更新轮数大于阈值)训练结束;存储训练好的参数;结束。
图4为具体使用学习算法训练所述框架流程图。步骤如下:训练开始时初始化所述框架各部分参数;输入自然场景图片、真实区域位置、真实文本串;框架根据真实区域位置生成真实类图、真实几何图;框架处理自然场景图片,生成预测类图、预测几何图与预测文本串;框架使用交叉熵损失函数衡量真实类图与预测类图之间损失、使用交并比损失函数以及余弦损失函数衡量真实几何图与预测几何图之间损失、使用ctc损失函数衡量真实文本串与预测文本串之间损失;框架计算整体损失;通过反向传播算法回传梯度;框架使用sgd算法更新各部分参数;如达到终止条件(如更新轮数大于阈值),则存储参数结束;若未达到,则输入新的自然场景图片、真实区域位置、真实文本串,开始新一轮的训练。
图5为基于近邻相关性边界优化算法的端到端文本识别深度学习框架测试过程流程图,测试过程描述如下:测试开始时,数据处理平台读取已训练好的各部分参数初始化框架;读取待测试的图片;图片经由共享特征层后,得到共享特征;共享特征经由检测部分,得到预测类图与预测几何图,据此得到检测区域;边界优化算法作用在检测区域之上,得到边界优化后的检测区域,即预测区域;根据预测区域,双线性插值采样作用在共享特征上,得到识别特征;识别特征经由识别部分,得到预测文本串;最后输出预测区域及预测文本串,端到端文本识别任务结束。
- 还没有人留言评论。精彩留言会获得点赞!