一种基于层级BERT神经网络的粗粒度情感分析方法与流程
本发明属于web挖掘和智能信息处理技术领域,涉及一种基于层级bert(基于变换器的双向编码表示,全称bidirectionalencoderrepresentationfromtransformers)神经网络的粗粒度情感分析方法。
背景技术:
粗粒度的文本情感挖掘,简称为粗粒度情感分析。粗粒度情感分析旨在于对评论文本进行情感极性的类别判别。情感极性包括褒义、贬义和中性三种类别。评论文本分为篇章级评论文本和句子级评论文本。
目前,粗粒度情感分析方法主要包括基于规则和统计融合的方法、基于机器学习的方法,以及基于深度学习的方法。
基于规则和统计融合的粗粒度情感分析方法是指通过规则分析与统计方法相融合的策略来进行粗粒度情感分析。例如,闫晓东等在文献《基于情感词典的藏语文本句子情感分类》(中文信息学报,2018)中,首先,人工构建了极性词典,极性词典包括程度副词词典、转折词词典、否定词词典等;然后,构建由极性词与修饰词构成的极性短语;最后,基于极性短语及其极性强度判别句子情感极性。
基于机器学习的方法是指采用决策树、支持向量机和条件随机场等分类器进行粗粒度情感分析。例如,王义真等在文献《基于svm的高维混合特征短文本情感分类》(计算机技术与发展,2018)中,首先,抽取了表情符号特征、词聚类特征、词性标注特征和否定特征等六种情感分类特征;然后,采用支持向量机svm(全称supportvectormachine)进行短文本的情感分类。
基于深度学习的方法是指通过深度神经网络模型进行粗粒度情感分析。例如,liao等在文献《perspectivelevelmicroblogsentimentclassificationbasedonconvolutionalmemorynetwork》(patternrecognitionartificialintelligence,2018)中,通过卷积运算扩展上下文词序进行注意力建模,设计了一种基于卷积神经网络的视角层次的微博情感分类方法。
现有的粗粒度情感分析方法主要存在如下问题:第一,粗粒度情感分析方法在进行文本情感极性分类时,主要采用word2vec等传统语言模型进行词、句子等文本向量模型的训练。传统语言模型多为浅层单向神经网络,难以深度描述或反映文本的语义信息。第二,现有粗粒度情感分析方法在生成文本向量表示时缺乏对文本语义信息深层次的挖掘,并且缺乏对分类数据类别不均衡问题的优化处理。
技术实现要素:
本发明的目的是为了解决粗粒度情感分析中存在的上述问题,提供一种基于层级bert神经网络的粗粒度情感分析方法。
本方法的特点是:(1)本发明将粗粒度情感分析任务转换为文本分类任务,采用层级bert神经网络模型生成文本的分布式表示,然后通过softmax方法进行句子级文本的情感极性分类。层级bert神经网络模型包括bert模型与层级神经网络模型。(2)本发明基于两种粒度的文本向量计算生成文本的分布式表示。两种粒度的文本向量包括从句级向量和句子级向量。句子级向量由从句级向量通过双向长短期记忆网络、多层感知机以及注意力机制计算生成。注意力机制使得在基于从句级向量生成句子级向量时,对不同从句进行了差异化处理,突出了构成句子级向量表示起关键作用的从句级向量。(3)本发明引入梯度协调机制以处理粗粒度情感分析数据不同类别样本数量不均衡的问题,提高了情感极性类别识别的准确性。
本发明的目的是通过以下技术方案实现的。
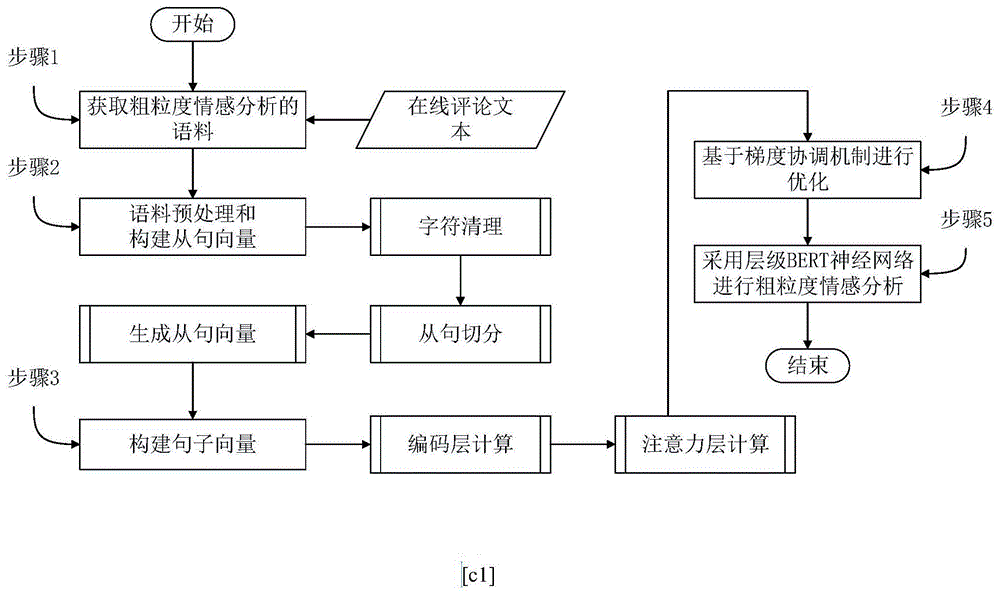
一种基于层级bert神经网络的粗粒度情感分析方法,包括如下步骤:
步骤1,获取粗粒度情感分析的语料
作为优选,语料的获取通过以下过程完成:采集互联网评论网站文本信息,构建为粗粒度情感分析的语料;或采集现有的根据评论网站信息构建的评论文本数据集,作为粗粒度情感分析的语料。
步骤2,语料预处理构建从句向量
本步骤主要工作为对步骤1所获取的语料进行无用字符清理、基于修辞结构理论的从句切分工作以及从句向量的构建。
步骤3,构建句子向量
本步骤主要工作为对步骤2所构建的从句向量采用双向长短期记忆网络、多层感知机以及注意力机制计算生成表示原始句子的句向量,具体过程如下:
步骤3.1,对于步骤2生成的从句向量,进入编码层进行从句向量的编码计算。编码层包括双向长短期记忆网络和多层感知机。
步骤3.2,对于步骤3.1生成的从句向量,进入注意力层进行计算,生成句向量。通过注意力层区分不同从句对生成句向量的权重,以突出重要从句对生成句向量的贡献度。
步骤4,基于梯度协调机制优化的情感极性识别
本步骤主要工作为对步骤3生成的句向量v利用softmax进行计算,并通过基于交叉熵损失函数设计的梯度协调机制,从梯度计算的角度对类别不均衡问题进行优化处理。
步骤5,采用层级bert网络进行粗粒度情感分析
使用步骤4生成的粗粒度情感分析模型对输入语料在经步骤2、3处理后的句子向量进行情感极性识别。
至此,就完成了本方法的全部过程。
本发明的有益效果:
本发明的方法,针对粗粒度情感分析的情感极性识别问题,提供一种基于层级bert神经网络的粗粒度情感分析方法。
(1)本发明采用一种基于层级bert模型的句向量生成方法。首先,通过将评论文本切分为从句级文本,并利用bert模型将其转换为包含深度语义信息的从句级文本向量;其次,采用双向长短期记忆网络(bidirectionallongshort-termmemorynetwork,简称bi-lstm)和多层感知机(multi-layerperception,简称mlp)对从句级文本向量进行语义编码计算;最后,通过对从句编码向量进行注意力机制计算,在区分不同从句对句子向量生成的不同贡献度的基础上,计算生成包含更丰富语义信息的句级向量,作为原始句子的分布式表示进行情感极性的识别计算,提高了粗粒度情感分析的准确性。
(2)本发明采取梯度协调机制进行类别不均衡问题的优化。基于交叉熵损失函数设计的梯度协调机制可以从梯度计算的角度对类别不均衡问题进行优化处理。通过引入梯度协调机制,在层级bert神经网络的基础上对情感极性类别识别问题的准确性进行了优化提高。
本发明提供的方法在舆情监控、主题检测、信息推荐和电子商务等领域具有广阔的应用前景。
附图说明
图1为本发明实施例一种基于层级bert神经网络的粗粒度情感分析方法的流程示意图。
具体实施方式
下面结合附图和实施例对本发明进行详细的说明。
实施例1
基于本发明方法的粗粒度情感分析方法,以ubuntu16.04操作系统为开发平台,开发语言选择thedebianalmquistshell(dash)与python2.7,深度学习开发框架为tensorflow1.9。如图1所示为一种基于层级bert神经网络的粗粒度情感分析方法,包含如下步骤:
步骤1,获取粗粒度情感分析的语料
作为优选,语料的获取通过以下过程完成:采集互联网评论网站文本信息,构建为粗粒度情感分析的语料;或采集现有的根据评论网站信息构建的评论文本数据集,作为粗粒度情感分析的语料。可以采集点评网站yelp数据,yelp包括了餐馆等场景下的用户评论,对于获取的数据采取json的格式保存到本地计算机。
步骤2,语料预处理构建从句向量
语料预处理包括字符清理、从句切分,以及从句向量构建。
首先,对语料中的句子进行字符清理,包括过滤无用标点符号以及乱码字符。停用标点符号包括{,,.,:,;,’,~,`,!,@,#,$,&,*,(,),”}。例如,对于句子“thefoodisgreatandtastyandthe#hotdogsareespeciallytopnotch:)”包含着无用的字符,如“#”和表情“:)”,需要在字符清理中进行过滤。经过字符清理完成的句子为“thefoodisgreatandtastyandthehotdogsareespeciallytopnotch”。
其次,对语料中的句子采用修辞结构理论进行从句切分。从句切分是指将句子切分为从句的序列。采用修辞结构理论(rhetoricalstructuretheory,简称rst)基于文本局部之间关系对句子进行从句切分。
对于上例中完成字符清理的句子“thefoodisgreatandtastyandthehotdogsareespeciallytopnotch”进行从句切分,从句切分的结果为“thefoodisgreatandtasty”,“andthehotdogsareespeciallytopnotch”。
然后,采用bert模型构建从句向量。根据情感分析语料对bert模型进行再训练。bert模型是上下文有关的双向语言模型。本发明基于完成预训练的bert模型,利用情感分析语料库对模型进行再训练,生成满足粗粒度情感分析需求的bert模型。进一步,通过再训练的bert模型构建从句向量。
步骤3,构建句子向量
构建句向量是指采用双向长短期记忆网络、多层感知机以及注意力机制对从句向量进行计算生成句子向量。本实施例采用如下过程实现:
步骤3.1,对于步骤2生成的从句向量,进入编码层进行计算。编码层包括双向长短期记忆网络(bidirectionallongshort-termmemorynetwork,简称bi-lstm)和多层感知机(multi-layerperception,简称mlp)。
首先,对于句子s及其通过步骤2生成的k个从句向量,采用双向长短期记忆网络对从句进行编码计算。将第i个从句经过双向长短期记忆网络的编码计算生成的向量表示为hi。
然后,对由经过bi-lstm编码计算生成的向量hi采用多层感知机进行进一步编码计算。将hi经过多层感知机的编码计算生成的向量表示为ui,下面式子给出了ui的计算方法,其中ws和bs为权重,通过模型训练产生,tanh表示作为激活函数的反双曲正切函数。
ui=tanh(ws×hi+bs)
步骤3.2,对于步骤3.1生成的从句向量,进入注意力层进行计算,生成句向量。通过注意力层区分不同从句对生成句向量的权重,以突出重要从句对生成句向量的贡献度。
注意力层的计算步骤包括:
首先,对于第i个从句经编码层编码计算生成的向量ui,采取注意力机制计算向量ui的权重。注意力机制旨在于度量每个从句在生成句向量中的重要程度。对于k个从句,设每个从句的注意力权重为ai,ai计算公式如下式所示,其中,us为权重,通过模型训练产生,
然后,根据注意力权重ai(1≤i≤k),生成句子s的句向量v,句向量v的计算方法如下式所示。
步骤4,基于梯度协调机制优化的情感极性识别
对于句子s的句向量v,计算情感极性类别的概率p=softmax(wcv+bc),其中wc和bc为权重。对于句子s经过步骤3生成的句向量进行softmax计算,生成对于褒义、贬义和中性三个类别的概率p1,p2,p3,选取最大概率对应的极性类别为句子的粗粒度情感分析结果。
针对情感极性类别识别问题中的数据类别不均衡问题,本发明采取基于交叉熵损失函数设计的梯度协调机制从梯度计算的角度对类别不均衡问题进行优化处理。通过引入梯度协调机制,在层级bert神经网络的基础上对情感极性类别识别问题的准确性进行优化提升。
步骤5,采用层级bert网络进行粗粒度情感分析
经过步骤1-4完成了对基于层级bert神经网络的粗粒度情感分析模型的训练,然后利用经过训练的模型对句子进行粗粒度情感分析,输出句子的粗粒度情感分析结果。
对于句子s,通过基于层级bert神经网络模型的粗粒度情感分析结果为,判别出句子s的唯一情感极性标签l。具体来说,对于每一个句子,设由t个词组成,记为s={wi1,wi2,wi3,…,wit},其中wij表示构成s的词语。通过本发明所提出的基于层级bert神经网络的粗粒度情感分析模型,进行计算,判别出句子对应的唯一情感极性类别标签l,l∈{褒义,中性,贬义}。例如,针对用户评论s=“ireallylovethefondantauchocolat!”,通过基于层级bert神经网络模型进行粗粒度情感分析的结果为褒义,即这是一条褒义的评论文本。
为说明本发明的粗粒度情感分析效果,本实验是在同等条件下,以相同的训练集和测试集分别采用基于支持向量机、基于lstm-grnn模型,以及基于本发明的基于层级bert神经网络模型的粗粒度情感分析方法进行粗粒度情感分析。lstm-grnn为利用lstm(longshorttermmemory,简称lstm)计算句向量,并利用门控递归神经网络(gatedrecurrentneuralnetwork,简称grnn)进行句向量分类的方法。采用accuracy(准确率)作为评测指标对识别效果进行度量。
其中tp代表模型预测为真且用例真值为真,即正确接受;fn代表模型预测为假但用例真值为真,即错误拒绝;fp代表模型预测为真但用例真值为假,即错误接受;tn代表模型预测为假且用例真值为假,即正确拒绝。基于本发明方法的粗粒度情感分析的效果如下:基于支持向量机的粗粒度情感分析方法的准确率约为61.8%,基于lstm-grnn的粗粒度情感分析方法的准确率约为67.1%,本发明提出的基于层级bert神经网络模型的粗粒度情感分析方法的准确率约为75.41%。本发明通过层级bert神经网络对评论文本进行包含深层语义信息的句子向量的构建,提高了粗粒度情感分析任务的准确性,在信息推荐、舆情监控等领域具有广阔的应用前景。
为了说明本发明的内容及实施方式,本说明书给出了具体实施例。在实施例中引入细节的目的不是限制权利要求书的范围,而是帮助理解本发明所述方法。本领域的技术人员应理解:在不脱离本发明及其所附权利要求的精神和范围内,对最佳实施例步骤的各种修改、变化或替换都是可能的。因此,本发明不应局限于最佳实施例及附图所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!