一种基于加权稀疏表示分类的手写汉字识别方法与流程
本发明涉及光学字符识别技术,特别涉及一种手写汉字的自动识别方法。
背景技术:
ocr(光学字符识别opticalcharacterrecognition)是指利用电子设备(例如扫描仪或数码相机)获取纸上的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。ocr技术广泛应用于录入和处理银行票据、文字资料、档案卷宗、文案等,可代替人的手工录入,节省大量人力。通常以最终识别率、识别速度作为评测ocr技术的重要依据。如何除错或利用辅助信息提高识别正确率,是ocr最重要的课题。
手写汉字识别技术属于ocr领域。显然识别手写汉字要把识别手写英文难上很多。第一,英文字符的分类少,总共62个字符(26个英文字母的大小写再加十个阿拉伯数字),而中文总共50,000多汉字,常用的就有3000多;第二,相同的汉字有多种字体,不同字体的书写方式有较大区别;第三每个人的书写风格也各不相同,实际的书写效果不利于机器识别。因此在过去的几十年中人们采用了许多办法去改进识别的精确度和稳定性。
近年来,受压缩感知理论影响,人们将稀疏表示引入模式识别问题中,提出了稀疏表示分类算法(sparserepresentation-basedclassification,src),如今该算法已广泛应用于图形的分类识别。在手写汉字识别过程中,有的学者在学习字典的同时进行分类器训练,然后用得到的分类器对图像稀疏编码进行分类。也有学者,在获得多个指定类字典的前提下,根据测试样本在不同类字典下的重构误差进行分类,取得了比较好的分类效果。但是现有技术中,通过稀疏表示分类器识别手写汉字时,由于未能考虑到样本局部性,即没有考虑到测试样本和每一个训练样本之间有相似性的特点,影响了识别精度。
技术实现要素:
本发明的目的是提供一种基于加权稀疏表示分类的手写汉字识别方法,通过该方法能够快速识别手写汉字,并提高识别的准确率。
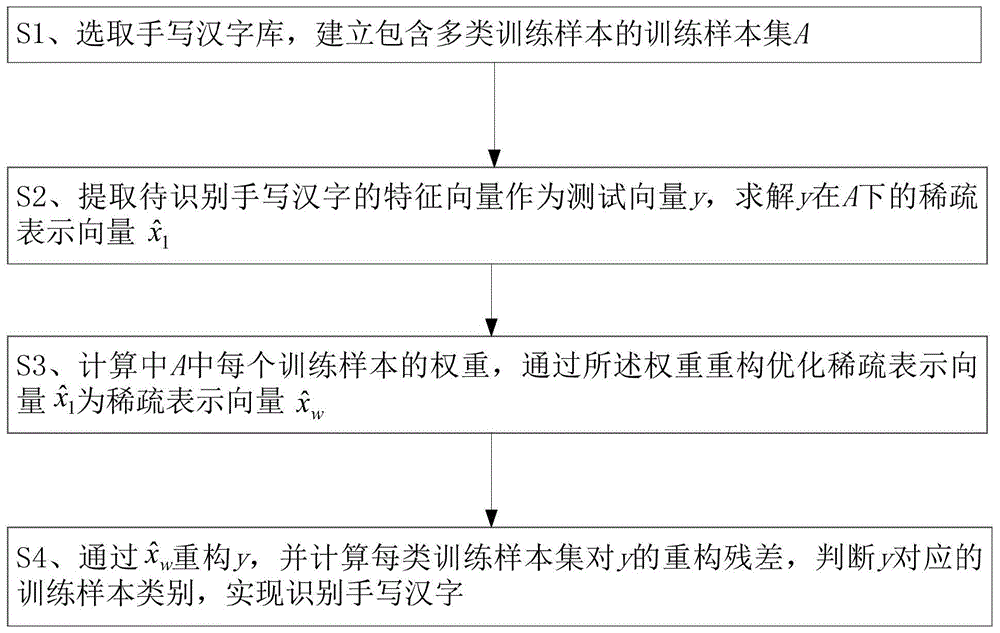
为了达到上述目的,本发明提供一种基于加权稀疏表示分类的手写汉字识别方法,包含步骤:
s1、选取手写汉字库,提取所述手写汉字库中所有汉字的特征向量并分类,建立训练样本集a=[ai]i∈[1,k];
其中ai为a中的第i类训练样本,也即是从手写汉字库中提取的第i类特征向量,i∈[1,k];k为从手写汉字库中提取的特征向量类别总数;一类特征向量作为一类训练样本;
s2、通过提取待识别手写汉字的特征向量y,将y作为测试样本;其中y∈rm×1,m为y的维数;求解y在a下的稀疏表示向量
s3、计算a中每个训练样本的权重,通过所述权重重构优化稀疏表示向量
s4、计算ai对y的重构残差ri(y),根据ri(y)判断y对应的训练样本类别,实现识别手写汉字。
所述步骤s2中,
其中ε为误差的容限度,||·||1表示求l1范数,||·||2表示求l2范数,x0为满足||y-ax0||2≤ε的解。
所述步骤s3中,具体包含:
s31、计算测试样本y到训练样本vi,j的欧氏距离,d(y,vi,j)=||y-vi,j||2s,其中i∈[1,k],j∈[1,ni],s为幂指数;
s32、计算训练样本vi,j的权重值
s33、通过wi,j生成权重对角矩阵w′,其中
s34、重构稀疏表示向量
所述步骤s4中,具体包含:
s41、计算ai对y的重构残差ri(y):
其中i∈[1,k],
s42、若rp(y)=min{r1(y),...,rk(y)},p∈[1,k],则判断y属于第p类训练样本,实现识别手写汉字。
所述手写汉字库为中科院自动化所提供的脱机手写汉字样本库casia-hwdb1.0。
所述步骤s1和s2中通过lbp图像检测算法提取手写汉字库和待识别手写汉字的特征向量。
与现有技术相比,本发明的基于加权稀疏表示分类的手写汉字识别方法,首先计算出测试样本对于训练样本的稀疏表示向量,其次利用训练样本与测试样本之间的欧式距离设定权重的对角矩阵,重构原有的稀疏表示向量。提高了手写汉字的识别精度,获得了更好的识别效果。并且本发明中,通过e的负指数函数来构造权重的对角矩阵,极大地简化了权重的对角矩阵,加快了重构原有稀疏表示向量的速度,提高了对手写汉字的识别速度。
附图说明
为了更清楚地说明本发明技术方案,下面将对描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一个实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图:
图1为本发明的基于加权稀疏表示分类的手写汉字识别方法步骤示意图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供一种基于加权稀疏表示分类的手写汉字识别方法,包含步骤:
s1、选取手写汉字库,通过lbp图像检测算法提取所述手写汉字库中所有汉字的特征向量并分类,建立训练样本集a=[ai]i∈[1,k];所述手写汉字库为中科院自动化所提供的脱机手写汉字样本库casia-hwdb1.0。
其中ai为a中的第i类训练样本,也即是从手写汉字库中提取的第i类特征向量,i∈[1,k];k为从手写汉字库中提取的特征向量类别总数;一类特征向量作为一类训练样本;
s2、通过lbp图像检测算法提取待识别手写汉字的特征向量y,将y作为测试样本;其中y∈rm×1,m为y的维数;通过l1范数求解y在a下的稀疏表示向量
其中ε为误差的容限度,||·||1表示求l1范数,||·||2表示求l2范数,x0为满足||y-ax0||2≤ε的解。
采用l1范数求解y在a下的稀疏表示向量的原因如下所示:
理想状态中y可使用训练样本a中的某一类训练样本ai线性表出,且y与其他类比的训练样本线性无关。既可以将y表示为
其中αi,j∈r,j∈[1,ni];
也可通过所有k个种类的训练样本来表示y:
y=ax0∈rm(3)
在理想的条件下,
但是
公式(5)中我们所求的是l0范数,也就是向量里非零元素的个数。向量越稀疏,那么对后续的分类识别就会越有利。但由于l0范数很难优化求解(np难问题),而l1范数是l0范数的最优凸近似,所以l0范数最小化问题便可转求解l1范数下y=ax0的解
由于现实问题中图像容易受到噪声影响,所以常常设置误差的容限度ε,因此将公式(6)调整为公式(1)。
s3、计算a中每个训练样本的权重,通过所述权重重构优化稀疏表示向量
s31、计算测试样本y到训练样本vi,j的欧氏距离:
d(y,vi,j)=||y-vi,j||2s(7)
其中i∈[1,k],j∈[1,ni],s为幂指数;s可根据实际的训练样本来设置;
s32、计算训练样本vi,j的权重
其中
s33、通过wi,j生成权重对角矩阵w′,
diag(·)为对角矩阵构造函数;其中
s34、重构稀疏表示向量
s4、计算ai对y的重构残差ri(y),i∈[1,k]
在本应用实施例中,
则
各类别训练样本对测试样本的重构残差可以来展现测试样本和各类别中的训练样本的逼近程度。重构残差计算结果越小,就说明这类训练样本在测试样本的重构工作中贡献越大,所以最终测试样本将判定为重构贡献最大的那个类别,即重构残差最小的那个类别。
因此若rp(y)=min{r1(y),...,rk(y)},p∈[1,k],则判断y属于第p类训练样本,实现识别手写汉字。
所述步骤s1和s3中通过lbp图像检测算法提取手写汉字库和待识别手写汉字的特征向量。
以下是本发明的方法在hwdb1.0手写汉字库中与现有技术中的pca(principalcomponentanalysis,主成分分析)、lda(lineardiscriminantanalysis,线性判别分析)方法的对比。很明显,与现有技术相比,本发明的方法对于手写汉字的识别率更高。在每类训练样本个数为8时,本发明的方法识别手写汉字的最大识别率可以达到93.7%,即使在每类2个训练样本时,本发明的识别率也达到了77.3%。本发明的方法对于手写汉字具有很好的识别效果。
表1
与现有技术相比,本发明的基于加权稀疏表示分类的手写汉字识别方法,首先计算出测试样本对于训练样本的稀疏表示向量,其次利用训练样本与测试样本之间的欧式距离设定权重,重构原有的稀疏表示向量。提高了手写汉字的识别精度,获得了更好的识别效果。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!