一种面向流水线结构化数据查询的数据库智能分区方法与流程
本发明涉及分布式数据库下基于机器学习的有利于pipeline执行的存储引擎存储节点之间数据partition策略技术领域,具体涉及一种面向流水线结构化数据查询的数据库智能分区方法。
背景技术:
分布式数据库中,在查询引擎物理计划优化阶段已划分好pipeline的基础上,一个pipeline对应一个执行节点,每一个执行节点所需的数据都会广播地从除该执行节点所在的存储引擎节点之外的其它所有存储节点获取数据。
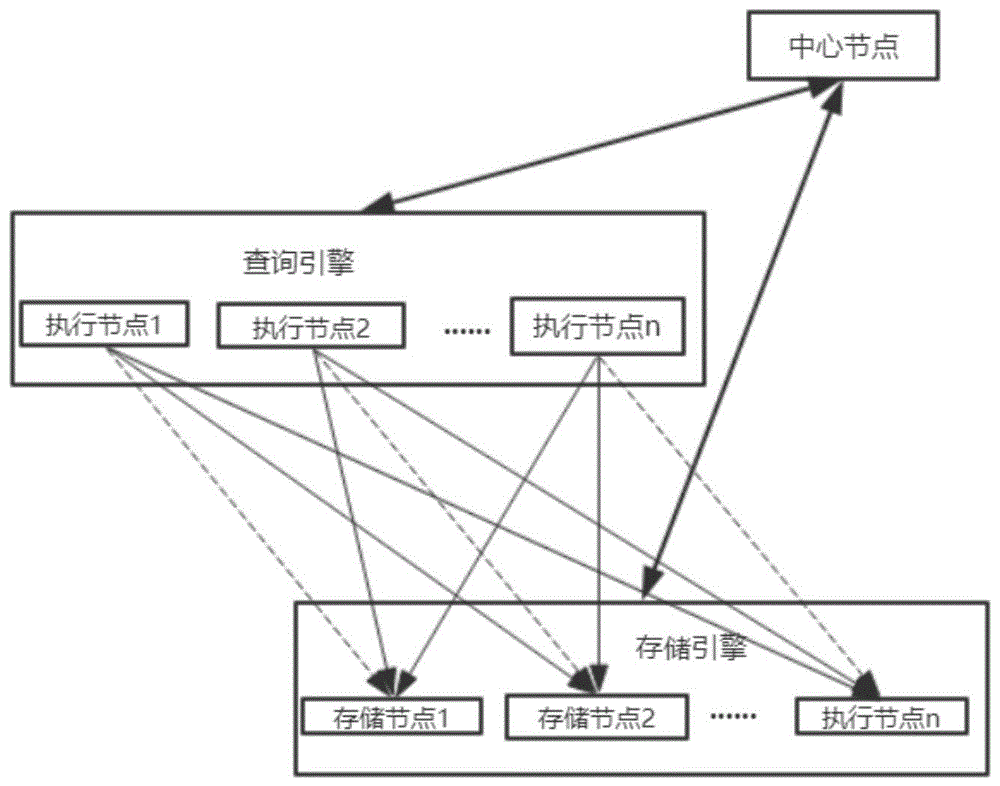
如图1所示,如果执行节点1落在存储节点1上执行,那么该执行节点就会从除存储节点1之外的其它存储节点上广播地获取所需的数据。如某一pipeline执行所需a表a列的部分数据,但是pipeline所在的执行节点在执行节点1上,也就是存储节点1上,而a表a列的数据分散在所有存储节点,那么执行该pipeline就需要广播地从其它存储节点获取执行所需的数据。又如执行某pipeline需要a表的a,b,c列,a列在该pipeline所在的执行节点上,而b列,c列却不在该pipeline所在的执行节点上,那么该执行节点就需要广播地从其它的存储节点获取b列和c列的数据。
然而,以上方式存在一些劣势:广播地从其它存储节点获取执行pipeline所需的数据,极大地增加了网络传输的开销,极大地增加了查询执行时间,进而影响了查询性能。
技术实现要素:
本发明所要解决的技术问题是:基于pipeline的查询上,广播地从其它存储节点获取执行pipeline所需的数据,极大地增加了网络传输的开销,极大地增加了查询执行时间,进而影响了查询性能的问题。本发明提供了解决上述问题的一种面向流水线结构化数据查询的数据库智能分区方法,旨在分布式内存列式数据库下降低查询引擎与存储引擎之间的网络传输开销,给出了一种基于机器学习的有利于pipeline执行的存储引擎节点间数据的布局策略,以提升查询引擎中物理计划的执行速度,进而提升查询性能。
本发明通过下述技术方案实现:
一种面向流水线结构化数据查询的数据库智能分区方法,该方法包括:
查询引擎根据sql的查询请求经过物理计划的执行来处理该sql查询请求,进行pipeline的划分,并将pipeline的划分情况上传至中心节点;
中心节点根据查询引擎发送的pipeline划分情况,采用在线k-means聚类算法计算出存储引擎节点间最优的数据存储布局,即经常被划分为同一pipeline的列数据属于聚类结果中的同一个簇,亦即经常被划分为同一pipeline的列数据存储在同一物理存储节点;其中,在线k-means聚类结果中的每个簇对应一个存储节点;
各存储节点利用增量方式存储当前最优数据布局的数据,直到各个存储节点上的数据皆按照最优的数据布局存储为止,每个存储节点便删除旧布局的数据,而保存新布局的数据。
工作原理是:基于pipeline的查询上,广播地从其它存储节点获取执行pipeline所需的数据,网络传输的开销大,查询执行时间长,进而导致查询性能差。本发明采用上述方案利用机器学习的思路通过优化数据库存储引擎节点间数据布局来提高物理计划执行速度,进而提高查询性能。具体地,查询引擎根据sql的查询请求经过物理计划的执行来处理该sql查询请求,进行pipeline的划分,并将pipeline的划分情况上传至中心节;然后,中心节点根据查询引擎发送的pipeline划分情况,采用在线k-means聚类算法计算出存储引擎节点间最优的数据存储布局,即经常被划分为同一pipeline的列数据属于聚类结果中的同一个簇,亦即经常被划分为同一pipeline的列数据存储在同一物理存储节点;各存储节点利用增量方式存储当前最优数据布局的数据,直到各个存储节点上的数据皆按照最优的数据布局存储为止,每个存储节点便删除旧布局的数据,而保存新布局的数据。本发明方法使pipeline执行节点与所需数据的存储节点尽可能地落在同一物理机上,这样就会减少pipeline执行节点与其它存储节点之间的交互,以及数据传输的开销,进而提升系统的查询性能,并且若pipeline某执行节点所需的数据全部在其对应的存储引擎节点上,那么直接让该执行节点在其对应存储节点所在的物理机上执行,大大提升查询性能。
进一步地,所述pipeline的划分,每一个pipeline的执行对应一个物理计划任务的执行,且一个pipeline对应一个执行节点。
所述将pipeline的划分情况上传至中心节点,是由查询引擎的master节点将每次pipeline划分的情况汇报给中心节点,其中,汇报的内容包括:每个pipeline所含的列属性信息。
还包括计时器,所述中心节点从收到查询请求起便由所述计时器执行计时。
进一步地,所述采用在线k-means聚类算法计算出存储引擎节点间最优的数据存储布局,具体包括:
通过中心节点收集与统计近段时间被划分为同一个pipeline的列属性信息,同时结合历史样本,采用在线k-means聚类算法进行聚类,结合存储引擎中各存储节点的现有资源和存储引擎的负载均衡对聚类出来的每个簇进行加权,并根据权重对簇降序排序,利用贪心算法生成存储引擎中各存储节点间最优的存储布局。
其中:所述通过中心节点收集与统计近段时间被划分为同一个pipeline的列属性信息,中心节点统计的属性信息用数字向量表示,数字向量的长度等于存储引擎表中属性的数量,聚类数等于存储引擎中存储节点总数,聚类结果中的每个簇对应一个存储节点,样本之间的距离采用欧式距离。
进一步地,各个存储引擎中的存储节点根据实时的数据布局信息,进行以最优的数据布局进行数据迁移,每个存储节点都按照最优布局以增量的方式进行数据的存储,直到各个存储节点上的数据皆按照最优的数据布局存储为止,每个存储节点便删除旧布局的数据,而保存新布局的数据。
进一步地,还包括:将数据源中的数据通过数据导入系统导入到存储引擎各存储节点中,一列一列地将数据导入到各存储引擎节点上,导入过程中,让一列的所有数据落在一个存储节点上。
本发明具有如下的优点和有益效果:
1、本发明提出使用机器学习的思路通过优化数据库存储引擎节点间数据布局来提高物理计划执行速度,使pipeline执行节点与所需数据的存储节点尽可能地落在同一物理机上,这样就会减少pipeline执行节点与其它存储节点之间的交互,以及数据传输的开销,进而提高查询性能;
2、本发明使用在线k-means聚类算法计算存储引擎节点间数据最优布局,通过中心节点收集与统计近段时间被划分为同一个pipeline的列属性信息,同时结合历史样本,采用在线k-means聚类算法进行聚类,结合存储引擎中各存储节点的现有资源和存储引擎的负载均衡对聚类出来的每个簇进行加权,并根据权重对簇降序排序,利用贪心算法生成存储引擎中各存储节点间最优的存储布局;
3、本发明存储引擎节点使用增量的方式存储当前最优布局的数据,各个存储引擎中的存储节点根据实时的数据布局信息,进行以最优的数据布局进行数据迁移,每个存储节点都按照最优布局以增量的方式进行数据的存储,直到各个存储节点上的数据皆按照最优的数据布局存储为止,每个存储节点便删除旧布局的数据,而保存新布局的数据。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
图1为现有技术中的基于pipeline的查询架构图。
图2为本发明提出的基于pipeline的查询在理想情况下的架构图。
图3为本发明方法流程架构图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
实施例
如图1至图3所示,一种面向流水线结构化数据查询的数据库智能分区方法,该方法包括:
查询引擎根据sql的查询请求经过物理计划的执行来处理该sql查询请求,进行pipeline的划分,并将pipeline的划分情况上传至中心节点;
中心节点根据查询引擎发送的pipeline划分情况,采用在线k-means聚类算法计算出存储引擎节点间最优的数据存储布局,即经常被划分为同一pipeline的列数据属于聚类结果中的同一个簇,亦即经常被划分为同一pipeline的列数据存储在同一物理存储节点;其中,聚类结果中的每个簇对应一个存储节点;
各存储节点利用增量方式存储当前最优数据布局的数据,直到各个存储节点上的数据皆按照最优的数据布局存储为止,每个存储节点便删除旧布局的数据,而保存新布局的数据。
具体地,如图3所示为系统架构,本发明方法的具体流程如下:
(1)将数据源中的数据通过数据导入系统导入到存储引擎中各存储节点上,一列一列地将数据导入到存储引擎中的各存储节点上,导入过程中,让一列的所有数据落在一个存储节点上,同时又要考虑到存储节点间的负载均衡。
(2)查询引擎根据sql的查询请求经过sql解析、生成逻辑计划、物理计划、物理计划的执行来处理该sql查询请求并返回结果给客户端。在物理优化阶段,进行pipeline的划分,每一个pipeline的执行对应一个物理计划任务的执行,且一个pipeline对应一个执行节点。查询引擎的master节点将每次pipeline划分的情况汇报给中心节点,汇报的内容包括:每个pipeline所含的列数据信息。并且,中心节点从系统启动收到查询请求业务起便开始计时。
(3)中心节点收到查询引擎master节点发送的pipeline信息之后,进行k-means聚类计算,当计时器的计时达到一定的时间间隔时,中心节点便将此时的聚类计算结果按照存储引擎中各存储节点的现有资源和存储节点间的负载均衡对每个簇进行加权,并对加权后的簇进行降序排序,计算每列到各簇的欧式距离,最后利用贪心算法确定各列应属于哪个簇,即确定各列属于哪个存储节点,最后生成存储引擎中各存储节点间最优的数据存储布局。
(4)中心节点将计算出的最优存储布局发给各个存储节点,各存储节点间收到最优布局信息之后便开始进行节点间的数据迁移,当所有存储节点都存储好最优布局的数据后便删除该节点上旧布局的数据。
本发明通过上述具体流程,使pipeline执行节点与所需数据的存储节点尽可能地落在同一物理机上,这样就会减少pipeline执行节点与其它存储节点之间的交互,以及数据传输的开销,进而提升系统的查询性能。理想情况如图2所示,执行节点与存储引擎节点之间存在一一对应的关系,比如,若pipeline执行节点1所需的数据全部在存储引擎节点1上,那么直接让执行节点1在存储节点1所在的物理机上执行。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!