一种在线社交网络中热点事件数据存储管理方法及系统与流程
本发明涉及数据存储技术领域,特别是指一种基于hbase数据库以及hdfs分布式文件系统的在线社交网络中热点事件数据存储管理方法及系统
背景技术:
近些年来,随着互联网的迅速发展和智能手机的普及,在线社交网络得到了迅猛的发展和普及,逐渐成为人们日常生活中必不可少的部分。各种在线社交网络平台同样也成为当下人们进行讨论热点事件的重要场所,由此产生了大量在线社交网络热点事件数据,并逐渐引起研究热点事件的相关学者和相关研究人员的重视。
至今,人们比较熟悉且广为使用的数据库仍然是关系型数据库,例如,oracle数据库以及mysql数据库等,此类数据库是建立在关系模型基础之上的数据库,它借助了集合代数等数学模型和方法来处理数据库中的数据。现实生活中所存在的各种实体以及实体间所存在的联系,在其中均用关系模型进行相应表示。关系模型的概念由就职于ibm的e.f.codd博士在1970年首先提出,这一模型概念的提出奠定了关系型数据库的理论基础。关系型数据库技术出现在关系模型概念提出后的20世纪70年代,在经历了80年代的稳健发展后,到上世纪90年代已经比较成熟了。且因其本身模型理解难度不高、查询语句的上手和掌握难度不高以及其产品的逐渐成熟,关系模型逐渐成为近20余年数据库架构中所使用的主流模型。
然而,社交网络热点事件数据隶属大数据,也具备大数据的基本特征(4v),即数据量大(volume)、数据类型多样化(variety)、时效性要求高(velocity)以及数据价值密度(value)相对较低。在线社交网络热点事件数据的这些特征,为使用传统关系型数据库作为数据的存储管理技术带来了极大挑战。以新浪微博为例,据新浪官方公布数据可知,截止至2018年3月,微博月活跃人数已增加到4.11亿,日活跃用户增至1.84亿,单月微博产生量达数十亿。“春晚答题王”这一活动则累计吸引了2400万人参与。而在两会期间,微博平台上参与两会话题讨论人数逾亿,两会相关短视频的总播放量超过30亿次。仅新浪微博中社交网络热点事件数据便可达数十tb。这对传统rmdb在存储和检索数据的时间空间开销上是极大的挑战。新浪微博用户在微博平台上发表内容的形式多种多样,包括短文字、文章、图片、动图、视频以及链接等,存在异构性。而传统的关系型数据库仅擅长处理结构化数据。新浪微博等在线社交网络平台也并未对用户发表信息的内容作出限制,从而所产生数据的价值密度相对较低。如何去实现价值密度的浓缩,也为传统关系型数据库带来了挑战。而不同在线社交网络平台的数据还存在差异性,这也增加在线社交网络热点事件数据的复杂度,这无疑也让使用传统关系型数据库技术进行这类数据存储和管理的境况雪上加霜。
如何有效地克服因在线社交网络热点数据本身数据基本特征(数据量大、数据类型多、数据价值密度低以及跨平台数据间存在差异性)所带来的数据存储和管理上的困难,以及有效地浓缩其价值密度来为热点事件相关研究提供数据支持,成为了现如今亟待解决的问题。
技术实现要素:
为解决上述技术问题,本发明提供一种在线社交网络中热点事件数据存储管理方法,所述方法包括:
基于hdfs分布式文件系统,对在线社交网络中热点事件的原始数据进行存储;在所述hdfs分布式文件系统中,同一热点事件的全部数据存放在同一路径下,同一事件中来源于不同平台的数据分平台存放在各自对应的路径中,而同一平台中来源于不同文章的数据则分文章存放在各自对应的路径中;
针对不同平台数据间存在的差异性,通过预设清洗及稀疏方式对数据进行清洗及稀疏,实现不同平台数据间的数据一致化;
对于热点事件的原始数据,根据其数据结构固定程度和数据大小特征,将各数据划分为文本类数据、图片类数据以及视频类数据;并对分类后的数据,依据各数据的数据类型,分别按预设分类存储方式设计不同的存储方案;
从预设维度建立数据存储模型,对所述hdfs分布式文件系统中所存储的数据进行解析,并按照所建立的数据存储模型完成数据的存储。
进一步地,所述通过预设清洗及稀疏方式对数据进行清洗及稀疏,实现不同平台数据间的数据一致化,包括:
针对相同数据在不同在线社交网络平台中有不同存储形式的情况,采用数据清洗的方式使不同平台中相同数据一致化;
针对不同在线社交网络平台中包含的数据不尽相同的情况,采用求取数据内容的并集并稀疏化各平台中数据的方式使不同平台中的数据一致化。
进一步地,所述依据各数据的数据类型,分别按预设分类存储方式设计不同的存储方案,包括:
对于文本类数据,保留其数据结构并将其存放至hbase数据库中;
对于图片类数据,将其直接存放至hbase表中的单元格内;
对于视频类数据,将其本身直接存放入hdfs分布式文件系统中,然后在hbase数据库中存放该视频类数据在hdfs分布式文件系统中的存放路径。
进一步地,所述从预设维度建立数据存储模型,包括从实体维度出发建立实体维度的数据存储模型,所述实体维度的数据存储模型的建立过程为:
首先从热点事件的原始数据中分析并抽取出多个数据实体,所述数据实体包括:事件、参与者、报道以及评论;
然后描述各数据实体并分析各数据实体间的关系,完成所述实体维度的数据存储模型设计。
进一步地,所述从预设维度建立数据存储模型,还包括从事件逻辑属性维度出发建立事件逻辑属性维度的数据存储模型;
所述事件逻辑属性维度的数据存储模型的建立过程为:
首先从逻辑上分析得到用来完整描述一个事件的属性信息,所述属性信息包括事件的时间、地点、任务、起因、经过以及结果;
然后结合在线社交网络热点事件数据特征,将所述属性信息归类为事件的时间、地点、人物和子事件四个分类;并依据事件属性信息的分类,通过描述每一类属性和各类属性间的关系完成事件逻辑属性维度的数据存储模型设计。
相应地,为解决上述技术问题,本发明还提供一种在线社交网络中热点事件数据存储管理系统,所述系统包括:
存储数据模块,用于基于hdfs分布式文件系统,对在线社交网络中热点事件的原始数据进行存储;
在所述hdfs分布式文件系统中,同一热点事件的全部数据存放在同一路径下,同一事件中来源于不同平台的数据分平台存放在各自对应的路径中,而同一平台中来源于不同文章的数据则分文章存放在各自对应的路径中;
清洗及稀疏模块,用于针对不同平台数据间存在的差异性,通过预设清洗及稀疏方式对数据进行清洗及稀疏,实现不同平台数据间的数据一致化;
分类及存储模式设定模块,用于对热点事件的原始数据,根据其数据结构固定程度和数据大小特征,将各数据划分为文本类数据、图片类数据以及视频类数据;并对分类后的数据,依据各数据的数据类型,分别按预设分类存储方式设计不同的存储方案;
数据存储模型设计模块,用于从预设维度建立数据存储模型,对所述hdfs分布式文件系统中所存储的数据进行解析,并按照所建立的数据存储模型完成数据的存储。
进一步地,所述清洗及稀疏模块,包括:
清洗单元,用于针对相同数据在不同在线社交网络平台中有不同存储形式的情况,采用数据清洗的方式使不同平台中相同数据一致化;
求取并集并稀疏单元,用于针对不同在线社交网络平台中包含的数据不尽相同的情况,采用求取数据内容的并集并稀疏化各平台中数据的方式,使不同平台中的数据一致化。
进一步地,所述分类及存储模式设定模块,具体用于:
对于文本类数据,保留其数据结构并将其存放至hbase数据库中;
对于图片类数据,将其直接存放至hbase表中的单元格内;
对于视频类数据,将其本身直接存放入hdfs分布式文件系统中,然后在hbase数据库中存放该视频类数据在hdfs分布式文件系统中的存放路径。
进一步地,所述数据存储模型设计模块包括实体维度的数据存储模型设计单元,所述实体维度的数据存储模型设计单元用于:
首先从热点事件的原始数据中分析并抽取出多个数据实体,所述数据实体包括:事件、参与者、报道以及评论;
然后描述各数据实体并分析各数据实体间的关系,完成所述实体维度的数据存储模型设计。
进一步地,所述数据存储模型设计模块还包括事件逻辑属性维度的数据存储模型设计单元;所述事件逻辑属性维度的数据存储模型设计单元用于:
首先从逻辑上分析得到用来完整描述一个事件的属性信息,所述属性信息包括事件的时间、地点、任务、起因、经过以及结果;
然后结合在线社交网络热点事件数据特征,将所述属性信息归类为事件的时间、地点、人物和子事件四个分类;并依据事件属性信息的分类,通过描述每一类属性和各类属性间的关系完成事件逻辑属性维度的数据存储模型设计。
本发明的上述技术方案的有益效果如下:
1、可存储传统数据库较难存储的数据量级,且存储容量易扩充:由于容量的可扩展性强,所以不仅能够应对当前的数据存储量级需求,还可以很好的应对未来可能存在的数据存储量级需求;
2、数据存储类型不受限制:可以妥善存储多种不同数据类型的数据;
3、有效浓缩了数据的价值密度:通过从多个维度进行数据的存储模型设计,有效提升了数据的价值密度;
4、透明化不同在线社交网络平台中热点事件数据:通过对不同平台中数据内容的并集和稀疏化操作,统一化不同在线社交网络中热点事件数据内容。
附图说明
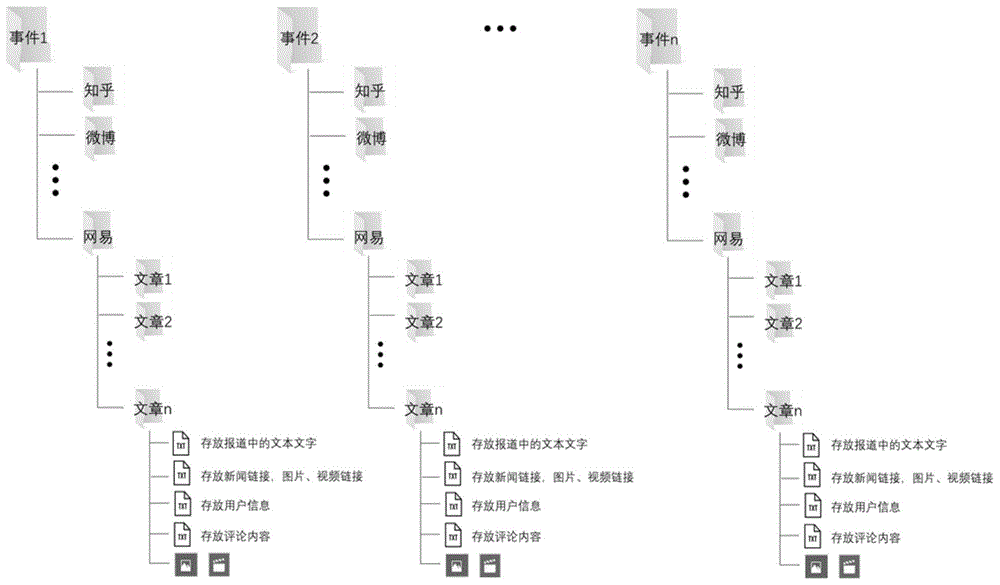
图1是本发明hdfs分布式文件系统中原始数据存储路径的设计示例图;
图2是本发明划分数据类别的多种存储模式策略中不同数据类别的数据存储方案设计示例图;
图3是本发明多维度的数据存储模型策略中从实体维度对在线社交网络热点事件数据的存储模型设计示意图;
图4是本发明多维度的数据存储模型策略中从事件逻辑属性维度对在线社交网络热点事件数据的存储模型设计示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
第一实施例
请参阅图1至图4,本实施例提供一种在线社交网络中热点事件数据存储管理方法,所述方法针对在线社交网络热点事件数据所具有的数据量大、跨平台数据间存在差异性、数据类型多以及数据价值密度低的问题,分别提出了分布式文件系统存储数据策略、清洗并稀疏多平台数据策略、划分数据类别的多种存储模式策略以及多维度的数据存储模型策略,下面进行详细说明:
分布式文件系统存储数据策略:基于hdfs分布式文件系统,对在线社交网络中热点事件的原始数据进行存储;
传统关系型数据库技术无法满足大规模数据的存储与管理的需求,其原因在于传统关系型数据库无法做到容量横向扩充,其扩充仅支持纵向扩充,即单个服务器上容量的扩充。这不仅需要很昂贵的设备(带来极大的经济开销),也会出现容量扩充的瓶颈问题。而建立在hadoop集群上的分布式文件系统hdfs就很好地规避了这些问题。hdfs分布式文件系统支持存储容量的横向扩充,即通过增加节点的方式实现存储容量的扩充,且对节点设备的要求不高,通常是一些较为廉价的设备(经济开销较小)。
当然对于原始数据在hdfs分布式文件系统中的存储,需要在存储物理位置上表达数据的一些简单关系。例如,在hdfs分布式文件系统中,同一热点事件的全部数据存放在同一路径下,即该事件所对应的事件路径下。同一事件中来源于不同平台的数据分平台存放在各自对应的路径中,即一个事件中某一平台中的数据,需存放在该事件路径下所对应的该平台路径下。而同一平台中来源于不同文章的数据则分文章存放在各自对应的路径中,即一个事件中某平台中的某文章数据,需存放在该事件平台路径下所对应的文章路径中。一篇文章中的数据包括,文本数据(例如报道中的文字数据、用户数据、评论数据等)、图片数据和视频数据;如图1所示。
清洗并稀疏多平台数据策略:针对不同平台数据间存在差异性,通过预设清洗及稀疏方式对数据进行清洗及稀疏,实现不同平台数据间的数据一致化;
具体地,不同平台数据间的差异性主要表现在两个方面:a、相同数据在不同在线社交网络平台中有不同存储形式;b、不同在线社交网络平台中包含的数据不尽相同。针对相同数据的不同存储形式,采用数据清洗的使不同平台中相同数据一致化。针对不同平台中包含的数据不尽相同,采用求取数据内容的并集并稀疏化各个平台中数据的方式来使不同平台中的数据一致化。针对稀疏数据的存储,选择采用善于存储稀疏数据的hbase数据库。
划分数据类别的多种存储模式策略:对于在线社交网络热点事件数据,首先根据其数据结构固定程度划分为非结构化数据和半结构化数据,再结合数据大小的特征,将数据进一步划分为文本类数据(半结构化数据、小文件)、图片类数据(非结构化数据、小文件)和视频类数据(非结构化数据、大文件),如图2所示;并对分类后的数据,依据各数据的数据类型,分别按预设分类存储方式设计不同的存储方案;
具体地,对于属于半结构化数据、文件大小较小、数据存在稀疏性的文本类数据,保留其基本数据结构,采用清洗并稀疏多平台数据策略中得到的数据结构将此类数据存放至hbase数据库中;对于属于非结构化数据且文件大小相对较小的图片类数据,将其直接存放至hbase表中的单元格内;base数据库有自动打包小文件的功能;而针对属于非结构化数据且文件大小较大的视频类数据,则将其本身直接存放入hdfs分布式文件系统中,然后在hbase数据库中存放该视频类数据在hdfs分布式文件系统中的存放路径。
多维度的数据存储模型策略:为浓缩在线社交网络热点事件数据的价值密度,从两个维度进行了数据存储模型的设计,分别是实体维度和事件逻辑属性维度。然后对hdfs分布式文件系统中所存储的数据进行解析,并按照所建立的数据存储模型完成数据的存储;其中,
实体维度的数据模型设计需首先从在线社交网络热点事件原始数据中分析抽取得到4个实体,分别是事件(event)、参与者(user)、报道(post)和评论(comment),如图3所示。同时分析找到不同数据实体间关系,并将这些关系转变成数据存储下来,即设计的eventusers表、eventposts表、userposts表、postcomments表及usercomments表;从而完成实体维度的数据模型设计。
事件逻辑属性维度的数据模型设计首先需要从逻辑上分析得到可以用来完整描述一个事件的属性信息。归纳得到以下六个,分别是事件的时间、地点、任务、起因、经过和结果。结合在线社交网络热点事件数据特征,将上述6类事件属性重新归类为事件的时间(timeevents)、地点(provinceevents)、人物(eventusers)以及子事件(eventprocess)这4类,如图4所示。并依据数据事件属性的分类,通过描述每一类属性和属性间的关系完成事件逻辑属性维度的数据模型设计。与上面的实体数据不同,这些数据是事件的属性数据,不同属性间不存在直接关联关系,皆通过直接与事件数据相关联,从而间接产生关联关系。所以从时间逻辑属性维度设计的在线社交网络热点事件数据存储模型仍然包含事件(event)实体数据。
本实施例中的所有策略在存储在线社交网络热点事件数据的过程中全部被涉及,整个数据存储过程可分为在线社交网络热点事件原始数据存储和原始数据解析及数据按存储模型存储入库两个部分。
其中,在线社交网络热点事件原始数据存储,其具体实施步骤如下:
1、hdfs分布式文件系统物理设备的选取及分配:根据hadoop集群即hdfs文件系统运行特征及原始数据存储空间需求,一共选取了4个有1t存储容量的节点,安装centos作为hadoop集群的节点。其中选取一个节点作为namenode,全部4个节点作为datanode;
2、建立hadoop用户组和关闭节点间防火墙:在每一个节点上执行sudoaddgrouphadoop命令,用于创建hadoop组,执行sudouseraddhadoop-ghadoop命令,用于创建hadoop用户,执行sudoufedisable关闭防火墙。使用sudoufwstatus命令检查防火墙是否成功关闭;
3、安装hadoop并配置相关环境变量:在~/.bashrc中添加hadoop_home、hadoop_install、hadoop_mapred_home、hadoop_hdfs_home以及yarn_home等参数配置信息;
4、配置core-site.xml文件:向hadoop的core-site.xml文件中添加fs.default.name(配置master节点信息)和hadoop.tmp.dir(hadoop临时路径)参数信息;
5、配置hdfs-site.xml文件:向hadoop的hdfs-site.xml文件中添加dfs.name.dir(namenode持久存储名字空间及事务日志的本地文件系统路径)、dfs.data.dir(datanode存放块数据的本地文件系统路径)以及dfs.replication(hdfs中副本数量)参数信息;
6、配置mapred-site.xml文件:向hadoop的mapred-site.xml文件中添加yarn.resourcemanager.address(向客户端暴露的访问地址)、yarn.resourcemanager.admin.address(向管理员暴露的访问地址)、yarn.resourcemanager.webapp.address(对外webui地址)等参数信息;
7、配置通用信息:包括修改各个节点主机名、添加各个节点内部ip地址至slaves文件中以及配置节点间无密码访问;
8、格式化namenode并启动hadoop:使用hadoopnamenode–format命令格式化namenode,使用start-all.sh命令启动hadoop集群;
9、创建hdfs文件系统中数据存储路径:例如hadoopfs-mkdir–p/eventdata(所有的在线社交网络热点事件数据存储路径)、hadoopfs-mkdir–p/eventdata/event1(事件一的所有数据存放路径)以及hadoopfs-mkdir–p/eventdata/event1/sina(事件一下所有新浪微博平台中相关数据存放路径)。
原始数据解析及数据按存储模型存储入库,其具体实施步骤如下:
1、设计hbase表结构:按照图3、图4设计的数据存储模型,对应设计相关hbase表结构,如图3,在event表中,将eventid设计为表的主键,同时将event表设计为双列族hbase表,一个列族命名为info,用于存储事件本身基础信息,另一个列簇命名为other,用于预防未来可能还需要存储的另外类别数据。other列族中具体每一列列名,与按清洗并稀疏多平台数据策略处理后所得到的数据名一致;
2、解析hdfs中原始数据:在存储数据进入hbase数据库之前,需要先解析数据。解析数据需要保留数据间的关系,具体解析步骤如下:
a)解析事件本身(event)数据:解析每个事件中的event.txt文件中数据,得到一个事件的基础数据,同时创建一个list<post>容器,可以有效表达事件与报道间的关系;
b)解析报道数据:解析每一个报道中的报道文本数据,得到一个报道的基础数据,同时分别创建list<user>、list<comment>以及list<media>容器,可以有效表达报道与这些数据间的关系。最后将解析后的报道数据和创建的这些容器一同添加进list<post>容器中;
c)解析参与者数据:解析每一个参与者的数据,得到一个参与者的基础数据,并将解析后的数据添加进list<user>容器中;
d)解析评论数据:解析每一个评论的数据,得到一个评论的基础数据,并将解析后的数据添加到list<comment>容器中;
e)解析图片和视频数据:当解析一个图片文件时,将图片数据添加进list<media>容器中。当解析一个视频文件时,先将视频数据存入hdfs分布式文件系统,再将在hdfs文件系统中的数据存放地址添进list<media>容器中。
3、创建hbase表:打开hbaseshell,使用creat‘表名’,‘列族名1’,‘列族名2’的命令创建对应hbase表;
4、数据存储到hbase数据库中:将解析的基础数据分别对应存入已创建的event表、post表、user表以及comment表中。依据利用容器所表达的数据关系,获取eventusers表、postcomment表以及timeevents表等表中所需数据并进行对应数据的入库存储。
第二实施例
本实施例提供一种在线社交网络中热点事件数据存储管理系统,包括:
存储数据模块,用于基于hdfs分布式文件系统,对在线社交网络中热点事件的原始数据进行存储;
在hdfs分布式文件系统中,同一热点事件的全部数据存放在同一路径下,同一事件中来源于不同平台的数据分平台存放在各自对应的路径中,而同一平台中来源于不同文章的数据则分文章存放在各自对应的路径中;
清洗及稀疏模块,用于针对不同平台数据间存在的差异性,通过预设清洗及稀疏方式对数据进行清洗及稀疏,实现不同平台数据间的数据一致化;
分类及存储模式设定模块,用于对于实现数据一致化后的数据,根据其数据结构固定程度和数据大小特征,将各数据划分为文本类数据、图片类数据以及视频类数据;并对分类后的数据,依据各数据的数据类型,分别按预设分类存储方式设计不同的存储方案;
数据存储模型设计模块,用于从预设维度建立数据存储模型,对hdfs分布式文件系统中所存储的数据进行解析,并按照所建立的数据存储模型完成数据的存储。
进一步地,上述清洗及稀疏模块,包括:
清洗单元,用于针对相同数据在不同在线社交网络平台中有不同存储形式的情况,采用数据清洗的方式使不同平台中相同数据一致化;
求取并集并稀疏单元,用于针对不同在线社交网络平台中包含的数据不尽相同的情况,采用求取数据内容的并集并稀疏化各平台中数据的方式,使不同平台中的数据一致化。
进一步地,上述分类及存储模式设定模块,具体用于:
对于文本类数据,保留其数据结构并将其存放至hbase数据库中;
对于图片类数据,将其直接存放至hbase表中的单元格内;
对于视频类数据,将其本身直接存放入hdfs分布式文件系统中,然后在hbase数据库中存放该视频类数据在hdfs分布式文件系统中的存放路径。
进一步地,上述数据存储模型设计模块包括实体维度的数据存储模型设计单元,该实体维度的数据存储模型设计单元用于:
首先从热点事件的原始数据中分析并抽取出多个数据实体,该数据实体包括:事件、参与者、报道以及评论;然后描述各数据实体并分析各数据实体间的关系,完成实体维度的数据存储模型设计。
进一步地,上述数据存储模型设计模块还包括事件逻辑属性维度的数据存储模型设计单元;该事件逻辑属性维度的数据存储模型设计单元用于:
首先从逻辑上分析得到用来完整描述一个事件的属性信息,该属性信息包括事件的时间、地点、任务、起因、经过以及结果;
然后结合在线社交网络热点事件数据特征,将属性信息归类为事件的时间、地点、人物和子事件四个分类;并依据事件属性信息的分类,通过描述每一类属性和各类属性间的关系完成事件逻辑属性维度的数据存储模型设计。
本实施中的在线社交网络中热点事件数据存储管理系统与上述第一实施例中的中的在线社交网络中热点事件数据存储管理方法相对应;其中,该在线社交网络中热点事件数据存储管理系统中的各模块所实现的功能与上述第一实施例中的方法的各流程步骤一一对应,故在此不再赘述。
本发明上述实施例中技术方案的有益效果如下:
1、可存储传统数据库较难存储的数据量级,且存储容量易扩充:由于容量的可扩展性强,所以不仅能够应对当前的数据存储量级需求,还可以很好的应对未来可能存在的数据存储量级需求;
2、数据存储类型不受限制:可以妥善存储多种不同数据类型的数据;
3、有效浓缩了数据的价值密度:通过从多个维度进行数据的存储模型设计,有效提升了数据的价值密度;
4、透明化不同在线社交网络平台中热点事件数据:通过对不同平台中数据内容的并集和稀疏化操作,统一化不同在线社交网络中热点事件数据内容。
此外,需要说明的是,本领域内的技术人员应明白,本发明实施例的实施例可提供为方法、装置、或计算机程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明实施例是参照根据本发明实施例的方法、终端设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明实施例范围的所有变更和修改。
还需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的相同要素。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!