一种基于可形变结构的行人图像生成方法和装置与流程
本发明涉及图像生成领域,特别涉及一种基于可形变结构的行人图像生成方法和装置。
背景技术:
从一张行人图片根据给定姿态转换成另一张行人图片,是行人图像生成问题。行人图像生成问题是图像生成的一个领域,相比较普通的图像生成,行人图像生成因为要考虑更复杂的场景和多样的可形变姿态,会更加复杂和充满挑战性。
可以根据传统的图像生成思路来解决行人图像生成问题,比如采用条件对抗生成网络,将人体全身的源图片作为条件指导网络生成具有源图片外观的新姿态图片;还可以采用循环对抗生成网络,替换行人图片的背景和光照,在保留人体特征的基础上,生成新的姿态和环境下的行人图片。这样的方法最大的问题是难以训练,人体作为可形变物体过于复杂,复杂的图片转换关系需要极大规模的训练样本。
将人体信息引入生成过程是一种更好的解决思路,比如将姿态信息作为输入信息的一部分,提供先验条件的指引。人体可形变复杂性的关键就是姿态的多样性,姿态信息的先验指导可以有效地缓解生成复杂性,从而可以生成更真实的行人图片。同样的问题依然存在,全身的姿态转换依然复杂,想要生成更真实的图片依然需要海量的训练样本。
技术实现要素:
本发明实施例提供了一种基于可形变结构的行人图像生成方法和装置,在考虑人体可形变结构的基础上,降低训练的代价,提升算法的性能。
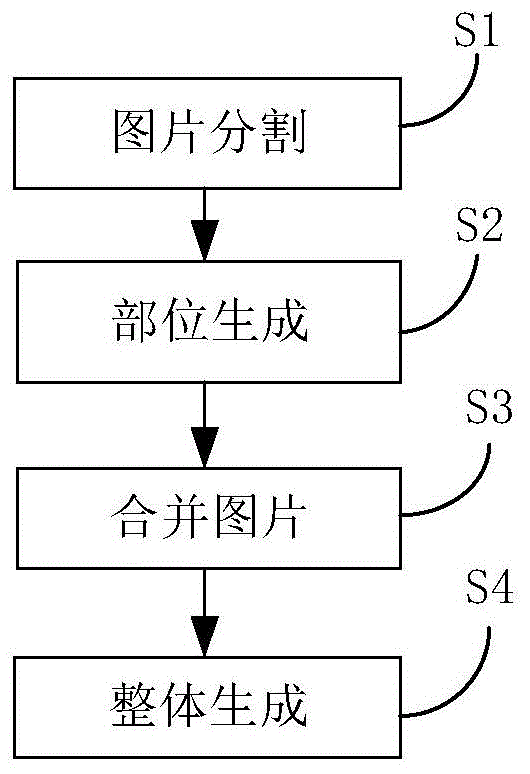
根据本发明实施例的第一方面,本发明一种基于可形变结构的行人图像生成方法,具体包括以下步骤:
步骤一、对于输入的行人图片和目标姿态图片,对行人图片和目标姿态图片按照部位结构进行分割操作,得到的部位行人图片和部位目标姿态图片,对行人图片、目标姿态图片、部位行人图片和部位目标姿态图片均进行提取mask操作,得到行人mask图片、目标姿态图片mask图片、部位行人mask图片和部位目标姿态图片mask图片;
步骤二、对部位行人图片预处理,对预处理后的部位行人图片、部位目标姿态图片和部位目标姿态mask图片,然后进行部位生成操作,得到部位生成图片;
步骤三、对步骤二中部位生成操作得到的部位生成图片进行结构化合并操作,得到结构化合并图片;
步骤四、对原始的行人图片进行预处理,将预处理后的行人图片和步骤三中的合并后的图片、目标姿态图片作为输入,然后进行整体生成操作,得到生成图片。
所述步骤一中,分割操作具体包括以下步骤:
1.1对行人图片和目标姿态图片,采用关节点检测算法,找到输入图片的关节点;
1.2通过关节点的位置和确信度,判断提取的关节点是否可以使用;
1.3如果关节点可以使用,根据双肩2个关节点的平均高度和髋关节2个关节点的平均高度,将图片分割为3个部分,双肩2个关节点的平均高度以上的部分为第一部分,2个关节点的平均高度和髋关节2个关节点的平均高度之间的部分为第二部分,髋关节2个关节点的平均高度以下的部分为第三部分;如果关节点不可以使用,根据固定尺寸将图片分割为3个部分,从上到下依次分别为第一部分、第二部分、第三部分。
所述步骤二中,具体包括以下子步骤:
2.1根据生成部位的不同,分为3个独立的生成网络,分别对应步骤一中的第一部分、第二部分和第三部分;
2.2对于第i个独立的生成网络,包括生成器
2.3依次对3个独立的生成网络重复步骤2.2,得到所有的部位生成图片。
所述步骤三,结构化合并操作包括如下子步骤:
3.1对于得到的3个分别对应第一部分、第二部分和第三部分的生成部位图片,根据原图中不同部位的尺寸比例ht,i和wt,将生成的部位图片
3.2根据原图中部位结构的位置关系,将
3.3调节结构化合并后的部位生成图片的颜色和边缘连接信息,δhi是高度的偏移调整,ci是不同部位图片的色彩平衡调整因子,得到更真实的结构化合并图片aw。
所述步骤2.2具体包括以下子步骤:
2.2a)将分割后的部位行人图片xi输入生成器
2.2b)将部位行人图片xi和目标姿态图片yi输入判别器
2.2c)计算部位目标姿态图片yi、生成图gpi(xi)与部位目标姿态mask图片pi的maskl1损失函数
2.2d)计算对抗损失函数
2.2e)综合上述两个损失函数,第i个独立的生成网络,损失函数为:
2.2f)通过最小化损失函数li来更新生成器
2.2g)通过最大化对抗损失函数
2.2k)返回2.2a)继续更新,直至损失函数li减低到阈值或者迭代次数达到要求,输出和目标姿态一致的部位生成图片gpi(xi,pi)。
所述步骤四,整体生成操作包括如下子步骤:
4.1将行人图片x输入生成器gw得到生成图gw(x),将行人图片x、目标姿态mask图片、合并图片aw输入生成器gw得到生成图gw(x,p,aw);
4.2将目标姿态图片y输入判别器dw得到dw(y),将生成图gw(x,p,aw)输入判别器dw得到dw(gw(x,p,aw));
4.3计算目标姿态图片y、生成图gw(x)和mask图片p的maskl1损失函数m(gw):
⊙指两个相同尺寸的矩阵之间的元素乘法,||*||1为1-范数;
4.4计算身份分类网络作为指导:
其中,cl指目标人物的身份类别标签,如果分类网络预测的类别标签和cl一致则qc=1,否则qc=0,p(gw(x,p,aw))分类网络的输出概率分布;
4.5计算对抗损失函数vw:
4.6整体生成网络,损失函数lw为:
lw=vw(dw,gw)+m(gw)+c(gw,cl)
4.7通过最小化损失函数lw来更新生成器gw;
4.8通过最大化对抗损失函数vw(dw,gw)更新判别器dw;
4.9返回步骤4.1继续更新,直至损失函数lw减低到可接受范围或者迭代次数达到要求,输出生成图片gw(x,p,aw)。
所述步骤一中,提取mask操作具体为:
对于输入的图片,采用mask检测算法,获得相应mask图片;其中,mask图片上的检测物体颜色统一为白色,背景颜色统一为黑色。
所述步骤三中,aw的计算公式为:
其中,ht和wt表示目标图片的高度和宽度,ht,i表示目标图片第i个身体部位的高度;r(pic,h,w)代表将一张图片的尺寸调整为h*w的操作,o(h*w)指h*w尺寸的零矩阵。我们根据目标图片的部位结构关系重新组织部位图片的位置。为了保证部位连接处的平滑,δhi是高度的偏移调整,而ci是不同部位图片的色彩平衡调整因子。
一种基于可形变结构的行人图像生成装置,包括:
图像预处理模块:对于输入的原行人图片和目标姿态图片,分别对原行人图片和目标姿态图片按照部位结构进行分割操作和提取mask操作,得到三组预处理后的部位行人mask图、部位目标姿态mask图片、部位行人图片和部位目标姿态图片;
部位生成模块:对分割得到的部位行人图片用部位行人mask图片预处理,对部位目标姿态mask图片、部位行人图片和部位目标姿态图片,进行部位生成操作,得到三张部位生成图片;
结构化合并模块:对部位生成操作得到的三张部分生成图片进行结构化合并操作,得到一张结构化合并图片;
整体生成模块:将结构化合并图片、原图片和目标姿态作为输入,进行整体生成操作,得到一张最终的行人生成图片。
部位生成模块和整体生成模块均包含生成器和判别器。
本发明实施例提供的技术方案可以包括以下有益效果:
通过将行人图像生成的复杂问题分解为数个部位图片的姿态间转换问题,降低了生成网络对于训练样本的数量需求,同时将更多的局部特征作为生成的指标,在高效的同时提高了生成图片的质量。具体来说,包括:通过分割操作和提取mask操作,将图片进行符合人体特征的先验处理;通过部位生成操作,生成不同的部位图片,分解复杂的全身姿态对应;通过结构化合并操作,将生成的部位图片组合起来,为全身的生成提供有力的指导;通过整体生成操作,在保留局部信息和身份信息的前提下,生成更真实可信的行人图像。综上所述,通过本发明实施例提供的方法能够提高行人图像生成算法的效率和生成真实性。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
图1为本发明一种基于可形变结构的行人图像生成方法流程图;
图2为本发明一种基于可形变结构的行人图像生成方法的对比图;
图3为本发明实施例中基于可形变结构的行人图像生成方法的整体示意图;
图4为本发明实施例中基于可形变结构的行人图像生成的分割和提取操作示意图;
图5为本发明实施例中基于可形变结构的行人图像生成的结构化合并操作示意图;
图6为本发明一种基于可形变结构的行人图像生成装置的结构框图。
具体实施方式
实施例一
如图1、2所示,本发明提供了一种基于可形变结构的行人图像生成方法,能够得到优化的目标姿态图片,具体包括以下步骤:
步骤一、如图4所示,对于输入的行人图片和目标姿态图片,对行人图片和目标姿态图片按照部位结构进行分割操作,得到的部位行人图片和部位目标姿态图片,对行人图片、目标姿态图片、部位行人图片和部位目标姿态图片均进行提取mask操作,得到行人mask图片、目标姿态mask图片、部位行人mask图片和部位目标姿态图片mask图片;
分割操作具体包括以下步骤:
1.1对行人图片和目标姿态图片,采用关节点检测算法,首先找到输入图片的14个关节点;
1.2通过关节点的位置和确信度,判断提取的关节点是否可以使用,可以使用需要满足:确信度大于0.6的关节点数量超过8个,并且肩关节点与髋关节点之间的最小纵向距离超过图片总高度的1/3;
1.3如果关节点可以使用,根据双肩2个关节点的平均高度和髋关节2个关节点的平均高度,将图片分割为3个部分,双肩2个关节点的平均高度以上的部分为第一部分,2个关节点的平均高度和髋关节2个关节点的平均高度之间的部分为第二部分,髋关节2个关节点的平均高度以下的部分为第三部分;如果关节点不可以使用,根据固定尺寸将图片分割为3个部分,具体尺寸为:纵向依次分割图片成三个部分,第一部分(头部)的高度占图片总高度的1/4,第二部分(上身部分)的高度占图片总高度的3/8,第三部分(下身部分)占图片总高度的3/8。
提取mask操作具体为:
对于输入的图片,采用mask检测算法,获得相应mask图片;
将mask图片上的检测物体颜色统一为白色,背景颜色统一为黑色,并将最终的mask图片输出为mask图片。
步骤二、对部位行人图片预处理,对预处理后得到的部位行人图片、部位目标姿态图片和部位目标姿态mask图片进行部位生成操作,得到部位生成图片;
预处理为将部位行人mask图片乘以原部位行人图片,得到去除背景的部位行人图片;
部位生成操作,输入要求为一张分割后的部位行人图片、分割后的部位目标姿态对应的mask图片和分割后的部位目标姿态图片,输出为一张和目标姿态一致的部位生成图片;具体包括如下步骤:
2.1根据生成部位的不同,分为3个独立的生成网络,分别对应步骤一中的第一部分、第二部分和第三部分;
2.2对于第i个独立的生成网络,包括一个生成器
2.3依次对3个独立的生成网络重复步骤2.2,得到所有的部位生成图片;
所述步骤2.2具体包括以下子步骤:
2.2a)将分割后的部位行人图片xi输入生成器
2.2b)将部位行人图片xi和目标姿态图片yi输入判别器
2.2c)计算部位目标姿态图片yi、生成图gpi(xi)与部位目标姿态mask图片pi的maskl1损失函数
2.2d)计算对抗损失函数
2.2e)综合上述两个损失函数,第i个独立的生成网络,损失函数为:
2.2f)通过最小化损失函数li来更新生成器
2.2g)通过最大化对抗损失函数
2.2k)返回2.2a)继续更新,直至损失函数li减低到阈值或者迭代次数达到要求,输出部位生成图片gpi(xi,pi)。
步骤三、对部位生成操作得到的部位生成图片进行结构化合并操作;
结构化合并操作包括如下子步骤:
3.1对于得到的3个分别对应第一部分、第二部分和第三部分的生成部位图片,根据原图中不同部位的尺寸比例ht,i和wt,将生成的部位图片
3.2根据原图中部位结构的位置关系,将缩放后的3个生成部位图片
3.3调节结构化合并后的部位生成图片的颜色和边缘连接等信息,δhi是高度的偏移调整,通过多次尝试得到,ci是不同部位图片的色彩平衡调整因子,优选的,可以为将三张图片的色彩平均值分别除以三张色彩总的均值得到,得到更真实的结构化合并图片aw;
aw的获取可以用下述公式求得:
其中,ht和wt表示目标图片的高度和宽度,ht,i表示目标图片第i个身体部位的高度;r(pic,h,w)代表将一张图片的尺寸调整为h*w的操作,o(h*w)指h*w尺寸的零矩阵。我们根据目标图片的部位结构关系重新组织部位图片的位置。为了保证部位连接处的平滑,δhi是高度的偏移调整,而ci是不同部位图片的色彩平衡调整因子,如图5所示;
步骤四、对原始图片进行预处理,将合并后的图片、行人图片和目标姿态图片作为输入,进行整体生成操作;
预处理为将行人mask图片乘上原行人图片,得到去除背景的行人图片;
整体生成操作输入要求为:一张原始图片、目标姿态mask图片、目标姿态图片和结构化合并后的部位生成图片;包括如下子步骤:
4.1将行人图片x输入生成器gw得到生成图gw(x),将行人图片x、目标姿态mask图片、合并图片aw输入生成器gw得到生成图gw(x,p,aw);
4.2将目标姿态图片y输入判别器dw得到dw(y),将生成图gw(x,p,aw)输入判别器dw得到dw(gw(x,p,aw));
4.3计算目标姿态图片y、生成图gw(x)和mask图片p的maskl1损失函数m(gw):
⊙指两个相同尺寸的矩阵之间的元素乘法,||*||1为1-范数;
4.4计算身份分类网络作为指导:
其中,cl指目标人物的身份类别标签,如果分类网络预测的类别标签和cl一致则qc=1,否则qc=0,p(gw(x,p,aw))分类网络的输出概率分布;
4.5计算对抗损失函数vw:
4.6整体生成网络,损失函数lw为:
lw=vw(dw,gw)+m(gw)+c(gw,cl)
4.7通过最小化损失函数lw来更新生成器gw;
4.8通过最大化对抗损失函数vw(dw,gw)更新判别器dw;
4.9返回步骤4.1继续更新,直至损失函数lw减低到可接受范围或者迭代次数达到要求,输出生成图片gw(x,p,aw)。
实施例二
如图3所示:本发明一种基于可形变结构的行人图像生成方法,具体包括以下步骤:
步骤一、通过分割操作和提取mask操作,将图片进行符合人体特征的先验处理;
步骤二、通过部位生成操作,生成不同的部位图片,分解复杂的全身姿态对应;
步骤三、通过结构化合并操作,将生成的部位图片组合起来,为全身的生成提供有力的指导;
步骤四、通过整体生成操作,在保留局部信息和身份信息的前提下,生成更真实可信的行人图像。
本发明提出基于可形变结构的行人图像生成方法,将行人图像生成的复杂问题分解为数个部位图片的姿态间转换问题,用分而治之的思路解决行人图像生成的问题。本发明降低了生成网络对于训练样本的数量需求,同时将更多的局部特征作为生成的指标,在高效的同时提高了生成图片的质量。下面对本发明实施例中基于可形变结构的行人图像生成的结构化合并操作进行详细说明。
如图5所示,为步骤三中本发明实施例中基于可形变结构的行人图像生成的结构化合并操作的示例性流程图,
3.1对于部位生成操作得到的3个生成部位图片,根据原图中不同部位的尺寸比例,将生成的部位图片进行缩放;
3.2根据原图中部位结构的位置关系,将缩放后的3个生成部位图片纵向合并为一张图片;
3.3根据合并图片边缘的平滑连接,将合并图片的3个生成部位图片进行位置微调,拼合成更加平滑整体的一张图片;根据合并图片的整体颜色和光照条件,调整合并图片的3个生成部位图片的颜色以及亮度权重,拼合成色彩均衡的一张图片。
如图6所示,本发明的一种基于可形变结构的行人图像生成装置,包括:
图像预处理模块:对于输入的原行人图片和目标姿态图片,分别对原行人图片和目标姿态图片按照部位结构进行分割操作和提取mask操作,得到三组预处理后的部位行人mask图、部位目标姿态mask图片、部位行人图片和部位目标姿态图片;
部位生成模块:对分割得到的部位行人图片用部位行人mask图片预处理,对部位目标姿态mask图片、部位行人图片和部位目标姿态图片,进行部位生成操作,得到三张部位生成图片;
结构化合并模块:对部位生成操作得到的三张部分生成图片进行结构化合并操作,得到一张结构化合并图片;
整体生成模块:将结构化合并图片、原图片和目标姿态作为输入,进行整体生成操作,得到一张最终的行人生成图片。
首先向图像预处理模块输入原行人图片和目标姿态图片,通过分割操作和提取mask操作,将图片进行符合人体特征的先验处理,得到三组预处理后的部位行人mask图、部位目标姿态mask图片、部位行人图片和部位目标姿态图片;对每一组部位行人图片和部位目标姿态图片,通过输入到部位生成模块,进行部位生成操作,生成不同的部位图片,分解复杂的全身姿态对应,得到三张不同部位的部位生成图片;对部位生成操作得到的三张部分生成图片,通过输入结构化合并模块,进行合并操作,将生成的部位图片组合起来,为全身的生成提供有力的指导,得到一张结构化合并图片;将结构化合并图片、原图片和目标姿态作为整体生成模块的输入,通过整体生成操作,在保留局部信息和身份信息的前提下,最终生成更真实可信的行人图像。
优选的,部位生成模块和整体生成模块均包含生成器和判别器。
生成器包括:
将多个输入图片进行第三个维度叠加的输入处理结构;
由多个卷积层串联组成的编码器;
由多个反卷积层串联组成的解码器;
通过编码器和解码器的对应层级网络直连组成的u型结构;
输出生成图片和生成损失的输出结构。
判别器包括:
将待判别图片和期望标签的输入处理结构;
由数个卷积层和全连接层组成的特征提取网络;
输出判别标签结果和判别损失的输出结构。
部位生成模块的生成器的损失函数为:
其中,
其中,
部位生成模块的判别器模块的判别函数为:
其中,
整体生成模块的生成器gw的损失函数为
lw=vw(dw,gw)+m(gw)+c(gw,cl)
其中,
其中,x为行人图片,y为目标姿态图片,p目标姿态mask图片,aw为合成照片,gw(x)为行人图片x输入生成器gw得到生成图,gw(x,p,aw)为行人图片x、目标姿态mask图片p、合并图片aw输入生成器gw得到生成图;dw(y)为目标姿态图片y输入判别器dw得到的判别结果,dw(gw(x,p,aw))为生成图gw(x,p,aw)输入判别器dw得到的判别结果,
整体生成模块的判别器gw的判别函数为:
其中,x为行人图片,y为目标姿态图片,p目标姿态mask图片,aw为合成照片,gw(x,p,aw)为行人图片x、目标姿态mask图片p、合并图片aw输入生成器gw得到生成图;dw(y)为目标姿态图片y输入判别器dw得到的判别结果,dw(gw(x,p,aw))为生成图gw(x,p,aw)输入判别器dw得到的判别结果,
以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!