面向政企服务大数据的智能派单方法与流程
本发明涉及大数据处理领域,尤其是涉及一种面向政企服务大数据的智能派单方法。
背景技术:
随着我国经济的不断发展,各种类型的企业不断涌现。然而,在当前政企服务过程中,政府相关职能部门常常需要挤出大量的时间来为企业办事人员解答政策、办事流程的询问,大量重复的询问使得政府职能部门人员苦不堪言。面对这种现状,政府职能部门一直思考如何更高效地服务好数量不断增多的企业。为了提高政企服务效率,各地政府不断开展企业办事流程网上咨询和预约业务。然而,企业咨询问题的数量庞大,咨询问题的类型众多,咨询内容纷繁复杂。现有的政企服务网上咨询系统往往需要设置专职人员手动地将数量庞大的企业咨询派送到相应的政府职能部门,这容易造成企业咨询的大量积压,极大地影响了政企服务网上咨询的效率。
为了提高政企服务网上咨询的效率,研究人员利用机器学习的方法对企业咨询文本进行分类,然后根据得到的类别将企业咨询派送到相应的政府部门。支持向量机是一种应用广泛的文本分类方法。为了达到较好的分类效果,技术人员往往需要对支持向量机的参数进行优化设计。正弦余弦算法是一种近年提出的有效优化方法(Mirjalili,S.(2016).SCA:a sine cosine algorithm for solving optimization problems.Knowledge-Based Systems,96,120-133.)。研究人员已利用正弦余弦算法来优化设计支持向量机的参数(朱静,何玉珠,崔唯佳.正弦余弦算法优化的SVM模拟电路故障诊断[J].导航与控制,2018,17(4):33-40.)。然而,传统正弦余弦算法在实践工程应用中容易出现搜索能力不足的缺点。
技术实现要素:
本发明的目的是提供一种面向政企服务大数据的智能派单方法。它在很大程度上减少了政企服务网上咨询派单的人工干预,可以智能高效地将企业咨询文本派送到对应的政府部门,本发明能够提高政企服务网上咨询派单的效率。
本发明的技术方案:一种面向政企服务大数据的智能派单方法,包括以下步骤:
步骤1,采集政企服务文本大数据;
步骤2,对政企服务文本大数据进行清洗,抽取出企业咨询文本及其被处理的政府部门,并将企业咨询文本的类别设置为其被处理的政府部门;
步骤3,将抽取出来的企业咨询文本进行文本特征提取,得到企业咨询文本的特征向量;
步骤4,将企业咨询文本的特征向量设置为企业咨询文本分类模型的训练数据集;
步骤5,利用局部搜索的正弦余弦算法来优化设计支持向量机的参数,并将优化设计得到的支持向量机设置为企业咨询文本分类模型;
步骤6,输入企业咨询文本;
步骤7,对企业咨询文本进行特征提取,得到相应的文本特征向量;
步骤8,将得到的文本特征向量输入到企业咨询文本分类模型,计算出企业咨询文本的类别;
步骤9,根据企业咨询文本的类别,将企业咨询文本派送到对应的政府部门;
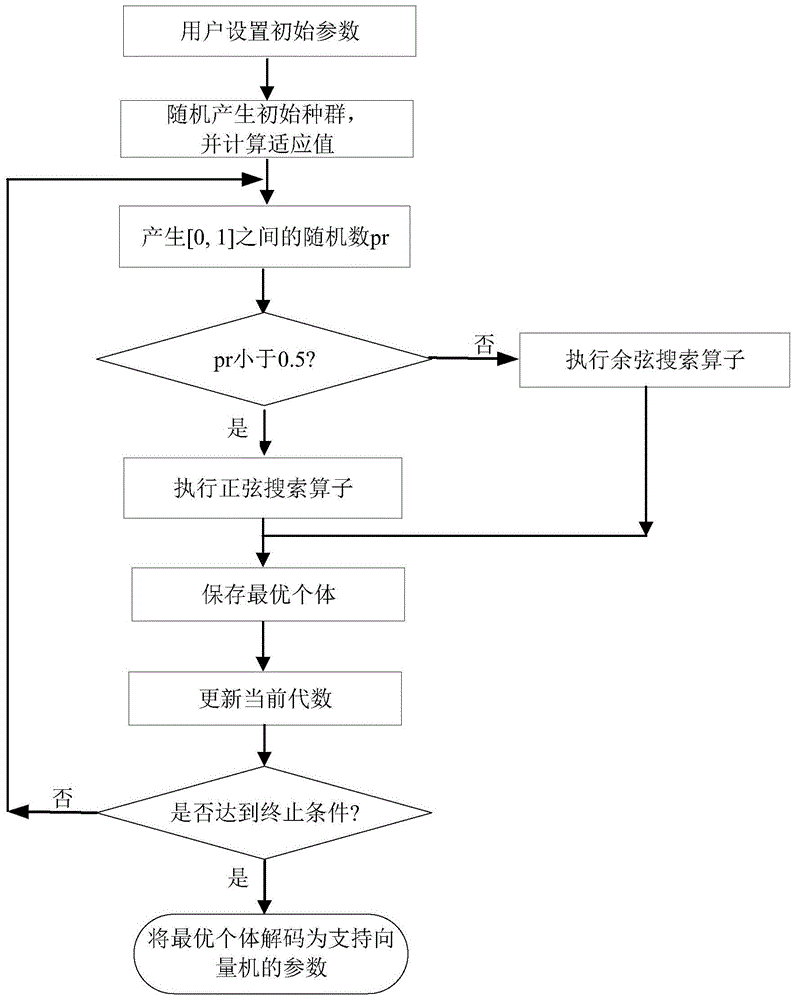
其中,步骤5所述的利用局部搜索的正弦余弦算法来优化设计支持向量机的方法包括以下步骤:
步骤5.1,初始化种群规模NS,然后设置最大演化代数MAXT;
步骤5.2,设置当前代数t=0;
步骤5.3,随机产生NS个个体组成初始种群,其中种群中的每个个体存储了支持向量机的惩罚因子C和径向基核参数g;
步骤5.4,计算种群中每个个体的适应度;
步骤5.5,保存最优个体gBXt;
步骤5.6,以0.5的概率对种群中的每个个体执行正弦搜索算子,同时也以0.5的概率对种群中的每个个体执行余弦搜索算子;
步骤5.7,从种群中随机选择出一个个体执行局部搜索操作,其中局部搜索操作按公式(1)进行:
其中为局部搜索得到的新个体,IXt和RXt为从种群中随机选择出来的两个不相等的个体,LS为搜索系数,sr为[0,1]之间的随机实数,exp为指数函数,log为对数函数;
步骤5.8,计算的适应度;
步骤5.9,如果的适应度小于RXt的适应度,则在种群中用替换RXt,否则保持RXt不变;
步骤5.10,保存最优个体gBXt,然后设置当前代数t=t+1;
步骤5.11,判断是否满足终止条件,如果不满足终止条件,则转到步骤5.6,否则转到步骤5.12;
步骤5.12,将种群中的最优个体解码为支持向量机的参数。
本发明基于优化的支持向量机从采集的政企服务大数据中训练文本分类模型,然后利用所建立的文本分类模型对新来的企业咨询文本进行确定类别,根据确定的类别将新来的企业咨询文本派送到对应的政府部门。本发明利用局部搜索的正弦余弦算法对支持向量机的参数进行优化设计,能够提升企业咨询文本的分类精度,从而提高政企服务网上咨询派单的效率。
附图说明
图1为本发明中局部搜索的正弦余弦算法的流程图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:
本实施例结合附图的图1所示,本发明的具体实施步骤如下:
步骤1,采集政企服务文本大数据;
步骤2,对政企服务文本大数据进行清洗,抽取出企业咨询文本及其被处理的政府部门,并将企业咨询文本的类别设置为其被处理的政府部门;
步骤3,将抽取出来的企业咨询文本进行文本特征提取,得到企业咨询文本的特征向量;
步骤4,将企业咨询文本的特征向量设置为企业咨询文本分类模型的训练数据集;
步骤5,利用局部搜索的正弦余弦算法来优化设计支持向量机的参数,并将优化设计得到的支持向量机设置为企业咨询文本分类模型;
步骤6,输入企业咨询文本;
步骤7,对企业咨询文本进行特征提取,得到相应的文本特征向量;
步骤8,将得到的文本特征向量输入到企业咨询文本分类模型,计算出企业咨询文本的类别;
步骤9,根据企业咨询文本的类别,将企业咨询文本派送到对应的政府部门;
其中,步骤5所述的利用局部搜索的正弦余弦算法来优化设计支持向量机的方法包括以下步骤:
步骤5.1,初始化种群规模NS=20,然后设置最大演化代数MAXT=50000;
步骤5.2,设置当前代数t=0;
步骤5.3,随机产生NS个个体组成初始种群,其中种群中的每个个体存储了支持向量机的惩罚因子C和径向基核参数g;
步骤5.4,计算种群中每个个体的适应度;
步骤5.5,保存最优个体gBXt;
步骤5.6,以0.5的概率对种群中的每个个体执行正弦搜索算子,同时也以0.5的概率对种群中的每个个体执行余弦搜索算子;
步骤5.7,从种群中随机选择出一个个体执行局部搜索操作,其中局部搜索操作按公式(1)进行:
其中为局部搜索得到的新个体,IXt和RXt为从种群中随机选择出来的两个不相等的个体,LS为搜索系数,sr为[0,1]之间的随机实数,exp为指数函数,log为对数函数;
步骤5.8,计算的适应度;
步骤5.9,如果的适应度小于RXt的适应度,则在种群中用替换RXt,否则保持RXt不变;
步骤5.10,保存最优个体gBXt,然后设置当前代数t=t+1;
步骤5.11,判断是否满足终止条件,如果不满足终止条件,则转到步骤5.6,否则转到步骤5.12;
步骤5.12,将种群中的最优个体解码为支持向量机的参数。
在步骤1中,所述政企服务文本大数据包括但不限于:企业的基础信息,工商、质监、食药监、边检、海关等部门数据,即工商信息、司法信息、行政许可、行政监督的文本格式数据。
在步骤2中,所述企业咨询文本包括但不限于:企业的知识产权、投资信息、融资信息、税务信息、企业填报信息、实地核查信息、税务信息,经营信息的文本格式数据。
在步骤3中,企业咨询文本的特征向量包括但不限于词频、词频逆向文件频率和Word2Vec任意一种方法提取的文本特征向量。
在步骤6中,所述企业咨询文本的数据可以包括但不限于:企业的投资信息、融资信息、税务信息、企业填报信息、实地核查信息、税务信息,经营信息的文本格式数据。
在步骤8和步骤9中,所述企业咨文本的类别可以包括但不限于:投资类别、融资类别、税务类别、经营类别、劳动类别。
在步骤9中,所述类别所对应的处理部门包括但不限于:投资类别对应的政府部门为招商部门;融资类别对应的政府部门为金融工作部门;税务类别对应的政府部门为税务部门;经营类别对应的政府部门为工商部门;劳动类别对应的政府部门为人力资源和社会保障部门。
在步骤5.11中,所述终止条件包括但不限于:当前代数大于最大演化代数。
- 还没有人留言评论。精彩留言会获得点赞!