面向数据空间的实体解析方法与流程
本发明涉及实体解析方法。
背景技术:
实体解析是指识别同一实体的不同描述形式的过程,旨在保障数据质量,是数据清理、数据集成及数据挖掘中的关键技术[1](vasilisefthymiou,kostasstefanidis,vassilischristophides.bigdataentityresolution:fromhighlytosomehowsimilarentitydescriptionsintheweb[c]//proceedingbigdata’15proceedingsofthe2015ieeeinternationalconferenceonbigdata,2015,11(1):401-410p)。在传统的实体解析工作中,大部分工作依赖于数据之间的模式或语义映射。数据空间是一种新的数据集成方式,它没有严格的数据模式及语义映射,而是根据主体的需求逐渐将数据纳入并建立关系,是一种异质数据集合,其特点是数据来自多个数据源[2](葛敬军,胡长军,刘歆.面向领域科学的虚拟数据空间共享模型[j].小型微型计算机系统,2014,35(3):514-519pgejingjun,huchangjun,liuxin.virtualdataspacesharingmodelfordomainscience[j].minicomputersystem,2014,35(13):514-519p)。在数据空间中进行实体解析时,就失去了实体解析的有力工具,语义映射。实体解析要对记录进行对比,对于不同领域的记录对,匹配概率很小,成对对比会浪费资源。
技术实现要素:
本发明的目的是为了解决现有在数据空间中进行实体解析时,要对记录进行对比,对于不同领域的记录对,匹配概率很小,成对对比会浪费资源的问题,而提出面向数据空间的实体解析方法。
面向数据空间的实体解析方法具体过程为:
步骤一、构建记录图:
步骤二、采用剪枝方法简化记录图;
步骤三、对剪化后的记录图进行分块处理;
步骤四、建立属性映射集群;
步骤五、计算属性映射集的优度;
步骤六、得到属性映射集群中各个映射集的优度后,在块内进行实体解析。
本发明的有益效果为:
本发明提出了分块技术[3](batyakening,avigdorgal.mfiblocks:aneffectiveblockingalgorithmforentityresolution[j].informationsystems,2013,38(6):908-926p),即利用一种代价较低的计算方法对数据进行预判,即可能属于同一实体的数据记录放在一个块中,仅在块内进行记录对比。解决了现有在数据空间中进行实体解析时,要对记录进行对比,对于不同领域的记录对,匹配概率很小,成对对比会浪费资源的问题。
本文面向数据空间对多源异质数据实体解析进行理论研究。考虑到即使在无语义映射下,指向同一实体的两条记录在其属性值上也有共同点,并且将记录之间的关系纳入计算,综合两者构建记录图。针对不同情况的记录集合,通过其适用的剪枝方法,简化记录图,并提出了根据剪枝后的记录图进行分块的算法。
在块内做实体解析时,利用属性值对属性做映射,通过获取块内整体数据记录的属性名所指代的信息,将块内与现有数据有共同值但仍不匹配的数据区分开来,并提出一种类似于正则表达式的方法,计算属性值的相似度,并对匹配记录的映射属性的属性值进行合并,以返回给用户一个较为全面的实体信息。
通过实验验证,本发明中所提出的方法对于实体解析有一定的正向推动作用。
附图说明
图1为本发明构建记录图流程图;
图2为本发明对记录图进行剪枝流程图;
图3为根据剪枝后的记录图进行分块流程图;
图4a为异质属性映射的数据图;
图4b为异质属性映射的全局属性映射图;
图4c为异质属性映射的属性映射集群的优度计算图;
图5a为在两个数据集上,两种方法随与之的变化情况图;
图5b为在两个数据集上,两种方法随与之的变化情况图;
图6为两种算法的实体生成对比图。
具体实施方式
具体实施方式一:本发明实施方式面向数据空间的实体解析方法具体过程为:
步骤一、构建记录图:
步骤二、采用剪枝方法简化记录图;
步骤三、对剪化后的记录图进行分块处理;
步骤四、建立属性映射集群;
步骤五、计算属性映射集的优度;
步骤六、得到属性映射集群中各个映射集的优度后,在块内进行实体解析工作,从而排除误纳入此块,指向其他实体的数据记录。
具体实施方式二:本实施方式与具体实施方式一不同的是,所述步骤一中构建记录图;具体过程为:
使用一种标签方法表示数据记录,将数据记录看做一个属性值集合;此时基于一种常识性假设[4]([4]s.prabhakarbenny,s.vasavidr,p.anupriya.hadoopframeworkforentityresolutionwithinhighvelocitystreams[j].procediacomputerscience,2016,85:550-557p),如果两个记录指向同一实体,则它们必然包含一些相同的属性值。并将数据记录间的关系计算在内,提高准确性[5](肖启华,陈珂,黄冬梅.考虑空间相关性的数据空间特征提取法方法[j].计算机仿真,2014,31(12):425-428,433pxiaoqihua,chenke,huangdongmei.dataspatialfeatureextractionmethodconsideringspatialrelevance[j].computersimulation,2014,31(12):425-428,433p)。利用一个记录图模型来表示数据空间中的记录结点及记录结点关系;通过计算两条记录之间的相似度,在两条记录之间画一条边,边权为相似度值。这种标签风格的分块方法,由于其表示方法简单,只需要获取记录的属性值,而不依赖固定的数据模式和强硬射的语义,所以在面对数据空间的异质数据集上,可以有着很强大的适用性。
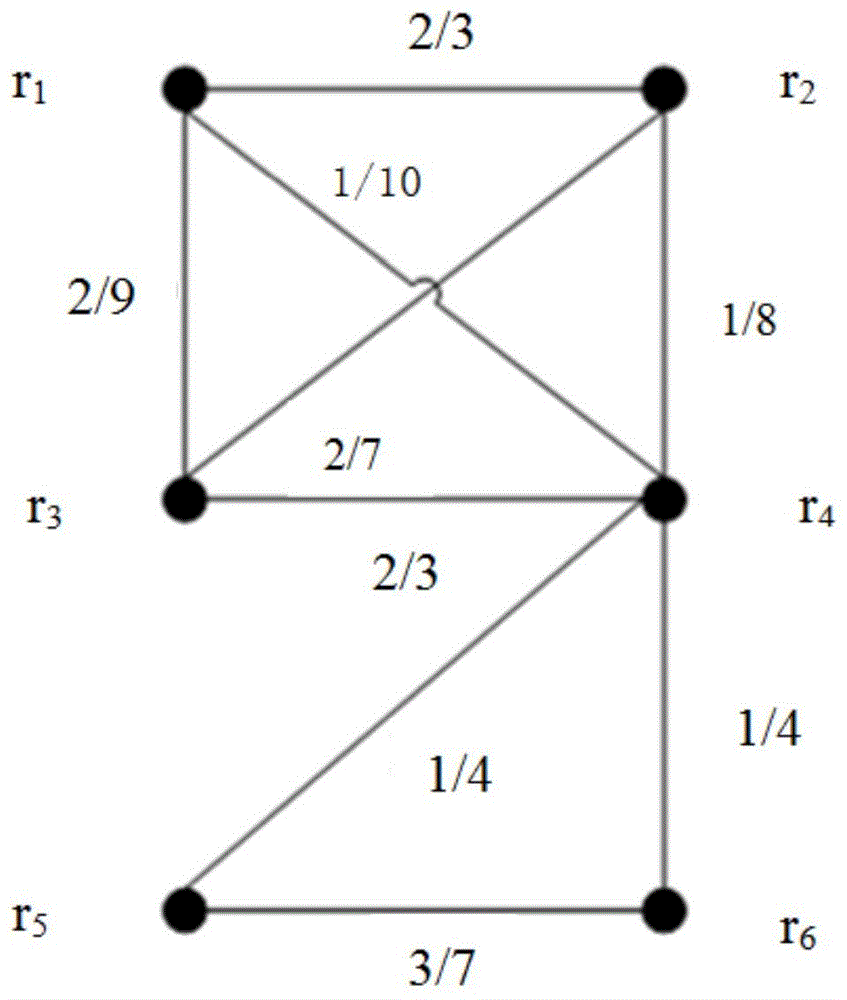
设有记录集合r={r1{fullname:tomlloydmalik;job:producer,actor;address:l.a.},r2{name:tommalik;producer;birthplace:l.a.},r3{label:mikestyles;profession:producer;place_of_birth:l.a.;place_of_birth:1964},r4{mikeharrystyles;birthplace:l.a.;gender:male},r5{fullname:harrygreen;address:los;sex:male;profession:writher},r6{label:harrygreen;gender:male;birthyear:1980;married}}。基于记录集合r的记录图分块方法概览如图1、图2、图3所示(为了简化示例图,图中记录集合暂不标记它们的关系)。
步骤一一、计算两条记录之间的相似度;
步骤一二、根据数据空间的记录和相似度构建记录图。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述步骤一一中计算两条记录之间的相似度;具体过程为:
标签转换函数tag()可以将一条记录转换为一个标签集(即tag:ri→t(ri))。计算两个集合交集与并集大小的比值,即可得到两条记录的标签相似度。
步骤一一一、计算标签相似度:
通过标签转换函数tag()将记录转为标签集合,计算两条记录的标签相似度,记为simtag(ri,rj):
其中,t(ri)为通过标签转换函数将记录ri转换成的规范化标签集;t(rj)为通过标签转换函数将记录rj转换成的规范化标签集;
步骤一一二、计算关系相似度:
整合了两条记录所具有的所有关系上的综合相似度,记为simrel(ri,rj):
其中,nbr(ri)表示与记录ri在rel关系上有连接的记录集合,nbr(rj)表示与记录rj在rel关系上有连接的记录集合,rel表示在记录r1、r2上出现的所有的记录关系集合,如合作关系,师生关系,教课关系等等;
步骤一一三、整合标签相似度和关系相似度,得出综合相似度sim(ri,rj):
sim(ri,rj)=α·simtag(ri,rj)+(1-α)·simrel(ri,rj)
其中,α表示标签相似度的权值。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是,所述步骤一二中根据数据空间的记录和相似度构建记录图;具体过程为:
给定一个数据空间的记录集合r,构建一个无向图g=(r,e),称之为记录图;
其中r为记录集合,代表数据空间中的记录;e为边集,两个记录之间存在一条边代表记录对的相似度。
记录图构建完成后,图内边权较小的记录对匹配概率较低,通过对记录图的边进行处理,减少不必要的记录对比较。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是,所述步骤二中采用剪枝方法简化记录图;具体过程为:
根据某种规则删除权值较小的边,即对图作剪枝操作,减少冗余的匹配次数。
为了便于接下来描述,给出点区域的定义。
定义4.点区域:一个记录r在记录图g中出现的形式为一个结点,此记录结点本身、与之有边的邻居记录和连接它们的边所构成的区域成为点区域。点区域为记录图g中的一个子图,记为gr={{r}∪rr,er}。其中,rr为与r有边相连的邻居结点所构成的集合,er为连接r与邻居结点的边所构成的集合。
剪枝过程主要有两个组成部分:剪枝中心与剪枝规则。
剪枝中心,可以分为两类:边中心化,通过遍历图的边集来选择全局最佳的待比较对,以此来筛选出不满足剪枝规则的边;结点中心化,它遍历图中所有的结点,旨在对于一个记录结点,在它的点区域,找到和它的最佳待比较对集——即,与此记录相连的边权最大的若干个记录。
剪枝规则,按照功能将其分为权重阈值和基数阈值。权重阈值指定了保留边的最小权值,删除所有低于此权值的边;基数阈值给出了图中保留边的最大边数,保留边权top-k的边。其中,基数阈值限定了待比较对的数量,适用于具有对时间资源有限制的应用。权值阈值根据记录对本身具有的匹配概率来决定是否修剪连接记录对的边,适用于看重有效性的应用程序。按照作用范围将剪枝规则分为全局阈值和局部阈值。全局阈值适用于整个图,也就是图中所有的边;而局部阈值适用于图的一个子集,即一个结点的点区域。
剪枝方法采用边中心化的基数剪枝、结点中心化的基数剪枝、边中心化的阈值剪枝或结点中心化的阈值剪枝中的一种;
(1)边中心化的基数剪枝:
全局基数阈值k指定了记录图要保留边的总数,保留k条权值最大的边;可以按照权值对边集降序排序,有效删除权值低的边。
(2)结点中心化的基数剪枝:
对于每个结点ri,保留连接结点ri的top-k权值(就是权值最大的k条边)的边;对于结点ri,记录结点ri的点区域gri={{ri}∪rri,eri}和当前记录结点的基数阈值kri,遍历子图中的边,保留权值top-k(与ri连接的共n条边,保留权值最高的k条边,其他的边删掉)边的同时删除其他连接ri的边;
其中,rri为与记录结点ri有边相连的邻居结点所构成的集合,eri为连接记录结点ri与邻居结点的边所构成的集合;点区域gri为记录图g中的一个子图;
一般来说,每个结点的基数阈值应取决于其点区域的边集大小(如kri=0.1×|eri|)。
(3)边中心化的阈值剪枝:
利用权重阈值在全局范围进行剪枝,选取最小边权wmin(实验得到),遍历图中所有边,将权值低于wmin的边删除;
它遍历了图中所有的边并删掉权值低于预设阈值wmin的边,保留图中剩余的边并输出。一般情况下,匹配记录之间的权值大于不匹配记录之间的权值,因此,选取wmin目标就是确定两者之间的平衡点。
(4)结点中心化的阈值剪枝:
对剪枝范围的选择,若采用全局阈值,则对记录图的所有结点采用一个统一的阈值,此时剪枝过程与边中心化的权值剪枝方案相同;若采用局部阈值,则可以根据用户需要,为特殊结点选取一个特定阈值,实质上,它将边中心化的权值剪枝应用在了结点ri的点区域上。与边中心化的阈值剪枝方案的主要不同为,它可以对于每个结点使用不同的阈值。它首先得到ri的点区域gri={{ri}∪rri,eri},然后根据输入的局部阈值标准指定了子图剪枝的最小边权;然后,遍历eri中的边,将权值小于设定阈值的边删除。
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是,所述步骤三中对剪化后的记录图进行分块处理;具体过程为:
剪枝后的图为g={r,e},r为记录集合,e为边集;
任取一个记录ri,创建一个块bi并将ri放置于bi中,若ri点区域中的结点rj与bi中所有结点均有边相连,则将rj放置于bi中,并删除rj与bi中所有结点的相连边,重复此操作直至遍历ri的所有邻居结点;此时,若bi中的结点在图中变成一个孤立的结点,无边与之相连,则从图中删除此结点;重复步骤三直至图g为空;此时,分块工作完成,得到块集合b={b1,b2,...,b|b|};
基于属性映射的记录对比与连接
经过分块,块内的记录信息包含大量重复的属性值,有助于对属性进行映射。通过观察全局数据的特点并作出语义映射的处理,可以发现其中一条或几条数据记录的信息有一些不同的地方,此时可以将这种记录划分出去以提高准确性。将匹配的记录信息整合,用户自取所需,可以缩减处理记录信息的时间。
异质属性的映射
实体解析中常用的方法是利用统一的属性来计算属性值相似度。但是在数据空间这种多源异质的环境下,没有准确的属性映射,所以可以反过来利用属性值来进行属性匹配。
实例化:一个实体记录由一组属性和值组成,而一个属性的值,可能存在错误拼写,或是空值。空值是无法进行比较的。如果一个实体由一个值不为空的属性所描述,则称这个属性实例化此实体。整个的属性语义映射过程如图4a、4b、4c所示。
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是,所述步骤四中建立属性映射集群;具体过程为:
步骤四一、对于来自不同实体的两个属性,计算属性的相似值:
1)属性名相似度(可以利用编辑距离或其他适合的字符串相似度量函数),记为sl,通过对比两个规范化后的属性名获得(根据数据集特点,可以规范大小写,扩展简称为全称);
可以根据数据集中,属性名相似度的大小,来决定是否将此部分纳入计算。
2)属性值相似度(两个属性,它们可能在不同的记录上有不同的值,如属性att1在记录集合上有3个值,属性att2在记录集合上有4个值,则选取att1和att2最相似的两个值作为两个属性的属性值相似度),记为sv,对比两个属性的所有值,并保留最高的相似度得分。
基于属性名相似度和属性值相似度方法得到属性匹配对,从属性匹配对集合中,通过计算得到属性匹配集,属性匹配集的集合称为属性匹配集群。
属性匹配集中的属性相互之间完全匹配。方法拒绝一个属性映射集包含许多松散相关的属性,且遵循广泛使用的无重复假设[6](imenmegdiche,oliverteste,cassiatrojahn.anextensiblelinearapproachforholisticontologymatching[c].iniswc,parti,vol.lncs9981.springer,kobe,japan,2016:393-410p),此时限制一个名称空间(一个实体,或一个有语义限制的数据源)下的每个属性最多可以匹配另一个名称空间下的一个属性,设置全局1:1的匹配约束[7](chunchengxiang,baobaochang,zhifangsui.anontologymatchingapproachbasedonaffinity-preservingrandomwalks[c]//proceedingijcai'15proceedingsofthe24thinternationalconferenceonartificialintelligence,2015:1471-1477p)。然而,全局1:1匹配约束下的属性映射集的推导不是一个简单的过程,因为一个属性经常涉及多于一个匹配的属性对,而简单地选择具有最高匹配概率估计的对可能会导致冲突。
将得到整个属性映射集群的过程称为全局属性映射,它将一个属性匹配对集合作为一个输入,返回一个属性映射集群。设i为命名空间数,j为匹配的属性匹配对数,对于两个不同的命名空间ns、nt,ns、nt下的属性数记为ms、mt,ns下的第a个属性,nt下的第b个属性分别记为pas、pbt,通过最大化所有匹配属性对的总匹配概率来优化整体属性匹配,以此满足全局1:1限制:
其中σ(pas,pbt)为属性对pas和pbt的匹配概率;θ(pas,pbt)为指示函数,当选择属性对pas、pbt来形成一个属性映射集时,函数值为1,否则为0。
对于由匹配属性对集合来形成属性匹配集群的算法1所示:
步骤四二、将属性匹配对集合按匹配概率降序排列(line2),按序处理,对于属性对pa、pb,如果属性映射集群n中没有分别包含pa、pb的属性映射集ni、nj,则向n中添加属性映射集{pa、pb}(line6-7);若属性映射集群n中包含pa的属性映射集ni且属性映射集群n中包含来自与pb同一命名空间的属性(一个数据源就是一个命名空间,如果不确定记录来自哪个数据源,则这个记录自己本身就是一个命名空间。与pb来自同一命名空间的属性,也就是说,这个属性与pb属于一个记录,是一个记录包括的两个属性。),删掉pa≈pb这个属性对(line8-9);否则(针对上述两个如果的否定,第一个如果是说,如果属性映射集群n中没有分别包含pa、pb的属性映射集ni、nj,第二个如果是说若属性映射集群n中存在包含pa的属性映射集ni且属性映射集群n中其中包含来自与pb同一命名空间的属性。否则就是这两种情况都不满足的情况。),合并ni、nj成为一个更大的属性映射集nk,将nk加入到n中,同时从n中删除ni、nj(line11-12);重复步骤四二直至j为空。
其它步骤及参数与具体实施方式一至六之一相同。
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,所述步骤五、计算属性映射集的优度;具体过程为:
此时,已经得到了属性映射集群。一个映射集内的所有属性,互相形成了语义映射,它们所对应的信息为一类信息。甄灵敏等人[8](甄灵敏,杨晓春,王斌等.基于属性权重的实体解析技术[j].计算机研究与发展,2013,50(suppl.):281-289pzhenlingmin,yangxiaochun,wangbin,etal.entityanalysistechnologybasedonattribute
weight[j].computerresearchanddevelopment,2013,50(suppl.):281-289p)认为,通过对一些重要的属性赋予更高的权值,也可以摒弃一些不重要的属性,来增加实体解析的准确性和效率。计算属性映射集的优度,对应上述的权值。在进行后续的实体解析时,进行加权计算,提高其准确性。
属性映射集的优度(good()):一个属性映射集,其中的属性名可能不同,但是对应一类信息。属性映射集所指向的一类信息,其对应的属性值信息的本身,对实体解析的帮助大小称为属性映射集的优度。
本发明通过以下三个方面计算属性映射集优度:
a、辨别性:
一个属性映射集,如果其值较为多变,跨度较大,对实体解析的帮助会很小。属性映射集对应的值,在相对较小范围内变化会对实体解析更有用。设r为记录集合,对于一个属性映射集ni,在r上定义一个辨别优度函数,记为discr(ni):
其中,val(r,ni)提取了记录在属性映射集里属性ci(属性映射集里的属性,来自不同的命名空间,通过计算,假设他们是指向同一类信息的。对这个映射集赋予权值,来增加实体解析的准确度,辨别性就是其中一种权值计算方法。如果这个映射集的属性,对应的属性值差异较大,则认为这个属性映射集的帮助较小,它们指向一类信息的概率也较低,要赋予较低的权值,以免影响准确度。)上的属性值,norm()为对不同来源的属性值进行规范化;u为并集符号;
b、丰富性:
属性映射集所具备的值越多,为实体解析提供的信息越丰富,也就是说,一个记录在此属性映射集上的属性,其值不为空,对实体解析有益。设r为记录集合,对于一个属性映射集ni,在r上定义一个丰富优度函数,记为abund(ni):
此时有
辨别性和丰富性进行加和,从大到小进行排序,按从大到小的顺序计算多样性;
c、多样性:
为了增加多样性,并减少不同属性映射集之间的重复,对于存在冗余信息的属性映射集,可以减少其优度。每选择一个属性映射集,需要将它与之前确定选择使用的映射集进行比较,如果它的信息和之前的映射集产生了大量的重复,则降低其多样性。设ni为当前的映射集,nselected为已经选择的映射集群;对于给定nselected,ni的多样性记为div(ni|nselected):
其中,si表示由ni实例化的记录集合(如果对于属性映射集ni,其中有{att1,att2,...,attn}共n个属性,若记录r包含其中一个属性,并这个属性值不为空,则称属性映射集ni实例化了这个记录r。),即
通过两步来结合优度。第一步合并辨别性和多样性,它们反映了一个属性映射集的静态优度,对属性映射集的静态优度降序排步结合多样性来更新优度。第二步结合多样性来更新优度。设n为排序的属性映射集群,对于一个映射集ni∈n,映射集ni整体优度为good(ni):
comb(ni)=α·discr(ni)+(1-α)·abund(ni)
其中,α为辨别性优度的权值,γ为为静态优度的权值,0≤α,γ≤1;comb(ni)为静态属性集优度,合并了辨别性和丰富性。
其它步骤及参数与具体实施方式一至七之一相同。
具体实施方式九:本实施方式与具体实施方式一至八之一不同的是,所述步骤六中得到属性映射集群中各个映射集的优度后,在块内进行实体解析工作,从而排除误纳入此块,指向其他实体的数据记录;计算过程如下:
有记录对ri、rj,此时ri有m个属性,rj有n个属性,其中,通过映射的属性有p个,且p≤min(m,n),映射的属性为{att1,att2,...,attp},ri与rj的相似度为:
其中,nl为属性映射集,simcontent(ri.attl,rj.attl)为ri、rj两条记录映射属性的属性值相似度;attl为一个属性映射集所对应的属性,此映射集包含了ri与rj中某一属性的映射;将两条记录的相似度与预先设定的阈值λ相比较,若大于阈值λ,则认为匹配;由于按序处理,所以,当记录对匹配时,合并为一条新记录,新记录涵盖原记录对的信息;simcontent()的计算方法和整合过程在下面进行详细描述。
所述simcontent(ri.attl,rj.attl)的具体求解过程为:类正则表达式的记录信息整合
在记录的合并过程中,可以利用一种类似于正则表达式方法来对信息来进行合并,因为这种信息合并和正则表达式有一些相似之处,都是对一类信息确定一个规律。合并记录对时,映射属性的两个值合为一个类正则表达式。
类正则表达式概念
由于映射的属性其值有相似性,可以对相同部分进行统一,不同部分进行保留,以此形成一个类正则表达式,可以有效合并匹配信息。
类正则表达式(similartoregularexpression,stre):设∑为一个字母表,ε为空字符。一个类正则表达式stre=s[1]s[2]...s[n]。其中对于任意i(1≤i≤n),元素s[i]={ci,1,ci,2,...,ci,ni},对于j(1≤j≤ni),ci,j∈∑∪{ε}。以下将类正则表达式简称为表达式。
r为属性值对,s为根据属性值对衍生出的表达式,g为s实例化的集合,此时r∈g。如类正则表达式{t,n}ight可以实例化出tight和night。
一个属性值的表达式为其值本身。而由两个属性值合并而成的表达式,或一个属性值和一个表达式合并而成的类正则表达式则需要进行推理计算。
(1)、计算类正则表达式的相似度;具体过程为:
一个属性值的表达式为本身,计算两个表达式相似度,可以利用编辑距离;记编辑距离函数为d(i,j),i、j分别表示两个字符串a与b的长度,采用动态规划来计算编辑距离;得出字符串间的编辑距离相似度函数simedit(a,b):
计算一个表达式和一个属性值的相似度,或者两个表达式的相似度,与编辑距离相似。由于表达式中可能存在多个元素或空字符,所以对编辑距离函数稍加改动,改动原则如下:(1)对于多个字符,如果两个表达式元素中含有相同字符,则表达式元素匹配;(2)对于空字符,如果不匹配,包含空字符的表达式元素取空字符,此时不占长度,对编辑距离无影响。
通过这个以上原则得出两个表达式的最小编辑距离;表达式s1、s2的编辑距离d(|s1|,|s2|)如下:
s[i]代表表达式的第i个元素,s1[i]表示表达式s1的第i个元素,s2[j]表示表达式s2的第j个元素,且有初始条件:
其中,函数mu对应原则(1),只要表达式元素间含有相同的字符,则匹配;原则(1)对于多个字符,如果两个表达式元素中含有相同字符,则表达式元素匹配;
函数nu对应原则(2),表达式元素中若存在空字符,则直接将其忽略,不对编辑距离的计算产生影响,可以维持编辑距离最小;原则(2)对于空字符,如果不匹配,包含空字符的表达式元素取空字符,此时不占长度,对编辑距离无影响。最后两个表达式的编辑距离为d(|s1|,|s2|);
此时,表达式间的编辑距离相似度为simedit(s1,s2):
其中,simedit(s1,s2)即为simcontent(),s1与s2为函数simcontent(ri.attl,rj.attl)中的两个属性值attl;
在对比合并过程中,将记录的属性值看做一个个表达式进行计算,对比计算完成后,根据表达式生成属性信息。
(2)、类正则表达式的生成
根据两个表达式生成新的表达式,原则是引入最少的无关示例。例如,属性值对cutekid和cutkind,则可以有表达式s1=cut{e,ε}ki{d,n}{d,ε},s1可得到8个实例,引入了6个无关实例,也可以有表达式s2=cut{e,ε}ki{n,ε}d,可得到4个实例,引入2个无关实例。所以s2优于s1。
本发明利用表达式的编辑距离矩阵m,从m[|s1|,|s2|]出发,一直回溯到m[0,0],即可得到表达式的表达式,生成规则如下所示:
特别地
其中,k为回溯过程中的某一位置,s[k]为当前位置的元素,当i=j=0时回溯结束;此时,表达式s1、s2合并成类正则表达式为s=...s[k]...s[0](其中k按回溯的顺序倒序排列)。且在生成的三个条件同时满足的情况下,函数mu的优先级高于函数nu。此时有助于相同字符的合并,减少无关实例的引入。nu(s2[j])为表达式s2的第j个元素对应的函数,nu(s1[i])为表达式s1的第i个元素对应的函数,mu(s1[i],s2[j])为表达式s2的第j个元素和表达式s1的第i个元素对应的函数;
用一个例子来说明类正则表达式的相似度计算以及生成过程。设属性值attvalue1=“cutekid”,attvalue2=“cutkind”。而这对应的表达式分别为s1=cutekid,s2=cutkind。此时可根据类正则表达式的生成公式得到距离矩阵,如表1所示。
表1类正则表达式的相似度计算与生成矩阵
其中矩阵中的每个值m[i,j]表示s1前i个元素与s2前j个元素的编辑距离,由于此时表达式为属性值本身,所以表达式的编辑距离等于属性值的编辑距离。s1与s2的编辑距离为m[7,7]=2,表达式相似度为1-2/7=5/7。假设此时两条记录的相似度超过了阈值,被确认匹配,则需要合并两个属性值。根据表达式的生成规则,在表达式矩阵m的基础上,从m[7,7]开始回溯。m[7,7]=m[6,6]+mu(s1[6],s2[6]),所以回溯到m[6,6]的位置,以此类推回溯。回溯路径在表1中加粗标记。最后得到表达式cut{e,ε}ki{ε,n}d。
(3)、实体信息的生成
在块处理结束后,对于属性映射集中的属性值,经过一步步的记录对比与信息合并生成,最后得到一个属性映射集的最终的表达式。可以在类正则表达式的生成过程中记录每一个元素出现的频数,利用这个带频数的类正则表达式,在每个类正则表达式元素中选取出现频数最大的字符作为该元素的值,最后生成一个出现频率最高的字符串作为该属性映射集的属性值。如三个属性值mikedoe、m.doe、miked.,得到表达式m{i:2,.:1}{k:2,ε:1}{e:2,ε:1}d{o:2,.:1}{e:2,ε:1},最后根据频次得到属性值mikedoe。
这种类正则表达式,对于由于排版、拼写等原因造成错误字符,这种错误字符出现频次必然要少于正确拼写的字符,所以取频次最大的字符有助于过滤噪声。
其它步骤及参数与具体实施方式一至八之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本实施例具体是按照以下步骤制备的:
实验数据集
分块实验使用两个数据集,简称为d1和d2。d1抽取自dbpedia与imdb所共有的电影信息数据集。d2抽取自两个版本的dbpedia所构成的数据集[9](georgepapadakis,jonathansvirsky,avigdorgal,themispalpanas.comparativeanalysisofapproximateblockingtechniquesforentityresolution[j].proceedingsofthevldbendowment,2016,9(9):684-695p)。其中d1有50796条记录,包含22403个实体,d2包含335479条记录,共有89258个实体。
实验评价标准
本文采用采用的评价标准[10](chiragnagpal,kylemiller,benediktboecking,arturdubrawski.anentityresolutionapproachtoisolateinstancesofhumantraffickingonline[j].computerscience,2017,3(18):10-18p):
分块标准:对完整性(pc),消减率(rr),f值(f=2×pc×rr/(pc+rr));
解析标准:准确率(p)、召回率(r)和f值(f=2×p×r/(p+r))。
分块方法的实验分析
在分块过程中,本发明描述了四种剪枝方法,将计算记录相似度的参数α设置值为0.6,然后进行剪枝:对于边中心化的阈值剪枝方案(ecwp),在数据集上阈值wmin分别取0.6,0.5时,f值最高;对于结点中心化的阈值剪枝方案(ncwp),实验基于一种平均分布假设,使用统一的权值阈值,执行过程及阈值与ecwp相同;对于边中心化的基数剪枝方案(eccp),在剪枝时,需要保留共k条边,k随总数|e|而变化,取k=0.5*|e|时,在两个数据集上f值均达到最高;对于结点中心化的基数剪枝方案(nccp),剪枝过程中,对每个结点ri所连接的边,保留kri条,此时仍基于平均分布假设,取kri=0.5*|eri|时,其f值均达到最高。此时,对于四种剪枝方法,取其表现最优的阈值,进行对比,如表2所示。
表2剪枝方法在两个数据集上的pc、rr值
可以看出:边中心化的剪枝方法剪掉了更多无用的记录对,着重效率,适合规模较大的实体解析任务,尤其在匹配实体较少的预期情况下;而对于结点中心化的剪枝方法,保留更多的匹配记录对。边中心化的算法保留了权值为top-k或权值大于预设阈值的边,而结点中心化算法确保每个结点都与其最相似的记录相连,更适用于注重准确性的应用;权值阈值算法保留了相似度较高的记录对,保证了算法的准确性;基数阈值控制了待比较记录对的数量,保留了权值top-k的边,会对准确性有影响,但对方法效率有保证。
整体的准确性均保持在97%以上,缩减率也保持在60%以上,说明对块图进行剪枝,对撇弃一定量的无用记录对,在一定程度上保证了算法效率。
属性映射与表达式的实验分析
在计算属性集群的映射优度时,实验将参数值设为α=0.5,λ=0.4。选取最短距离法进行结果对比。对两个阶段进行结果测评:一是实体解析的结果,而是真实实体信息的生成。
对于实体解析的结果,两种方法的准确率、召回率如图5a、5b所示。可以看出,随着阈值的上升,召回率下降,准确率大幅上升。在两个数据集上,阈值取0.6时,本文方法均达到了较高的f值。方法在两个数据集上,两种方法的召回率差别不大,而本文基于属性映射和类正则表达式的处理方法使得召回率稍佳。准确率明显好于基于最短距离的方法,准确率更高。表明本文的方法更适应数据空间的记录特点。而最短距离较依赖数据的语义,在语义性较强的环境下,能发更大的作用。
对于实体信息的生成阶段,大部分实体解析工作的重点在于解析结果,而对实体信息和合并与实体的生成关注不高。利用数据集d1,在其上的生成实体数与实际实体数如图6所示。利用实体解析过程中产生的最佳阈值进行实体生成。从图中可以看出,本文解析结果更准确,生成实体数与真实实体数目较接近。但是其准确率仍明显高于最短距离法。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!