基于改进曼彻斯特编码的多叉查询树RFID防碰撞方法与流程
本发明属于射频识别技术领域,具体涉及一种基于改进曼彻斯特编码的多叉查询树rfid防碰撞方法的设计。
背景技术:
射频识别(radiofrequencyidentification,rfid)是一种非接触自动识别技术,具有成本低、功耗低、存储量大、穿透性强、多目标识别等优点,已经在物流、军事、交通、旅游、医疗等领域得到广泛的应用,典型的rfid系统通常由电子标签、阅读器和后台服务器三部分组成,由于阅读器和标签共享同一个无线信道,当多个标签同时向同一个阅读器发送数据,就会相互干扰,这就是标签碰撞问题,由于标签能量有限,计算、处理、存储能力较弱,很多传统的方法都不能用于解决标签防碰撞问题。
现阶段的防碰撞算法主要是基于时分多路算法,可分为两类:基于aloha的概率性算法和基于二进制树的确定性算法,aloha算法相对简单,但存在随机性大、效率不高、性能不稳定等问题,并且存在由于标签长时间内不被识别而引起的“饥饿”问题;树形算法是确定性算法,在标签数量较大的情况下,存在搜索时延较长,搜索效率较低等问题。
经典的树形防碰撞算法主要有:基本二进制搜索树(binarysearch,bs)算法、动态二进制搜索树(dbs)算法,查询树(querytree,qt)算法、碰撞树(collisiontree,ct)算法、跳跃式动态搜索树(umpinganddynamicsearching,jds)算法、基于搜索树的增强型rfid防碰撞(enhancedalgorithmbasedonsearchtree,ebst)算法、自适应修剪枝查询树(adaptivealgorithmbasedon4-arypruningquerytree,a4pqt)算法等。这些算法通过二叉树轮询方式对标签进行遍历,不存在标签“饥饿”问题,可以百分之百识别标签。
在树形搜索过程中,阅读器发出搜索命令,符合搜索条件的标签返回数据给阅读器,搜索时隙可分为以下几种情况:
(1)识别时隙:仅一个标签返回数据,阅读器可以直接识别标签。
(2)空闲时隙:没有任何一个标签返回数据,这个时隙被浪费了,因此应当尽量减少或避免空闲时隙。
(3)碰撞时隙:有两个或两个以上的标签同时返回数据,即发生了碰撞,阅读器不能识别任何标签。
(4)查询时隙:在该时隙内,阅读器为了知道标签某几位的具体数值,而对这几位数据进行查询,标签返回的数据通常是对应数据位的映射码,主要用于多叉树搜索中,查询时隙增加了搜索时间,因此应当尽量减少或避免。
二叉树搜索可避免空闲时隙和查询时隙,但具有较多的碰撞时隙,导致标签搜索次数多,搜索时延长。为了减少搜索总时隙,提高搜索速率,很多学者对多叉树进行了研究,但多叉树算法存在空闲时隙,通过查询碰撞位的方法可以减少或避免空闲时隙,但却增加了查询时隙。
树形搜索算法通常是通过曼彻斯特编码来准确检测碰撞位,曼彻斯特编码也叫相位编码,其编码方式是通过电平的改变来表示数值位,每一位的中间有一个跳变,从低到高跳变表示‘0’,从高到低跳变表示‘1’,即由电平“01”表示数据位‘0’,由电平“10”表示数据位‘1’,由于每一位都被调制成两个电平,数据传输速率只有调制速率的50%。
曼彻斯特编码可以准确检测碰撞位,广泛应用于rfid防碰撞算法中。实际上,上述树形防碰撞算法都是采用曼彻斯特编码来检测碰撞位,难以同时减少碰撞时隙、空闲时隙、查询时隙和数据通信量,搜索总时隙较多,识别效率较低,总的效果不太理想。
技术实现要素:
本发明的目的是提出一种基于改进曼彻斯特编码的多叉查询树rfid防碰撞方法,能够准确检测碰撞位并实现任意叉树的多叉树搜索,能够减少碰撞时隙,完全避免空闲时隙,没有查询时隙,不增加数据通信量,进而提高标签搜索的效率。
本发明的技术方案为:基于改进曼彻斯特编码的多叉查询树rfid防碰撞方法,包括以下步骤:
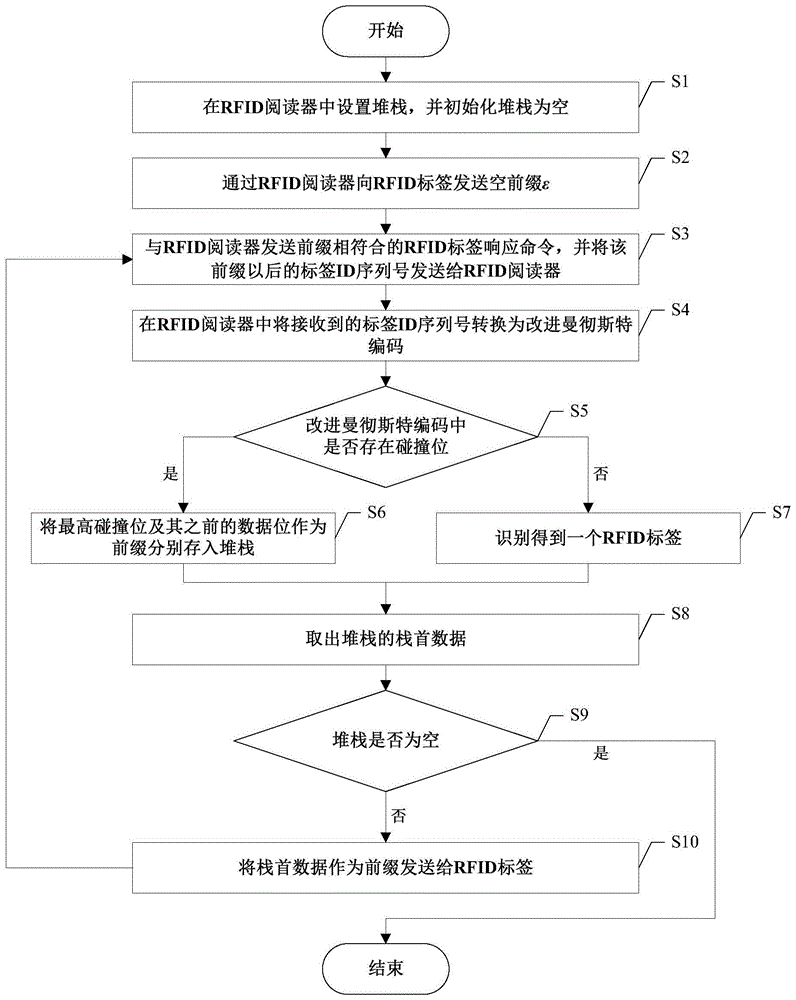
s1、在rfid阅读器中设置堆栈,并初始化堆栈为空。
s2、通过rfid阅读器向rfid标签发送空前缀ε。
s3、与rfid阅读器发送前缀相符合的rfid标签响应命令,并将该前缀以后的标签id序列号发送给rfid阅读器。
s4、在rfid阅读器中将接收到的标签id序列号转换为改进曼彻斯特编码。
s5、判断改进曼彻斯特编码中是否存在碰撞位,若是则进入步骤s6,否则进入步骤s7。
s6、将最高碰撞位及其之前的数据位作为前缀分别存入堆栈,进入步骤s8。
s7、识别得到一个rfid标签,进入步骤s8。
s8、取出堆栈的栈首数据。
s9、判断堆栈是否为空,若是则结束流程,否则进入步骤s10。
s10、将栈首数据作为前缀发送给rfid标签,返回步骤s3。
进一步地,堆栈用于存储每次搜索的最高碰撞位数据,并且按先进后出的原则存取数据。
进一步地,改进曼彻斯特编码的编码方式具体为:
改进曼彻斯特编码可实现多进制编码,m进制的改进曼彻斯特编码的任意一个数据位分为m个等间隔的时隙,其中m-1个时隙为低电平,1个时隙为高电平,最低时隙位为高电平表示m进制的码元“0”,次低时隙位为高电平表示m进制的码元“1”…最高时隙位为高电平表示m进制的码元“m-1”,m为大于或等于2的整数。
进一步地,步骤s4中将标签id序列号转换为改进曼彻斯特编码的公式为:
a0*m0+a1*m1+...+ah-1mh-1=b0*20+b1*21+...+bl-1*2l-1
其中ah-1…ai…a1a0表示长度为h的m进制改进曼彻斯特编码,bl-1…bj…b1b0表示长度为l的二进制标签id序列号,ai∈{0,1,...,m-1},bj∈{0,1},i=0,1,2,...,h-1,j=0,1,2,...,l-1。
进一步地,步骤s5中判断改进曼彻斯特编码中是否存在碰撞位的具体方法为:
当rfid阅读器作用范围内全部或部分rfid标签同时发送标签id序列号数据时,判断其转换成的改进曼彻斯特编码中某一码元是否有两个或两个以上的高电平,若是则存在碰撞位,否则不存在碰撞位。
本发明的有益效果是:本发明能够减少碰撞时隙,完全避免空闲时隙,没有查询时隙,从而有效减小了rfid标签搜索的总时隙,减小了通信数据量,提高了识别效率,提高了识别速度,优于现有的rfid防碰撞算法;此外,本发明对标签消耗的能量较少,不需要标签具有记忆功能,不需要标签具有复杂的计算和处理能力,便于rfid系统防碰撞方法的实现和应用,不仅具有重要的理论价值,也具有较大的实用价值,具有广阔的发展前景。
附图说明
图1所示为本发明实施例提供的基于改进曼彻斯特编码的多叉查询树rfid防碰撞方法流程图。
图2所示为本发明实施例提供的改进曼彻斯特编码碰撞位检测示意图。
图3所示为本发明实施例提供的总时隙数仿真示意图。
图4所示为本发明实施例提供的搜索效率仿真示意图。
图5所示为本发明实施例提供的通信时延仿真示意图。
图6所示为本发明实施例提供的搜索效率对比示意图。
具体实施方式
现在将参考附图来详细描述本发明的示例性实施方式。应当理解,附图中示出和描述的实施方式仅仅是示例性的,意在阐释本发明的原理和精神,而并非限制本发明的范围。
本发明实施例提供了一种基于改进曼彻斯特编码的多叉查询树rfid防碰撞方法,如图1所示,包括以下步骤s1~s10:
s1、在rfid阅读器中设置堆栈,并初始化堆栈为空。
堆栈用于存储每次搜索的最高碰撞位数据,并且按先进后出的原则存取数据。
s2、通过rfid阅读器向rfid标签发送空前缀ε。
s3、与rfid阅读器发送前缀相符合的rfid标签响应命令,并将该前缀以后的标签id序列号发送给rfid阅读器。
s4、在rfid阅读器中将接收到的标签id序列号转换为改进曼彻斯特编码。
本发明实施例中,提出一种改进曼彻斯特编码,其编码方式具体为:
改进曼彻斯特编码可实现多进制编码,m进制的改进曼彻斯特编码的任意一个数据位分为m个等间隔的时隙,其中m-1个时隙为低电平,1个时隙为高电平,最低时隙位为高电平表示m进制的码元“0”,次低时隙位为高电平表示m进制的码元“1”…最高时隙位为高电平表示m进制的码元“m-1”,m为大于或等于2的整数。
例如,4进制的改进曼彻斯特编码,时隙电平“0001”表示4进制的“0”,“0010”表示“1”,“0100”表示“2”,“1000”表示“3”。由此可以看出,改进曼彻斯特编码是对现有曼彻斯特编码的扩展,当m=2时,二进制的改进曼彻斯特编码就是现有的曼彻斯特编码。
因此步骤s4中将标签id序列号转换为改进曼彻斯特编码的公式为:
a0*m0+a1*m1+...+ah-1mh-1=b0*20+b1*21+...+bl-1*2l-1(1)
其中ah-1…ai…a1a0表示长度为h的m进制改进曼彻斯特编码,bl-1…bj…b1b0表示长度为l的二进制标签id序列号,ai∈{0,1,...,m-1},bj∈{0,1},i=0,1,2,...,h-1,j=0,1,2,...,l-1。
s5、判断改进曼彻斯特编码中是否存在碰撞位,若是则进入步骤s6,否则进入步骤s7。
由于m进制的改进曼彻斯特编码中的每一个码元都有且仅有一个高电平,因此当rfid阅读器作用范围内全部或部分rfid标签同时发送标签id序列号数据时,判断其转换成的改进曼彻斯特编码中某一码元是否有两个或两个以上的高电平,若是则存在碰撞位,否则不存在碰撞位。
碰撞数据位的表示方法:以4进制的改进曼彻斯特编码为例:某数据位发生碰撞,该接收数据位可用x0123的形式来表示:x表示该数据位为碰撞位,下标表示同时收到改进曼彻斯特编码:“0”、“1”、“2”和“3”。同理,x023表示该数据位是同时收到“0”、“2”、“3”的碰撞位。
例如,如果同时接收到4进制的改进曼彻斯特编码:“3”和“0”,“3”由电平“1000”表示,“0”由电平“0001”表示,则接受到的数据电平为“1001”,在一个码元出现两个高电平,可判断发生了碰撞,并把接收到的该碰撞位数据记为:x03,表示同时收到改进曼彻斯特编码“0”和“3”。
假设有4个标签,二进制id分别为:“01011011”、“11010001”、“00010111”、“10010011”,对应的4进制改进曼彻斯特编码分别为:“1123”、“3101”、“0113”、“2103”,利用改进曼彻斯特编码,rfid阅读器可以准确的检测出碰撞位,如图2所示。由图2可以看出,接收到的数据共有3位改进曼彻斯特编码数据发生碰撞,可以表示为:x01231x012x13。
s6、将最高碰撞位及其之前的数据位作为前缀分别存入堆栈,进入步骤s8。
s7、识别得到一个rfid标签,进入步骤s8。
s8、取出堆栈的栈首数据。
s9、判断堆栈是否为空,若是则结束流程,否则进入步骤s10。
s10、将栈首数据作为前缀发送给rfid标签,返回步骤s3。
本发明的基本设计思想是通过树形搜索,逐渐缩小搜索范围,直到识别出rfid标签。改进曼彻斯特编码可以准确的测知某个碰撞位的具体数据,当检测到发生碰撞时,可以根据最高碰撞位把检测标签分为几个子集,通过堆栈存取前缀,依次搜索每一个子集,如果有碰撞,再根据最高碰撞位把该子集往下分裂成几个更小的子集,如果无碰撞,则识别出一个标签,再弹出堆栈数据,继续其它子集的搜索,依次类推,直到识别出所有的标签。
下面以4进制改进曼彻斯特编码为例对本发明的具体实现过程进行进一步描述。
假设rfid阅读器作用范围内有8个rfid标签,标签id二进制数据位为10位,则其4进制改进曼彻斯特编码为5位,如表1所示。
表1标签及其id序列号
本发明的过程如表2所示,8个rfid标签,总时隙只有6次。在第2次、第5次、第6次搜索时隙中,只有一个碰撞位,可直接识别多个标签。值得注意的是:4进制改进曼彻斯特编码并未增加数据通信时间,实际上,标签发送相同的id数据,4进制改进曼彻斯特编码和现有曼彻斯特码的通信时间相同,但基于4进制改进曼彻斯特编码的查询树防碰撞方法却大大减少了总的识别时间。
表2本发明搜索过程
可以看出,本发明简单高效,在整个算法过程中,rfid标签并未涉及复杂的计算和处理过程,而这正好符合rfid防碰撞算法的要求:算法尽可能的简单,不需要标签有太高的计算、存储能力。
下面利用matlab软件对本发明提供的基于改进曼彻斯特编码的多叉查询树rfid防碰撞方法进行仿真,仿真条件为:标签数:10个、40个、70个、100个,标签二进制id位数:96位,多叉树为2-10叉树,时钟频率:96khz,仿真100次取平均值。
图3为本发明总时隙数仿真图,可以看出:
(1)标签数量对总时隙数的影响:标签数量越多,总时隙数越大。当标签数量较多时,随着叉树的增多,总时隙数下降较明显;当标签数量较少时,随着叉树的增多,总时隙数下降比较平缓。
(2)不同叉树对总时隙数的影响:叉树越大,总时隙数越少,随着叉树的增多,总时隙下降由明显趋向缓和。
在标签数量为100时,二叉树rfid防碰撞方法的总时隙数为199,10叉树rfid防碰撞方法的总时隙数为131,和基于现有曼彻斯特码的二叉树算法相比,基于10进制改进曼彻斯特编码的10叉树rfid防碰撞方法的总时隙数减少了68个,总时隙数下降了34.1%。
图4为本发明搜索效率仿真图,可以看出:
(1)标签数量对搜索效率的影响:标签数量对搜索效率影响不大。
(2)不同叉树对搜索效率的影响:搜索效率随着叉树的增大而增大,但随着叉树的增大,搜索效率增大趋缓。
在标签数量为100时,二叉树rfid防碰撞方法的吞吐率为50.3%,10叉树rfid防碰撞方法的吞吐率为76.3%,和基于现有曼彻斯特码的二叉树算法相比,基于10进制改进曼彻斯特编码的10叉树rfid防碰撞方法的搜索效率提高了51.9%。
图5为本发明通信时延仿真图,可以看出:
(1)标签数量对通信时延的影响:标签数量越大,通信时延越长。在标签数量较大时,通信时延随着叉树的变化而显著变化,在标签数量较小时,通信时延对叉树变化不敏感,变化相对比较稳定。
(2)不同叉树对通信时延的影响:在不大于10叉树的rfid防碰撞方法中,基于曼彻斯特编码的二叉树rfid防碰撞方法具有最大的通信时延,基于4进制改进曼彻斯特编码的4叉树rfid防碰撞方法具有最小的通信时延,4叉树以后,随着叉树的增多,通信时延逐渐增大。
在标签数量为100时,二叉树rfid防碰撞方法的通信时延为200ms,4叉树rfid防碰撞方法的通信时延为160ms,和基于现有曼彻斯特码的二叉树算法相比,基于4进制改进曼彻斯特编码的4叉树rfid防碰撞方法的通信时延减少了40ms,通信时延下降了20%。
在rfid防碰撞算法中,搜索效率是一个非常重要的指标,图6是4叉树rfid防碰撞方法和其他现有算法搜索效率对比图,由图6可见,4叉树rfid防碰撞方法具有最高的搜索效率,搜索效率明显高于其他算法,再结合图4可知,随着叉树的增大,本发明的搜索效率也在不断增大,和其他算法相比,具有更大的优势。
综上可知,本发明提供的基于改进曼彻斯特编码的多叉查询树rfid防碰撞方法,减小了rfid标签搜索的总时隙,减小了通信数据量,提高了识别效率,提高了识别速度,优于现有的rfid防碰撞算法;此外,本发明对标签消耗的能量较少,不需要标签具有记忆功能,不需要标签具有复杂的计算和处理能力,便于rfid系统防碰撞方法的实现和应用,不仅具有重要的理论价值,也具有较大的实用价值,具有广阔的发展前景。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!