一种基于特权信息的特征选择方法与流程
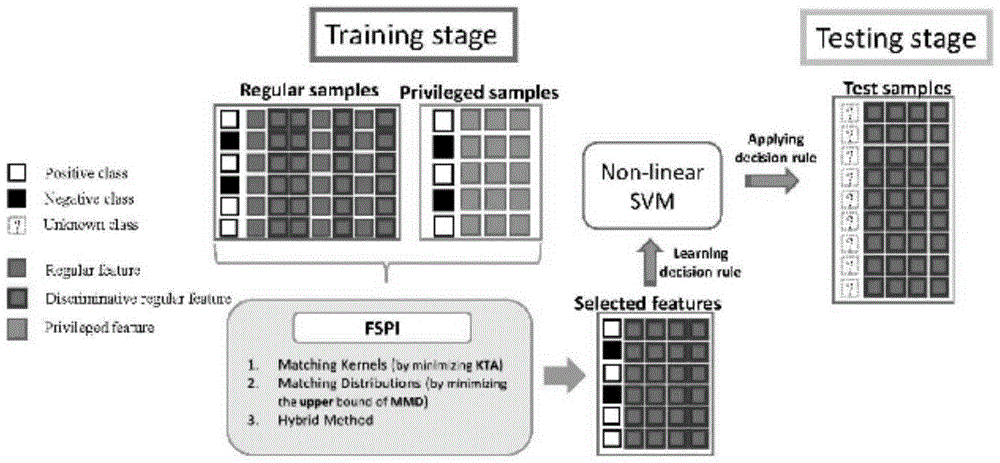
本发明属于机器学习的特征选择领域,尤其涉及一种基于特权信息的特征选择方法。
背景技术:
近年来,计算机电子信息行业发展十分迅猛,数据的获取渠道越来越多,获取得到的数据不仅在数量上越来越多,在维度上也同样越来越大。为了更好获取海量数据中的信息,通常采用降维来消除数据中的噪声和冗余。特征选择由其较好的解释性成为许多实际应用的主流方法。监督特征选择大致可以分为过滤器模型,包装器模型和嵌入式模型。过滤器较为依赖训练数据,而包装器模型算法开销较大,故一般采用嵌入式模型来结合过滤器和包装器模型,在训练模型同时进行特征选择。
特权信息学习框架是近年来提出的一种新的学习框架,它通过对仅用于训练阶段的特权信息的学习,来提高模型测试阶段的泛化能力。所谓特权信息被定为一些易获得、具有现实指导意义的信息,例如医学疾病预测的诊断结果,图像分类中图像的语义描述,网络分析中的详细用户行为信息等。其主要思想就是借鉴了人们在学习过程得到了老师的教授,从而加速了自己的学习速度而无须大量机械的练习这一现象,采用一些对于常规样本有促进意义的先验信息来加速训练。该方法框架由svm+框架引入,目前已成功扩展到各种机器学习任务中,比如分类问题,回归问题,多标签学习问题,鲁棒学习和排序任务等。
虽然特权信息学习框架对于训练有很大帮助,但极少有研究去结合特权学习框架进行特征选择的方案,主要是特权样本与常规样本之间的关系比较复杂,很难去衡量距离。如何很好的去衡量两组样本的关系并使得常规样本尽可能的靠近特权样本,由此实现训练加速也成为了一大难题。
技术实现要素:
为了解决上述问题,本发明将特权学习框架与嵌入式方法结合作为新的正则项,提出了新的一种基于类可分性,运用特权信息的非线性特征选择方法,很好地衡量了不同分布样本之间的接近程度。
为了达到上述目的,本发明提供一种基于特权信息的特征选择方法,包括以下步骤:
步骤a:根据一些易获得、具有现实指导意义的信息定义特权信息,例如医学疾病预测的诊断结果,图像分类中图像的语义描述,网络分析中的详细用户行为信息等,然后将定义的特权信息作为附加信息加入训练阶段的常规信息中;
步骤b:根据常规信息和特权信息的分布关系进行三种不同情况的设置:匹配、不匹配和部分匹配,形成训练数据和测试数据,进行交叉验证;
步骤b不同情况的关系设置具体为:
b1对于匹配情况,在训练阶段获得n对输入数据:
其中xi∈x,
b2对于不匹配情况,输入样本从两组样本中学习:
{(x1,y1),(x2.y2),…,(xn,yn)},
其中m是特权数据集的数量;
b3对于一部分匹配一部分不匹配的部分匹配情况,将b1、b2两种情况相结合,训练样本分为三组:
{(x1,y1),(x2.y2),…,(xn,yn)},
步骤c:使用现有技术的内核可分性方法作为特征选择函数,对步骤b所述样本中的非线性分布情况进行处理,根据常规信息和特权信息不同分布的情况,采取不同内核矩阵的对齐度量函数作为内核可分性特征选择函数的正则项,内核可分性特征选择函数和对齐度量函数两部分相结合形成目标函数;
步骤c的具体展开为:
步骤c1:对于基于类可分性的特征选择函数,它的主要思想是最大化类间散射矩阵与类内散射矩阵之间的比值,来衡量同一类样本的距离;
首先修改基础类可分性函数,使其变为带有非线性映射函数曲的基于内核可分性函数,则特征选择函数形式改为:
其中k=φtφ代表对应的核函数,c代表种类数目,ni代表每个类中样本的个,||k||1代表1-范数运算;
步骤c2:有了步骤c1所述特征选择函数之后,根据步骤b所确立的三种不同样本分组情况确定代表内核矩阵对齐程度的函数作为步骤c1所述特征选择函数的正则项;
c21、对于匹配情况,采用核对齐的核矩阵对齐度量方法,来测量核矩阵的相似性,基础形式如下:
定义
与所述的内核可分离优化函数结合之后,目标函数如下:
其中k*代表特权特征的内核矩阵,
c22、对于不匹配情况,常规和特权样本来自不同空间,对于考量两组样本之间的距离方法最大平均差异评估方式如下:
其中k(·,·)为高斯核函数,对于来自不同空间分布的常规样本和特权样本,修改高斯核函数为:
与所述的内核可分离优化函数结合之后,目标函数如下:
c23、对于部分配对情况,常规样本和特权样本一部分来自同一分布,另一部分来自于不同分布,可以分别进行c21、c22所述的分组优化目标函数,最后结合起来即可:
步骤d:对步骤c所述目标函数,使用现有技术的凹凸过程算法,选出最优特征子集,放入选定的算法框架比较性能得出结论。
步骤d的具体展开为:
步骤d1:对于本发明寻求最优特征子集来寻找最优特征,主要内容为求解核参数问题,对于本方法应用的高斯内核如下式:
其中
步骤d2:采用凹凸过程算法,对非凸形式的目标函数进行优化求解,对两个凸函数分别求梯度进行迭代。
步骤d2的具体步骤如下:
d21、设置如步骤d1所述需要求解的核函数超参数η初值;
d22、通过所述步骤c的不同情况初始线性化函数;
d23、迭代形式:目标函数形成两个凸函数相减或者凸函数ecave(η)与凹函数evex(η)之和
的形式,即e(η)=evex(η)+ecave(η),求解e(η)的最小值。
采用以上方法与现有技术相比,本发明具有以下优点:本发明将特权学习框架与嵌入式方法结合作为新的正则项,提出了新的一种基于类可分性,运用特权信息的非线性特征选择方法,很好地衡量了不同分布样本之间的接近程度,根据特权特征和常规特征的关系,提出了三种情况设置:配对,不配对和部分配对。首先该方法对于匹配情况,通过核对齐(kta)来匹配常规特征和特权特征,将特权特征和常规特征的内核矩阵进行对齐从而学习出两个分布的相似性。对于不匹配情况,两个特征松散耦合的情况下,提出了基于最小最大平均差异(mmd)的新型方法smmd来学习不同内核分布的相似性。对于部分配对情况,则同时应用kta和smmd方法进行解决,并把三种情况表示为凸函数差值形式,使用凹凸过程求解。
附图说明
图1是本发明方法的流程框架图;
图2是模拟数据实验的流程图;
图3是模拟数据集中部分配对情况的精度,召回率和f值的特征选择性能比较图。
图4是模拟数据集中非配对情况的精度,召回率和f值的特征选择性能比较图。
具体实施方式
如图1所示,本发明提出了一种基于特权信息的特征选择方法,并在模拟数据集和真实数据集上分别进行测试来保证方法的有效性和鲁棒性。
1.模拟数据集实验:
本发明使用生成服从正态分布的随机样本进行模拟数据生成,展示了模拟数据集上的特征选择的精度,召回率和f值。
在配对的情况下,将样本量大小作为实验中的参数,其值范围是100到500,并且将测试样本大小设置为1000。在未配对的情况下,本文将常规样本大小设置为100,300和500,特权样本大小设置为常规样本的50%,100%和200%。对于部分情况为一半配对情况与另一半未配对情况相结合。大致生成训练流程如图2所述。
表1展示了模拟数据集上配对情况的不同特征选择方法的性能比较。
表1模拟数据集中部分配对情况的三种特征选择算法的特征选择性能比较
模拟数据集上未配对情况和部分配对情况的fspi精度,召回率,f值,对比与其他性能选择方法如图3,图4所示。在上述三种情况中,本发明在所有特征选择性能测量中都具有几乎最佳的表现,证明了该方法在模拟数据集中的有效性和鲁棒性。
2.真实数据集实验:
本发明也在真实数据集uci乳腺癌数据集和adni阿尔茨海默病数据集上验证了提出方法的有效性。实际上,在真实数据集中,由于每个数据集的最优特征具有未知性。因此无法测量和比较之前实验中的精确度,召回率和f-score。所以本实验通过所选特征提供给svm分类器来比较预测性能,使用交叉验证为所有具有超参数方法选择验证集上的超参数。
实验设计主要分为五个阶段。
(1)首先确定常规样本和特权样本数据集,划分为训练集和测试集。例如,对于uci乳腺癌数据集,原始集作为常规特征,诊断集作为特权特征。对于adni阿尔茨海默病选择脑脊液样本(csf)作为特权,阿尔茨海默blood1与blood2样本作为各自常规特征,各数据集的数量、维度和特征如表2所示:
表2乳腺癌数据集和阿尔茨海默病数据集的统计数据
(2)将常规样本和特权样本划分出训练集和测试集。为了贴近实际,本实验将附加的随机噪声特征(大约30%的特征维度)与常规特征相结合,同时对数据集进行预处理,设置好初始的参数值。本实验过程中对于阿尔茨海默数据集进行了均一化处理,使其数据分布便于学习。
(3)根据常规样本和特权样本的分布情况选择所述不同的目标函数(匹配、不匹配和部分匹配),然后进行核参数的选择.本实验过程中,根据实际划分的常规样本和特权样本的分布情况,采取了不匹配情况的fspi算法,并选择了其他一些相关特权学习的算法以及一些传统方法进行性能比较。
(4)进行核参数优化,主要采用高斯核进行非线性映射,本算法使用凹凸过程方法进行优化,遴选出最佳特征子集。本实验过程中,对于使用核函数的算法,选出最佳核参数,然后使用核参数获得最佳特征子集;没有使用核参数的算法,则直接学习出特征子集。
(5)将选出的最佳特征子集放入基准学习算法进行学习预测。本实验的基本标准方法是没有特征选择的标准支持向量机(svm)。真实数据集设计中所有实验均进行十次,并报告平均预测准确度。
表3展示了不成对的fspi在四个真实数据集上的性能比较。为了公平比较,通过使用每种方法的所选特征训练线性svm来实现分类准确性。
表3真实数据集上的不同特征选择方法性能比较
通过以上两个实验可以看出,本发明所提出的一种基于特权信息的特征选择方法,能够很好的利用特权信息,使得常规样本向特权信息接近来加速训练过程,在实验中优于其他特征选择方法,具有良好的有效性和鲁棒性。
本发明的保护内容不局限于以上实施例。在不背离发明构思的精神和范围下,本领域技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保护范围。
- 还没有人留言评论。精彩留言会获得点赞!