结合情感原因发现的文本情感预测学习系统的制作方法
本发明属于情感预测技术领域,特别涉及结合情感原因发现的文本情感预测学习系统。
背景技术:
在传统文本情感分析的研究中,通常采用单任务学习模型,将文本情感原因发现和文本情感预测分别看作单一任务。
由于传统的情感分析方法将情感原因发现和情感预测看作两个独立的学习任务,需要针对不同的任务设计不同的学习模型,这种方式效率低下且难以挖掘二者之间密切的联系,即情感原因驱动情感的产生,所以对文本情感原因的研究能够促进对情感本身的研究。此外,单任务学习模型在优化时,梯度的反向传播倾向于陷入局部极小值,而多任务学习中不同任务的局部极小值处于不同的位置,通过相互作用,可以帮助隐含层逃离局部极小值,找到更优解。
技术实现要素:
为克服已有技术的不足之处,本发明提出一种结合情感原因发现的文本情感预测学习系统,可以帮助机器更加精准地判断人类的情感。
为了实现上述目的,本发明采用的技术方案为:
一种文本情感原因发现装置,其特征在于,该装置包括词-子句层级结构,包含有四部分:词级别编码器、词级别注意力、子句级别编码器、子句级别注意力;其中,
词级别编码器,将文本送入词级别编码器,用于捕获词与词之间的序列特征;
词级别注意力,通过当前词语的隐状态表示和与之对应的情绪表达之间的关系来获得词级别的注意力值,用来指示当前词在其所在的子句中所占的重要程度,然后通过权重和累加操作获得每个子句的表示;
子句级别注意力,利用一个分类器来获得当前子句是情感原因的概率以此作为子句的注意力值,在子句层级将当前子句距离情绪表达词的距离与子句表示拼接;
子句级别编码器,通过子句编码器获取不同子句之间的结构性信息更新子句表示,通过softmax来获得分类特征的概率分布。
一种结合情感原因发现的情感预测学习系统,该系统包括上述情感原因发现装置以及共享模块、情感预测模块。
相比于现有的技术,本发明的优点有:
首先针对目前情感原因发现领域中忽略文本的结构性信息及不同子句之间关系的问题,提出一种层级结构增强子句的文本表示。其次,根据情感原因对于准确识别情感的推动作用,采用联合任务模型结合情感原因对文本进行情感预测,以帮助机器更加精准地判断人类的情感。
附图说明
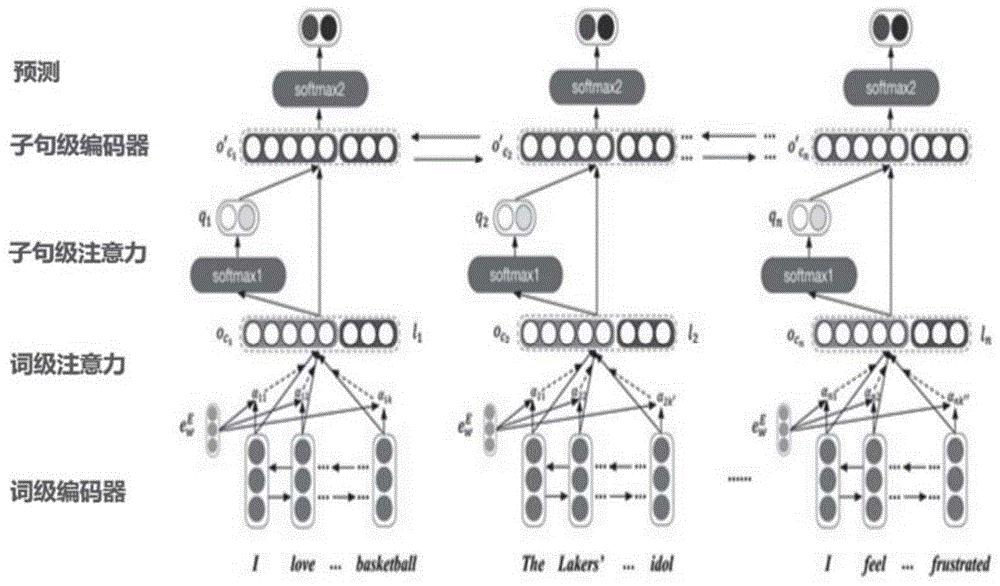
图1是文本情感原因发现框架图;
图2是结合情绪原因的文本分类的联合模型。
具体实施方式
下面结合附图说明及具体实施方式对本发明进一步说明。
由于目前有关情感原因发现的方法忽略了文本的结构性信息及不同子句之间的关系,这些信息可以为情感原因发现任务提供重要的线索。本发明将采用一种层级的框架结构以提取文本中的有关情感原因的结构性信息及不同子句之间的语义关系。文本中不同的词和句子会呈现不同的信息,因此本发明在每个层级增加注意力机制来捕获子句及篇章的内在语义信息以增强子句的文本表示,助于最终的分类决策。
如图1所示:框架采用词-子句层级结构,主要分为四部分:词级别编码器、词级别注意力、子句级别编码器、子句级别注意力。下面将针对以上四部分进行详细介绍。
1)词级别编码器:首先将文本送入词级别的编码器,用于捕获词与词之间的序列特征。本发明采用门限循环单元(gru)作为最基础的词级别编码器,在每一个时间步,隐状态ht通过以下公式进行更新:
zt=σ(wzxt+uzht-1+bz)(1)
rt=σ(wrxt+urht-1+br)(2)
其中,xt是输入单词wt的向量表示,σ和tanh是激活函数,
由于前序、后序信息对于当前的表达都很重要,因此本发明采用双向的gru用来作为词级别的码器并通过以下公式进行更新隐状态:
其中,xit表示第i个子句(ci)第t个单词wit的向量表示,k为ci的长度,
2)词级别注意力:通过当前词语的隐状态表示和与之对应的情绪表达之间的关系来获得词级别的注意力值,用来指示当前词在其所在的子句中所占的重要程度,然后通过权重和累加操作获得每个子句的表示,计算公式如下:
其中,w为参数矩阵,
3)子句级别注意力:不仅是词之间有这样的关系,不同的子句同样有不同的重要程度。因此,本发明利用一个分类器来获得当前子句是情感原因的概率以此作为子句的注意力值,此外,也可以表达有多少当前的信息被保留。同时,位置信息表示是很重要的信息,因此在子句层级将当前子句距离情绪表达词距离的分布式表示与子句表示拼接。计算公式如下:
其中,wv为参数矩阵,li为位置信息向量表示,qi为子句ci是情感原因的概率,同时也表示将有多少信息被保留到
4)子句级别编码器:通过子句编码器获取不同子句之间的结构性信息更新子句表示。最后,通过softmax来获得分类特征的概率分布。
计算公式如下:
其中,
由于情感原因发现及文本情感预测具有很强的相关性,因此本发明利用文本情感原因对于情绪的驱动作用,来辅助文本情感预测任务的决策。本发明采用一种联合模型,如图2所示,为了保留任务本身的特征,针对文本情感原因发现任务和文本情感预测任务,增添分别提取任务特定信息的神经网络层,为了共享任务的交互信息,设置共享层,这样既能提取任务特定特征又能捕获两个任务共享的信息,达到提升情感预测任务的准确性的目的,其中情感原因发现模块即为图1中的结构。
1)共享模块:情感原因驱动情感的产生,所以对文本情感原因的研究能够促进对情感本身的研究。因此,本发明设置一个共享模块捕获两个任务间的共享信息并通过一个共享gru单元实现,计算公式如下:
其中,
2)情感预测模块:该模块利用gru单元捕获情感预测文本的序列特征,并通过注意力机制获取文本的隐状态表示,最后和共享层的输出一起用于情感预测,计算公式如下:
gpt=wp·hpt(23)
其中,
考虑两个任务的优化目标不同,本发明将对单任务进行分别优化,将交叉熵作为损失函数,如公式(26)所示:
l=-∑d∑c∈cyclogfc(x;θ)(26)
其中,d是训练数据,c是样例的所有类别,yc是真实类别的分布,fc(x;θ)是模型预测为c-th类别的概率分布。
综上,本发明中提出了层级结构增强子句的文本表示,并根据情感原因对于准确识别情感的推动作用,采用联合任务模型结合情感原因对文本进行情感预测,能够帮助机器更准确地判断人类的情感。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!