一种基于CUDA的矩阵转置方法与流程
本发明涉及一种矩阵转置方法,具体涉及一种基于cuda的矩阵转置方法,属于计算机领域。
背景技术:
图形处理器(gpu)技术的进步和cuda编程模型的引入对于稀疏及密集的线性代数计算速度有着极大的提高。而矩阵转置作为线性代数中一个极其重要而又普遍的操作,涉及计算科学和各种工程应用。对于多批次、大尺寸的矩阵,使用传统的计算方法进行串行处理的效率显然不高。而对于使用图形处理器(gpu)并行操作而言,有几个因素严重影响图形处理器(gpu)设备的计算性能。其中包括内存的访问模式,如全局内容中的合并访问以及共享内存中的内存块冲突。而对于矩阵转置,该运算的本质是进行数据交换。
传统的串行处理效率不高,所以通常图形处理器(gpu)采用并行的方式处理数据,但是由于其全局内存之间的转存延迟高,影响了矩阵转置的整体效率。
因此如何提供一种基于cuda的矩阵转置方法,能够最大化利用图形处理器(gpu)的数据带宽,提高图形处理器的处理速度,是本领域技术人员亟待解决的技术问题。
技术实现要素:
针对上述现有技术的不足,本发明的目的在于最大化利用设备的数据带宽,提高图形处理器的处理速度。本发明提供一种基于cuda的矩阵转置方法,包括以下步骤:矩阵转置预处理工作:1)识别输入矩阵a大小。2)根据输入矩阵a的大小,在图像处理器中设置最优大小的共享内存d。3)将输入矩阵a内的数据索引后存入共享内存d。4)将共享内存d中的索引后的数据,转置存入目标内存c中。
根据本发明的实施方案,提供一种基于cuda的矩阵转置方法:
一种基于cuda的矩阵转置方法,包括以下步骤:矩阵转置预处理工作:
1)识别输入矩阵a大小。
2)根据输入矩阵a的大小,在图像处理器中设置最优大小的共享内存d。
3)将输入矩阵a内的数据索引后存入共享内存d。
4)将共享内存d中的索引后的数据,转置存入目标内存c中。
作为优选,在步骤1)和2)具体为:
a)输入矩阵a的大小为[n,w,h],其中n表示批量转置矩阵的个数,w表示矩阵的宽,h表示矩阵的高。
b)识别输入矩阵a的最优逻辑待读矩阵,待读矩阵大小为[w,h]。
c)最优大小的共享内存d的物理大小为w*h*t比特;逻辑尺寸宽为w,高为h。
其中,w、h、t满足以下要求:
其中,t表示数据类型大小。
作为优选,步骤3)具体包括以下步骤:
a)为输入矩阵a中的每个待读矩阵,分配一个线程块。
b)线程块对待读矩阵的数据进行索引标记。
c)线程块将所有待读矩阵的数据拷贝至共享内存d中。
作为优选,步骤4)具体包括以下步骤:
a)为共享内存d中分配一个线程块。
b)线程块根据索引标记,将共享内存d中的数据转置拷贝至目标内存c中。
作为优选,为输入矩阵a中的每个待读矩阵,分配一个线程块具体为:
a)每一个线程块负责处理w*h大小的数据。
b)总共分配
c)每个线程块内部申请设置h个线程。
作为优选,线程块对待读矩阵的数据进行索引标记,线程块将所有待读矩阵的数据拷贝至共享内存d中具体为:
a)设线程块的x线程的一维索引为threadidx.x,则映射成二维索引为(thidy=threadidx.x/w,thidx=threadidx.x%w)。则线程负责操作线程块映射到待读矩阵内的索引为(thidy+i)*h+thidx,其中i=0,1,2,3,…,w-1。待读矩阵中的每个数据对应共享内存d相应区域的索引位置为(thidy+i)*h+(thidy+i+thidx)%h,其中i=0,1,2,3,…,w-1。
b)执行线程,合并访问拷贝出数据。
作为优选,线程块根据索引标记,将共享内存d中的数据转置拷贝至目标内存c中具体为:
a)设线程块的x’线程的一维索引为threadidx’.x’,则映射成二维索引为(thidy=threadidx’.x’/h,thidx’=threadidx’.x’%h)。则该线程负责操作线程块映射到共享内存d相应区域的索引为thidx’*h+(thidx’+thidy+i*readrows)%h,其中readrows=h/w,i=0,1,2,3,…,s.t.i*readrows<w。共享内存d的每个数据对应目标内存c相应区域的索引位置为(thidy+i*readrows)*w+thidx’,其中readrows=h/w,i=0,1,2,3,…,s.t.i*readrows<w。
b)执行线程,合并方为写入数据。
作为优选,当x’线程的索引位置越界时,则停止x’线程的执行。
在现有技术中,传统的串行处理效率不高,所以通常图形处理器(gpu)采用并行的方式处理数据,但是由于其全局内存之间的转存延迟高,影响了矩阵转置的整体效率。
本发明旨在最大化使用图形处理器(gpu)的性能,通过设计自适应大小的共享内存,来进行矩阵的转置。首先,识别输入矩阵a的大小尺寸。第二根据输入矩阵a的具体大小尺寸,自适应地动态申请最优的共享内存d的大小和形状。自适应申请的共享内存d将为输入矩阵a和目标矩阵c之间的数据交换提供中转。通过线程块将数据从输入矩阵a拷贝至共享内存d中,同时对共享内存d中的数据进行索引标记。再通过线程块根据共享内存d中的索引标记,将共享内存d中的数据拷贝并转置,存入目标矩阵c中。这样能使在对共享内存的数据进行访问时避免内存块冲突。保证物理地址相邻的数据被相邻索引的线程合并操作,同时一个线程将处理多个数据,提高数据传输的效率。
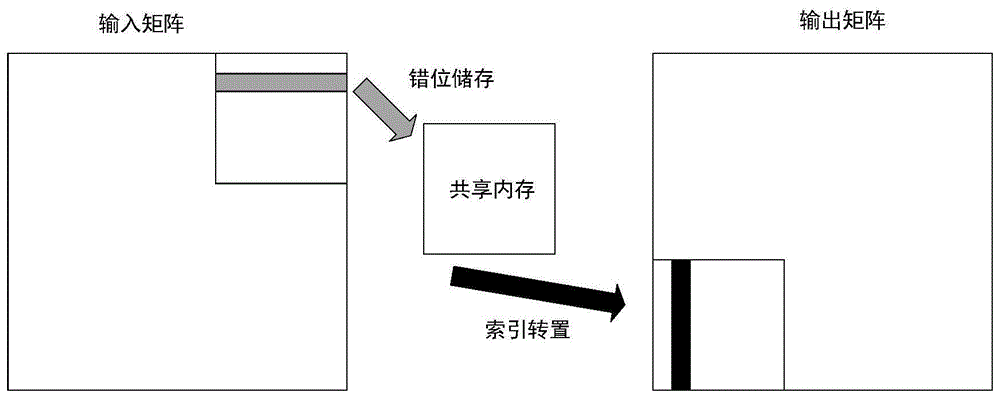
需要进一步说明的是,本申请所提供的方案中,步骤3)将输入矩阵a内的数据索引后存入共享内存d具体为:将输入矩阵a内的索引后,错位储存到共享内存d中。
在本申请中,输入矩阵a的大小可以通过调取数据属性获知,输入矩阵a的大小为[n,w,h]。识别输入矩阵的最优逻辑待读矩阵[w,h]。其中,
其中,w、h、t满足以下要求:
其中,t表示数据类型大小。
最后设置共享内存d[w,h,t]。
需要说明的是,共享内存的数据量小于等于214。
在本申请中,步骤3)的步骤b)中,线程块对待读矩阵的数据进行索引标记。通过设置索引式:(thidy+i)*h+thidx,其中i=0,1,2,3,…,w-1;(thidy+i)*h+(thidy+i+thidx)%h,其中i=0,1,2,3,…,w-1;将待读矩阵的数据与共享内存d中的物理地址错位关联。执行线程后,输入矩阵a中的数据错位存储到共享内存d中。
需要进一步说明的是,在现有技术中,单个线程块的一个线程按顺序读取其对应的数据块,再由下一个线程按顺序读取对应的数据块,以此类推。所有线程读取的数据块再按照线程的顺序排列,存放至目标内存中。该方案无法做到读取和写入两个步骤都进行合并访问。导致运算效率较低。
需要进一步说明的是,在本发明提供的方案中,共享内存d中的数据为错位存储。线程块中的多个线程可按顺序同时读取索引标记后的数据。再按照索引式将数据同时存放如目标内存c中。该方案多个线程同时访问的地址在物理上是间隔的,但在逻辑上是连续的,因此多个线程能够避免内存冲突同时工作,运算速度大大的提高。从而提高采用此方法进行数据转移计算的图像处理器(gpu)的计算速度。
在本申请中,步骤4)的步骤b)中,线程块根据索引标记,将共享内存d中的数据转置拷贝至目标内存c中。通过设置索引式:thidx’*h+(thidx’+thidy+i*readrows)%h,其中readrows=h/w,i=0,1,2,3,…,s.t.i*readrows<w;(thidy+i*readrows)*w+thidx’,其中readrows=h/w,i=0,1,2,3,…,s.t.i*readrows<w。将共享内存d的数据拷贝至目标内存c中。
需要进一步说明的是,原本在共享内存d中错位存储的数据,在拷贝至目标内存c的过程中线程索引与需要操作的数据索引之间进行了错位运算。两次错位,使得目标内存c中的数据相对原来输入矩阵a的数据进行了转置。即,第一次写入到共享内存的时候使用了错位储存。后面在转入目标内存时,线程索引与需要操作的数据索引之间的计算方法上添加了错位运算。保证每个线程所取到的数据在逻辑上连续的,同时从整个过程来看,将输入矩阵的数据转置到目标内存中。
需要进一步说明的是,一个优选的方案,步骤3)的步骤a)中,和步骤4)的步骤a)中,同样所分配的线程块,为同一个线程块。同一个线程块将数据从输入矩阵a中拷贝至共享内存d中,再从共享内存d中将数据拷贝至目标内存c中。即对于每一个大小为w,h的矩阵,对其分配一个线程块后。该线程块将负责把数据中转到共享内存后还负责写入到目标内存,线程块会负责转置的所有操作。
综上所述,本发明提供的方法,能够更快速的完成数据转移过程中的数据转置。从而提高采用此方法处理数据的图像处理器(cpu)的处理速度。
在本申请中,x’线程的索引位置越界即线程索引的目标位置不存在时。则停止该线程继续执行,说明该线程执行结束。
与现有技术相比,本发明具有以下有益效果:
1、根据矩阵尺寸动态申请最优形状的共享内存,使得全局内存的读写都能利用合理的资源进行合并访问;
2、数据转存操作计算量小,控制线程进行多个数据的索引操作,提高程序的执行效率;
3、共享内存数据采用错位储存的方式,能够在不浪费任何共享内存存储空间下避免内存块冲突;
4、在写入数据到共享内存时便完成索引的转置,无需在共享内存中额外进行转置操作。
附图说明
图1为本发明实施例中转置操作示意图;
图2为本发明使用实施例中错位储存方式示意图。
具体实施方式
为了使本领域的技术人员更好地理解本申请中的技术方案,下面将结合本申请实施例中的附图对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请的一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
根据本发明的实施方案,提供一种基于cuda的矩阵转置方法:
一种基于cuda的矩阵转置方法,包括以下步骤:矩阵转置预处理工作:
1)识别输入矩阵a大小;
2)根据输入矩阵a的大小,在图像处理器中设置最优大小的共享内存d;
3)将输入矩阵a内的数据索引后存入共享内存d;
4)将共享内存d中的索引后的数据,转置存入目标内存c中。
作为优选,在步骤1)和2)具体为:
a)输入矩阵a的大小为[n,w,h],其中n表示批量转置矩阵的个数,w表示矩阵的宽,h表示矩阵的高;
b)识别输入矩阵a的最优逻辑待读矩阵,待读矩阵大小为[w,h];
c)最优大小的共享内存d的物理大小为w*h*t比特;逻辑尺寸宽为w,高为h;
其中,w、h、t满足以下要求:
其中,t表示数据类型大小。
作为优选,步骤3)具体包括以下步骤:
a)为输入矩阵a中的每个待读矩阵,分配一个线程块;
b)线程块对待读矩阵的数据进行索引标记;
c)线程块将所有待读矩阵的数据拷贝至共享内存d中。
作为优选,步骤4)具体包括以下步骤:
a)为共享内存d中分配一个线程块;
b)线程块根据索引标记,将共享内存d中的数据转置拷贝至目标内存c中。
作为优选,为输入矩阵a中的每个待读矩阵,分配一个线程块具体为:
a)每一个线程块负责处理w*h大小的数据;
b)总共分配
c)每个线程块内部申请设置h个线程。
作为优选,线程块对待读矩阵的数据进行索引标记,线程块将所有待读矩阵的数据拷贝至共享内存d中具体为:
a)设线程块的x线程的一维索引为threadidx.x,则映射成二维索引为(thidy=threadidx.x/w,thidx=threadidx.x%w);则线程负责操作线程块映射到待读矩阵内的索引为(thidy+i)*h+thidx,其中i=0,1,2,3,…,w-1;待读矩阵中的每个数据对应共享内存d相应区域的索引位置为(thidy+i)*h+(thidy+i+thidx)%h,其中i=0,1,2,3,…,w-1;
b)执行线程,合并访问拷贝出数据。
作为优选,线程块根据索引标记,将共享内存d中的数据转置拷贝至目标内存c中具体为:
a)设线程块的x’线程的一维索引为threadidx’.x’,则映射成二维索引为(thidy=threadidx’.x’/h,thidx’=threadidx’.x’%h);则该线程负责操作线程块映射到共享内存d相应区域的索引为thidx’*h+(thidx’+thidy+i*readrows)%h,其中readrows=h/w,i=0,1,2,3,…,s.t.i*readrows<w;共享内存d的每个数据对应目标内存c相应区域的索引位置为(thidy+i*readrows)*w+thidx’,其中readrows=h/w,i=0,1,2,3,…,s.t.i*readrows<w;
b)执行线程,合并方为写入数据。
作为优选,当x’线程的索引位置越界时,则停止x’线程的执行。
使用实施例1
以下实施例的矩阵输入为三维数据,其维度分别代表需要转置矩阵的个数n、宽w和高h。输入尺寸为[24,5,100]的32位浮点类型矩阵,其主要步骤为:
1)在设备端开辟24*5*100*32[n,w,h,t]大小的全局内存,并标识为input;将input的数据从主机端拷贝到设备端,并在设备端开辟同等存储大小的全局内存output;进行转置操作的示意图如图1所示.
2)计算出最适合的共享内存形状;其长边满足大于100且为2最小整数次幂,即h设为128,w设为5。
3)在每个线程块内动态开辟5*128*32[w,h,t]大小的共享内存存储空间;
4)设备端分配24个线程网络;每个线程网络内部仅含有1个线程块;每个线程块内分配128个线程;
5)将数据从input上合并读取到共享内存中;其中,线程块内每个线程将操作5个数据;线程的一维索引为threadidx.x,则映射成二维索引为(thidy=threadidx.x/w,thidx=threadidx.x%w);该线程负责操作线程块在input相应区域内的索引为(thidy+i)*h+thidx,其中i=0,1,2,3,…,w-1;例如对于索引为0的线程,应操作input上二维逻辑索引为(0,0),(1,0),(2,0),(3,0),(4,0)的数据;每个数据对应共享内存相应区域索引位置为(thidy+i)*h+(thidy+i+thidx)%h,其中i=0,1,2,3,…,w-1;其错位储存效果示意图如图2所示;在上例线程索引中,这些数据在共享内存上的二维逻辑错位索引应为(0,0),(1,1),(2,2),(3,3),(4,4);
6)等待线程网络中的所有线程都执行完操作;
7)将数据从共享内存中合并写入到output上;其中,线程的一维索引为threadidx’.x’,则映射成二维索引为(thidy=threadidx’.x’/h,thidx’=threadidx’.x’%h),并设readrows=h/w;线程负责操作线程块映射到共享内存相应区域的索引为thidx’*h+(thidx’+thidy+i*readrows)%h,其中i=0,1,2,3,…,s.t.i*readrows<w线程块内每个线程将操作5个数据;例如对于在内存块中索引为1的线程,应操作共享内存上所对应二维逻辑索引为(1,0),(1,25),(1,50),(1,75)的数据;因矩阵数据高的索引范围是0-99,故(1,100)索引越界,不作处理;每个数据对应output相应区域的索引位置为(thidy+i*readrows)*w+thidx’,其中i=0,1,2,3,…,s.t.i*readrows<w;在上例线程索引中所涉及的这些数据对应的二维逻辑索引为(0,1)(25,1)(50,1)(75,1);同样因(100,1)越界从而舍弃;待所有线程操作完毕后即可完成矩阵转置。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!