基于梯形云模型的水体富营养化评价方法与流程
本发明主要涉及河湖水体富营养化评价技术领域,具体指基于梯形云模型对河湖进行水体富营养化评价的方法。
背景技术:
调查表明,我国富营养化湖泊个数占调查湖泊的比例由20世纪70年代末的41%发展到80年代后期的61%,至今上升到77%。在26个国控重点湖泊中,水质一般较差,低于《地面水环境质量标准》(gb3838-2002)ⅴ类标准,氮、磷污染较高,相当一部分湖泊发生了藻类水华灾害(如巢湖、太湖、洪泽湖等)。另外,众多的城市湖泊已达严重富营养化(如南京玄武湖、杭州西湖、九江甘棠湖、广州的东山湖等),少数湖泊处于富营养化边缘,如洞庭湖和鄱阳湖已具备了发生富营养化的营养盐条件。我国水库、河流水体富营养化的问题也比较严重,根据对全国39个大、中、小型水库的调查结果表明:处于富营养状态的水库个数和库容分别占所调查水库的30.8%和11.2%,处于中营养状态的水库个数和库容分别占所调查水库的43.6%和83.1%。可见,水体富营养化已成为我国最为重要的水环境问题之一。因此,河湖水体的富营养化评价就显得尤为重要。一种适当的评价方法可以让评价效果更加的准确和简单。当前已经有很多的传统方法来解决水体富营养化评价问题。其中基于云模型的方法对水体进行评价(云模型,参见参考文献[1]:曾德彪.基于多维正态云模型的水体富营养化评价方法[d].南京大学,2015.)比较常用。云模型对水体的富营养化评价有很高的认可性,但是在评价过程中也存在一定缺陷,云模型在评价中对于等级的评价局限于一个点,而在实际当中某一个等级是存在相应的范围的,不能单纯的用某一个点来代表整个等级范围,这会对评价结果产生一定的影响。因此需要对这个缺陷进行改进已达到更加准确的评价结果。
技术实现要素:
本发明提供的基于梯形云模型的方法能够充分的解决正态云模型方法中存在的缺陷,在梯形云模型中,使用数值区间来表征一个评价等级而非一个等级中的点,在梯形云模型数字特征的确定中提出新的确定方式,采用定性结合定量的方法对数字特征进行确定,并且细化了水体评价的等级范围,使得评价结果更加合理和准确。
本发明提供了一种基于梯形云模型的水体富营养化评价方法,所述方法在确定水体富营养化的五个影响因子的基础上,通过以有的历史资料利用阿塔纳索夫区间值直觉语言数定性的给出河湖所属等级评价的确定度模糊区间,再通过构造的语言标度函数和定性的确定度(隶属度)模糊区间确定出梯形云的五个参数特征,然后建立梯形云模型,将所要测试河湖的水质数据输入到梯形云模型里,最后得出六个评价等级的确定度大小,通过比较选择出拥有较大确定度所在的等级作为最终的评价等级;具体包括如下步骤:
第一步(定性):收集所要评价河湖的历史评价结果,采用阿塔纳索夫区间值直觉语言数(atanassov'sinterval-valuedintuitionisticlinguisticnumbers)的方法得出模糊的评价结果。
第二步(定量):建立语言标度函数。通过国家水体评价等级(共六级)范围,将模糊的评价结果中的水质等级hk映射为数字参数θk,这个映射过程就是建立语言标度函数的过程。
第三步(定量):通过第二步得到的数字参数θk结合国家水体评价等级的具体范围得到梯形云模型的参数
第四步(定量):通过主客观权值的融合得到一个更加合理的权值分配从而计算得出五个影响因子(chla、tp、tn、cod、sd)分别对水体质量的影响大小,得出相应的权值。
第五步(定量):确定每一影响因子属于水质等级k的隶属度。
第六步,把待评价河湖具体的水质数据输入到梯形云模型当中得出多个影响因子在同一个水质等级的隶属度,通过比较将隶属度最大的所属等级作为最终的评价结果。
本发明的优点在于:
(1)本发明能改进现有的云模型中以点来代表等级范围的缺陷,本发明的梯形云模型中使用一个数值区间来表示等级范围,使得评价结果更加合理准确。
(2)本发明能够解决在等级范围内不是以区间范围的中间值为期望的正态分布数据的问题,本发明提供的梯形云模型更加与数据匹配,对数据的适应性更高。
(3)本发明在计算过程中会产生更加细化的等级评价范围,对是否属于某等级的确定性更高,结果更加准确。
(4)本发明在最终的计算结果中每个等级的确定度(相比于之前的云模型)差异更大,避免了由于梯形云模型中随机数对评价结果的影响,使结果更具有说服力。
(5)采用主客观相结合的赋权方法得出影响因子的权值,更加合理和准确。
附图说明
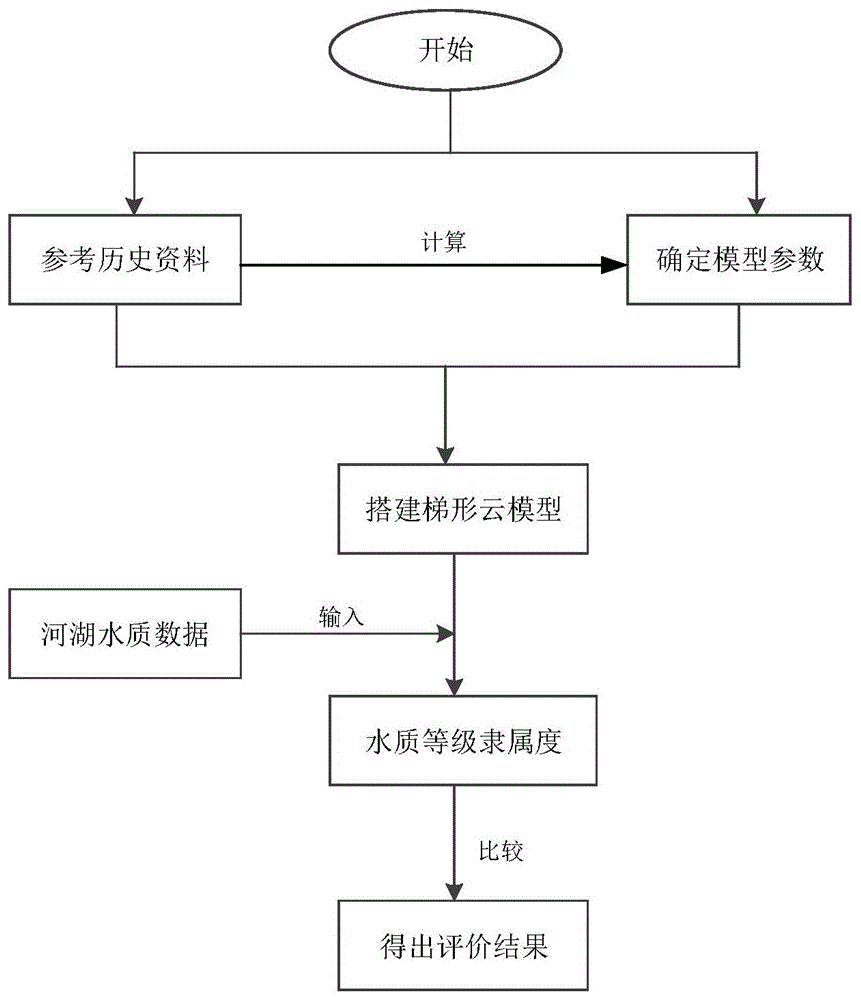
图1为本发明中的基于梯形云模型的水体富营养化评价方法的流程图;
图2为本发明中的梯形云模型的构建方法流程图;
具体实施方式
下面结合附图对本发明进行详细说明。
本发明提供一种更加合理准确的水体富营养化评价方法,基于梯形云模型的定性结合定量的更加优化的评价方法。如图1所示流程,本发明提供的基于梯形云模型的水体富营养化评价方法,如图1和图2所示流程,具体包括如下步骤:
步骤一、参考所要评价河湖的历史评价数据,根据历史评价数据得到阿塔纳索夫区间值直觉语言数即河湖的模糊评价区间,阿塔纳索夫区间值直觉语言数的具体确定方法如下:
(1.1)首先建立一个水质等级分化的语言项集h如下:
h={hk|k=1,…,2t,t∈n*}
其中hk为水质级别,根据国家水体评价等级的分类,水质一共分为6个等级,所以水质级别hk的语言项一共有6个分别为i、ii、iii、iv、v、ⅵ;所以t的取值为3;n*表示正整数。
(1.2)根据水质的影响因素的大小,采用chl_a(叶绿素含量)、tp(磷含量)、tn(氮含量)、cod(需氧量)、sd(水体透明度)5个影响因子作为此次水质评价的基础。建立影响因子集x,其中x1、x2、x3、x4、x5分别对应五个影响因子;
x={x1,x2,x3,x4,x5}
(1.3)根据每个影响因子对应的水体等级建立阿塔纳索夫区间值直觉语言数a如下:
a={<x,hk,[a,b],[c,d]>}
hk∈h,
步骤二:映射计算,建立语言标度函数。
根据国家水体评价等级范围,将语言项集h中的水质等级映射为数字参数θk,映射公式如下:
f:hk→θk
其中,映射公式中的g在同一个河湖不同时期是相等的,可通过河湖历史数据以及历史评价等级反求得到,g一般的取值范围在[1.361.4]之间。通过上述映射公式就会把评价等级的语言值转化为数字值,为后续的计算提供方便。
步骤三:结合国家水体评价等级的具体范围得到梯形云模型的参数。
其中,在计算水质数据中,每个影响因子的不同等级的熵的取值总是取最大的那个。根据上述计算结果得出每个影响因子在不同等级k下的梯形云模型参数
步骤四:计算得出五个影响因子(chl_a、tp、tn、cod、sd)分别对水体质量的影响权值。采用主观(模糊对数优先规划理论cfpp)和客观(critic法)结合的方法确定影响因子的权重。
(4.1)cfpp法(对数优先规划理论)的主要思想是通过三角模糊数理论,能够使得决策更加的合理。具有如下属性的数可称之为三角模糊数,基本表示形式为m=(l,m,u),l和u分别表示三角模糊数的下界和上界,它们表示模糊的程度,区间越大,模糊程度越强,m表示最优值。其中影响因子xi对比影响因子xj的相对重要度的取值范围为(lij,uij),mij表示最可能的相对重要度。三角模糊数重要度标度(相对重要度)的取值如下表1:
表1三角模糊数重要度标度的取值
根据三角模糊数重要度标度构造如下模糊判断矩阵,n为5:
根据cfpp法,首先给出函数minj和约束条件如下:
其中,xi为第i个影响因子xi的权重,xi=lnwi,i=1,…,n;xj为第j个影响因子xj的权重,wi为模糊判断矩阵aij的重要度;m为一个规定的大数值如m=105,用来保证权重的合理性;为保证非线性优化不等式组一定有解,引入了非负误差参数δij和ηij,λ为最小隶属度,根据上述方程求得影响因子xi的权重最优解记为xi*和最小隶属度最优解λ*,最后根据下述公式求得每一个影响因子的主观权重
(4.2)客观法即critic法根本思想是以指标数据的对比度和冲突性两个概念为基础,综合确定指标的客观权数。对比度用标准差表示,反应不同样本之间同一指标的差距大小,标准差越大,样本间数据的取值差距越大,因此数据样本反应的信息量越大。指标冲突用相关性表示,如果两个指标具有较大的正相关系数,说明两个指标冲突性较低,如果两个指标存在负相关系数,且其绝对值越大时,冲突性越大,表明这两个指标在样本的优劣上反映的信息有较大的不同,权重也就越大。计算公式如下:
一般的,rij为影响因子xi和影响因子xj之间的相关系数,i=1,…,n;i≠j;δi为标准差,ci表示第i个影响因子的权重,ci越大,第i个影响因子所包含的信息量越大,则该影响因子的相对重要性也就越大。设
(4.3)融合cfpp主观权重和critic客观权重得到最终的融合权重fi,融合权重公式如下:
步骤五:用matlab搭建梯形云模型,得出每个影响因子属于水质等级k的隶属度。隶属度μk确定公式如下:
其中,xi为河湖影响因子(5个)的具体数据。
步骤六:对于待评价河湖的水质数据,即影响因子数据输入梯形云模型,得到处于每个等级最终的隶属度,比较每个水质等级隶属度的大小,选择最大的隶属度所在的水质等级作为最终的评价结果。
以影响因子叶绿素浓度xchl_a和总磷浓度xtp为例,给出第k个水质等级二维梯形云模型的算法生成过程如下:
步骤6.1:判断影响因子所属的影响区间,如果xchl_a和xtp同时满足
其中,exkchl_a表示叶绿素浓度在第k个水质等级的取值下限,
步骤6.2:直接使隶属度μ=1。
步骤6.3:如果
步骤6.4:如果
步骤6.5:根据上述得到的数据使用隶属度如下公式来得到上述两个影响因子在当前水质等级的隶属度:
其中,fchl_a表示叶绿素浓度的融合权重,ftp表示总磷浓度的融合权重。
对k个水质等级的隶属度的大小进行比较判断,选择最大的隶属度所在的水质等级作为最终的评价结果。
本发明能够有效的避免正态云模型中以点来代表等级范围的缺陷,使得评价模型更加的合理和准确;还能够有效的解决等级范围内不是以区间范围的中间值为期望的正态分布的数据问题,使得模型更加的贴切数据所表达出来的特性,使模型的对数据的适应性更高。能够使评价结果更加的准确合理。
- 还没有人留言评论。精彩留言会获得点赞!