一种基于注意力机制的卷积神经网络视线估计方法及系统与流程
本发明涉及图像处理和模式识别领域,具体涉及一种基于注意力机制的卷积神经网络视线估计方法及系统。
背景技术:
视线估计是计算机视觉研究中一个经典的问题,现有的基于眼睛图像进行视线估计的方法有:(1)瞳孔角膜反射法;(2)虹膜-巩膜边缘法;(3)基于卷积神经网络的外观的方法。
现在方法的主要问题有:(1)头部运动带来的视线估计不准确;(2)需要标定相机,需要测量环境距离;(3)需要专业的,昂贵的硬件设备;(3)精度不够高。
技术实现要素:
本发明的目的在于提供一种基于注意力机制的卷积神经网络视线估计方法,从而可以简洁、方便、高精度地实现人的视线估计。。
为实现上述目的,本发明提供如下技术方案:一种基于注意力机制的卷积神经网络视线估计方法,包括以下步骤:
步骤1:采用局部约束神经元域来对人脸关键点进行定位;
步骤2:使用步骤1检测到的坐标点来对眼部图像进行截取;
步骤3:将截取到的图像进行标准化处理;
步骤4:将标准化处理后的图像送入注意力机制的卷积神经网络进行回归,得到估计的视线角度坐标。
优选的,所述图像标准化处理即通过图像的仿射变换,将图像转换到一个标准化的相机空间,在这个标准化相机空间中,所有图像中的人的头部和相机的距离是一样的,且头部姿态也是一样的。
优选的,所述图像标准化处理包括有三个步骤:
步骤1:以相机坐标系为世界坐标系,已知双眼中心坐标ec和头部姿态旋转矩阵r,先将相机旋转至相机的z轴对准两眼中心;这一步只需让相机z轴对齐双眼中心坐标ec,可得旋转后的相机z轴为rz=ec/||ec||;
步骤2:相机绕z轴旋转至相机的x轴和头部姿态的x轴位于同一平面上;由于头部姿态的x轴为已知量,为头部姿态旋转矩阵r的第一列rx,要让旋转后的相机x轴rx和rx位于同一平面,则需满足旋转后的相机y轴ry垂直于此平面;又ry垂直于旋转后的相机z轴rz,因此,ry可由rx和rz的叉积求得:ry=rx×rz;rx可由ry和rz的叉积求得:rx=ry×rz;于是,得到相机的旋转矩阵rc=[rx,ry,rz];
步骤3:标准化双眼中心到相机中心的距离;这一步可通过缩放相机的z轴实现,即定义一个尺度缩放矩阵s=diag(1,1,d/||ec||),其中d为双眼中心到相机中心的标准化距离。
优选的,所述注意力机制的卷积神经网络的注意力模块由双通道组成;
上层的称为主通道,由cnn模块构成;
下层称为掩码通道,是一个自底向上-自顶向下的沙漏网络。。
优选的,对于一个输入图像i,记主通道的输出为f(i),掩码通道的输出为a(i),则注意力模块的输出m(i)可以根据f(i)和a(i)的点乘得到:mc(i)=fc(i)+fc(i)·ac(i);
式中:fc(i)表示f(i)的第c个通道,ac(i)表示a(i)的第c个通道,符号·表示矩阵的点乘。
有益效果:
(1)本发明的一种基于注意力机制的卷积神经网络视线估计方法及系统,设计采用注意力机制网络使得在高层提取特征的特征基本来自于瞳孔的位置,从而更好的提高准确率,减小误差;并且通过关键点检测从而使得裁剪出来的图片分辨率更小,从而使快速性得到提高。
(2)本发明的一种基于注意力机制的卷积神经网络视线估计方法及系统,具有准确(精确度得到提高,可以达到误差仅有4.8°)、客观、便捷(无需苛刻的实验室环境,无需特殊的设备,只需一个普通的相机或者智能手机)、快速的优点。
附图说明
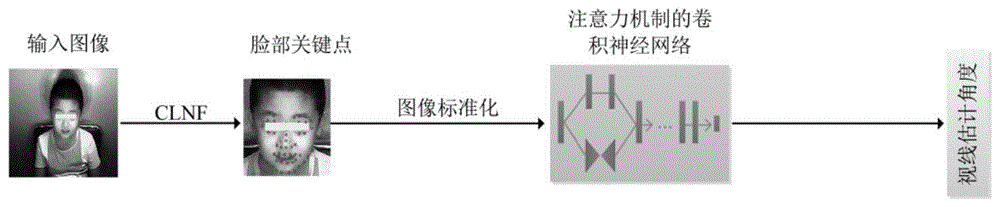
图1为本发明方法流程示意图。
图2为本发明中注意力机制的卷积神经网络结构图。
图3为本发明中注意力模块结构图。
具体实施方式
下面结合附图进一步说明本发明的实施例。
如图1-3所示,首先,采用局部约束神经元域(constrainedlocalneuralfields,clnf)来对人脸关键点进行定位。
然而,当我们使用clnf检测到的坐标点对眼部图像截取时,不同的头部姿态,不同的拍摄距离,都会造成不同的图像大小,卷积神经网络(convolutionalneuralnetworks,cnn)要求的输入图像大小往往是一致的,而通常的方法是缩放图像至固定的大小,这样会导致图片失真,特别是在处理视线估计任务时,这种缩放法会严重影响网络的性能,带来偏差。为了解决这个问题,我们引入图像标准化技术:即通过图像的仿射变换,将图像转换到一个标准化的相机空间,在这个标准化相机空间中,所有图像中的人的头部和相机的距离是一样的,且头部姿态也是一样的。具体来说,可以分为以下三个步骤:
1)以相机坐标系为世界坐标系,已知双眼中心坐标ec和头部姿态旋转矩阵r,先将相机旋转至相机的z轴对准两眼中心。这一步只需让相机z轴对齐双眼中心坐标ec,可得旋转后的相机z轴为rz=ec/||ec||。
2)然后相机绕z轴旋转至相机的x轴和头部姿态的x轴位于同一平面上。由于头部姿态的x轴为已知量,为头部姿态旋转矩阵r的第一列rx,要让旋转后的相机x轴rx和rx位于同一平面,则需满足旋转后的相机y轴ry垂直于此平面。又ry垂直于旋转后的相机z轴rz,因此,ry可由rx和rz的叉积求得:
ry=rx×rz(1)
rx可由ry和rz的叉积求得:
rx=ry×rz(2)
于是,得到相机的旋转矩阵rc=[rx,ry,rz]。
3)标准化双眼中心到相机中心的距离。这一步可通过缩放相机的z轴实现,即定义一个尺度缩放矩阵s=diag(1,1,d/||ec||),其中d为双眼中心到相机中心的标准化距离,本申请中取d=600mm。
通过以上三步,我们可以得到一个相机转换矩阵m=src。在实际操作中,要得到标准化的图像,需要经过一个仿射变换矩阵
最后,将标准化后的图片送入注意力机制的卷积神经网络。
该网络的注意力模块由双通道组成:上层的称为主通道,由resnet的残差模块等流行的cnn模块构成;下层称为掩码通道,是一个自底向上-自顶向下的沙漏网络。对于一个输入图像i,记主通道的输出为f(i),掩码通道的输出为a(i),则注意力模块的输出m(i)可以根据f(i)和a(i)的点乘得到:
mc(i)=fc(i)+fc(i)·ac(i)(3)
式中:fc(i)表示f(i)的第c个通道,ac(i)表示a(i)的第c个通道,符号·表示矩阵的点乘。
通过堆叠这样的注意力模块,形成深度的注意力机制cnn。这样,在视线估计任务中,注意力模块能从底层开始寻找眼睛瞳孔在图像中的位置,并不断地增加该位置的权重而减少其他不相干位置的权重,到高层时,提取的特征基本来自于眼睛瞳孔的位置。将这些特征送入分类器中进行分类,能得到高准确率。
在实验中,我们测试resnet-50我们将第一个卷积层中卷积核的大小由原来的7×7修改为5×5,以适应我们的小尺寸图像输入(36×224),并把最后一层的softmax层改成全连接层,用于回归两个注视角度;由于视线估计是一个依赖于眼部位置的任务,我们认为网络的位置不敏感性会造成性能的下降。基于resnet-50的注意力网络称之为attentiongazenet-res。损失函数:
通过这个注意力机制的卷积神经网络,我们视线估计误差仅只有4.8°。
本发明的一种基于注意力机制的卷积神经网络视线估计方法及系统,设计采用注意力机制网络使得在高层提取特征的特征基本来自于瞳孔的位置,从而更好的提高准确率,减小误差。并且通过关键点检测从而使得裁剪出来的图片分辨率更小,从而使快速性得到提高。
本发明的一种基于注意力机制的卷积神经网络视线估计方法及系统,具有准确(精确度得到提高,可以达到误差仅有4.8°)、客观、便捷(无需苛刻的实验室环境,无需特殊的设备,只需一个普通的相机或者智能手机)、快速的优点。
以上对本发明的具体实施例进行了详细描述,但其只是作为范例,本发明并不限制于以上描述具体实施例。对于本领域技术人员而言,任何对本发明进行的等同修改和替代也都在本发明的范畴之中。因此,在不脱离本发明的精神和范围下所作的均等变换和修改,都涵盖在本发明范围内。
- 还没有人留言评论。精彩留言会获得点赞!