一种轻量级快速人脸识别方法与流程
本发明涉及人脸识别领域,特别是涉及一种轻量级快速人脸识别方法。
背景技术:
在过去十年里,深度神经网络,尤其是深度卷积神经网络,极大地提高了人脸识别的精度。然而,这些技术不仅计算成本高,而且测试集和训练集之间的相关性高,但在大量应用中,需要在一定规模的数据库上进行高效快速的人脸识别,然而实时性已成为这些应用的一项巨大的挑战。
人脸识别的过程是将人脸图像和人脸数据库的图像一一比对的过程,想要识别人脸图像,必须遍历人脸数据集中的所有的图像,找出与被识别图像最接近的数据库中的图像。因此,对于比较大规模的数据集而言,快速的人脸识别很难实现。现有一些论文提出了一些方法。这些方法主要集中在两个方面:特征描述和图像索引。
特征描述的选择对于人脸识别的准确性至关重要。子空间是人脸识别的主要方法。由于低计算和高性能的特点,子空间算法已经成为人脸识别的主要方法之一,此外,还有其他识别方法,如lbp(localbinarypatterns局部二值模式),sift(scale-invariantfeaturetransform尺度不变特征变换)和hog(histogramoforientedgradient方向梯度直方图)。ahonen等人,将面部图像划分为若干区域,从中提取lbp特征分布(localbinarypatterns局部二值模式)并将其连接成用作面部描述符的增强特征向量。cui等人将每个图像划分为若干空间块,然后通过对在块内采样的无位置补片的非负稀疏码进行求和来表示每个块。li等人提出了一种基于梯度方向直方图(hog)特征提取的人脸识别方法。在该方法中,haar特征分类器用于提取原始数据,然后从图像数据中提取hog特征并用pca(principalcomponentanalysis主成分分析方法)降维,并使用支持向量机(svm)算法识别人脸。一般来说,快速人脸识别的图像索引可以分为两类:一类是由粗到精的层次匹配索引,它根据逐渐严格的约束不断地剔除不合格数据,另一类是聚类索引。cao、zhou等人将整个数据库划分为若干个集群。cao直接学习矢量回归函数,从图像中推断出整个面部形状,得到一组面部标志,并明确最小化训练数据上的对齐误差。固有的形状约束在级联学习框架中自然地编码到回归量中,并且在测试期间从粗到精应用,而不像在大多数先前的方法中那样使用固定的参数形状模型。zhou等人提出了一种面部识别系统的通用分类框架。在该框架内,提出了一种数据采样策略,用于在从数千个面部图像中采样图像对以准备训练数据集时解决数据不平衡问题。上面提到的特征描述符和图像索引在小规模数据库上表现良好,但是当数据量增加时性能明显降低。处理大量数据库的能力与特征或分类器的计算成本之间存在相互约束。
技术实现要素:
本发明的目的是为了克服现有技术中的不足,提供一种轻量级快速人脸识别方法,该方法可以适用于大型人脸数据集上,实现快速人脸图像的定位,同时对于计算要求较低,对硬件的性能要求较低,能在大量低廉的硬件上实现。
本发明的目的是通过以下技术方案实现的:
一种轻量级快速人脸识别方法,基于预处理组件和索引组件,由预处理组件提取人脸图像的特征值和特征向量;之后预处理组件将具有相似特征值和特征向量的图像分组到一个聚类中;在索引组件中,基于聚类结果并以自下而上的方式构建二叉树索引,当用户启动识别任务时,将过滤掉无效的集群并将所需的面部图像返回给用户;具体包括以下步骤:
(1)提取特征,将面部图像视为一个m*n矩阵a,通过2dpca(二维主分量分析)算法进行特征提取;
(2)对于具有n个图像的人脸数据集f={f1,f2,……fn},每个面部图像fi(i∈[1,n])是由m个特征向量构成(e1,e2,……,em);然后,利用聚类算法将人脸数据集划分为k个集群;形成集群的方法是:以2的幂取k值,以构建一个平衡的二叉树,再最小化集群中每个点到集群中点距离的平方和,以增强聚类结果;
(3)在上一个组件形成的集群上构建二叉树索引,索引的叶节点是k个簇;每个二叉树索引的中间节点c具有两个且仅有两个子节点,c表示两个子节点集群的中心节点;
(4)进行人脸识别:从二叉树索引的根节点开始向下索引;对于想要识别的人脸图像x,分别计算当前节点的两个子节点与x之间的距离,如果距离差大于阈值δ,将判断范围限定在更接近的子节点中;否则,说明面部图像位于两个簇的边界;当面部图像在边界或面部图像在叶节点中时,将停止判断;并返回当前节点表示的所有集群;最后在返回的集群中,计算人脸图像x与集群中每个人脸的距离差,最小的距离差的人脸就是识别的人脸。
进一步的,在二叉树索引中,给定叶簇c=c1,c2,……,ck,对于任何面部图像f,f都可以被分到一个且仅有一个簇中;对于任何节点x、y,x是y的父节点,则y表示的范围都包含在x的范围内。
进一步的,所述索引组件采用两级存储架构:整个索引存储在内存中,人脸数据集以文件的形式保存在磁盘中;对于每个人脸图像,都有一个相应的文本文件,记录特征值信息;每个图像及其相应的文本文件存储在同一文件夹中,该文件夹有唯一的标识;同时,被分到在同一集群中的图像存储在同一父类文件夹中,父类文件夹的名称定义为集群的中心节点c。
与现有技术相比,本发明的技术方案所带来的有益效果是:
本发明方法以提供稳定的人脸识别服务。它满足实时面部检索需求。该方法包括用于创建图像集群的数据预处理组件和用于提供快速图像检索的多级索引组件。在预处理组件中提取人脸图像的特征值和特征向量,并根据特征值和特征向量的相似性将这些图像分到不同的簇中。在索引组件中在这些集群上构建了一个二叉树索引,以便快速搜索。此外,还提出了两级存储架构以提供更好的识别服务。
附图说明
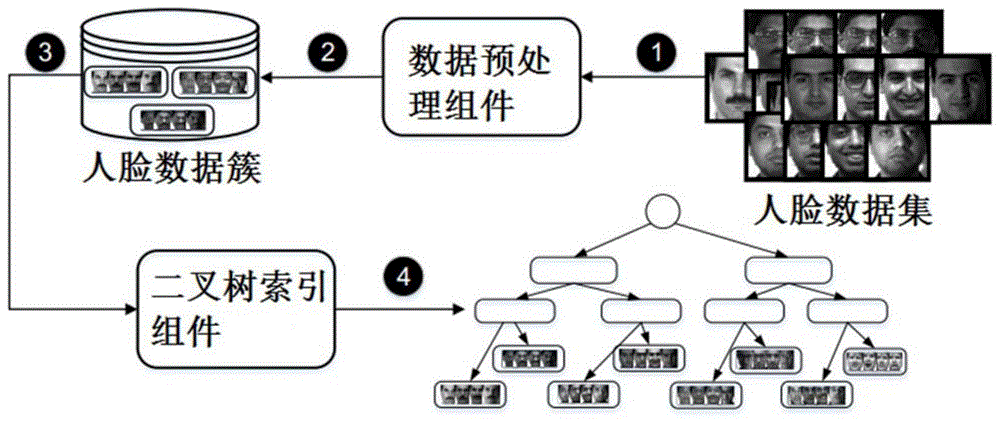
图1是本发明方法采用的框架的结构示意图。
图2是一个具有8个簇和4个层的索引示例。
图3是二叉树构建算法的描述。
图4面部图像识别过程算法示意图。
图5是阈值δ对人脸识别的影响示意图。
图6表示群集的数量对实验影响的示意图。
图7是本发明方法与其他方法对比图。
具体实施方式
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参见图1,本发明采用的框架主要包含两个组件,包括数据预处理组件和二叉树索引组件。这两个组件在加速图像搜索和相互交互方面起着不同的作用。首先,由数据预处理组件提取人脸图像的特征值和特征向量。然后,数据预处理组件将具有相似特征值和特征向量的图像分组到一个聚类中。在索引组件中,二叉树是以自下而上的方式基于人脸数据簇构建的。当用户启动识别任务时,所提出的方案将过滤掉无效的集群并将所需的面部图像返回给用户。
这两个组件的构建过程主要是:
(1)预处理组件
数据预处理组件侧重于人脸识别的两个步骤—人脸检测和特征提取。人脸检测是一种识别数字图像中人脸的技术。特征提取从面部图像中获取信息特征。面部图像可以被视为一个m*n矩阵a。特征提取是保留特征值并剔除冗余信息的过程。本发明中,考虑使用2dpca(二维主分量分析)算法进行特征提取。2dpca是一种基于pca(主成分分析方法)的改进的算法,具有实现简单,时间复杂度低的优点。与传统的pca算法相比,2dpca不需要将图像转换为一维向量,这大大减少了数据的维数,能适用于大型数据集。
在预处理之后,数据集转换如下:对于具有n个图像的人脸数据集f={f1,f2,……fn},每个面部图像fi(i∈[1,n])是由m个特征向量构成(e1,e2,……,em)。然后,利用聚类算法将数据库划分为k个集群。由于要构建一个平衡的二叉树,因此集群的数量必须是2的幂。为了获得更好的聚类效果,尝试最小化集群中每个点到集群中点距离的平方和,以增强聚类结果。
(2)索引组件
二叉树索引是在上一个组件形成的集群上构建的。索引的叶节点是k个簇。每个中间节点c具有两个且仅有两个子节点。它由其子节点创建,c表示两个集群的中心节点。二叉树有两个特征:第一点,给定叶簇c=c1,c2,……,ck,对于任何面部图像f,f都可以被分到一个且仅有一个簇中;第二点,对于任何节点x、y,x是y的父节点,则y表示的范围都包含在x的范围内。
参见图2,显示了一个具有8个簇和4个层的索引示例。索引的叶节点是8个簇。每个中间节点具有两个且仅有两个子节点,它由其子节点创建。
参见图3,这是对二叉树构建算法的描述。构建索引的过程大致是:首先,根据聚类算法将训练数据集划分为2n个不相交的聚类。然后随机地选择一个簇u。根据欧几里德距离找到最近的簇v。为了创建中间节点,计算簇u和v的中心点c。然后c就是u和v的父节点。这个过程将迭代执行,直到得到树的根。
将该框架应用于人脸查找时,主要是利用索引来加速人脸识别。索引是自下而上构建的,而在使用过程中,遵循自上而下的原则。首先,考虑这种情况:如果要识别的面部图像f位于两个聚类的边界处,则将f分类到任何聚类中是不合适的。这是因为最近的节点可能不存在于最近的集群中。为了保持高精度,可靠的方法是判断这两个簇中的所有元素。因此,参见图4,识别的过程首先从根节点执行。然后,分别计算两个子节点之间的距离。如果距离差大于阈值δ,将判断范围限定在更接近的子节点中;否则,说明f位于两个簇的边界。当f在边界或f在叶节点中时,将停止判断。然后返回当前节点表示的所有集群。寻找与f具有最小距离的数据。对于识别算法,阈值δ的选择由性能决定。
本发明中构建的二叉树索引的每个节点仅保留中心节点和簇的半径。因此,二叉树索引的存储并不占太多空间。为了提供更好的实时人脸识别服务,采用两级存储架构:可以将整个索引存储在内存中,人脸数据集以文件的形式保存在磁盘中。对于每个人脸图像,都有一个相应的文本文件,记录特征值信息。每个图像及其相应的文本文件存储在同一文件夹中,该文件夹有唯一的标识。同时,被分到在同一集群中的图像存储在同一父类文件夹中,这个父类文件夹的名称由集群的管理。
下面简要介绍实验环境。实验在具有3.40ghzcpu和16gb内存的单台计算机上执行。使用的软件是matlab2017b。实验通过标准数据库(如youtubeface、cas-peal和lfw)的大量图像和视频进行评估。youtubeface是一个面部视频数据库,旨在研究视频中无约束的人脸识别问题。该数据集包含3425个不同人的视频。所有视频都是从youtube上下载的。cas-peal由中国科学院计算技术研究所完成,包含了10300名志愿者的不同面部图像。lfw数据集用来研究无约束人脸识别的问题。该数据集包含从网络收集的13000多张面部图像。每张脸都标有图中人物的名字。采用precision和recall作为衡量识别准确度的指标。还计算每个面部图像的平均识别时间作为表示处理速度的时间成本。
参见图5,讨论阈值δ对人脸识别的影响。在这个问题中使用的数据集是lfw。由于簇k的数量应该是2的幂,将k设置为4069(212)。不需要担心由大量集群引起的性能下降,因为本发明中提出的索引可以动态地确定查找范围。图5显示出了在k值固定的情况下具有不同阈值δ的人脸识别的准确度和速度。根据该图,可以得出结论,识别速度增加而精度随着δ减小而减小。当δ从3增长到4时,精度显着提高。当δ大于5时,精度继续增加,但不像过去那么快。此外,当δ大于4.5时,图5显示了时间成本增加的显着趋势。因此得出结论:当δ设置为4.5时,可以在准确度和速度之间取得平衡。
参见图6,讨论群集的数量如何影响实验。使用的数据集是lfw并将δ设置为4.5。n表示2的次方。将n从7设置为13。当n增加时,数据分割的单位变小。在这种情况下,cb树索引可以有效地消除大多数无效数据,并且识别时间变短。理论上,n越大,得到的识别时间越短,但当数据被过度细化后,使得存储分配不合理,此外,精度也将降低。
参见图7,将本发明方法和其他方法进行了比较。与深度学习算法相比,在本发明中使用的方法表明在准确性方面没有优势。但它在识别速度方面具有很大的优势。可确保当识别速度增加时,本发明方法的准确性与其他方法的准确性没有太大差别。
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!