一种基于实际路网环境的网约拼车站点选址方法与流程
本发明属于交通运输规划与管理中的公共交通领域,具体涉及一种基于实际路网环境的网约拼车站点选址方法。
背景技术:
作为“互联网+共享经济”的代表,“拼车”被认为是一种公共交通服务改良式的出行模式,能在城市公共交通服务盲区发挥替补作用。现有的网约拼车采取的是任意地点的自由拼车模式,当乘客定位较偏或需搭载多名乘客时,会造成网约车辆绕行距离较大、乘客等待时间较长,从而使得用户行程无法得到保障。
站点拼车由滴滴公司率先发行,主要目的是为了减少现存网约拼车服务中因接拼友而产生的绕路里程,且拼车站点的设立允许车辆在同一地点搭载多名乘客而不会增加额外地停车次数。目前,我国站点拼车的发展仍处初步探索阶段,关于拼车站点选址问题的研究较为缺乏。然而在现实生活中,合理的拼车站点位置对提高拼车匹配率、增强用户体验感、促进拼车行业的可持续发展等方面具有较强的现实意义。此外,在拼车站点选址时考虑实际路网环境,可使站点选址的结果更加贴近现实情况且容易实施。
因此,有必要设计一种基于实际路网环境的网约拼车站点选址方法对拼车站点进行合理布设,为当前站点拼车的发展提供相应的参考。
技术实现要素:
本发明提供一种能满足实际路网中乘客需求、最小化乘客步行距离、构思巧妙合理的基于实际道路环境的网约拼车站点选址方法。
为了解决上述技术问题,本发明采用的一种基于实际路网环境的网约拼车站点选址方法,包括以下步骤:
(1)利用k-means聚类法对乘客预约需求点进行分组,并确定各分组的聚类中心;
(2)根据所述各分组乘客需求点和聚类中心的空间位置,确定各分组对应的实际路网分析区;
(3)取路网分析区zi中任一路段[va,vb],计算该分组所有乘客需求点对应的路段[va,vb]分割点;
(4)对于可能存在于路段[va,vb]上的拼车站点x,计算分析区内所有乘客需求点到站点x的最短路距离,并将距离求和,来确定针对该路段的最优站点位置;
(5)对路网分析区zi中其它路段重复步骤(3)和步骤(4)的操作,再比较各路段的最短距离之和,确定最优站点的所在的路段和位置。
进一步的,本发明中,步骤(1)中,聚类中心点个数确定的具体步骤为:
(11)收集乘客预约需求点的空间位置坐标信息,包括:上车点和下车点经纬度坐标;
(12)基于k-means聚类算法,当聚类中心为k时,计算每个聚类范围内的所有乘客需求点与对应聚类中心ki的欧式距离,取距离最大值
(13)对于每个聚类中心范围,以拼车站点服务半径r为约束,判断步骤(12)计算得到的距离最大值
(14)取k=k+1,重复步骤(12)和步骤(13)。
进一步的,本发明中,步骤(13)中,拼车站点服务半径确定方法如下:
站点服务半径r为乘客最大步行范围,取500m,站点服务范围是以聚类中心为圆心,以r为半径向外辐射的圆形区域范围。
进一步的,本发明中,步骤(2)中,各分组对应的实际路网分析区确定方法如下:
设unit为路网节点能构成的最小封闭多边形,为最小路网单元;
路网分析区即为包含一个聚类范围所有乘客需求点的最小实际路网区域;
(21)对一个聚类范围ki内的乘客需求点进行判断,若其位于路网单元unit内或边界处,则记录该单元包含的节点ni(包括顶点)和路段ei(包括边界),路段也可用其端点表示,如路段[v1,v2];
(22)得到包含聚类范围ki内所有需求点的节点集ni={n1,n2,n3....}和路段集ei={e1,e2,e3....和};
(23)路网分析区zi用图论方法可表示zi=(ni,ei)。
进一步的,本发明中,步骤(3)中,乘客需求点对应的路段分割点确定方法如下:
说明:最短路距离均采用实际网络距离,而不是欧几里得距离;
va和vb代表一个路段两端点,路段及路段长度均可用[va,vb]表示;pi和pj之间的最短路用
(31)由所述的步骤(23)可知,一个路网分析区zi中含有节点数ni,路段数ei,含有的乘客需求点集合为pi={p1,p2,p3....};
(32)对于路段[va,vb]([va,vb]∈ei),以乘客需求点pi(pi∈pi)为起点,分别以路段[va,vb]的两端点va和vb为终点,运用dijkstra算法分别计算最短路径距离,记为
(33)以pi、va、vb为三角形的顶点,以
进一步的,本发明中,步骤(33)中,利用三角形不等式关系寻找路段[va,vb]的分割点,具体步骤如下:
(331)在三角形pivavb中,有以下关系成立:
则对于乘客需求点pi来说,在路段[va,vb]存在的一个分割点espi,使得
(332)分割点espi在路段[va,vb]上的位置可用分割点espi与va的距离占路段[va,vb]总长度的比例
设路段距离分布函数为
分割点espi的位置计算公式如下:
分割点espi距离路段起点va的距离计算公式如下:
[va,vb]——路段[va,vb]的长度;
(334)对乘客需求点集合pi中的所有对象,可求出其对应于路段[va,vb]上的分割点集合为
进一步的,本发明中,步骤(4)中,对于可能存在于路段[va,vb]上的拼车站点x,计算分析区内所有乘客需求点到站点x的最短路距离,将距离求和,来确定针对该路段的最优站点位置,具体步骤如下:
初始化,最短路距离集合
(41)取路段[va,vb]上任意一点x作为拼车站点,设站点x的路段[va,vb]占比为θ;
(42)结合权利要求5中的步骤(32)和权利要求6中的步骤(333)所述,可知当
则从乘客需求点pi到站点x最短路径距离可表示为如下的线性分段函数,
(43)以路网分析区zi内所有乘客需求点集合pi为对象,重复步骤(42)操作,计算pi中每个对象到站点的最短路径距离,结果存入集合dθ[va,vb]中,记为dθ[va,vb]={dp1(θ),dp2(θ),dp3(θ)....};
(44)将距离集合中的元素求和,记为∑dθ[va,vb];
进一步的,本发明中,步骤(5)中,对路网分析区zj中其它路段重复步骤(3)和步骤(4)的操作,再比较各路段的最短距离之和,确定最优站点的所在的路段和位置,具体步骤如下:
初始化,距离和集合
(51)对路网分析区zi中路段集合ei中其他元素重复步骤(3)和步骤(4)中对路段[va,vb]的相同操作,分别将距离求和得到的值存入集合d中,则d={∑dθ[e1],∑dθ[e2],∑dθ[e3]...}
(52)记sd(e1)=min∑dθ[e1],计算∑dθ[e1]的最小值,并记录sd(e1)值和对应的θ值;
(53)同样的,类似对路段e1的操作,分别计算集合d中所有元素的最小值,结果存入集合sd中,即sd={sd(e1),sd(e2),sd(e3),sd(e4)....},并记录各自对应的θ值;
(54)比较集合sd中的所有元素,最小的元素值对应的路段和θ值即为路网分析区zi中拼车站点x存在的最优路段及位置。
与现有技术相比,本发明的技术方案具有以下有益效果:
1.本发明能够基于乘客预约需求数据对拼车站点进行合理布设,填补了网约拼车站点选址方法的空白,为当前站点拼车服务中的站点选址层面提供相应的参考和方法支撑。
2.本发明提出的拼车站点选址方法依托于真实道路网络环境,摒弃了传统人为经验主观设置调整方法的弊端,确保了拼车站点布设的科学性、准确性、合理性和有效性。
3.本发明基于路段分割点对任一条路段的拼车站点位置进行优化,再比较各路段的结果来确定最终的最优站点所在路段及位置,方法合理且计算简便。
附图说明
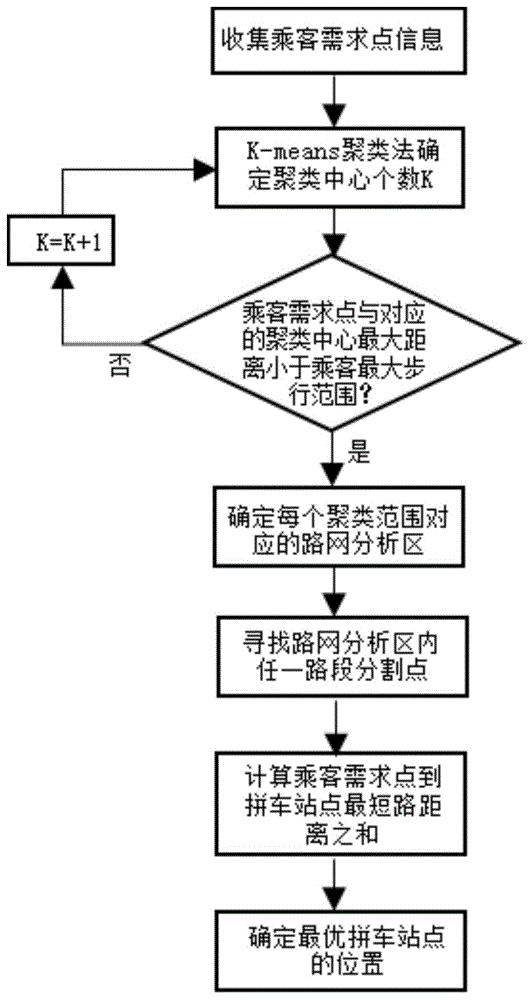
图1是本发明的流程图。
图2是本发明所述的实际路网结构。
图3是本发明所述的路网分析区z2。
具体实施方式
下面结合说明书附图和实施例,对本发明的技术方案作进一步详细说明。
实施例1:参见图1,一种基于实际路网环境的网约拼车站点选址方法,包括以下步骤:
(1)利用k-means聚类法对乘客预约需求点进行分组,并确定各分组的聚类中心;
(2)根据所述各分组乘客需求点和聚类中心的空间位置,确定各分组对应的实际路网分析区;
(3)取路网分析区zi中任一路段[va,vb],计算该分组所有乘客需求点对应的路段[va,vb]分割点;
(4)对于可能存在于路段[va,vb]上的拼车站点x,计算分析区内所有乘客需求点到站点x的最短路距离,并将距离求和,来确定针对该路段的最优站点位置;
(5)对路网分析区zi中其它路段重复步骤(3)和步骤(4)的操作,再比较各路段的最短距离之和,确定最优站点的所在的路段和位置。
进一步的,本发明中,步骤(1)中,聚类中心点个数确定的具体步骤为:
(11)收集乘客预约需求点的空间位置坐标信息,包括:上车点和下车点经纬度坐标;
(12)基于k-means聚类算法,当聚类中心为k时,计算每个聚类范围内的所有乘客需求点与对应聚类中心ki的欧式距离,取距离最大值
(13)对于每个聚类中心范围,以拼车站点服务半径r为约束,判断步骤(12)计算得到的距离最大值
(14)取k=k+1,重复步骤(12)和步骤(13)。
本发明中,步骤(13)中,拼车站点服务半径确定方法如下:
站点服务半径r为乘客最大步行范围,取500m,站点服务范围是以聚类中心为圆心,以r为半径向外辐射的圆形区域范围。
本发明中,步骤(2)中,各分组对应的实际路网分析区确定方法如下:
设unit为路网节点能构成的最小封闭多边形,为最小路网单元;
路网分析区即为包含一个聚类范围所有乘客需求点的最小实际路网区域;
(21)对一个聚类范围ki内的乘客需求点进行判断,若其位于路网单元unit内或边界处,则记录该单元包含的节点ni(包括顶点)和路段ei(包括边界),路段也可用其端点表示,如路段[v1,v2];
(22)得到包含聚类范围ki内所有需求点的节点集ni={n1,n2,n3....}和路段集ei={e1,e2,e3....和};
(23)路网分析区zi用图论方法可表示zi=(ni,ei)。
本发明中,步骤(3)中,乘客需求点对应的路段分割点确定方法如下:
说明:最短路距离均采用实际网络距离,而不是欧几里得距离;
va和vb代表一个路段两端点,路段及路段长度均可用[va,vb]表示;pi和pj之间的最短路用
(31)由所述的步骤(23)可知,一个路网分析区zi中含有节点数ni,路段数ei,含有的乘客需求点集合为pi={p1,p2,p3....};
(32)对于路段[va,vb]([va,vb]∈ei),以乘客需求点pi(pi∈pi)为起点,分别以路段[va,vb]的两端点va和vb为终点,运用dijkstra算法分别计算最短路径距离,记为
(33)以pj、va、vb为三角形的顶点,以
本发明中,步骤(33)中,利用三角形不等式关系寻找路段[va,vb]的分割点,具体步骤如下:
(331)在三角形pivavb中,有以下关系成立:
则对于乘客需求点pi来说,在路段[va,vb]存在的一个分割点espi,使得
(332)分割点espt在路段[va,vb]上的位置可用分割点espi与va的距离占路段[va,vb]总长度的比例
设路段距离分布函数为
分割点espi的位置计算公式如下:
分割点espi距离路段起点va的距离计算公式如下:
[va,vb]——路段[va,vb]的长度;
(334)对乘客需求点集合pi中的所有对象,可求出其对应于路段[va,vb]上的分割点集合为
本发明中,步骤(4)中,对于可能存在于路段[va,vb]上的拼车站点x,计算分析区内所有乘客需求点到站点x的最短路距离,将距离求和,来确定针对该路段的最优站点位置,具体步骤如下:
初始化,最短路距离集合
(41)取路段[va,vb]上任意一点x作为拼车站点,设站点x的路段[va,vb]占比为θ;
(42)结合权利要求5中的步骤(32)和权利要求6中的步骤(333)所述,可知当
则从乘客需求点pi到站点x最短路径距离可表示为如下的线性分段函数,
(43)以路网分析区zi内所有乘客需求点集合pi为对象,重复步骤(42)操作,计算pi中每个对象到站点的最短路径距离,结果存入集合dθ[va,vb]中,记为dθ[va,vb]={dp1(θ),dp2(θ),dp3(θ)....};
(44)将距离集合中的元素求和,记为∑dθ[va,vb];
进一步的,本发明中,步骤(5)中,对路网分析区zi中其它路段重复步骤(3)和步骤(4)的操作,再比较各路段的最短距离之和,确定最优站点的所在的路段和位置,具体步骤如下:
初始化,距离和集合
(51)对路网分析区zi中路段集合ei中其他元素重复步骤(3)和步骤(4)中对路段[va,vb]的相同操作,分别将距离求和得到的值存入集合d中,则d={∑dθ[e1],∑dθ[e2],∑dθ[e3]...}
(52)记sd(e1)=min∑dθ[e1],计算∑dθ[e1]的最小值,并记录sd(e1)值和对应的θ值;
(53)同样的,类似对路段e1的操作,分别计算集合d中所有元素的最小值,结果存入集合sd中,即sd={sd(e1),sd(e2),sd(e3),sd(e4)....},并记录各自对应的θ值;
(54)比较集合sd中的所有元素,最小的元素值对应的路段和θ值即为路网分析区zi中拼车站点x存在的最优路段及位置。
应用实施例1:参见图1-图3,一种基于实际路网环境的网约拼车站点选址方法,包括以下步骤:
(1)利用k-means聚类法对乘客预约需求点进行分组,并确定各分组的聚类中心。本实施例选取了部分真实道路网,如图2所示,路网包含11个节点,19条路段。在路网上随机产生乘客拼车预约需求点。通过乘客最大步行距离范围约束,采用k-means聚类法可得聚类中心个数为3,编号分别为k1、k2、k3。
(2)根据所述各分组乘客需求点和聚类中心的空间位置,确定各分组对应的实际路网分析区。这里及后续内容均以聚类中心k2为例进行详细说明,其他聚类范围操作类似。通过对聚类中心k2范围内的需求点(编号为p1、p2、p3)存在路网范围进行判断,可确定其对应的路网分析区为z2,如图3所示。路网分析区z2包含的节点集合n2和路段集合e2分别为n2={v5,v4,v6,v7],e2={[v5,v4],[v4,v6],[v6,v7],[v5,v6],[v5,v7]}。
(3)取路网分析区z2中任一路段[v5,v6],计算该分组所有乘客需求点对应的路段[v5,v6]分割点。分析区z2中路段权值分别为[v5,v4]=6,[v4,v6]=7,[v6,v7]=4,[v5,v6]=7,[v5,v7]=5。乘客需求点p1、p2、p3在路段上的位置分别为[v5,p1]=4,[v4,p2]=3,[v5,p3]=2。
乘客需求点p1对应的路段[v5,v6]分割点计算如下:
同理,可计算乘客需求点p2和p3对应的路段[v5,v6]分割点为
(4)对于可能存在于路段[v5,v6]上的拼车站点x,计算分析区内所有乘客需求点到站点x的最短路距离,将距离求和,来确定针对该路段的最优站点位置。各乘客需求点到站点x的最短路距离可表示为
将距离求和得到∑dθ[v5,v6]为
(5)对路网分析区z2中其它路段重复步骤(3)和步骤(4)的操作,再比较各路段的最短距离之和,确定最优站点的所在的路段和位置。对于分段函数∑dθ[v5,v6]来说,由于sd([v5,v6])=min∑dθ[v5,v6],当θ=4/7时,可得sd([v5,v6])=13;
相似的,可计算得到sd([v5,v7])=19,sd([v4,v5])=15,sd([v4,v6])=18,sd([v6,v7])=18;因此,集合sd={13,19,15,18},最小元素为13,即为sd([v5,v6]);
在路网分析区z2中,拼车站点x存在的最优选址为路段[v5,v6]上且距点v5距离为4/7路段长度的位置处。
对其它聚类中心范围确定最优拼车站点位置操作均与上述k2类似。
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!