用户信用的确定方法及装置、存储介质、终端与流程
本发明涉及计算机技术领域,尤其涉及一种用户信用的确定方法及装置、存储介质、终端。
背景技术:
近年来,消费金融、小额贷款、p2p等借贷行业不断发展,国内的征信制度却仍有许多缺陷,这导致逾期坏账率居高不下。而最为常见的逾期欠款催收,往往由于采用的催收策略不同,产生了催收效果的差异。比如:可能会产生对因偶然遗忘等原因导致的低风险高金额客户采用较为过激的催收方式,而对高风险低金额客户没有采用有效催收手段。
目前,存在基于用户过往的信用信息构建模型,进而对用户的信用进行预测评估的方法。
然而,在个人信贷场景中,随着市场推广渠道的不断变化,申请的人群会发生很大的变化,这对于风控模型的鲁棒性会有很大的挑战,往往发生上线应用一段时间后,预测效果下降的问题。
技术实现要素:
本发明解决的技术问题是提供一种用户信用的确定方法及装置、存储介质、终端,可以在采用ftrl算法更新模型时,有机会选择更适当的信用信息,从而有机会降低数据量较大的早期数据对用户信用的影响。
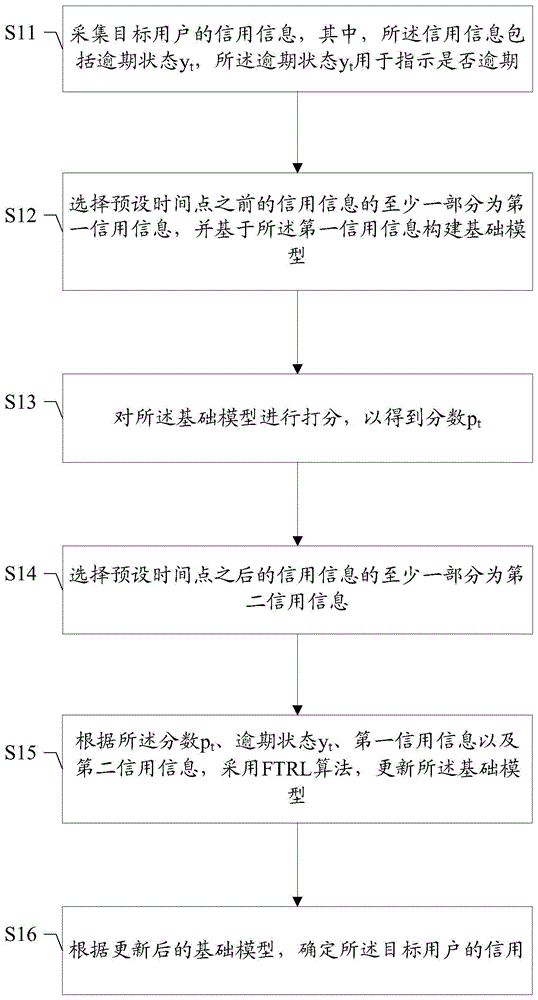
为解决上述技术问题,本发明实施例提供一种用户信用的确定方法,包括以下步骤:采集目标用户的信用信息,其中,所述信用信息包括逾期状态yt,所述逾期状态yt用于指示是否逾期;选择预设时间点之前的信用信息的至少一部分为第一信用信息,并基于所述第一信用信息构建基础模型;对所述基础模型进行打分,以得到分数pt;选择预设时间点之后的信用信息的至少一部分为第二信用信息;根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型;根据更新后的基础模型,确定所述目标用户的信用。
可选的,选择预设时间点之前的信用信息的至少一部分为第一信用信息包括:采用第一预设比例,选择预设时间点之前的信用信息为第一信用信息;选择预设时间点之后的信用信息的至少一部分为第二信用信息包括:采用第二预设比例,选择预设时间点之后的信用信息为第二信用信息;其中,所述第一预设比例小于第二预设比例。
可选的,每个信用信息为单维向量或者多维向量;其中,所述单维向量为所述逾期状态yt;所述多维向量的多个参数选自以下参数中的多项:收入信息、性别、交易流水以及逾期状态yt。
可选的,根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型包括:
采用下述公式,确定权重w:
gi=(pt-yt)xi;
zi←zi+gi-σiwt,i;
或者,
wt,i=0,其中,|zi|≤λ1;
其中,xi用于表示序号为i的单个信用信息,gi、ni、σi、zi、λ1以及λ2为所述ftrl算法的中间变量。
为解决上述技术问题,本发明实施例提供一种用户信用的确定装置,包括:采集模块,适于采集目标用户的信用信息,其中,所述信用信息包括逾期状态yt,所述逾期状态yt用于指示是否逾期;选择及构建模块,适于选择预设时间点之前的信用信息的至少一部分为第一信用信息,并基于所述第一信用信息构建基础模型;打分模块,适于对所述基础模型进行打分,以得到分数pt;选择模块,适于选择预设时间点之后的信用信息的至少一部分为第二信用信息;更新模块,适于根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型;信用确定模块,适于根据更新后的基础模型,确定所述目标用户的信用。
可选的,所述选择及构建模块包括:第一选择子模块,适于采用第一预设比例,选择预设时间点之前的信用信息为第一信用信息;所述选择模块包括:第二选择子模块,适于采用第二预设比例,选择预设时间点之后的信用信息为第二信用信息;其中,所述第一预设比例小于第二预设比例。
可选的,每个信用信息为单维向量或者多维向量;其中,所述单维向量为所述逾期状态yt;所述多维向量的多个参数选自以下参数中的多项:收入信息、性别、交易流水以及逾期状态yt。
可选的,所述更新模块包括权重确定子模块,所述权重确定子模块采用下述公式,确定权重w:
gi=(pt-yt)xi;
zi←zi+gi-σiwt,i;
或者,
wt,i=0,其中,|zi|≤λ1;
其中,xi用于表示序号为i的单个信用信息,gi、ni、σi、zi、λ1以及λ2为所述ftrl算法的中间变量。
为解决上述技术问题,本发明实施例提供一种存储介质,其上存储有计算机指令,所述计算机指令运行时执行上述用户信用的确定方法的步骤。
为解决上述技术问题,本发明实施例提供一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行上述用户信用的确定方法的步骤。
与现有技术相比,本发明实施例的技术方案具有以下有益效果:
在本发明实施例中,采集目标用户的信用信息,其中,所述信用信息包括逾期状态yt,所述逾期状态yt用于指示是否逾期;选择预设时间点之前的信用信息的至少一部分为第一信用信息,并基于所述第一信用信息构建基础模型;对所述基础模型进行打分,以得到分数pt;选择预设时间点之后的信用信息的至少一部分为第二信用信息;根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型;根据更新后的基础模型,确定所述目标用户的信用。采用上述方案,在采集目标用户的信用信息之后,选择预设时间点之前的信用信息的至少一部分为第一信用信息,选择预设时间点之后的信用信息的至少一部分为第二信用信息,可以在采用ftrl算法更新模型时,有机会选择更适当的信用信息,从而有机会降低数据量较大的早期数据对用户信用的影响;进一步地,通过采用ftrl算法更新模型,可以有效利用ftrl算法计算速度快的优点,提高模型更新的效率,从而有机会更实时地对用户信用进行确定。
进一步,在本发明实施例中,采用第一预设比例,选择预设时间点之前的信用信息为第一信用信息;采用第二预设比例,选择预设时间点之后的信用信息为第二信用信息;其中,所述第一预设比例小于第二预设比例,通过减少数据量较大的早期数据的使用,增加采用近期数据,可以降低数据量较大的早期数据对用户信用的影响,提高对用户信用的确定效果。
附图说明
图1是本发明实施例中一种用户信用的确定方法的流程图;
图2是本发明实施例中另一种用户信用的确定方法的流程图;
图3是本发明实施例中一种用户信用的确定装置的结构示意图。
具体实施方式
如前所述,在现有技术中,存在基于用户过往的信用信息构建模型,进而对用户的信用进行预测评估的方法。然而,在个人信贷场景中,随着市场推广渠道的不断变化,申请的人群会发生很大的变化,这对于风控模型的鲁棒性会有很大的挑战,往往发生上线应用一段时间后,预测效果下降的问题。
本发明的发明人经过研究发现,在现有技术中,对用户的过往数据并不会在时间上进行区分,无论是数年前的数据,还是数天前的数据,均一视同仁加以使用,导致在用户的信用出现问题时,难以及时发现。具体而言,构建出的模型可能会依赖数据量较大的早期数据,仍然为该用户提供较高的评分。
在本发明实施例中,采集目标用户的信用信息,其中,所述信用信息包括逾期状态yt,所述逾期状态yt用于指示是否逾期;选择预设时间点之前的信用信息的至少一部分为第一信用信息,并基于所述第一信用信息构建基础模型;对所述基础模型进行打分,以得到分数pt;选择预设时间点之后的信用信息的至少一部分为第二信用信息;根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型;根据更新后的基础模型,确定所述目标用户的信用。采用上述方案,在采集目标用户的信用信息之后,选择预设时间点之前的信用信息的至少一部分为第一信用信息,选择预设时间点之后的信用信息的至少一部分为第二信用信息,可以在采用ftrl算法更新模型时,有机会选择更适当的信用信息,从而有机会降低数据量较大的早期数据对用户信用的影响;进一步地,通过采用ftrl算法更新模型,可以有效利用ftrl算法计算速度快的优点,提高模型更新的效率,从而有机会更实时地对用户信用进行确定。
为使本发明的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
参照图1,图1是本发明实施例中一种用户信用的确定方法的流程图。所述用户信用的确定方法可以包括步骤s11至步骤s16:
在步骤s11的具体实施中,可以采集目标用户的多种信用信息。
具体地,所述信用信息可以用于指示目标用户的还款能力和信用程度。
在具体实施中,每个信用信息可以为单维向量或者多维向量。
其中,所述单维向量可以为所述逾期状态yt;所述多维向量的多个参数可以选自以下参数中的多项:收入信息、性别、交易流水以及逾期状态yt。
具体地,所述收入信息可以用于指示目标用户的财产增加状况,所述交易流水可以用于指示目标用户的消费状况,可以理解的是,收入越高,交易流水显示的消费越低,逾期还款的可能性越小。
所述性别可以用于广泛性反映用户的收入和消费,例如女性用户有可能消费较为保守,男性用户有可能单笔开支较大,对信用状况易产生影响。
逾期状态yt用于指示该目标用户在过去是否发生过逾期行为。例如可以采用1bit的指示符进行表示,采用1表示发生过逾期行为,采用0表示未发生过逾期行为。
可以理解的是,如果目标用户在过去较长时间内一直未发生过逾期行为,则在后续一段时间内,发生逾期的概率相对较低。
在本发明实施例中,通过设置信用信息可以为多维向量,可以同时依据信用信息中的多种参数构建模型,从而提高用户考察的全面性和准确性。
在步骤s12的具体实施中,通过设置预设时间点,可以将所述预设时间点之前的信用信息的全部或部分作为第一信用信息,用于指示目标用户在过去较早一段时间内的信用情况。
在具体实施中,可以基于所述第一信用信息构建基础模型。
具体地,可以基于大量的历史数据,利用机器学习方法,构建所述基础模型。
进一步地,所述机器学习方法可以选自:xgboost以及lgbm。
需要指出的是,还可以采用其他任意适当的方式构建所述基础模型,在本发明实施例中,对于机器学习方法的选择不做限制。
在步骤s13的具体实施中,对所述基础模型进行打分,以得到分数pt。
具体地,可以采用所述基础模型作用到新的样本(例如为大量的新人群群体)上,计算出用所述基础模型为每个样本打出的模型分,作为所述分数pt。
其中,所述分数pt可以设置有上限值和下限值,例如采用百分制打分,通过在上限值和下限值之间的位置,反应出该模型的实现效果;所述分数pt还可以为无限制的具体的分数,分数越高,反应出该模型效果越好。
在本发明实施例中,可以采用任意适当的方式,采用所述基础模型进行打分,在本发明实施例中,对于如何打分的具体实现方式不做限制。
在步骤s14的具体实施中,可以将所述预设时间点之后的信用信息的全部或部分作为第二信用信息,用于指示目标用户在最近一段时间内的信用情况。
在具体实施中,可以通过设置预设时间点,控制第二信用信息的数量。可以理解的是,所述预设时间点选择的越早,所述第二信用信息越多,所述预设时间点选择的越晚,所述第二信用信息越少。
在步骤s15的具体实施中,根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型。
具体地,在现有常规应用中,在线学习和点击通过率(click-through-rate,ctr)往往采用逻辑回归(logisticregression),而传统的批量(batch)算法无法有效地处理超大规模的数据集和在线数据流,持续正规化引领(follow-the-regularized-leader,ftrl)算法在处理诸如逻辑回归之类的带非光滑正则化项(例如1范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色。
在本发明实施例中,通过选择ftrl算法更新模型,可以有效利用ftrl算法计算速度快的优点,提高模型更新的效率,从而有机会更实时地对用户信用进行确定。
进一步地,根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型的步骤可以包括:采用下述公式,确定权重w:
gi=(pt-yt)xi;
zi←zi+gi-σiwt,i;
或者,
wt,i=0,其中,|zi|≤λ1;
其中,xi用于表示序号为i的单个信用信息,gi、ni、σi、zi、λ1以及λ2为所述ftrl算法的中间变量。
需要指出的是,对xi的选取可以仅包括第二信用信息,从而可以仅基于目标用户的近期数据对该模型进行更新,以提高模型的实时性;对xi的选取可以包括第一信用信息以及第二信用信息,从而可以基于目标用户的历史数据和近期数据对该模型进行更新,以提高模型的全面性;对xi的选取可以仅包括第一信用信息,从而可以仅基于目标用户的历史数据对该模型进行更新,以提高模型的追溯性。
更具体而言,在具体实施中,可以先确定zi、λ1以及λ2,进而根据zi与λ1之间的关系,选择对应的公式计算wt,i,也即确定新的权重w,从而对所述基础模型进行更新。
其中,所述逾期状态yt的值可以选自集合{0,1},例如采用1表示目标用户发生过逾期行为,采用0表示未发生过逾期行为。
在本发明实施例中,通过选择第一信用信息和/或第二信用信息,可以在采用ftrl算法更新模型时,有机会选择更适当的信用信息,从而有机会降低数据量较大的早期数据对用户信用的影响。
参照图2,图2是本发明实施例中另一种用户信用的确定方法的流程图。所述另一种用户信用的确定方法可以包括步骤s201至步骤s207,以下对各个步骤进行说明。
在步骤s201中,采集目标用户的信用信息。
在步骤s202中,采用第一预设比例,选择预设时间点之前的信用信息为第一信用信息。
具体地,通过采用第一预设比例,选择预设时间点之前的信用信息,可以仅选择部分,减少对于目标用户的历史数据的采集量,有助于提高运算效率。
在步骤s203中,基于所述第一信用信息构建基础模型。
在步骤s204中,对所述基础模型进行打分,以得到分数pt。
在步骤s205中,采用第二预设比例,选择预设时间点之后的信用信息为第二信用信息,其中,所述第一预设比例小于第二预设比例。
具体地,通过采用第二预设比例,选择预设时间点之后的信用信息,可以仅选择部分,减少对于目标用户的近期数据的采集量,有助于提高运算效率。
更重要的的是,在本发明实施例中,通过采用第一预设比例,选择预设时间点之前的信用信息为第一信用信息;采用第二预设比例,选择预设时间点之后的信用信息为第二信用信息;其中,所述第一预设比例小于第二预设比例,通过减少数据量较大的早期数据的使用,增加采用近期数据,可以降低数据量较大的早期数据对用户信用的影响,提高对用户信用的确定效果。
在步骤s206中,根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型。
在步骤s207中,根据更新后的基础模型,确定所述目标用户的信用。
需要指出的是,在本发明实施例中,可以根据具体需要,对更新后的基础模型进行再次更新。
如图2中虚线箭头方向所示,在采用更新后的基础模型确定用户信用一段时间后,还可以对更新后的基础模型进行再次打分,以重新得到新的分数pt,进而采用ftrl算法,再次更新所述基础模型,以提高基础模型的时效性。
在本发明实施例中,在采集目标用户的信用信息之后,选择预设时间点之前的信用信息的至少一部分为第一信用信息,选择预设时间点之后的信用信息的至少一部分为第二信用信息,可以在采用ftrl算法更新模型时,有机会选择更适当的信用信息,从而有机会降低数据量较大的早期数据对用户信用的影响;进一步地,通过采用ftrl算法更新模型,可以有效利用ftrl算法计算速度快的优点,提高模型更新的效率,从而有机会更实时地对用户信用进行确定。
在具体实施中,有关步骤s201至步骤s207的更多详细内容请参照图1中的步骤s101和s102的描述进行执行,此处不再赘述。
参照图3,图3是本发明实施例中一种用户信用的确定装置的结构示意图。所述用户信用的确定装置可以包括:
采集模块31,适于采集目标用户的信用信息,其中,所述信用信息包括逾期状态yt,所述逾期状态yt用于指示是否逾期;
选择及构建模块32,适于选择预设时间点之前的信用信息的至少一部分为第一信用信息,并基于所述第一信用信息构建基础模型;
打分模块33,适于对所述基础模型进行打分,以得到分数pt;
选择模块34,适于选择预设时间点之后的信用信息的至少一部分为第二信用信息;
更新模块35,适于根据所述分数pt、逾期状态yt、第一信用信息以及第二信用信息,采用ftrl算法,更新所述基础模型;
信用确定模块36,适于根据更新后的基础模型,确定所述目标用户的信用。
进一步地,所述选择及构建模块32可以包括:第一选择子模块,适于采用第一预设比例,选择预设时间点之前的信用信息为第一信用信息;所述选择模块34可以包括:第二选择子模块,适于采用第二预设比例,选择预设时间点之后的信用信息为第二信用信息;其中,所述第一预设比例小于第二预设比例。
进一步地,每个信用信息可以为单维向量或者多维向量;其中,所述单维向量可以为所述逾期状态yt;所述多维向量的多个参数可以选自以下参数中的多项:收入信息、性别、交易流水以及逾期状态yt。
进一步地,所述更新模块35可以包括权重确定子模块,所述权重确定子模块采用下述公式,确定权重w:
gi=(pt-yt)xi;
zi←zi+gi-σiwt,i;
或者,
wt,i=0,其中,|zi|≤λ1;
其中,xi用于表示序号为i的单个信用信息,gi、ni、σi、zi、λ1以及λ2为所述ftrl算法的中间变量。
关于该用户信用的确定装置的原理、具体实现和有益效果请参照前文及图1至图2示出的关于用户信用的确定方法的相关描述,此处不再赘述。
本发明实施例还提供了一种存储介质,其上存储有计算机指令,所述计算机指令运行时执行上述图1至图2示出的关于用户信用的确定方法的步骤。所述存储介质可以是计算机可读存储介质,例如可以包括非挥发性存储器(non-volatile)或者非瞬态(non-transitory)存储器,还可以包括光盘、机械硬盘、固态硬盘等。
本发明实施例还提供了一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行上述图1至图2示出的关于用户信用的确定方法的步骤。所述终端包括但不限于手机、计算机、平板电脑等终端设备。
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!