基于融合词性和位置信息的汉-越卷积神经机器翻译方法与流程
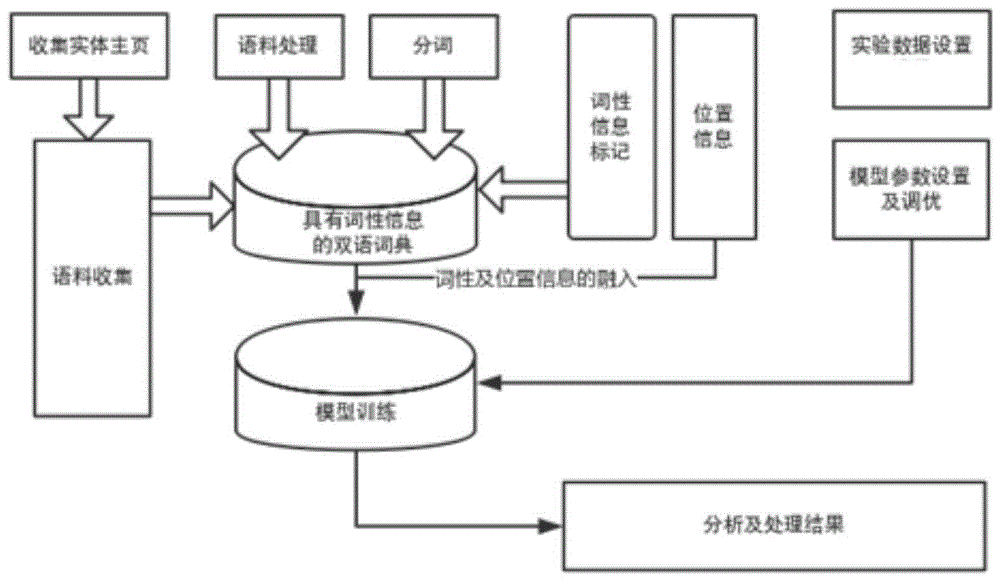
本发明涉及基于融合词性和位置信息的汉-越卷积神经机器翻译方法,属于自然语言处理
技术领域:
。
背景技术:
:机器翻译,又称为自动翻译,是利用计算机将一种自然语言转换为另一种自然语言的过程。随着机器翻译技术的迅速发展,机器翻译在大规模语料上取得了较好的效果,然而由于获取平行语料的成本较高,在资源稀缺型语言的机器翻译效果并不理想。为有效提升资源稀缺型语言的机器翻译性能,通常将词法知识、句法知识等外部知识融入到翻译模型中。因此,对资源稀缺的汉-越机器翻译,上述方法具有较高的科学与实用价值。目前,基于循环神经网络的汉-越机器翻译,是一种端到端的机器翻译方法,该方法生成的译文词序与越南语词序存在不一致问题(形容词、副词和动词等的修饰顺序不一致),例如“我是张老师的学生。”,通过该方法得到的译文为“(我)là(是)tru’o’ng(张)(老师)(的)trò(学生).”;该例句的正确译文为“(我)là(是)trò(学生)(的)(老师)tru’o’ng(张).”。其原因是汉语与越南语之间存在语言结构的差异,即汉语和越南语修饰语与被修饰语的语序不同。传统的处理方法是利用词性标注工具对双语语料进行词性标记,之后通过bpe工具进行分词,最后以模型嵌入或与词向量拼接的方式将词性信息融入模型翻译中。然而,通过bpe工具处理的语料会使词与词性信息无法形成一一对应的关系,从而破坏了词与相应词性之间的对应关系。针对这个问题,提出一种融合词性信息的汉-越卷积神经机器翻译方法。技术实现要素:本发明提供了基于融合词性和位置信息的汉-越卷积神经机器翻译方法,以用于有效地改善汉越译文语序不一致的问题。本发明的技术方案是:一种基于融合词性和位置信息的汉-越卷积神经机器翻译方法,首先在收集的汉越双语平行语料的基础上,利用汉越词性标记工具对汉语和越南语进行词性信息标注,并在标记词性信息的双语语料基础上生成具有词性信息的词表,利用带词性的词表对汉越双语语料进行词与词性的联合编码与解码,然后通过门控线性单元融入词性信息,并采取多层卷积神经网络及不同大小卷积核进行翻译模型的训练,生成较好性能的汉-越神经机器翻译模型再进行汉语越南语机器翻译。所述基于融合词性和位置信息的汉-越卷积神经机器翻译方法的具体步骤如下:step1、获取汉越双语平行语料;主要通过网络爬虫requests技术或xpath爬取方法从相应网站爬取后,经相应处理得到规范格式的汉越双语平行语料,从中随机抽取一定数量的训练集、开发集和测试集;step2、利用汉越词性标记工具对汉语和越南语进行词性信息标注;具体的,采用结巴分词工具和基于svmtool的越南语词性标注工具分别对汉语和越南语进行词性信息的标记;step3、在标记词性信息的双语语料基础上生成具有词性信息的词表;其中,在生成的词表中,包含不同词性信息的词,就会将词性信息作为词法关系特征融入到翻译模型中,以指导模型生成符合语言语法的目标语句;如“发明/v”与“发明/n”;在模型训练时,将“发明”的词性信息作为词法关系特征融入到翻译模型中,以指导模型生成符合语言语法的目标语句。step4、利用带词性信息的词表对汉越双语语料进行词与词性的联合编码与解码;其中,进一步地,编码器与解码器同样是共享块结构,并根据固定数量的输入元素来计算中间状态;在解码器中定义了第l块的输出表示为在编码器中也定义了第l块的输出表示为每一个块包含一个一维的卷积与一个非线性函数;融入词性信息的cnn,在卷积过程中能获取到语言间相关的词法知识,而词法知识获取的程度与卷积核的大小密切相关。因此,针对不同数量的越南语音节,采用不同大小的卷积核,以获取不同程度的、完整的汉语与越南语的词法知识;如公式所示,分别设置了大小为3、5、7的卷积核:为了防止网络退化,在每个卷积层中加入残差连接,其公式如下:其中,w为权重参数,b为偏置项参数,为j时刻的先前块的解码器状态;在编码器中,使用教导层来确保输入与输出的长度始终保持一致;在解码器中,从左侧开始进行m-1个全零元素的填充,之后在卷积的末尾移除m个元素;则第j+1个词的计算公式如下:其中,wo为权重,bo为偏置项参数,为第j时刻解码器最顶层的输出;在解码层中,沿用了多步注意力机制,即上层注意力为下层注意力提供信息;为了计算第l块上第j个解码器状态的总和将当前的解码器状态与先前目标元素yj的嵌入相融合,其公式如下:其中,为融入注意力后第l块的权重参数,为融入注意力后第l块的偏置项参数,为第j时刻的解码器状态;对于解码器第l层中的第l块上第i个编码器状态与第j个解码器状态总和的注意力其计算公式如下:其中,为第l块上第j个解码器状态总和,为第l块上第i个编码器状态;对于上下文向量其计算公式如下:step5、通过门控线性单元融入词性信息及位置信息,并采取多层卷积神经网络及不同大小卷积核进行翻译模型的训练,生成汉-越神经机器翻译模型进行汉语越南语机器翻译。所述步骤step5中,在融入词性信息时,以门控线性单元融入,在fairseq模型的基础上,利用以门控线性单元融入词性信息和位置信息;对于输入序列x=(x1,...,xm),利用门控线性单元glu将其嵌入到分布空间e中,得到的输入向量为e1,...,em,其中,ei∈rd是嵌入矩阵d∈rm×d的列,其计算如下:其中,w1,v1∈rk×m×n为权重,b1,c1∈rn为偏置项,m为输入序列长度,σ为sigmoid函数,是点乘;对于输入序列x=(x1,...,xm)对应的绝对位置序列p=(p1,...,pm)采用同样的方法嵌入到分布空间e中,其中pi∈rd,其维度大小始终与词向量维度大小相一致。模型根据词向量的信息查找相对应的位置向量信息,且该位置向量通过glu不断优化,其表示如下:其中,w2,v2∈rk×m×n为权重,b2,c2∈rn为偏置项,m为输入序列长度,σ为sigmoid函数,是点乘,得到的最终输入向量表示为:i=(e1+p1,...,em+pm)对于解码器得到的输出序列y=(y1,...,yn)也进行上述处理。本发明的有益效果是:1、本发明所述方法通过将词性和位置信息融入,有效的改善了汉越译文语序不一致的问题,通过对比实验分析,结果表明本发明的方法均优于其他模型;2、本发明的汉-越神经机器翻译模型不仅能学习到词语的位置信息还能学习到相关的词性信息,还能通过位置信息与词性信息的作用来约束译文的生成,汉-越译文语序不一致问题有较好的缓解作用,有效提升资源稀缺的汉-越神经机器翻译性能。附图说明图1为本发明中的流程图;图2为本发明提出方法的词性融入图。具体实施方式实施例1:如图1-2所示,基于融合词性和位置信息的汉-越卷积神经机器翻译方法,本方法采用单gpu进行进行实验,所述方法具体步骤如下:step1、获取汉越双语平行语料;主要通过网络爬虫requests技术或xpath爬取方法从相应网站爬取后,经相应处理得到规范格式的汉越双语平行语料,从中随机抽取一定数量的训练集、开发集和测试集;step2、利用汉越词性标记工具对汉语和越南语进行词性信息标注;具体的,采用结巴分词工具和基于svmtool的越南语词性标注工具分别对汉语和越南语进行词性信息的标记step3、在标记词性信息的双语语料基础上生成具有词性信息的词表;其中,在生成的词表中,包含不同词性信息的词,就会将词性信息作为词法关系特征融入到翻译模型中,以指导模型生成符合语言语法的目标语句;如“发明/v”与“发明/n”;在模型训练时,将“发明”的词性信息作为词法关系特征融入到翻译模型中,以指导模型生成符合语言语法的目标语句。step4、利用带词性信息的词表对汉越双语语料进行词与词性的联合编码与解码;其中,进一步地,编码器与解码器同样是共享块结构,并根据固定数量的输入元素来计算中间状态;在解码器中定义了第l块的输出表示为在编码器中也定义了第l块的输出表示为每一个块包含一个一维的卷积与一个非线性函数;融入词性信息的cnn,在卷积过程中能获取到语言间相关的词法知识,而词法知识获取的程度与卷积核的大小密切相关,因此,针对不同数量的越南语音节,采用不同大小的卷积核,以获取不同程度的、完整的汉语与越南语的词法知识;如公式所示,分别设置了大小为3、5、7的卷积核:为了防止网络退化,在每个卷积层中加入残差连接,其公式如下:其中,w为权重参数,b为偏置项参数,为j时刻的先前块的解码器状态;在编码器中,使用教导层来确保输入与输出的长度始终保持一致;在解码器中,从左侧开始进行m-1个全零元素的填充,之后在卷积的末尾移除m个元素;则第j+1个词的计算公式如下:其中,wo为权重,bo为偏置项参数,为第j时刻解码器最顶层的输出;在解码层中,沿用了多步注意力机制,即上层注意力为下层注意力提供信息;为了计算第l块上第j个解码器状态的总和将当前的解码器状态与先前目标元素yj的嵌入相融合,其公式如下:其中,为融入注意力后第l块的权重参数,为融入注意力后第l块的偏置项参数,为第j时刻的解码器状态;对于解码器第l层中的第l块上第i个编码器状态与第j个解码器状态总和的注意力其计算公式如下:其中,为第l块上第j个解码器状态总和,为第l块上第i个编码器状态;对于上下文向量其计算公式如下:step5、通过门控线性单元融入词性信息及位置信息,并采取多层卷积神经网络及不同大小卷积核进行翻译模型的训练,生成汉-越神经机器翻译模型进行汉语越南语机器翻译。所述步骤step5中,在融入词性信息时,以门控线性单元融入,在fairseq模型的基础上,利用以门控线性单元融入词性信息和位置信息;对于输入序列x=(x1,...,xm),利用门控线性单元glu将其嵌入到分布空间e中,得到的输入向量为e1,...,em,其中,ei∈rd是嵌入矩阵d∈rm×d的列,其计算如下:其中,w1,v1∈rk×m×n为权重,b1,c1∈rn为偏置项,m为输入序列长度,σ为sigmoid函数,是点乘;对于输入序列x=(x1,...,xm)对应的绝对位置序列p=(p1,...,pm)采用同样的方法嵌入到分布空间e中,其中pi∈rd,其维度大小始终与词向量维度大小相一致。模型根据词向量的信息查找相对应的位置向量信息,且该位置向量通过glu不断优化,其表示如下:其中,w2,v2∈rk×m×n为权重,b2,c2∈rn为偏置项,m为输入序列长度,σ为sigmoid函数,是点乘,得到的最终输入向量表示为:i=(e1+p1,...,em+pm)对于解码器得到的输出序列y=(y1,...,yn)也进行上述处理。为了验证本发明的有效性,在实验中将gnmt模型、不具有任何外部信息的cnn模型、融入位置信息的cnn模型(cnn+p)、具有词性信息的cnn模型(cnn+pos)以及本发明同时具有位置信息与词性信息的cnn模型(cnn+p+pos)进行对比。其中,在模型参数设置时,设置的参数如下所示:在gnmt实验模型中,词嵌入维度为512维,编码器与解码器网络的层数均为6层,其中每层的隐含单元数为256,dropout值为0.2,并用1.0初始化lstm的遗忘门偏置项。对于基于卷积神经网络实验的模型,每个模型需要3-4天的训练时间,编码器与解码器的嵌入维度均设置为768维。编码器设置为15层的卷积神经网络,解码器则采用lstm网络,其中编码器中前9层的隐含单元数为512,后4层的隐含单元数为1024,最后两层的隐含单元数为2048,批次大小为64以及dropout值为0.1,卷积核大小为k。在基准实验中卷积核大小k=3,在对比同卷积核大小是k的取值分别为k={3,5,7}。在探究影响机器翻译性能的因素方面,实验又对比了不同卷积核大小及不同深度的神经网络对实验结果的影响。每组模型实验重复进行三次,将每次实验最后保存的模型进行评测并取三次平均值作为最终实验结果的bleu值:表1为gnmt、cnn、cnn+p、cnn+pos和cnn+p+pos模型的实验结果gnmtcnncnn+pcnn+poscnn+p+pos汉-越13.618.8821.2222.5823.8越-汉20.5618.2321.1929.2929.36表2为cnn+p+pos模型的汉-越不同卷积核大小实验结果卷积核大小汉-越越-汉323.829.36519.5318.86720.1419.50表3为cnn+p+pos模型的汉-越不同网络层数实验结果从以上数据可以看出,基于卷积神经网络的机器翻译效果明显优于基于rnn的gnmt,且将词性信息融入到cnn模型中的bleu值优于其他模型。在基准实验模型cnn+p的基础上融入词性信息,模型不仅能学习到词语的位置信息还能学习到相关的词性信息,还能通过位置信息与词性信息的作用来约束译文的生成。因此,提出的方法对汉-越译文语序不一致问题有较好的缓解作用,有效提升资源稀缺的汉-越神经机器翻译性能。同时,在实验结果中得知,在模型的训练时,将编码器层数设为15,卷积核大小设为3时,得到的模型训练结果较优。上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1