一种基于信用评估的保险理赔方法和系统与流程
本公开涉及大数据处理和应用,尤其涉及基于信用评估的保险理赔方法和系统。
背景技术:
现有的保险理赔流程过于复杂。例如,根据现有的车险理赔流程,当车主发生事故时,车主通常会给保险公司打电话报案,由保险公司安排查勘人员到现场进行查勘定损,或由车主对损伤处进行拍照后将照片发给保险公司,在经过现场或远程查勘后,确定需要维修更换的项目,再由车主去维修厂进行修理,拿到发票或维修清单之后,将这些材料交给保险公司,保险公司对所有相关单据进行审核后,将维修费用赔付给车主。整个过程比较冗长,车主需要关注的事项较多,拿到赔付款的速度也很慢。
保险公司也想简化上述流程,但由于保险公司为了预防理赔欺诈,需要耗费大量人力物力用于现场查勘和证据采集。虽然保险公司当前可以根据自己掌握的理赔历史数据来做到提前赔付,即在审核相关单据之前赔付用户,但这些理赔历史数据通常仅仅基于客户上一年度的出险次数、区域、车型、车价、使用性质等因素,可见这些因素都属于车因素,缺少“与人相关的”数据维度,从而使得这些数据在很大程度上无法体现车主或报案人的信用水平。因此,保险公司无法基于这些理赔历史数据来进一步简化理赔流程。
当前,金融科技(英语:financialtechnology,也称为fintech)的快速发展使得解决保险(例如,车险)行业的高查勘成本、低效赔付流程和理赔欺诈问题成为可能。保险公司或相关企业通过运用科技手段(尤其是ai技术和相关算法)来使得理赔流程变得更有效率并且降低查勘成本和不合理赔付率是合乎需要的。
技术实现要素:
提供本公开内容来以简化形式介绍将在以下具体实施方式部分中进一步描述的一些概念。本公开内容并不旨在标识出所要求保护的主题的关键特征或必要特征,也不旨在用于帮助确定所要求保护的主题的范围。
为了使用户信用更加精准可信并由此简化理赔流程以改善用户体验,必须对当前的车主信用体系进行改进以便基于高度可信的用户信用来为用户提供差异化理赔服务,本公开正是出于此目的而做出的。
具体地,本公开将与车主或报案人本身有关的属性,即与人相关的属性,与保险公司通常具备的与车有关的属性相结合以用于信用评估,从而能够更加准确且全面地确定车主或报案人的信用水平。随后,能够基于所生成的更加可信的信用评估结果来为用户提供差异化服务以改善用户体验,诸如为高信用用户提供极简的理赔流程和服务等等。
在本公开的一个实施例中,提供了一种基于信用评估的保险理赔方法,包括:
获取用户的用户数据;
使用无监督聚类来对所述用户数据进行预处理以生成带标签数据;
通过gbdt对所述带标签数据进行特征变换;
基于经变换特征通过逻辑回归模型来确定所述用户的信用等级;以及
向保险服务提供者提供所述信用等级以供其基于所述信用等级来为所述用户提供差异化理赔服务。
在本公开的一个实施例中,提供了一种基于信用评估的保险理赔系统,该系统包括:
用于获取用户的用户数据的装置;
用于使用无监督聚类来对所述用户数据进行预处理以生成带标签数据的装置;
用于通过gbdt对所述带标签数据进行特征变换的装置;
用于基于经变换特征通过逻辑回归模型来确定所述用户的信用等级的装置;以及
用于向保险服务提供者提供所述信用等级以供其基于所述信用等级来为所述用户提供差异化理赔服务的装置。
在本公开的另一实施例中,提供了一种存储用于基于信用评估的保险理赔的指令的计算机可读存储介质,所述指令包括:
用于获取用户的用户数据的指令;
用于使用无监督聚类来对所述用户数据进行预处理以生成带标签数据的指令;
用于通过gbdt对所述带标签数据进行特征变换的指令;
用于基于经变换特征通过逻辑回归模型来确定所述用户的信用等级的指令;以及
用于向保险服务提供者提供所述信用等级以供其基于所述信用等级来为所述用户提供差异化理赔服务的指令。
本公开的各方面一般包括如基本上在本文参照附图所描述并且通过附图所阐示的方法、装置、系统。
在结合附图研读了下文对本公开的具体示例性实施例的描述之后,本公开的其他方面、特征和实施例对于本领域普通技术人员将是明显的。尽管本公开的特征在以下可能是针对某些实施例和附图来讨论的,但本公开的全部实施例可包括本文所讨论的有利特征中的一个或多个。换言之,尽管可能讨论了一个或多个实施例具有某些有利特征,但也可以根据本文讨论的本公开的各种实施例使用此类特征中的一个或多个特征。以类似方式,尽管示例性实施例在下文可能是作为设备、系统或方法实施例进行讨论的,但是应当领会,此类示例性实施例可以在各种设备、系统、和方法中实现。
附图说明
为了能详细理解本公开的以上陈述的特征所用的方式,可参照各方面来对以上简要概述的内容进行更具体的描述,其中一些方面在附图中阐示。然而应该注意,附图仅阐示了本公开的某些典型方面,故不应被认为限定其范围,因为本描述可允许有其他等同有效的方面。
图1、2a、2b和3示出了其中可实施本公开的各实施例的各种操作环境。
图4示出了根据本公开的一个实施例的信用评估模块的框图。
图5示出了根据本公开的一个实施例的混合模型结构。
图6示出了根据本公开的一个实施例的理赔模块的框图。
图7示出了根据本公开的一个实施例的基于信用评估的保险理赔方法的流程图。
图8示出了根据本公开的一个实施例的用于信用评估的方法的流程图。
图9示出了根据本公开的一个实施例的用于提供差异化理赔服务的方法的流程图。
具体实施方式
以下将参考形成本公开一部分并示出各具体示例性实施例的附图更详尽地描述各个实施例。然而,各实施例可以以许多不同的形式来实现,并且不应将其解释为限制此处所阐述的各实施例;相反地,提供这些实施例以使得本公开变得透彻和完整,并且将这些实施例的范围完全传达给本领域普通技术人员。各实施例可按照方法、系统或设备来实施。因此,这些实施例可采用硬件实现形式、全软件实现形式或者结合软件和硬件方面的实现形式。因此,以下具体实施方式并非是局限性的。
图1、2a、2b、3及相关联的描述提供了本文描述的信用评估模块可在其中实现的各种操作环境的讨论。然而,关于图1-3所示出和讨论的设备和系统是用于示例和说明的目的,而非对可被用于实施本文所述的本公开的各实施例的大量计算设备配置的限制。
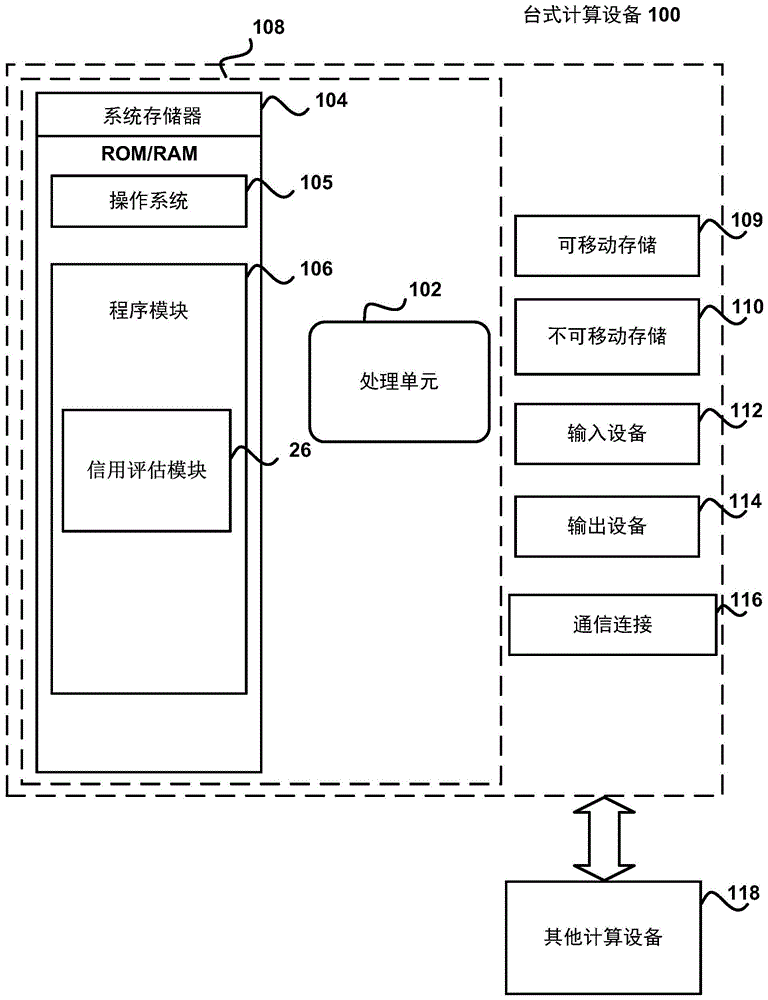
图1是示出可用来实施本公开的各实施例的台式计算设备100的示例物理组件的框图。以下描述的计算设备组件可适用于上述计算设备。在一基本配置中,台式计算设备100可以包括至少一个处理单元102和系统存储器104。取决于计算设备的配置和类型,系统存储器104可以包括,但不限于,易失性存储器(例如,随机存取存储器(ram))、非易失性存储器(例如,只读存储器(rom))、闪存或任何组合。系统存储器104可以包括操作系统105、一个或多个编程模块106,且可以包括web浏览器应用120。例如,操作系统105可适用于控制台式计算设备100的操作。在一个实施例中,编程模块106可包括安装在台式计算设备100上的信用评估模块26。此外,本公开的各实施方式可以结合图形库、其他操作系统、或任何其他应用程序来实践,且不限于任何特定应用程序或系统。该基本配置在图1中由虚线108内的那些组件示出。
台式计算设备100可具有附加特征或功能。例如,台式计算设备100还可包括附加数据存储设备(可移动和/或不可移动),诸如例如,磁盘、光盘、或磁带。这些附加存储由可移动存储109和不可移动存储110示出。
如上所述,可以在系统存储器104中存储包括操作系统105在内的多个程序模块和数据文件。当在处理单元102上执行时,程序模块106可执行各个过程,包括与如下所述的方法有关的操作。下述过程是示例,且处理单元102可执行其他过程。根据本公开的各实施方式可以使用的其他程序模块可以包括电子邮件和联系人应用、字处理应用、电子数据表应用、数据库应用、幻灯片演示应用、绘图或计算机辅助应用程序等。
一般而言,根据本公开的各实施方式,程序模块可以包括可以执行特定任务或可以实现特定抽象数据类型的例程、程序、组件、数据结构和其他类型的结构。此外,本公开的各实施方式可用其他计算机系统配置来实践,包括手持式设备、多处理器系统、基于微处理器的系统或可编程消费电子产品、小型机、大型计算机等。本公开的各实施方式也可以在其中任务由通过通信网络链接的远程处理设备执行的分布式计算环境中实现。在分布式计算环境中,程序模块可位于本地和远程存储器存储设备两者中。
此外,本公开的各实施方式可在包括分立电子元件的电路、包含逻辑门的封装或集成电子芯片、利用微处理器的电路、或在包含电子元件或微处理器的单个芯片上实现。例如,可以通过片上系统(soc)来实施本公开的各实施例,其中,可以将图1中示出的每个或许多组件集成到单个集成电路上。这样的soc设备可包括一个或多个处理单元、图形单元、通信单元、系统虚拟化单元以及各种应用功能,所有这些都被集成到(或“烧录到”)芯片基板上作为单个集成电路。当通过soc操作时,在此所述的关于管理器26的功能可以通过与计算设备/系统100的其他组件一起集成在单个集成电路(芯片)上的应用专用逻辑来操作。本公开的各实施方式还可以使用能够执行诸如,例如,and(与)、or(或)和not(非)等逻辑运算的其他技术来实践,包括但不限于,机械、光学、流体和量子技术。另外,本公开的各实施方式可以在通用计算机或任何其他电路或系统中实现。
例如,本公开的各实施方式可被实现为计算机进程(方法)、计算系统或诸如计算机程序产品或计算机可读介质等制品。计算机程序产品可以是计算机系统可读并编码了用于执行计算机进程的指令的计算机程序的计算机存储介质。
如这里所使用的术语计算机可读介质可以包括计算机存储介质。计算机存储介质可包括以用于存储诸如计算机可读指令、数据结构、程序模块、或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。系统存储器104、可移动存储109和不可移动存储110都是计算机存储介质(即,存储器存储)的示例。计算机存储介质可以包括,但不限于,ram、rom、电可擦除只读存储器(eeprom)、闪存或其他存储器技术、cd-rom、数字多功能盘(dvd)或其他光存储、磁带盒、磁带、磁盘存储或其他磁性存储设备、或可用于存储信息且可以由台式计算设备100访问的任何其他介质。任何这样的计算机存储介质都可以是设备100的一部分。台式计算设备100还可以具有输入设备112,如键盘、鼠标、笔、声音输入设备、触摸输入设备等。还可包括诸如显示器、扬声器、打印机等输出设备114。上述设备是示例且可以使用其他设备。
相机和/或某种其他传感设备可操作来记录一个或多个用户以及捕捉计算设备的用户作出的运动和/或姿势。传感设备还可操作来捕捉诸如通过话筒口述的单词和/或捕捉来自用户的诸如通过键盘和/或鼠标(未描绘)的其他输入。传感设备可包括能够检测用户的移动的任何运动检测设备。
如这里所使用的术语计算机可读介质还包括通信介质。通信介质由诸如载波或其他传输机制等已调制数据信号中的计算机可读指令、数据结构、程序模块或其他数据来体现,并包括任何信息传递介质。术语“已调制数据信号”可以描述以对该信号中的信息进行编码的方式设定或者改变其一个或多个特征的信号。作为示例而非限制,通信介质包括诸如有线网络或直接线连接等有线介质,以及诸如声学、射频(rf)、红外线和其他无线介质等无线介质。
图2a和2b示出可用来实施本公开的各实施例的合适的移动计算环境,例如移动电话、智能电话、输入板个人计算机、膝上型计算机等。参考图2a,示出了用于实现各实施例的示例移动计算设备200。在一基本配置中,移动计算设备200是具有输入元件和输出元件两者的手持式计算机。输入元件可包括允许用户将信息输入到移动计算设备200中的触摸屏显示器205和输入按钮210。移动计算设备200还可结合允许进一步的用户输入的可选的侧面输入元件215。可选的侧面输入元件215可以是旋转开关、按钮、或任何其他类型的手动输入元件。在替代实施例中,移动计算设备200可结合更多或更少的输入元件。例如,在某些实施例中,显示器205可以不是触摸屏。在又一替代实施例中,移动计算设备是便携式电话系统,如具有显示器205和输入按钮210的蜂窝电话。移动计算设备200还可包括可选的小键盘235。可选的小键盘235可以是物理小键盘或者在触摸屏显示器上生成的“软”小键盘。
移动计算设备200结合输出元件,如可显示图形用户界面(gui)的显示器205。其他输出元件包括扬声器225和led220。另外,移动计算设备200可包含振动模块(未示出),该振动模块使得移动计算设备200振动以将事件通知给用户。在又一实施例中,移动计算设备200可结合耳机插孔(未示出),用于提供另一手段来提供输出信号。
尽管此处组合移动计算设备200来描述,但在替代实施例中,本公开还可组合任何数量的计算机系统来被使用,如在台式环境中、膝上型或笔记本计算机系统、多处理器系统、基于微处理器或可编程消费电子产品、网络pc、小型计算机、大型计算机等。本公开的实施例也可在分布式计算环境中实践,其中任务由分布式计算环境中通过通信网络链接的远程处理设备来执行;程序可位于本机和远程存储器存储设备中。总而言之,具有多个环境传感器、向用户提供通知的多个输出元件和多个通知事件类型的任何计算机系统可结合本公开的实施例。
图2b是示出在一个实施例中使用的诸如图2a中所示的计算设备之类的移动计算设备的组件的框图。即,移动计算设备200可结合系统202以实现某些实施例。例如,系统202可被用于实现可运行与台式或笔记本计算机的应用类似的一个或多个应用的“智能电话”,这些应用例如演示文稿应用、浏览器、电子邮件、日程安排、即时消息收发、以及媒体播放器应用。在某些实施例中,系统202被集成为计算设备,诸如集成的个人数字助理(pda)和无线电话。
一个或多个应用266可被加载到存储器262中并在操作系统264上或与操作系统264相关联地运行。应用程序的示例包括电话拨号程序、电子邮件程序、pim(个人信息管理)程序、文字处理程序、电子表格程序、因特网浏览器程序、消息通信程序等等。系统202还包括存储器268内的非易失性存储262。非易失性存储268可被用于存储在系统202断电时不会丢失的持久信息。应用266可使用信息并将信息存储在非易失性存储268中,如电子邮件应用使用的电子邮件或其他消息等。同步应用(未示出)也可驻留在系统202上并被编程为与驻留在主机计算机上的对应同步应用进行交互,以保持存储在非易失性存储268中的信息与存储在主机计算机上的对应信息相同步。如应被理解的,其他应用可被加载到存储器262中且在设备200上运行,包括信用评估模块26。
系统202具有可被实现为一个或多个电池的电源270。电源270还可包括外部功率源,如补充电池或对电池重新充电的ac适配器或加电对接托架。
系统202还可包括执行发射和接收无线电频率通信的功能的无线电272。无线电272通过通信运营商或服务供应商方便了系统202与“外部世界”之间的无线连接。来往无线电272的传输是在操作系统264的控制下进行的。换言之,无线电272接收的通信可通过操作系统264传播到应用266,反之亦然。
无线电272允许系统202例如通过网络与其他计算设备通信。无线电272是通信介质的一个示例。通信介质由诸如载波或其他传输机制等已调制数据信号中的计算机可读指令、数据结构、程序模块或其他数据来体现,并包括任何信息传递介质。术语“已调制数据信号”是指使得以在信号中编码信息的方式来设置或改变其一个或多个特性的信号。作为示例而非限制,通信介质包括诸如有线网络或直接线连接之类的有线介质,以及诸如声学、rf、红外及其他无线介质之类的无线介质。如此处所使用的术语计算机可读介质包括存储介质和通信介质两者。
系统202的该实施例是以两种类型的通知输出设备来示出的:可被用于提供视觉通知的led220,以及可被用于扬声器225提供音频通知的音频接口274。这些设备可直接耦合到电源270,使得当被激活时,即使为了节省电池功率而可能关闭处理器260和其他组件,它们也在一段由通知机制指示的持续时间保持通电。led220可被编程为无限地保持通电,直到用户采取行动指示该设备的通电状态。音频接口274用于向用户提供听觉信号并从用户接收听觉信号。例如,除被耦合到扬声器225以外,音频接口274还可被耦合到话筒以接收听觉输入,诸如便于电话对话。根据各本公开的各实施例,话筒也可充当音频传感器来便于对通知的控制,如下文将描述的。系统202可进一步包括允许板载相机230的操作来记录静止图像、视频流等的视频接口276。
移动计算设备实现系统202可具有附加特征或功能。例如,该设备还可包括附加数据存储设备(可移动的/或不可移动的),诸如磁盘、光盘或磁带。此类附加存储在图2b中由存储268示出。计算机存储介质可包括以用于存储诸如计算机可读指令、数据结构、程序模块、或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。
设备200生成或捕捉的且经系统202存储的数据/信息可如上所述本地存储在设备200上,或数据可被存储在可由设备通过无线电272或通过设备200和与设备200相关联的分开的计算设备之间的有线连接访问的任何数量的存储介质上,该分开的计算设备如例如因特网之类的分布式计算网络中的服务器计算机。如应理解的,此类数据/信息可经设备200、经无线电272或经分布式计算网络来被访问。类似地,这些数据/信息可根据已知的数据/信息传送和存储手段来容易地在计算设备之间传送以存储和使用,这些手段包括电子邮件和协作数据/信息共享系统。
图3示出了其中可实现本公开的各实施例的联网环境。保险服务提供者302指的是提供包括车险在内的各种保险服务的保险公司,这些保险公司将自己的理赔和用户注册信息存储在数据存储304中,并且基于从信用评估模块306接收到的用户信用信息,通过理赔模块306来为用户提供差异化理赔服务。
信用评估模块308从保险服务提供者,具体而言从保险服务提供者的数据存储304接收各项理赔数据并结合从第三方数据提供者310接收到的用户的各项数据来确定用户的信用水平,并对保险服务提供者开放查询结构以供其查询所确定的用户信用水平。
第三方数据提供者310包括各种不同类型的互联网公司,这些公司提供各种各样的互联网服务,包括财务服务(诸如信用卡还款、理财产品购买等)、地图服务(诸如兴趣点搜索、路线导航等)、消费服务(诸如在线购买商品、线下信用卡消费等)、即时消息收发服务(诸如提供消息通知、用户交流等)、社交网络服务(诸如提供朋友动态、碎片消息发布等)。第三方数据提供者将其数据存储在数据存储312中以便在信用查询模块请求时提供给它。
图4示出了根据本公开的一个实施例的信用评估模块402的框图。在该实施例中,信用评估模块402包括数据获取组件404、聚类组件406、特征变换组件408、以及线性分类组件410。下文将针对每个组件进行详细描述。
数据获取组件404用于获取关于用户的来自保险服务提供者的保险数据以及来自第三方服务提供者的用户互联网数据。具体而言,保险数据包括但不限于该用户在该保险公司的询价、投保、理赔以及日常咨询和回放记录,诸如用户在保险公司a的投保记录、投保金额、理赔记录、理赔金额、日常咨询内容等等。用户互联网数据包括但不限于该用户的关系网络、1度和2度关系黑名单关联度、消费记录、财富水平、lbs(基于位置的服务)信息、职业稳定度,等等。
本文描述的用户关系网络以及1度和2度关系黑名单关联度被用来基于具备与高风险人员的共性特征或者处于与高风险人员的某一维度的网络关系来确定低信用水平。在现实生活中,骗保人群通常需要多人配合才能提高骗保的伪装性。而骗保人员的聚集在很多情况下也会基于熟人关系或具有较为明显的共性特征或某一维度的网络关系特征数据。例如以亲戚之间合伙的骗保行为,传销性质的具有明显阶层划分的骗保团体、有经验的历史骗保人员为头目拉拢的社会群体或学生群体等。在本公开的各个实施例中,从包含投保人员和申请理赔人员的目标人群的多种关系关联数据出发,进行一度或多度关系网络的构图(关系网络图的数据可以称为多度关系图数据),以便深入挖掘目标人群之间的关系网络,从而解决现有技术中仅对历史骗保人员和与历史骗保人员有直接关系(即一度关系)的人员进行识别的覆盖率低和识别率低的问题。
例如,a与b是老板关系、a与c是家人关系等。单独的两个人员之间的关系可以称为一度关系,本实施例中所述的多度关系网络图数据中的“多度”可以包括基于所述一度关系建立的新的人员之间的关联数据,如基于第一人员与第二人员的一度关系和第二人员与第三人员的一度关系建立的所述第一人员与第三人员的二度关系,甚至进一步可以基于其他一度关系建立第一人员与第四人员的三度关系等等。如一个示例中,a是单个人员,b是a的姐夫,则a与b是一度的社会关系,a与其姐夫b的公司老板c之前不存在社会关系,但在本说明书实施例中,由于存在b既是a的姐夫又是公司老板c的下属,因此a与公司老板c之间建立的二度关系。
消费记录可以包括用户的线上和线下消费记录,包括消费金额、消费频率、消费地点,等等。消费记录还可包括用户的信用卡消费账单信息、信用卡额度、透支记录、提现记录,还款记录等等。上述消费记录信息可用于帮助确定用户的信用水平,比如信用卡额度越高代表信用越好,信用卡消费金额高且还款及时代表用户的信用水平高,消费地点也可暗示用户的信用水平(例如,经常在五星级酒店消费代表用户有一定的社会地位,并由此暗示用户的信用水平很有可能是很高的)。反之,如果有多次信用卡还款逾期、信用卡额度过低、频繁信用卡提现或透支,则代表用户的信用水平很低。
财富水平指可以指用户的资产水平,诸如房产价值、车辆价值、有价证券价值,等等。
lbs(基于位置的服务)信息是通过地图服务提供的定位信息以及位置周边的兴趣点信息。lbs被用来进行o2o匹配以便为用户提供基于位置的各种o2o服务。
职业稳定度信息可以通过社交网络服务来提供,诸如基于社交网络中的自我介绍中的职业信息的变动。或者可通过和社保机构合作,从社保机构获取非敏感信息来判断用户的就业信息。
上述这些互联网用户数据可以对传统的保险企业自己的数据做出有益的补充,从而能够有助于更全面且更准确地反映用户的信用水平。
在传统技术中,在搜集到足够的样本数据之后,直接根据样本数据以及样本数据的样本标签来训练神经网络模型。神经网络(neuralnetwork,即nn),从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activationfunction)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达
神经网络的学习方式可分为监督学习和非监督学习。在监督学习中,将训练样本的数据加到网络输入端,同时将相应的期望输出与网络输出相比较,得到误差信号,以此控制权值连接强度的调整,经多次训练后收敛到一个确定的权值。当样本情况发生变化时,经学习可以修改权值以适应新的环境。然而,上述搜集的样本数据通常会包括多个维度的信息,这会导致神经网络模型训练的效率比较低且给样本数据加标签的工作量极大。
无监督检测算法可以事先不给定标准样本,直接将网络置于环境之中,学习阶段与工作阶段成为一体。此时,学习规律的变化服从连接权值的演变方程。非监督学习最简单的例子是hebb学习规则。竞争学习规则是一个更复杂的非监督学习的例子,它是根据已建立的聚类进行权值调整,因此无监督检测算法无需依赖于任何标签数据来训练模型。这种检测机制算法的核心内容是无监督异常样本检测,通过利用关联分析和相似性分析,发现目标用户行为间的联系,创建群组。然而,该方法受限于识别率偏低。
针对识别率偏低的问题,还可以结合专家经验来提升识别率。通过对领域专家的访谈和对这些专家对历史数据的分析,可以得到一些非常可靠的评判标准。以保险行业为例,如果一个人刚买短期保险没两天就意外身亡,这存在欺诈的风险就很高。这样的标准或许从机器学习中可以学到,或许学不到,但专家经验显然是更直接的方法,需要和领域专家一起协作才能有最好的结果。但这种方法收到人力和成本的制约,无法对大规模用户数据使用,只能作为有益的补充,例如在特征生成阶段纳入专家经验。
另一种预估用户信用等级的方法是逻辑回归(lr),lr是广义线性模型,与传统线性模型相比,lr使用了logit变换将函数值映射到0~1区间,映射后的函数值就是用户信用等级预估值。lr这种线性模型很容易并行化,处理上亿条训练样本不是问题,但线性模型学习能力有限,需要大量特征工程预先分析出有效的特征、特征组合,从而去间接增强lr的非线性学习能力。因此,lr模型中的特征组合很关键,但又无法直接通过特征笛卡尔积解决,只能依靠人工经验,耗时耗力同时并不一定会带来效果提升。因此,如何自动发现有效的特征、特征组合,弥补人工经验不足,缩短lr特征实验周期,是本公开中的信用评估的关键所在。
上述各种方法虽然都有缺陷,但也有其相应的优点。它们的优点使得将这些方法中的某一些进行组合使用以产生意想不到的良好效果成为可能。
除了上述方法或策略之外,在本公开的一个实施例中,还结合了gbdt(gradientboostdecisiontree,梯度提升决策树)。gbdt是一种常用的非线性模型,它基于集成学习中的boosting思想,即每一次建立模型是在之前建立模型损失函数的梯度下降方向。损失函数是评价模型性能(一般为拟合程度+正则项),认为损失函数越小,性能越好。而让损失函数持续下降,就能使得模型不断改性提升性能,其最好的方法就是使损失函数沿着梯度方向下降(讲道理梯度方向上下降最快)。每一次建立树模型是在之前建立模型损失函数的梯度下降方向。即利用了损失函数的负梯度在当前模型的值作为回归问题提升树算法的残差近似值,去拟合一个回归树。每次迭代都在减少残差的梯度方向新建立一颗决策树,迭代多少次就会生成多少颗决策树。gbdt的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合,特征决定模型性能上限,例如深度学习方法也是将数据如何更好的表达为特征。如果能够将数据表达成为线性可分的数据,那么使用简单的线性模型就可以取得很好的效果。gbdt构建新的特征使特征更好地表达数据。
用已有特征训练gbdt模型,然后利用gbdt模型学习到的树来构造新特征,构造的新特征向量可通过one-hot编码取值0/1,向量的每个元素对应于gbdt模型中树的叶子结点。当一个样本点通过某棵树最终落在这棵树的一个叶子结点上,那么在新特征向量中这个叶子结点对应的元素值为1,而这棵树的其他叶子结点对应的元素值为0。新特征向量的长度等于gbdt模型里所有树包含的叶子结点数之和。
决策树的结果或路径可以直接作为lr输入特征使用,省去了人工寻找特征、特征组合的步骤。这种通过gbdt生成lr输入特征的方式(gbdt+lr)在图5中示出。
图5示出了根据本公开的一个实施例的混合模型结构500。该混合模型结构500示出了gbdt与lr的融合方式。常规上是直接将原始样本数据作为gbdt的输入数据,但在本公开的一个实施例中,在gbdt模型之前还融合了原始样本数据的无监督聚类。传统上,无监督聚类被用来根据原始样本数据中的一个或多个特征维度的相似性来寻找原始样本数据中的异常样本,但在本公开的该实施例中无监督聚类由于其能够基于某些特征维度来聚合样本数据集的天然属性而被用来对原始输入数据进行预处理,该预处理由图4所示的信用评估模块402中的聚类组件404来执行。在将原始样本数据输入到gbdt模型中之前对其进行无监督聚类能够使得通过gbdt模型得到的变换特征组合的区分性更强,从而能够提升最终的lr模型得出的信用评估的准确度。
具体而言,聚类组件406从数据获取组件404获取的保险数据和用户数据的样本数据组合中选择n个初始变量,随机抽取其中m(m<n)个变量作为变量子集,变量子集的抽取办法有
对于每个变量子集,聚类组件406使用聚类方法将所有样本数据组合分成l个组并为每组数据新增标签,标签值分别为g1、g2……gl,该标签值即每个样本数据的特征向量中的新增特征维度。因为数据获取组件获取的各种各样数据中的变量维度很多以使得使用全部变量来聚类的计算成本会特别高,所以需要进行变量抽取以形成变量子集,并且针对每个变量子集的每一次聚类都会生成新的标签。
如本领域技术人员可以理解的,上述初始变量数n、抽取变量数m、聚类分组数l都并非是限制性的,而是可由信用评估者根据自身需求进行相应设定以达到最好的聚类效果,并且由于详细的聚类细节是本领域内公知的,因此在此不再赘述。
参考图5,将经聚类的带标签样本数据输入到gbdt,即图4所示的聚类组件406将经聚类的带标签样本数据传递至特征变换组件408。作为示例而非限制,图5中的树1和树2是通过gbdt模型训练和学习得到的两颗树,x为经聚类的带标签样本数据。在特征变换组件408中,对带标签样本数据进行特征变换。在本公开的另一实施例中,经变换特征的生成还可以通过专家经验来进行补充以获得更多的强区分性特征组合。
具体而言,带标签样本数据x遍历两棵树后,带标签样本数据x分别落到两颗树的叶子节点上,每个单独树的输出被视为线性分类器(即,lr)的分类输入特征,每个叶子节点对应lr一维特征,那么通过遍历树,就得到了该样本对应的所有lr输入特征。
具体而言,作为示例而非限制,左树有三个叶子节点,右树有两个叶子节点,对于输入x,假设x落在左树第一个节点,编码[1,0,0],落在右树第二个节点则编码[0,1],所以整体的编码为[1,0,0,0,1],最终的特征即为五维的特征向量。
随后特征变换组件408将经变换的特征向量传递至线性分类组件410,即将经变换的特征向量输入到线性分类模型(lr)中进行分类和收敛。由于树的每条路径,是通过最小化均方差等方法最终分割出来的有区分性路径,根据该路径得到的特征、特征组合都相对更有区分性,效果理论上不会亚于人工经验的处理方式,甚至具备人类未必能感知到的区分特征组合。
如本领域技术人员可以理解的,上述gbdt中的树、节点和路径分叉的各种设定并非是限制性的,而是可由信用评估者根据自身需求来设定以得到区分性更佳且可解释性更强的特征向量,并且gbdt的实现细节和相关算法在本领域内是公知的,因此在此不再赘述。
随后,特征变换组件408将变换的特征组合传递至线性分类组件410,即在图5中将变换特征作为线性分类器(lr)的输入以预测最终信用水平。特征具有相应的权重(w),这取决于该特征对于最终信用水平的重要性。如本领域技术人员可以理解的,上述权重可由信用评估者基于自身的需求或者对信用水平的定义来自行设定。
在本公开的一个实施例中,线性分类组件410使用所述逻辑回归算法可以学习出每个gbdt算法得出的结果值,当代入逻辑回归公式后,可以预测用户欺诈概率,其范围在(0,1)之间。
逻辑回归算法对应的公式如下:
在上式中,fi指的是每一个gbdt算法模型的结果值,
最后按照该欺诈概率1-10档次划分用户信用等级。作为示例而非限制,当用户欺诈概率在(0,0.1]之间时,用户信用等级为10;当用户欺诈概率在(0.1,0.2]之间时,用户信用等级为9;当用户欺诈概率在(0.2,0.3]之间时,用户信用等级为8;当用户欺诈概率在(0.3,0.4]之间时,用户信用等级为7;当用户欺诈概率在(0.4,0.5]之间时,用户信用等级为6;当用户欺诈概率在(0.5,0.6]之间时,用户信用等级为5;当用户欺诈概率在(0.6,0.7]之间时,用户信用等级为4;当用户欺诈概率在(0.7,0.8]之间时,用户信用等级为3;当用户欺诈概率在(0.8,0.9]之间时,用户信用等级为2;当用户欺诈概率在(0.9,1.0]之间时,用户信用等级为1。
在本公开的另一实施例中,在最后确定用户信用等级时可参照专家经验来使得预测结果更加准确(作为补充)。
在本公开的另一实施例中,可以为原始样本数据指定多个(至少两个)特征维度。在该实施例中,所指定的特征维度可以为用于评价用户信用的预定指标。通过对至少两个特征维度的综合处理,可以借助无监督聚类、gbdt树和lr模型来对用户的信用值作出可信的综合预测或评估。作为示例而非限制,特征维度可以包括:保险记录、社会关系网络(黑名单关联度)、消费记录、财富水平、lbs信息、职业稳定度等维度。即可以从保险、社会关系(黑名单关联度)、消费、财富、lbs、职业等维度对用户的信用值分别进行评价,再将上述各个特征维度的评价综合后,得到一个最终的用户信用值。
具体而言,对于保险记录维度,其用于评价用户在保险方面信用值的高低。该保险维度可以包括有一个或者多个预定特征(即,变量)。与保险维度对应的预定特征的特征数据可以从用户投保的各个保险公司的历史数据中获取。例如,该保险维度的预定特征可以包括投保记录、投保金额、理赔记录、理赔金额、日常咨询内容,等等。
对于社会关系维度,其用于评价用户在社会关系方面信用值的高低。社会关系维度可以包括有一个或者多个预定特征。社会关系维度对应的预定特征的特征数据可以从例如公安系统、用户的社交应用中获取。例如,社会关系维度的预定特征可以包括黑名单关联度。
对于消费记录维度,其用于评价用户在消费方面信用值的高低。消费维度可以包括有一个或者多个预定特征。消费维度对应的预定特征的特征数据可以从例如用户的支付应用、银行获取。例如,消费维度的预定特征可以包括消费金额、消费频率、消费地点。
对于财富维度,其用于评价用户财富水平。财富水平越高,信用很有可能也越高。财富维度可以包括有一个或者多个预定特征。财富维度对应的预定特征的特征数据可以从例如银行、房产中介、证券公司等获取。例如,消费维度的预定特征可以包括房产价值、车辆价值、有价证券价值。
对于lbs维度,其用于评价商户在提供o2o服务时用户的履约情况。lbs维度可以包括有一个或者多个预定特征。lbs维度对应的预定特征的特征数据可以从例如商家、o2o相关应用等获取。例如,lbs维度的预定特征可以包括用户的履约率、商家对用户的评价,等等。
对于职业维度,其用于评价用户的职业状况,不同的职业可以在相当程度上反映用户的信用水平。例如,各种兼职表示信用水平不高、公务员、教师和医生等稳定的职业可表示较高的信用水平,等等。职业维度可以包括有一个或者多个预定特征。职业维度对应的预定特征的特征数据可以从例如社保机构、社交软件等获取。例如,职业维度的预定特征可以包括用户的社保交费,跳槽频率,等等。
当然,上述特征维度及其对应的预定特征不限于上述描述。所属领域技术人员在本公开的技术精髓启示下,还可能做出其他的变更,但只要其实现的功能和效果与本公开相同或相似,均应涵盖于本公开的保护范围内。
随后,被分成不同特征维度的样本数据及其对应的预定特征信息由聚类组件进行无监督聚类,从而获得更好的聚类效果和性能。
然后,针对这些经聚类的样本建立多棵决策树组合模型。所有的决策树的结论累加起来获得最终结果。每棵所述决策树可以是回归树。即,每一棵树学的是之前所有树结论和的残差。所述残差是一个加预测值后能得到真实值的累加量,即:a的预测值+a的残差=a的实际值。具体的,预先建立的模型可以采用gbdt算法,即每个所述决策树可以采用gbdt算法建立。在实际的应用中,所述gbdt可以用于预测实际值,例如上述各个维度中的预定特征的表征值等。
在本实施例中,将用户在各个特征维度的特征数据分别代入对应的决策树模型。相应地,所述决策树模型根据代入的特征数据不同,得出不同的输出结果。一个用户的不同类型的特征数据分别在对应的决策树模型进行运算后,得到不同类型的输出结果。通过将上述输出结果进行累加,可以得到该用户的相应特征维度的表征值。
当然,在本实施例中采用举例的方式来表述可以采用gbdt算法构建模型,所属领域技术人员在本公开的技术精髓的启示下,还可能做出其他变更,或者利用程序语言和数学逻辑,编制出其他的算法。但只要其实现的功能和效果与本公开相同或相似,均应涵盖于本公开的保护范围内。
在该实施例中,无监督聚类、gbdt和lr的组合模型可以包括基于相应权值来将表征向量的表征值加权求和得到用户信用值。
在一个具体的实施方式中,作为示例而非限制,可以为学习出的每个gbdt算法结果值分配权值(如图5所示),当代入逻辑回归的公式后,可以确定最终的用户信用值。
在本公开的一个实施例中,为了保持数据最新,信用评估模块每天更新用户信用等级并向保险公司开放查询接口以供其查询用户信用等级。
图6示出了根据本公开的一个实施例的理赔模块604的框图。理赔模块604包括信用查询组件606和差异化服务组件608。信用查询组件用于向信用评估模块602查询用户信用等级并将所获得的用户信用等级传递至差异化服务组件608。差异化服务组件608基于所接收到的用户信用等级来为用户提供差异化理赔服务。
具体而言,确定用户信用等级是否大于或等于阈值,并且确定事故是否涉及内部损伤或人伤。当用户信用等级大于或等于阈值并且事故仅仅是车辆外部损伤且不涉及人伤时,差异化服务组件608可以为用户提供免现场查勘和取证、无需交警出具的事故责任认定书、修理厂直修、实施赔付、免押代步车,等等。由此,为诚信用户提供了极简的理赔体验和优质的服务,提升了用户粘性。而当用户信用等级低于阈值或者事故涉及内部损伤或人伤时,差异化服务组件608确定按照普通理赔流程来赔付用户。
在本公开的另一实施例中,当用户信用等级大于或等于阈值时,还可以为用户提供不涉及理赔的优质服务,诸如节假日意外险赠送等。上文中描述的阈值不限于任何特定阈值,而是保险服务提供者可根据自身业务要求来自行设定,并且上述提供极简的理赔体验的条件也并非是限制性的,而是保险服务提供者可根据自身业务要求来自行设定。
图7示出了根据本公开的一个实施例的基于信用评估的保险理赔方法700的流程图。在702,获取关于用户的来自保险服务提供者的保险数据以及来自第三方服务提供者的用户数据。保险数据包括该用户在该保险公司的询价、投保、理赔以及日常咨询和回放记录,等等。用户互联网数据包括该用户的关系网络、1度和2度关系黑名单关联度、消费记录、财富水平、lbs(基于位置的服务)信息、职业稳定度,等等。上述这些互联网用户数据可以对传统的保险企业自己的数据做出有益的补充,从而能够有助于更全面且更准确地反映用户的信用水平。
在704,基于该保险数据和用户数据来确定用户信用等级。在本公开的一个实施例中,通过无监督聚类、gbdt(梯度提升决策树)以及lr(逻辑回归)的组合来确定用户信用等级。gbdt用于生成具有强区分性和强解释性的特征组合,无监督聚类用于增强gbdt的效果,lr用于对通过无监督聚类和gbdt生成的经变换的特征组合进行收敛以确定用户的信用等级。以上方法步骤的更多细节在图8中讨论。
在706,向保险服务提供者提供该用户信用等级以供其基于该用户信用等级来为该用户提供差异化理赔服务。保险服务提供者向信用评估模块查询用户信用并接收信用评估模块提供的用户信用等级。随后,保险服务提供者基于所接收到的用户信用等级来为用户提供差异化理赔服务。上述方法步骤的细节在图9中讨论。
图8示出了根据本公开的一个实施例的用于信用评估的方法800的流程图。在802,选择保险数据和用户数据的数据组合中的初始变量并抽取变量子集。在804,对于每个变量子集使用聚类方法对该数据组合进行分组并为每组数据添加标签。该标签值即每个样本数据的特征向量中的新增特征维度,并且针对每个变量子集的每一次聚类都会生成新的标签。在806,通过gbdt对带标签数据进行特征变换。这样做使得通过gbdt模型得到的经变换特征组合的区分性更强,从而能够提升最终的lr模型得出的信用评估的准确度。在808,基于作为输入的经变换特征通过逻辑回归来预测用户的欺诈概率。通过逻辑回归算法可以学习出每个gbdt算法得出的结果值,当代入逻辑回归公式后,可以确定最终的用户欺诈概率,其范围在(0,1)之间,最后按照该欺诈概率1-10档次划分用户信用等级。
图9示出了根据本公开的一个实施例的用于提供差异化理赔服务的方法900的流程图。在902,向信用评估模块查询用户信用等级。信用评估模块每天更新用户信用等级并向保险公司开放查询接口以供其查询用户信用。在904,确定查询到的用户信用等级是否大于或等于阈值。如果是,则前进至步骤906,确定事故是否涉及内部损伤或人伤。如果否,则转至步骤910,提供传统理赔服务。如果确定事故不涉及内部损伤和人伤,则在步骤908处提供极简的理赔服务,诸如免现场查勘和取证、无需交警出具的事故责任认定书、修理厂直修、实施赔付、免押代步车,等等。如果确定事故涉及内部损伤或人伤,则转至步骤912,提供传统理赔服务。
以上参考根据本公开的实施例的方法、系统和计算机程序产品的框图和/或操作说明描述了本公开的实施例。框中所注明的各功能/动作可以按不同于任何流程图所示的次序出现。例如,取决于所涉及的功能/动作,连续示出的两个框实际上可以基本上同时执行,或者这些框有时可以按相反的次序来执行。
以上说明、示例和数据提供了对本公开的组成部分的制造和使用的全面描述。因为可以在不背离本公开的精神和范围的情况下做出本公开的许多实施例,所以本公开落在所附权利要求的范围内。
- 还没有人留言评论。精彩留言会获得点赞!