一种基于部件幂集和多尺度特征的行人重识别方法与流程
本发明属于计算机视觉技术领域,尤其是涉及一种基于部件幂集和多尺度特征的行人重识别方法。
背景技术:
在人的感知系统所获得的信息中,视觉信息大约占到80%~85%。图像与视频等相关的应用在国民日常生活的地位日益突出。图像处理学科既是科学领域中具有挑战性的理论研究方向,也是工程领域中的重要应用技术。行人重识别(personre-identification)是近几年智能视频分析领域兴起的一项新技术,属于在复杂视频环境下的图像处理和分析范畴,是许多监控和安防应用中的主要任务,并且在计算机视觉领域获得了越来越多的关注。
行人重识别是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。在监控视频中,由于相机分辨率和拍摄角度的缘故,通常无法得到质量非常高的人脸图片。当人脸识别失效的情况下,行人重识别就成为了一个非常重要的替代品技术。行人重识别有一个非常重要的特性就是跨摄像头,所以学术论文里评价性能的时候,是要检索出不同摄像头下的相同行人图片。行人重识别已经在学术界研究多年,但直到最近几年随着深度学习的发展,才取得了非常巨大的突破。
行人重识别的研究面临着诸如图像分辨率低、视角变化、姿态变化、光线变化以及遮挡等带来的诸多挑战。比如,(1)监控视频的画面一般比较模糊,分辨率也比较低,所以利用人脸识别等方式无法进行重识别的工作,只能利用头部之外的人体外观信息进行识别,而不同行人的体型和衣着服饰有可能相同,这为行人重识别的准确度带来了极大的挑战;(2)行人重识别的图像往往采自于不同的摄像机,由于拍摄场景、摄像参数不同,行人重识别工作一般存在光照变化及视角变化等问题,这导致同一个行人在不同摄像机下存在较大的差异,不同行人的外貌特征可能比同一个人的外貌特征更相似;(3)进行重识别的行人图像可能拍摄于不同的时间,行人姿态、衣着会有不同程度的改变。此外,在不同的光照条件下,行人的外观特征也会有很大的差异。此外实际视频监控下的场景非常复杂,很多监控场景人流量大,场景复杂,画面很容易出现遮挡等情况,这种时候靠步态等特征就很难进行重识别。以上情况都给行人重识别的研究带来了巨大的挑战,因此目前的研究距离实际应用层面还有很大的距离。
相对于行人检测来说,行人重识别的研究还不算成熟,但早在1996年,就有学者关注行人重识别问题,在2006年,行人重识别的概念第一次在cvpr上提出后,相关的研究不断涌现。此后越来越多的学者开始关注行人重识别的研究。近些年,每年在国际顶级的会议以及顶级期刊上关于行人重识别的工作不在少数。2012年,第一个行人重识别研讨会在eccv会议上召开;2013年,第一本行人重识别的专著出版了;2014年后,深度学习被应用到行人重识别领域;2016年,行人重识别迎来井喷式的增长,在各大计算机视觉的会议中出现了几十篇相关论文,尤其是基于深度神经网络的方法引起了广泛的关注;同时,相关数据集在不断地扩充,在各个数据集上的结果也获得很大的提升,到目前,行人重识别问题已成为计算机视觉的一个热点问题。
传统的行人重识别从特征提取和距离度量学习两个方面进行研究。2014年后,越来越多的研究者尝试将行人重识别的研究与深度学习结合在一起,深度学习不仅应用于提取高层特征,也为度量学习的研究带来了革新。即使深度学习在规模较小的数据集上的结果没有很明显的提升,但随着研究方法的成熟以及较大规模的数据集的出现,深度学习在行人重识别领域越来越受研究者们青睐。
技术实现要素:
本发明的目的在于提供一种基于部件幂集和多尺度特征的行人重识别方法。
本发明包括以下步骤:
(一)模型训练过程:
1)初始化模型参数;
2)输入训练图像到网络提取图像特征;
3)计算训练图像的多尺度特征;
4)枚举部件幂集,并提取其特征;
5)计算softmax交叉熵损失函数;
6)计算tripletloss三元损失函数;
7)计算组合排序模块的交叉熵损失函数;
8)使用梯度下降算法更新模型参数;
9)重复步骤2)~8)直到收敛;
10)使用模型计算数据库里所有图像的特征向量;
(二)模型推理过程:
11)输入图像到模型中,获得目标的特征向量;
12)计算目标和数据库图像的特征向量的欧氏距离;
13)选择欧氏距离最近的数据库图像对应的行人身份作为最终检测结果。
在步骤3)中,计算训练图像的多尺度特征,结合了最高层特征图和底层特征图得到多尺度的特征表示。
在步骤4)中,枚举部件幂集的具体方法为:将图像平均分为n个部分,然后枚举所有可能的部件组合,总的部件组合数目为:
在步骤5)中,所述softmax交叉熵损失函数,使用随机梯度下降算法训练判别器
其中,nim和nid分别表示图像的数目和行人身份的数目,yi表示第i张图行人的身份,
在步骤6)中,所述tripletloss三元损失函数为:
其中,图像ii和
在步骤7)中,所述组合排序模块的交叉熵损失函数为:
其中,
本发明是一种新颖的基于部件幂集和多尺度特征的行人重识别方法。早期的行人重识别研究主要关注点在全局的特征上,就是用整图得到一个特征向量进行图像检索。但是逐渐基于全局特征的行人重识别方法遇到了瓶颈,于是开始渐渐研究基于局部特征的行人重识别方法。常用的提取局部特征的思路主要有图像切块、利用骨架关键点定位以及姿态矫正等等。目前的方法有三个主要缺点:首先,这些方法严重依赖行人部件的对齐。因此,目前的方法无法在不引入额外信息的情况下,矫正行人部件不对称的问题。其次,大多数方法依赖人工设计部件组合来提升模型的鲁棒性。这些手工设计的特征往往需要更多的人工努力,而且也往往容易陷入局部最小值。最后,目前大部分方法只使用最粗糙的一层特征。因此,在更精细分辨率特征图上的空间细节往往被丢失。事实上,更精细分辨率的特征图上包含很多有用的低层特征,比如颜色、纹理。这些信息对于区分行人身份具有很重要意义。
本发明提出使用部件幂集和多尺度特征的行人重识别方法。首先,本发明提出部件幂集模块,枚举所有n个部件的全组合。这些组合包含了全局到局部,粗粒度到细粒度的特征组合。这种部件幂集可以带来很强的部件非对齐鲁棒性。其次,本发明还引入了组合排序模块来指导模型的训练。这种模块可以加强重要的部件组合,弱化不重要的部件组合,使得模型更加具有鲁棒性。最后,本发明在增加少量内存和时间消耗的情况下,结合了不同尺度的特征。不同尺度特征的结合可以带来更加抽象的语义信息和更加精细的特征图。大量的实验结果表明,本发明的方法取得了优异的行人重识别的性能。
附图说明
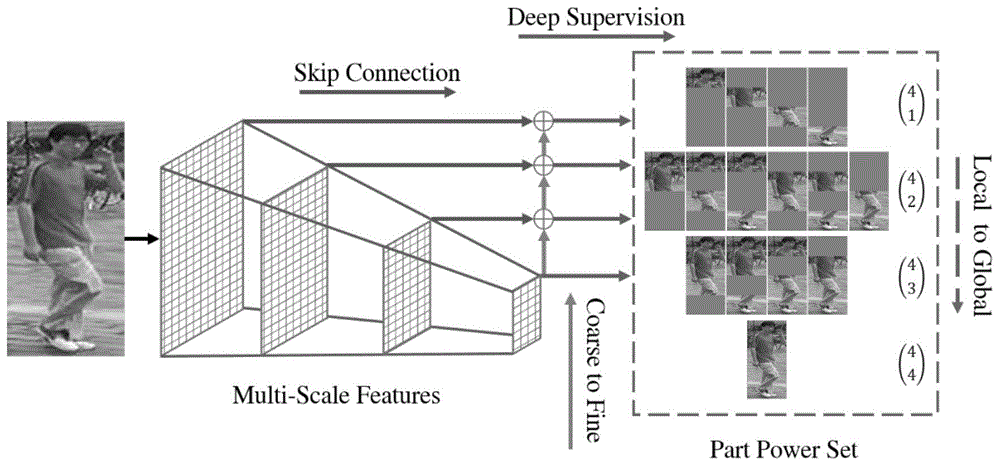
图1为本发明简略图。
图2为部件幂集对齐行人的关键部件。
图3为本发明的结构框架。
图4为本发明中的组合排序模块
图5为本发明中的多尺度特征提取结构。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
本发明实施例包括以下步骤:
首先定义本发明主要使用的符号。这里用
本发明使用resnet50(kaiminghe,x.zhang,s.ren,andj.sun,“deepresiduallearningforimagerecognition,”incvpr,2016.)网络作为的基本模型后端结构。通常情况下模型后端的深度越深,模型的表达能力也越强。如图1所示,给定一系列的特征图,本发明枚举出n个垂直分布的行人部件的全组合。同时,本发明还使用残差连接来构建多尺度特征图。本发明使用的枚举全组合方法可以有效的解决行人部件不对齐的问题。如图2所示,两张图像的显著部件的没有对齐的,通过特定的部件组合方式可以对齐部件。
本发明提出了部件幂集模块,如图3所示。首先,把特征图m进行垂直平均分割为n个部件。每部件的大小为
其中,nim和nid分别表示图像的数目和行人身份的数目,yi表示第i张图行人的身份,
其中,图像ii和
从上可以看到,最主要引入的计算量是全连接层的计算。额外的flops是:(2n-1)(2i-1)o,我们设置特征的尺度i=128,o=752为行人身份在market1501中的数量。因此,当n=5和n=10时候,额外的flops分别是6×106和0.2×109。注意到,resnet50有3.8×109flops。因此,额外引入的计算量是很少的。
本发明提出了组合排序模块,如图4所示。组合排序模块有两个子网络,每个子网络分别有个全连接层和softmax归一化层。第一个子网络输出预测概率
其中,wid表示全连接层的权值。第二个子网络输出预测概率
其中,wra表示全连接层的权值。我们通过点对点乘积来使用
组合排序模块只需要少量的参数,因为对于所有的部件组合,两个子网络的全连接层的参数wid和wra是共享的。最后,我们得到组合排序模块的交叉熵损失函数:
其中,
本发明引入了多尺度特征学习,如图5所示。为了解决高层特征的空间细节的损失,引入多尺度深度学习特征来捕获从粗粒度到细粒度的具有判别力的行人特征。特别地,对于resnet,使用最后4个阶段输出的特征图来构建多尺度特征表示。构建方法分为以下两个步骤:(1)从最高层特征开始,使用卷积核为1×1的卷积层来减小通道数量,然后上采样两倍特征图;(2)上采样后的特征图和前一阶段输出的特征图进行点对点的加法,获得合并的特征图。重复以上两个步骤直到所有四个阶段的特征图都被遍历过。最后,把多尺度特征图输入到部件幂集模块和组合排序模块,也就是所有的多尺度特征都使用了前面的损失函数。
本发明提出使用部件幂集和多尺度特征的行人重识别方法。首先,本发明提出部件幂集模块,枚举所有n个部件的全组合。这些组合包含了全局到局部,粗粒度到细粒度的特征组合。这种部件幂集可以带来很强的部件非对齐鲁棒性。其次,本发明还引入了组合排序模块来指导模型的训练。这种模块可以加强重要的部件组合,弱化不重要的部件组合,使得模型更加具有鲁棒性。最后,本发明在增加少量内存和时间消耗的情况下,结合了不同尺度的特征。不同尺度特征的结合可以带来更加抽象的语义信息和更加精细的特征图。大量的实验结果表明,本发明的方法取得了优异的行人重识别的性能。
- 还没有人留言评论。精彩留言会获得点赞!