基于人工神经网络的RGB图像场景三维模型重建方法与流程
本发明属于计算机视觉、计算机图形学技术领域,特别地,本发明涉及一种基于人工神经网络的单张rgb图像场景三维模型重建方法。
背景技术:
rgb图像是目前最广泛应用的媒体数据形式,可以快速捕捉,记录周围三维世界的信息。使用单张rgb图像重建图像中记录场景的三维模型,是计算机视觉与计算机图形学领域中一个重要且基础的问题,在人机交互,虚拟现实及增强现实等领域中有着非常广泛的应用。例如,在增强现实领域中,使用rgb相机拍摄了一张场景的二维图像,重建得到该场景的三维模型,可以方便地对场景三维模型进行编辑修改,通过虚拟的三维模型看到对场景进行改动后整体场景的呈现效果,给人类日常生活和工作的很多方面提供了便利。正是由于根据rgb图像重建三维模型有着良好的应用前景,但目前仍存在较多问题需要克服,该基础课题研究具有较高的科研和应用价值。
然而根据rgb图像对重建场景的三维拓扑及场景中对象三维模型具有相当大的挑战性,主要瓶颈限制是缺乏潜在的场景三维信息,具体而言,缺少深度信息使得改变视角或合理地解决物体之间的遮挡遮挡和照明变化具有挑战性,这是对场景中物体进行对象级别操作所必需的,而场景中物体对场景墙面与地面,墙面与墙面,墙面与天花板之间交线存在较多遮挡,也为重建场景的三维拓扑增加了难度。
在计算机视觉领域,对复杂室内场景进行较好的布局识别和三维重建一直是一个重要但具有挑战性的问题。因此,本发明中的方法利用人工神经网络模型对室内场景进行布局识别和场景物体检测,克服传统方法在处理复杂场景时存在的不足,为三维重建提供较好的输入信息,使得可以重建得到更为精确的场景三维模型。
技术实现要素:
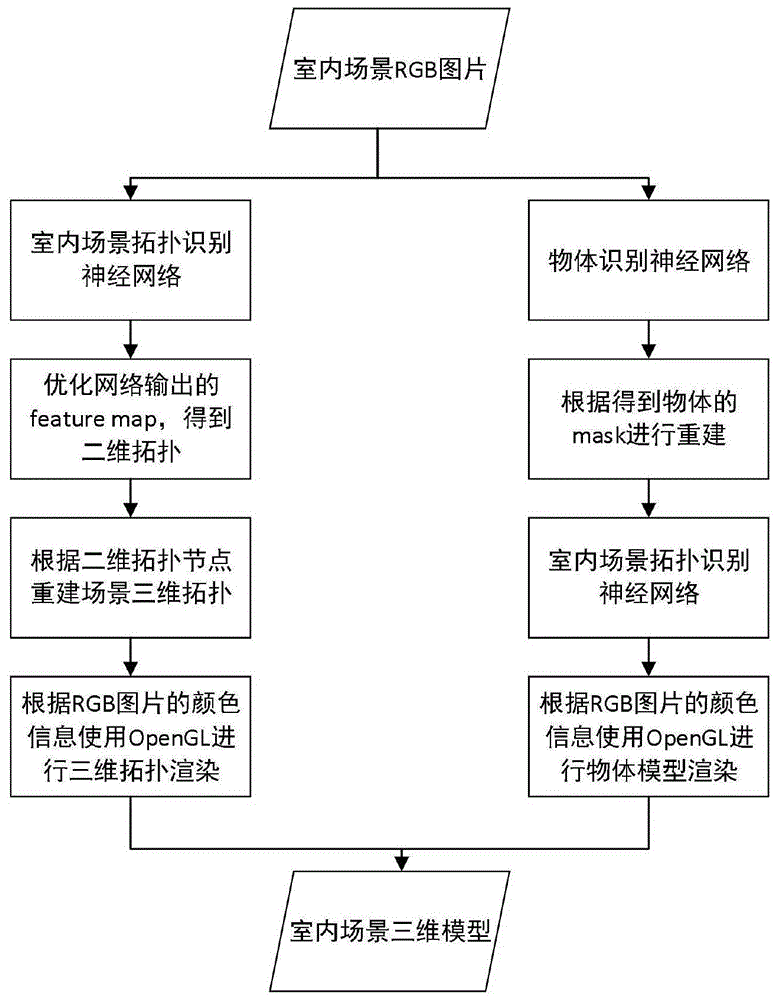
本发明的目的是解决复杂室内场景下的场景拓扑结构三维重建和物体三维重建的问题。本发明提出了一种基于人工神经网络的rgb图像场景三维模型重建方法,其特征在于使用人工神经网络模型对输入的图像进行处理,识别得到场景的二维拓扑结构和场景中物体的类别和形状,进一步对神经网络输出的特征图进行优化,该优化分为拓扑结构优化和物体识别优化两个模块进行;随后使用该信息迭代计算得到三维模型的参数,包括平面到相机中心距离、平面法向量;使用opengl进行三维模型渲染,利用原输入图像中的像素颜色对重建得到的三维平面进行颜色渲染,得到更接近输入图像中场景的三维模型;
所述的二维拓扑结构是指地面与墙面、天花板与墙面、墙面与墙面之间的交线三类交线组成的结构。
本发明所述的一种基于人工神经网络的rgb图像场景三维模型重建方法,包括如下步骤:
步骤1.训练阶段:
用到两个人工神经网络模型,分别实现场景的二维拓扑结构识别和物体检测功能,需要分别进行训练;
二维拓扑结构识别的人工神经网络模型:
首先更改训练数据:原始数据集中对室内场景的三类交线进行标记,groundtruth中包含了地面与墙面、天花板与墙面、墙面与墙面之间的交线三类交线的标记数据,采用墙面与地面交线、墙面与墙面交线、墙面与天花板交线三类交线来定义室内场景的二维拓扑,从而将室内常见的二维拓扑识别看作是回归得到三类交线位置的问题;其中使用的数据集为lsun;
其次设计神经网络并训练,实现对室内场景的二维拓扑识别;选择卷积残差神经网络作为网络的基本结构,为了使得网络能够输出矩阵,在网络的顶端用卷积层代替一般的全连接层,实现对室内场景的二维拓扑识别,输出为场景中三类交线的位置预测结果
物体检测的人工神经网络模型:
设计网络并训练,实现对室内场景的语义分割,从而检测到场景中物体的分布情况及轮廓;搭建人工神经网络模型,选择卷积残差神经网络和金字塔池化网络作为网络的基本结构,为了使得网络能够输出矩阵,在网络的顶端用卷积层代替一般的全连接层,实现对室内场景的语义分割;输入数据为普通rgb图片,对应的groundtruth为输入图片中的场景人工语义分割的结果,网络输出结果与groundtruth之间进行比较,运用梯度下降的方法求得较好的网络权值,得到的模型能够对室内场景中的物体进行37类的分类,网络输出结果为w*h*37的矩阵,每个通道对应一类物体在该场景中存在概率,取每个像素对应的37维概率向量中最大值所在通道作为汇总结果中该像素的类别,最终可得到该场景的语义分割结果,从而检测到场景中物体的分布情况及轮廓;
步骤2.用步骤1中得到的模型对输入的rgb图像进行处理,得到输入图像中场景的二维拓扑识别特征图和物体识别特征图,对特征图进行优化,过滤其中的噪声,得到场景二维拓扑的节点像素坐标和场景中物体外观轮廓的坐标及其物体类别标签;
步骤3.对室内场景的拓扑结构和物体进行重建;
步骤4.使用opengl进行三维模型渲染,三维模型表面像素颜色为原输入图像中场景拓扑平面和物体的颜色,较为真实地渲染得到场景的三维模型。
步骤3所述的对室内场景的拓扑结构和物体进行重建,其相关约束条件如下:
①相机光轴方向平行于地面;
②拍摄的场景为曼哈顿世界,相邻平面两两垂直,场景中物体为规则物体;
③该视频帧序列通过透视投影获得,使用具有固有矩阵k的拍摄设备;点q为相机坐标系下的一点,点q为像素坐标系下的一点,点q映射到点q满足如下公式:
qi=λk-1qi
其中,λ为转换系数,点q坐标表示,点q坐标表示以及转换矩阵k分别表示如下:
其中,f为相机的焦距,δu和δv为像平面坐标系转为像素坐标系的转换。
平面法向量和平面到相机中心的距离满足:
dp=npqi=npλk-1qi;
其中,np为平面法向量。
利用步骤2中得到的场景二维拓扑节点坐标和物体外观轮廓节点坐标,利用曼哈顿世界相邻平面两两垂直,利用空间中一点在像素坐标系下存在唯一投影进行约束,优化得到输入图像中组成场景拓扑平面和组成场景中物体平面的三维信息,经opengl渲染后即为该帧图像对应的三维平面。
本发明的特点及有益效果:
本发明实现了一种基于人工神经网络的单张rgb图像场景三维模型重建方法,对室内场景下的重建,识别等计算机视觉任务有重大意义。本发明中的方法优势如下
1.利用人工神经网络模型完成室内场景下的布局识别和物体识别任务,提高系统对复杂场景的处理能力;
2.完全自动地识别场景中的拓扑结构和物体外观轮廓,无需人工参与;
3.使用单目的rgb信息还原三维信息,减少硬件成本,使用优化算法求解得到场景中拓扑平面和构成物体平面的法向量和到相机中心距离。
此技术可以在普通pc机或工作站等硬件系统上实现。
附图说明
图1为本发明方法总体流程图。
图2为按照平面分类存在语义歧义的情况举例。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1和2所示,基于人工神经网络的rgb图像场景三维模型重建方法,包括如下实现步骤:
步骤1.训练阶段:
方法中用到两个人工神经网络模型,分别实现场景的二维拓扑结构识别和物体检测功能,需要分别进行训练。
更改训练数据:原始数据集中对室内场景的三类交线进行标记,groundtruth中包含了地面与墙面,天花板与墙面,墙面与墙面之间的交线三类交线的标记数据,但三类交线的像素点数量远远少于背景像素的数量,造成训练数据的不平衡(dataunbalance),增加训练过程的难度。目前常用的数据集也有通过地面,天花板和三类墙面(左边,中间和右边)对室内场景的二维拓扑进行定义。这这种定义方式不存在训练数据不平衡的情况,不同平面的像素数量分布基本均衡,但它存在的问题是在某些情况下墙面的语义会出现歧义如图2所示,在场景中出现两面墙的情况下,该种拓扑结构定义方式无法唯一确定两面墙的语义,可以理解为中间墙面和左边墙面,中间墙面和右边墙面,亦或者是左边墙面和右边墙面。综合考虑,本发明工作采用墙面与地面交线,墙面与墙面交线和墙面与天花板交线三类交线来定义室内场景的二维拓扑,为了避免训练数据不平衡带来的训练困难,文中将室内常见的二维拓扑识别看作是回归得到三类交线位置的问题。
用于二维拓扑结构识别的人工神经网络模型ⅰ:
选择卷积残差神经网络作为网络的基本结构,为了使得网络可以输出矩阵,在网络的顶端用若干卷积层代替一般的全连接层,实现对室内场景的二维拓扑识别,输出为场景中三类交线的位置预测结果
用于物体检测的人工神经网络模型ⅱ:
选择卷积残差神经网络和金字塔池化网络作为网络的基本结构,为了使得网络能够输出矩阵,在网络的顶端用若干卷积层代替一般的全连接层,实现对室内场景的语义分割。输入数据为普通rgb图片,对应的groundtruth为输入图片中的场景人工语义分割的结果,网络输出结果与groundtruth之间进行比较,运用梯度下降的方法求得较好的网络权值,得到的模型能够对室内场景中的物体进行37类的分类,网络输出结果为w*h*37的矩阵,每个通道对应一类物体在该场景中存在概率,取每个像素对应的37维概率向量中最大值所在通道作为汇总结果中该像素的类别,最终可以得到该场景的语义分割结果,从而检测到场景中物体的分布情况及轮廓;
步骤2.用步骤1中得到的模型对输入的rgb图像进行处理,得到输入图像中场景的二维拓扑识别特征图和物体识别特征图,对特征图进行优化,过滤其中包含的部分噪声,得到场景二维拓扑的节点像素坐标和场景中物体外观轮廓的坐标及其物体类别标签。
步骤3.基于相关约束对室内场景的拓扑结构和物体进行重建,相关约束条件如下:
①相机光轴方向平行于地面;
②拍摄的场景为曼哈顿世界,相邻平面两两垂直,场景中物体为规则物体;
③该视频帧序列通过透视投影获得,使用具有固有矩阵k的拍摄设备;点q为相机坐标系下的一点,点q为像素坐标系下的一点,点q映射到点q满足如下公式:
qi=λk-1qi
其中,λ为转换系数,点q坐标表示,点q坐标表示以及转换矩阵k分别表示如下:
其中,f为相机的焦距,δu和δv为像平面坐标系转为像素坐标系的转换;
平面法向量和平面到相机中心距离满足:
dp=npqi=npλk-1qi
利用步骤2中得到的场景二维拓扑节点坐标和物体外观轮廓节点坐标,利用曼哈顿世界相邻平面两两垂直,利用空间中一点在像素坐标系下存在唯一投影进行约束,优化得到输入图像中组成场景拓扑平面和组成场景中物体平面的三维信息(平面单位法向量和该平面到相机中心距离),经opengl渲染后即为该帧图像对应的三维平面。
步骤4.使用opengl进行三维模型渲染,三维模型表面像素颜色为原输入图像中场景拓扑平面和物体的颜色,较为真实地渲染得到场景的三维模型。
- 还没有人留言评论。精彩留言会获得点赞!