一种基于深度哈希的多标签图像检索方法与流程
本发明涉及图像检索技术领域,具体涉及一种基于深度哈希的多标签图像检索方法。
背景技术:
基于内容的图像检索技术是一种使用图像作为输入的检索技术,区别于基于文本的图像检索技术。单标签图像哈希是使用哈希算法对使用单个标签标注的图像进行编码的技术,目前主流的方法是将深度学习与哈希算法相结合;多标签图像哈希技术的优势在于可以充分学习到图像所包含的多重语义信息,更加贴近现实应用场景,但目前的多标签图像哈希的性能如准确率等还有待提升。
技术实现要素:
为了提高多标签图像检索的准确率,本发明提供一种基于深度哈希的多标签图像检索方法,所述方法引入成对多标签图像标签向量的余弦距离作为监督信息参与模型训练,使用残差网络对多标签图像进行特征抽取,同时引入二进制编码机制对抽取的高维特征进行降维,并使用多标签图像数据集对基于残差网络的深度哈希模型进行训练;训练完成后调用该模型在多标签图像查询数据集上进行图像检索,并评估该模型的泛化能力及检索准确度。
本发明的技术方案包括如下步骤:
(1)给定多标签图像训练数据集。
(2)搭建基于深度学习keras框架的软件环境,为后续网络模型的训练做准备。
(3)对输入的多标签图像训练数据集进行数据预处理,处理成图像与标签一一对应的形式。
(4)使用残差网络加哈希损失层构建基于深度哈希的多标签图像检索模型,采用50层残差网络的前49层来提取多标签图像的高维语义特征,将残差网络最后的分类层替换为哈希损失层,对获取的高维语义特征进行降维。
(5)将经过数据预处理的多标签图像训练集输入多标签图像检索模型,使用多标签图像标签向量的余弦距离来衡量多标签图像之间的相似性,使用加权交叉熵损失和最小均方误差损失来构造一个损失函数以此保留成对多标签图像的相似性排序信息,使用量化损失函数来控制模型输出的哈希编码质量;然后将上述三组损失函数构成联合损失函数对构建好的模型进行训练,并生成hdf5格式的模型文件。
(6)使用训练好的多标签图像检索模型对多标签图像库中图像进行哈希编码,将得到多标签图像的哈希编码存入哈希表,从而建立起多标签图像库的索引库。
(7)从多标签图像查询数据集中获取图片作为查询图像,调用训练好的深度哈希模型来得到查询图像的哈希编码,计算输入图像与多标签图像数据库中图像的相似度,使用平均检索精度来评估模型的泛化能力。
附图说明
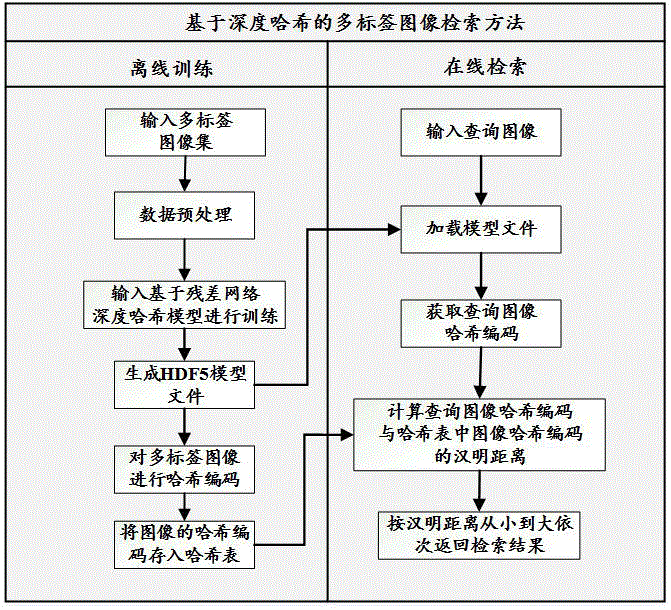
图1为本发明的流程图。
图2为本发明中的模型训练及在线检索过程图。
具体实施方式
本发明给出的实施例设计了一种新的多标签图像检索模型,一方面,模型使用残差网络增强了对多标签图像低维特征的提取能力,同时借助残差网络的恒等映射模块可以加快模型收敛速度;另一方面,模型应用了微调策略,从而可以增加模型的检索准确率。具体来说分为两个阶段:离线训练和在线检索。
离线训练阶段:首先,构建基于残差网络的深度哈希模型,使用预训练的权重来初始化模型中的参数;其次,引入交叉熵损失、最小均方误差损失和量化损失函数损失构造一个联合损失函数作为监督;最后,使用目标多标签图像训练集对该模型进行微调。
在线检索阶段:使用已训练好的深度哈希模型对多标签图像内容进行二值化编码,然后将二值化编码和图像标识以键值对的形式存储到哈希表中。当用户输入查询图像时,使用哈希模型产生查询图像二值检索码hq,计算hq与多标签图像数据库中所有二值检索码的汉明距离,按照汉明距离从小到大获得检索结果排序列表,返回检索排序结果列表中相似度最高的前n(1≤n≤检索排序结果列表长度)张图像作为检索返回结果。
参照图1,本发明包括如下步骤:
(1)给定多标签图像训练数据集。
(2)搭建基于深度学习keras框架的软件环境为后续网络模型的训练做准备。
(3)对输入的多标签图像训练数据集进行数据预处理,处理成图像与标签一一对应的形式。
(4)使用残差网络加哈希损失层构建基于深度哈希的多标签图像检索模型,具体来说,为了获取所述模型大小与多标签图像检索精度之间的平衡,本发明采用50层残差网络来提取多标签图像的高层语义特征。为了解决多标签图像检索的效率问题,本发明将残差网络最后的分类层替换为哈希损失层,对获取的高维语义特征进行降维。一方面,所述模型使用了性能优异的网络结构来获得多标签图像更好的特征表示;引入哈希编码机制对高维的特征进行降维,在保证检索准确率的基础上减少检索消耗的时间,从而获得一种高效、准确的多标签图像检索方法;另一方面,所述模型在训练时应用了微调策略以增加模型的检索准确率。
(5)将经过数据预处理的多标签图像训练集输入所述模型,为了保留多标签图像中包含的多级相似性信息,本方明使用多标签图像标签向量的余弦距离来衡量多标签图像之间的相似性。在此基础上,本方明使用交叉熵损失和最小均方误差损失来构造一个损失函数以此保留成对多标签图像的相似性排序信息;使用量化损失函数来控制模型输出的哈希编码质量;然后将上述三组损失函数构成联合损失函数对构建好的模型进行训练以获取多标签图像更好的特征表示,并生成hdf5格式的模型文件。
(6)使用训练好的模型对多标签图像库中图像进行哈希编码,将得到多标签图像的哈希编码存入哈希表,从而建立起多标签图像库的索引库。
(7)从多标签图像查询数据集中获取图片作为查询图像,调用训练好的模型来得到查询图像的哈希编码,计算输入图像与多标签图像数据库中图像的相似度,使用平均检索精度(map)来评估模型的泛化能力。
参照图2,所述多标签图像检索模型训练及检索的具体步骤如下:
(1)首先在imagenet大规模图像数据集上对50层残差网络训练得到预训练模型。
(2)使用残差网络加哈希损失层构建基于深度哈希的多标签图像检索模型,该模型采用50层残差网络的前49层网络层,同时将残差网络最后一个分类层替换为哈希层。使用步骤(1)得到的预训练模型的权重来初始化已构建好基于深度哈希模型的参数,然后在目标多标签图像数据集上对已构建的模型进行固定参数的微调。
(3)将已经微调好的模型对多标签图像数据库图像进行哈希特征生成、特征二值化。然后使用多标签图像查询数据集中图像作为查询图像,计算查询图像与多标签图像数据库中图像的相似度,使用平均检索精度来评价模型的泛化能力。模型在两个多标签图像查询数据集的最高平均检索精度分别为87.39%和82.41%。
构建所述多标签图像检索模型主要包括如下步骤:
(1)保留50层残差网络的前49层作为模型的特征提取模块,使用哈希层替换原残差网络的分类层,实现对提取的高维多标签图像语义特征降维。
(2)计算成对多标签图像的标签相似度矩阵s,其计算的表达式如下:
s={sij|i,j=1,2,...,n};
其中sij为矩阵s第i行第j列的元素,其取值可分为两种情况:当多标签图像ii和ij共有至少一个类别标签时,sij取值为rij;否则的话,sij取值为0。rij取值为成对多标签图像标签向量的余弦距离,计算表达式如上述公式所示,其中li和lj分别为多标签图像ii和ij的标签向量,<li,lj>为li和lj的内积,||liorj||2为多标签图像标签向量li或lj的l2范数,本发明将成对多标签图像标签向量的余弦距离作为监督信息参与模型训练。
为了让哈希编码能更好地表示模型提取的多标签图像特征,本发明使用量化损失来控制哈希编码的质量;同时,为了提升多标签图像检索的性能,本发明使用交叉熵损失和最小均方误差损失对模型进行训练,以此来保留多标签成对图像之间存在的多层次语义相似度。
量化损失函数的表达式如下:q=|||ui|-1||1+|||uj-1|||1。
其中ui为深度哈希模型输出多标签图像的q-bit哈希编码,||ui||1为一种向量的元素级操作,表示对向量ui的每一维元素取绝对值,量化损失函数促使模型输出分布在-1、+1附近。
交叉熵损失函数和最小均方误差损失函数如下:
其中sij=0or1表示交叉熵损失函数,以此来表示成对多标签图像拥有的类别标签完全一致或者是完全不一致的情况;0<sij<1表示成对多标签图像只拥有部分相似的类别标签的情况。其中
(3)最终本模型使用交叉熵损失、最小均方误差损失和量化损失函数损失构成的联合损失函数进行训练,并应用微调的策略对模型进行训练从而引导基于残差网络的深度哈希模型达到一个预期的效果。
- 还没有人留言评论。精彩留言会获得点赞!