基于矩阵分解和知识图谱的服装搭配推荐方法与流程
本发明属于服装搭配推荐
技术领域:
,具体涉及一种基于矩阵分解和知识图谱的服装搭配推荐方法。
背景技术:
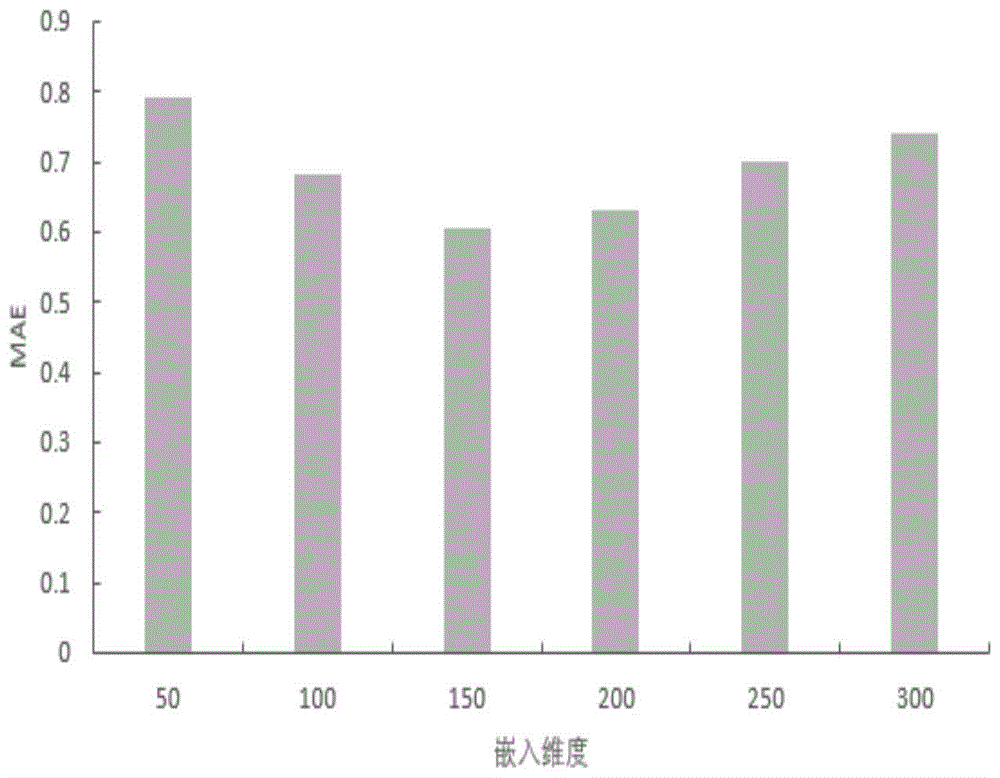
:服装搭配推荐系统在服装销售活动中具有重要的意义,通过服装搭配可以推荐适合用户身材的服装搭配组合,比如判定这件衬衫和这件裤子是否更相配。深入挖掘服装的搭配组合模式,通过服装搭配组合进行推荐可以增加服装交叉销售量,同时可以满足用户对服装搭配的个性化需求,指导用户的着装。服装搭配推荐属于推荐系统领域搭配组合推荐的一种,与推荐领域其他商品的搭配推荐不同。目前,进行服装搭配推荐的方法主要有以下几种:(1)基于矩阵分解的协同过滤推荐方法将上衣服装和下衣服装的搭配关系映射到协同过滤算法的用户与商品的评分关系上,挖掘潜在的上下装服装搭配模式。但是这种方法不能考虑到上下装的任何内容信息,主要利用具有相同搭配的服装之间的相似性关系来进行推荐;(2)基于内容的服装搭配推荐方法主要是通过服装的内在属性信息和服装图像信息来进行服装搭配,如服装标题在一定程度上对服装的颜色、款式、风格进行了描述,计算上装和下装的标题相似性,基于这种考虑挖掘上装和下装服装描述的相关性来衡量服装是否搭配;(3)基于关联规则的服装搭配方法主要深入挖掘用户交易历史记录,挖掘购买上装和下装的购买频繁模式。基于服装领域知识的推荐方法主要是依靠服装专家建立的专家知识库,指定一系列的规则利用推理机制生成推荐结果,但是该方法的性能好坏直接被知识库的完备性所制约。技术实现要素:本发明的目的是提供一种基于矩阵分解和知识图谱的服装搭配推荐方法,解决了现有服装搭配推荐方法中不考虑服装语义信息的问题。本发明所采用的技术方案是,基于矩阵分解和知识图谱的服装搭配推荐方法,具体操作过程包括如下步骤:步骤1,根据服装自身的特性,建立上装和下装搭配组合矩阵,通过分解搭配组合矩阵分别得到上装特征矩阵和下装特征矩阵;步骤2,在步骤1分解搭配组合矩阵的过程中融入上装和下装之间的语义信息,结合知识图谱和矩阵分解计算上下装的相似度,得到合适的服装搭配推荐。本发明的其他特点还在于,步骤1的具体过程如下:根据服装自身的特性,将上装和下装的搭配看作二元关系,则形成服装搭配组合矩阵m,将搭配组合矩阵m分解后得到上装特征矩阵uc,下装特征矩阵lc,如式(1)所示:m=uc×lc(1)为了对比分解后的上装特征矩阵uc与下装特征矩阵lc相乘结果与原始搭配组合矩阵差异,定义损失函数将矩阵分解问题转化为求解最优解问题,采用平方损失的损失函数如式(2)所示:式中,如果上装uc与下装lc是专家给出的搭配,则muc,lc=1,否则muc,lc=0;m'uc,lc为上装uc与下装lc搭配的估计值;λ1||puc||2+λ2||qlc||2是正则化项,来减少过拟合风险。优选的,步骤2的具体过程如下:步骤2.1,通过知识图谱表示学习transr算法训练得到服装的特征向量;步骤2.2,将步骤1中服装搭配组合矩阵中的上装特征矩阵和下装特征矩阵与步骤2.1知识图谱得到的服装特征向量进行匹配;步骤2.3,根据步骤2.2的匹配结果,选取知识图谱中与待预测上装最相似的k个近邻下装融入式(1)得到矩阵分解模型;步骤2.4,通过学习步骤2.3得到的模型求解矩阵分解后的低维上装特征矩阵和下装特征矩阵,计算上装和下装的相似度,得到下装的预测评分。优选的,步骤2.3中将知识图谱中进行融合后的目标函数为如式(3)所示:其中,式中第一项来自矩阵分解模型;第二项和第三项分别是上装特征矩阵和下装特征矩阵过拟合的正则化项,来减少过拟合风险;第四项是通过知识图谱表示学习计算出下装之间的隐藏相似性信息。nqlc,i表示下装qlc,i的最相似的k个近邻集合;sim(qlc,i,qlc,j)表示余弦相似度函数,用于计算下装特征向量lci和下装特征向量lcj的相似度,值的大小范围介于[-1,1]之间,如式(4)所示:式中,d是通过transr模型训练出来的实体向量的维度;优选的,对式(3)的求解过程如下:采用随机梯度下降的方法最小化目标函数求解上装特征矩阵puc和下装特征矩阵qlc;具体是:通过对参数求偏导数来寻找最快下降方向,分别如式(5)和式(6)所示:采用梯度下降方法对融合后的目标函数公式(3)进行参数学习优化,当上装特征矩阵puc和下装特征矩阵qlc与步骤1中式(2)的求解相近时,则迭代过程结束,将此时的上装特征矩阵puc和下装特征矩阵qlc带入公式4中计算相似度,从而得到服装搭配推荐结果。本发明的有益效果是,基于矩阵分解和知识图谱的服装搭配推荐方法,解决了现有服装搭配推荐方法中不考虑服装语义信息的问题。考虑上下装的语义信息,将服装的语义相似性融入上下装分解矩阵中,使推荐的服装搭配组合更具专业指导作用、更符合时尚潮流、从而更加贴合用户的需求,对用户的着装指导和推荐不再局限于用户自身的搭配习惯。通过知识图谱表示获取上下装潜在的服装知识信息,将潜在的搭配规则信息融入到矩阵分解模型中,从而得到更准确的服装搭配结果。附图说明图1是本发明的实施例中不同嵌入维度下的mae值图;图2是本发明的实施例中不同嵌入维度下的rmse值图;图3是本发明的实施例中不同近邻数的mae值图;图4是本发明的实施例中不同近邻数的rmse值图;图5是本发明的实施例中搭配推荐结果图。具体实施方式下面结合附图和具体实施方式对本发明进行详细说明。本发明的基于矩阵分解和知识图谱的服装搭配推荐方法,具体操作过程包括如下步骤:步骤1,根据服装自身的特性,建立上装和下装搭配组合矩阵,通过分解搭配组合矩阵分别得到上装特征矩阵和下装特征矩阵;步骤1的具体过程如下:在进行上衣服装和下衣服装的搭配时,每件上装和每件下装都有自己的特征属性,将上装和下装的搭配看作一种二元关系,从而形成一个服装搭配关系矩阵。通过对搭配矩阵进行分解可以得到上装特征矩阵和下装特征矩阵,降低了搭配矩阵的维度。通过服装搭配专家给出的服装搭配组合我们可以得到一个二维矩阵,将专家给出的搭配对应矩阵中的值设置为1,然后通过矩阵分解拟合服装搭配矩阵。定义服装搭配组合矩阵为m,将搭配组合矩阵m分解后得到上装特征矩阵uc,下装特征矩阵lc,如式(1)所示:m=uc×lc(1)为了对比分解后的上装特征矩阵uc与下装特征矩阵lc相乘结果与原始搭配组合矩阵差异,定义损失函数将矩阵分解问题转化为求解最优解问题,采用平方损失的损失函数如式(2)所示:式中,如果上装uc与下装lc是专家给出的搭配,则muc,lc=1,否则muc,lc=0;m'uc,lc为上装uc与下装lc搭配的估计值;λ1||puc||2+λ2||qlc||2是正则化项,来减少过拟合风险。步骤2,在步骤1分解搭配组合矩阵的过程中融入上装和下装之间的语义信息,结合知识图谱和矩阵分解计算上下装的相似度,得到合适的服装搭配推荐。步骤2的具体过程如下:矩阵分解过程中,通过梯度下降方法最优化损失函数l求出上装特征矩阵和下装特征矩阵,将上装特征矩阵和下装特征矩阵相乘得到原始搭配矩阵中空缺的近似值,从而可以预测专家未给出的上装和下装是否未搭配。但在求解过程中,可能会丢失上下装之间的潜在语义相似性信息,考虑到上下装之间潜在的语义特征,我们将知识图谱表示学习和矩阵分解结合进行服装的搭配推荐。专家进行搭配服装的基本思想是从上装和下装的属性语义相似性来确定套装的,高度相似的上下装矩阵分解后的向量表示也是高度相似的。比如,上装uc1和下装lc1语义特征相似,代表他们的特征向量也是相似的。知识图谱表示学习服装实体嵌入到低维向量中,通过相似度函数计算低维向量中上下装特征之间的相似度,将相似性潜在因子融入矩阵分解中,以此融入上下装之间的潜在语义信息。融合知识图谱表示学习和矩阵分解的服装搭配推荐包括如下步骤:步骤2.1,通过知识图谱的学习transr算法训练得到服装的特征向量;步骤2.2,将步骤1中服装搭配组合矩阵中的上装特征矩阵和下装特征矩阵与步骤2.1知识图谱得到的服装特征向量进行匹配;步骤2.3,根据步骤2.2的匹配结果,选取知识图谱中与待预测上装最相似的k个近邻下装融入式(1)得到矩阵分解模型;步骤2.4,通过学习步骤2.3得到的模型求解矩阵分解后的低维上装特征矩阵和下装特征矩阵,得到原始搭配矩阵中的预测值,即指定上装的预测下装,训练集中的评分近似看作上下装之间的相似度,评分高代表推荐的下装和上装搭配出的效果更好。步骤2.3中将知识图谱中进行融合后的目标函数为如式(3)所示:其中,式中第一项来自矩阵分解模型;第二项和第三项分别是上装特征矩阵和下装特征矩阵过拟合的正则化项,来减少过拟合风险;第四项是通过知识图谱表示学习计算出下装之间的隐藏相似性信息。nqlc,i表示下装qlc,i的最相似的k个近邻集合;sim(qlc,i,qlc,j)表示余弦相似度函数,用于计算下装特征向量lci和下装特征向量lcj的相似度,值的大小范围介于[-1,1]之间,如式(4)所示:式中,d是通过transr模型训练出来的实体向量的维度;对式(3)的求解过程如下:采用随机梯度下降的方法最小化目标函数求解上装特征矩阵puc和下装特征矩阵qlc;具体是:通过对参数求偏导数来寻找最快下降方向,分别如式(5)和式(6)所示:采用梯度下降方法对融合后的目标函数公式(3)进行参数学习优化,当上装特征矩阵puc和下装特征矩阵qlc与步骤1中式(2)的求解相近时,则迭代过程结束,将此时的上装特征矩阵puc和下装特征矩阵qlc带入公式4中计算相似度,从而得到服装搭配推荐结果。本发明采用平均绝对值误差(meanabsoluteerror,mae)和均方根误差(rootmeansquarederror,rmse)两个指标对本发明的推荐方法进行评估,这两个指标是推荐系统中预测评价指标中常用的两种度量方式。平均绝对误差可以计算预测评分和真实评分之间的差异。均方根误差是所有项目真实评分和预测评分误差的平方之和的平均值的根值。mae和rmse分别如式(7)和式(8)所示:式中,ep表示测试集,rua表示用户u对商品α的真实评分,ru'a表示用户u对商品α的预测评分;mae和rmse的值越小代表推荐的结果越准确。实施例通过爬虫技术抓取了polyvore网站的时尚衣服搭配数据及其相关信息,构建了一个大规模的服装搭配数据集。对每一个服装搭配,包含服装的图像,标题,类别,评分,点赞数等,本文选取点赞数大于100的配对作为比较好的搭配对,在人工标注和数据清洗之后,包含一些服装搭配组合信息,获得比较好的搭配组合有4034对。上装分为t恤衫、衬衫、卫衣、毛衣、运动衣、外套六种类别,包含12623条上装信息。下装分为牛仔裤、休闲裤、运动裤、裙装四类,包含13653条下装信息。为了构建与之对应的知识图谱数据集,抓取对应的polyvore网站的服装数据,在对数据结构化之后进行知识抽取,抽取的数据以三元组的形式存储。经过处理后的最终得到与之对应的2732个实体,5种关系属性和12660条三元组数据。对专家给出的服装搭配进行抽样,抽取3000条作为训练样本,剩下的作为测试样本。本文的服装搭配推荐模型参数的设置如下:用户和服装的特征向量维度为100维,λ1=0.01、λ2=0.01、λ3=0.01,学习率为0.01。如果知识图谱表示学习的嵌入维度不同,那么所实现的推荐效果也不同,针对服装实体嵌入的维度,分别选取了50-300维进行实验,实验结果如图1和图2所示。从图中可以看出,当知识图谱表示学习的嵌入维度为150维的情况下,mae和rmse有所改善,本文提出的推荐方法具有较好的推荐效果。在融合知识图谱表示学习的过程中,待预测上装最相似的近邻个数在选取不同值的时候对推荐效果也会有一定的影响。所以我们选取原始上装搭配下装的近邻个数来观察近邻个数对服装推荐效果的影响,这里设置近邻个数为100-350来进行实验,实验结果如图3和图4所示。从图3和图4中看出,选取不同近邻个数对推荐效果有一定的影响,当下装的近邻个数为200时,mae和rsme的值最小,推荐效果最好。为了验证本文提出的基于知识图谱和矩阵分解模型具有较好的推荐效果,我们将其与矩阵分解算法进行对比分析,这里选取知识图谱表示学习嵌入维度为150,近邻个数为200个,上装和下装的特征向量维度为100维,实验结果如表1所示:表1实验结果对比方法transr-mfmfmae0.62450.6764improve-5.19%rmse0.77520.8165improve-4.13%通过表1可以看出,在相同条件下,本文提出的融合知识图谱和矩阵分解的推荐方法在mae和rmse上是优于矩阵分解算法的。因此考虑下装之间的语义相似度,将相似性潜在因子融入矩阵分解中在一定程度上能提高推荐系统的准确性。选取四组测试上衣服装项进行下装的搭配推荐结果,如图5所示。第一列标注的表示给定上装项的下装搭配,根据服装搭配模型学习与专家给出的搭配下装的相似度,可得到对应下装的候选集。最后标注出来的是由于分类信息的不准确和服装的相似性导致下装匹配的差异性。综合来看,基于矩阵分解和知识图谱的服装搭配方法能产生好的服装搭配推荐结果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1