一种对大型点云数据的索引方法、装置、终端设备和介质与流程
本发明涉及计算机数据结构技术领域,尤其涉及一种对大型点云数据的索引方法、装置、终端设备和介质。
背景技术:
点云数据具有数据量大(海量性)、数据表达精细(高空间分辨率)、空间三维点之间无拓扑关系(散乱性)等特征,在后续的数据处理中需要频繁的进行邻域查找,因此常采用八叉树结构或k-d树数据结构进行数据的组织,以实现对点云数据的索引。
八叉树数据结构是通过对点云数据按正方体不断往下切分为8个子正方体的形式。在计算机内存足够大的情况下,利用八叉树数据结构能够做到对超大型点云数据的索引。但每次索引都需要将点云数据重新读入内存以建立八叉树数据结构,且每次处理的数据不能超过内存上限。当数据到达tb或pb级时,现有商业计算机都无法使用该种方法对数据索引。k-d树是每个节点都为k维点的二叉树。所有非叶子节点可以视做用一个超平面把空间分割成两个半空间。节点左边的子树代表在超平面左边的点,节点右边的子树代表在超平面右边的点。同样地,k-d树需要将点云数据重新读入内存以建立k-d树数据结构。
上述两种方法均是在内存中根据点云数据建立树结构,对计算机内存要求较高。另外,对于超大型点云数据,每次索引都需要将大量点云数据先读入内存建立树结构后才可进行索引,索引效率较低。
技术实现要素:
本发明所要解决的技术问题在于,提供一种对大型点云数据的索引方法、装置、终端设备和介质,能够降低计算机内存的处理压力,提高对大型点云数据的索引效率。
为了解决上述技术问题,本发明提出了一种对大型点云数据的索引方法,包括:
从本地硬盘中读取点云数据;其中,所述点云数据为,将目标文件的空间特征数据结构,以文件名的形式作为索引的入口存储于本地硬盘;
计算所述点云数据的最小包围盒顶点,得到包围盒的最大和最小的x、y、z轴坐标;
根据所述坐标构建文件索引表;
在所述文件索引表中定向提取目标点云数据,其中,所述目标点云数据为:
进一步地,所述将目标文件的空间特征数据结构,以文件名的形式作为索引的入口存储于本地硬盘,包括:
对目标文件进行格式转换并提取原始点云数据集ai(x,y,z);
根据所述原始点云数据ai(x,y,z)生成点云数据集aj(x,y,z);其中,
将所述点云数据集aj(x,y,z)以文件名的形式作为索引的入口存储于本地硬盘。
进一步地,所述格式转换,为将所述目标文件转换为二进制格式文件并执行截尾操作。
本发明还提出了一种对大型点云数据的索引装置,包括:
读取模块,用于从本地硬盘中读取点云数据;其中,所述点云数据为,将目标文件的空间特征数据结构,以文件名的形式作为索引的入口存储于本地硬盘;
计算模块,用于计算所述点云数据的最小包围盒顶点,得到包围盒的最大和最小的x、y、z轴坐标;
构建模块,用于根据所述坐标构建文件索引表;
索引模块,用于在所述文件索引表中定向提取目标点云数据,其中,所述目标点云数据为:
进一步地,所述读取模块,包括:
提取单元,用于对目标文件进行格式转换并提取原始点云数据集ai(x,y,z);
生成单元,用于根据所述原始点云数据ai(x,y,z)生成点云数据集aj(x,y,z);其中,
存储单元,用于将所述点云数据集aj(x,y,z)以文件名的形式作为索引的入口存储于本地硬盘。进一步地,所述格式转换,为将所述目标文件转换为二进制格式文件并执行截尾操作。
本发明还提出了一种对大型点云数据的索引终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述存储器与所述处理器耦接,且所述处理器执行所述计算机程序时实现如权利要求1至3所述的对大型点云数据的索引方法。
本发明还提出了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如权利要求1至3所述的对大型点云数据的索引方法。
实施本发明实施例具有如下有益效果:
本发明实施例通过计算点云数据的包围盒最大和最小坐标,构建索引文件列表,使得通过索引文件列表即可定向提取目标点云数据。同时,将点云数据,即目标文件的空间特征数据结构,以文件名的形式作为索引的入口存储于本地硬盘,能够有效降低计算机内存的处理压力,提高对大型点云数据的索引效率。
附图说明
图1为本发明第一实施例中的一种对大型点云数据的索引方法的流程示意图;
图2为本发明第一实施例中的一优选的实施例的流程示意图;
图3为本发明第二实施例中的一种对大型点云数据的索引装置的结构示意图。
具体实施方式
下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,文中的步骤编号,仅为了方便具体实施例的解释,不作为限定步骤执行先后顺序的作用。本实施例提供的方法可以由相关的服务器执行,且下文均以服务器作为执行主体为例进行说明。
第一实施例。请参阅图1-2。
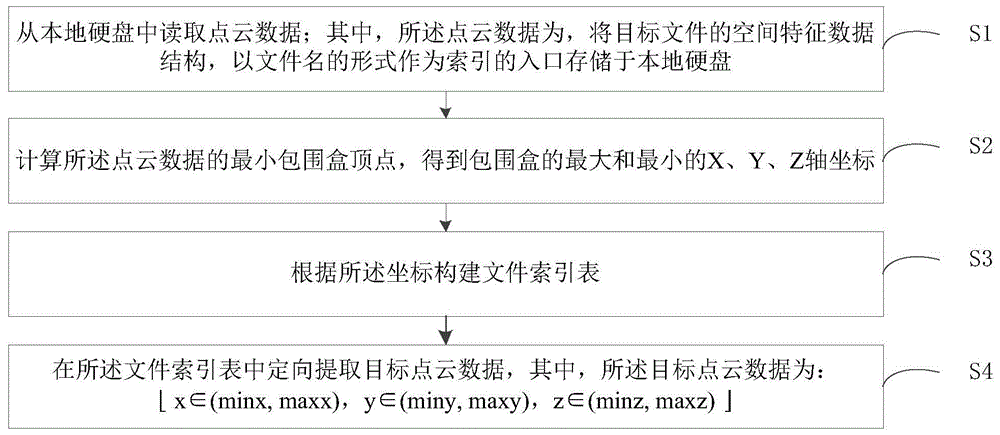
如图1所示,第一实施例提供的一种对大型点云数据的索引方法,包括步骤s1~s4:
s1、从本地硬盘中读取点云数据;其中,所述点云数据为,将目标文件的空间特征数据结构,以文件名的形式作为索引的入口存储于本地硬盘。
s2、计算所述点云数据的最小包围盒顶点,得到包围盒的最大和最小的x、y、z轴坐标。
s3、根据所述坐标构建文件索引表。
s4、在所述文件索引表中定向提取目标点云数据,其中,所述目标点云数据为:
可以理解的是,当点云数据的数据量巨大时,将点云数据,即目标文件的空间特征数据结构以文件名的形式作为索引入口存储于本地硬盘,可以直接从本地硬盘中读取点云数据以进行后续的数据处理,无需通过计算机内存进行数据处理,能够有效降低计算机内存的处理压力,提高对大型点云数据的索引效率。
在具体的实施例当中,通过计算所述点云数据的最小包围盒顶点,得到包围盒的最大和最小的x、y、z轴坐标。
需要说明的是,所述包围盒的最大和最小坐标,为:(maxx,maxy,maxz)、(maxx,miny,maxz)、(maxx,maxy,minz)、(minx,maxy,maxz)、(minx,maxy,minz)、(minx,miny,maxz)、(minx,miny,maxz)和(minx,miny,minz)。
在具体的实施例当中,所述包围盒的包围区域可通过改变所述包围盒的三维坐标进行自定义调整。
可以理解的是,根据所述包围盒的最大和最小坐标构建的文件索引表,仅包括处于所述包围盒包围区域内的所述点云数据。当点云数据的数据量巨大时,可根据所要提取的目标点云数据,改变包围盒的三维坐标以缩小包围盒的包围区域,从而加快索引进程,提高对大型点云数据的索引效率。
如图2所示,在一优选的实施例当中,在所述步骤s1之前,包括步骤s01~s03:
s01、对目标文件进行格式转换并提取原始点云数据集ai(x,y,z)。
s02、根据所述原始点云数据ai(x,y,z)生成所述点云数据集aj(x,y,z);其中,
s03、将所述点云数据集aj(x,y,z)以文件名的形式作为索引的入口存储于本地硬盘。
在具体的实施例当中,所述格式转换,为将所述目标文件转换为二进制格式文件并执行截尾操作。
可以理解的是,通过将所述目标文件转化为二进制格式文件并执行截尾操作,避免目标文件中的单个数据被切断,从而确保准确提取所述目标文件中的所有所述原始点云数据,即所述原始点云数据集。同时,通过对所有所述原始点云数据的三维坐标值分别进行向下取整,对应生成所有所述点云数据,即所述点云数据集,能够对提取的所有所述原始点云数据均做保留,保证了原始点云数据的完整性。
在具体的实施例当中,可通过改变向下取整的取整参数调整所述原始点云数据的保留范围。
本实施例中默认的切分子数据边长大小为1,该参数可以进行改变以替换向下取整函数。例如,可设置边长大小为2。
实施本发明实施例具有如下有益效果:
本发明实施例通过计算原始点云数据的包围盒最大和最小坐标,构建索引文件列表,使得通过索引文件列表即可定向提取目标点云数据。同时,将原始点云数据,即目标文件的空间特征数据结构,以文件名的形式作为索引的入口存储于本地硬盘,能够有效降低计算机内存的处理压力,提高对大型点云数据的索引效率。
第二实施例。请参阅图3。
如图3所示,第二实施例提供的一种对大型点云数据的索引装置,包括:读取模块21,用于从本地硬盘中读取点云数据;其中,所述点云数据为,将目标文件的空间特征数据结构,以文件名的形式作为索引的入口存储于本地硬盘;计算模块22,用于计算所述点云数据的最小包围盒顶点,得到包围盒的最大和最小的x、y、z轴坐标;构建模块23,用于根据所述坐标构建文件索引表;索引模块24,用于在所述文件索引表中定向提取目标点云数据,其中,所述目标点云数据为:
可以理解的是,当点云数据的数据量巨大时,将点云数据,即目标文件的空间特征数据结构以文件名的形式作为索引入口存储于本地硬盘,可以直接从本地硬盘中读取点云数据以进行后续的数据处理,无需通过计算机内存进行数据处理,能够有效降低计算机内存的处理压力,提高对大型点云数据的索引效率。
在具体的实施例当中,通过计算所述点云数据的最小包围盒顶点,得到包围盒的最大和最小的x、y、z轴坐标。
需要说明的是,所述包围盒的最大和最小坐标,为:(maxx,maxy,maxz)、(maxx,miny,maxz)、(maxx,maxy,minz)、(minx,maxy,maxz)、(minx,maxy,minz)、(minx,miny,maxz)、(minx,miny,maxz)和(minx,miny,minz)。
在具体的实施例当中,所述包围盒的包围区域可通过改变所述包围盒的三维坐标进行自定义调整。
可以理解的是,根据所述包围盒的最大和最小坐标构建的文件索引表,仅包括处于所述包围盒包围区域内的所述点云数据。当点云数据的数据量巨大时,可根据所要提取的目标点云数据,改变包围盒的三维坐标以缩小包围盒的包围区域,从而加快索引进程,提高对大型点云数据的索引效率。
在具体的实施例当中,所述读取模块21,包括:提取单元211,用于对目标文件进行格式转换并提取原始点云数据集ai(x,y,z);生成单元212,用于根据所述原始点云数据ai(x,y,z)生成所述点云数据集aj(x,y,z);其中,
在具体的实施例当中,所述格式转换,为将所述目标文件转换为二进制格式文件并执行截尾操作。
可以理解的是,通过提取单元211将所述目标文件转化为二进制格式文件并执行截尾操作,避免目标文件中的单个数据被切断,从而确保准确提取所述目标文件中的所有所述原始点云数据,即所述原始点云数据集。同时,通过生成单元212对所有所述原始点云数据的三维坐标值分别进行向下取整,对应生成所有所述点云数据,即所述点云数据集,能够对提取的所有所述原始点云数据均做保留,保证了原始点云数据的完整性。
在具体的实施例当中,可通过改变向下取整的取整参数调整所述原始点云数据的保留范围。
本实施例中默认的切分子数据边长大小为1,该参数可以进行改变以替换向下取整函数。例如,可设置边长大小为2。
实施本发明实施例具有如下有益效果:
本发明实施例通过计算原始点云数据的包围盒最大和最小坐标,构建索引文件列表,使得通过索引文件列表即可定向提取目标点云数据。同时,将原始点云数据,即目标文件的空间特征数据结构,以文件名的形式作为索引的入口存储于本地硬盘,能够有效降低计算机内存的处理压力,提高对大型点云数据的索引效率。
第三实施例。
第三实施例提供的一种对大型点云数据的索引终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述存储器与所述处理器耦接,且所述处理器执行所述计算机程序时实现如上所述的对大型点云数据的索引方法,并具有与上述方法相同的有益效果。
第四实施例。
第四实施例提供的一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如上所述的对大型点云数据的索引方法,并具有与上述方法相同的有益效果。
综上所述,实施本发明实施例,能够在本地硬盘对大型点云数据进行索引,实现有效降低计算机内存的处理压力,提高对大型点云数据的索引效率。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
本领域普通技术人员可以理解实现上述实施例中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)或随机存储记忆体(randomaccessmemory,ram)等。
- 还没有人留言评论。精彩留言会获得点赞!