基于关键词提取的实体名消岐方法与流程
本发明涉及自然语言处理领域。更具体地说,本发明涉及一种基于关键词提取的实体名消岐方法。
背景技术:
命名实体消歧是自然语言处理技术的一项基础性研究,在语义标注、在线推荐系统、互联网搜索引擎等应用中具有重要的实用价值,因此对命名实体消歧方法研究具有重要意义。
命名实体歧义是指对于给定的命名实体指称具有多个含义。一个命名实体指向多个实体时,根据背景文本为其选择正确的语义实体就是命名实体消歧的主要内容。导致命名实体歧义主要包括命名实体的多样性和歧义性两方面原因。实体指称多样性指一个命名实体有多种表达方式,包括同义词和简称等情况;实体指称歧义性指一个命名实体可能表示不同的实体语义。
消歧的工作就是为一个命名实体在多个语义下选择一个正确的语义实体。基于上下文实体信息在指称多样性和指称歧义性两方面进行消歧。
现有的消岐技术有针对性略缩词的也有针对实体多音字的,但是将原始文本进行处理得到初步实体名然后和关键词进行相似性计算来消岐的案例基本没有。
技术实现要素:
本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。
本发明还有一个目的是提供一种基于关键词提取的实体名消岐方法,其鲁棒性较强,能够适应不同长度、不同格式的文本,在多个信息来源下均有比较好的表现;具有较强的可解释性,各个步骤的结果可见。而且可以对负面词典进行管理以进行针对不同领域的精细化处理;具有更高的精确性,考虑负面词及词的词性信息,并且通过关键词对比的方法确保所识别的实体在文本的表达中占据主要地位。
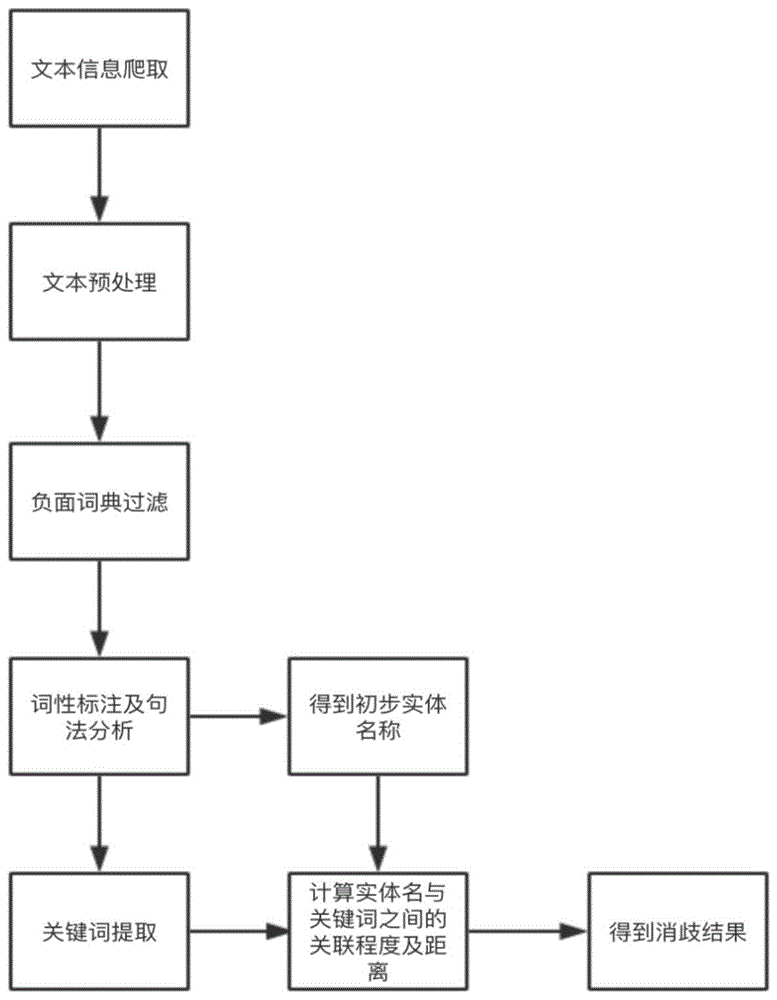
为了实现根据本发明的这些目的和其它优点,提供了一种基于关键词提取的实体名消岐方法,包括:
准备步骤、以固有监测实体名单中的实体名为基准,从互联网上利用爬虫程序爬取带有实体名或者与实体名相关的未消岐的信息文本作为原始文本;
步骤二、根据负面词词典将步骤一得到文本向量进行分词过滤,得到分词过滤后的语句;
步骤三、通过hmm隐马尔科夫模型对步骤二得到的语句中的每个词进行词性标注,得到原始文本的初步实体名;
步骤四、提取步骤三得到的词性标注后的语句的关键词;
步骤五、计算步骤三得到的实体名与关键词之间的相似性;
步骤六、根据步骤五得到的相似性结果得到原始文本与实体的消岐识别结果。
优选的是,步骤一中,中文停用词表通过网络上的开源网站获得。
优选的是,步骤二中,负面词词典包括:否定词、实体名所在领域的负面性名词与实体名所在领域的负面性动词。
优选的是,步骤四中,关键词的提取采用text-rank、tf-idf、ske、word2vec+kmeans或基于lda的关键词提取方法中的一种进行。
优选的是,hmm隐马尔科夫模型进行词性标注的具体过程为:
将步骤二得到的语句作为观测序列,经过hmm隐马尔科夫模型进行词性标注后的序列为观测序列;
观测序列到隐藏序列是通过viterbi算法,利用语料统计得到的起始概率、发射概率和转移概率来得到的,得到隐藏序列后即完成了词性标注过程。
优选的是,步骤四种使用text-rank、tf-idf、ske、word2vec+kmeans和基于lda的关键词提取手段进行原始文本的关键词提取。
优选的是,步骤四中,文本的命名实体与提取出的关键词的相似性计算是通过wordembedding得到的词向量进行计算的。
本发明至少包括以下有益效果:
第一、鲁棒性较强,能够适应不同长度、不同格式的文本,在多个信息来源下均有比较好的表现;
第二、具有较强的可解释性,各个步骤的结果可见。而且可以对负面词典进行管理以进行针对不同领域的精细化处理;
第三、具有更高的精确性,考虑负面词及词的词性信息,并且通过关键词对比的方法确保所识别的实体在文本的表达中占据主要地位。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
图1为本发明基于关键词提取的实体名消岐方法的原理图;
图2为本发明基于关键词提取的实体名消岐方法的流程图。
具体实施方式
下面结合实施例对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
具体步骤根据附图1~2所示,并进行举例说明:
以下证券交易为背景进行举例说明;
在准备步骤中,首先根据固有监测实体名单中的实体名为基准,从互联网上利用爬虫程序爬取带有实体名或者与实体名相关的未消岐的信息文本作为原始文本;
其中,所述固有监测实体名名单为人为给出的,例如,以实体名“热钱”为例,其具有多种意思,热的钱币,刚到手的货币,刚到手的资金,游资或投机性短期资本;其中,使用者想在互联网上搜索关于“热钱”的文本信息,得到一系列原始文本,这些文本中的“热钱”具有多种可解释的含义,但是使用者所需要的本文中“热钱”的意思为游资或投机性短期资本,因此,其他文本中若“热钱”为其他意思,便成为歧义,为了得到更好的阅读体验因此需要进行文本的消岐处理,以满足使用者的需求;
步骤一、对原始文本去除非文字部分,采用中文停用词表去除无效连接词,得到待向量化文本;采用适应n=2的n-gram方法将待向量化文本进行向量化处理,得文本向量;
搜索得到的原始文本的格式不定,长度不同;先对原始文本进行基本过滤,去除原始文本中的非文字部分,这里的非文字部分包括标点符号、特殊标记、公式、数字;
其中,所述中文词停用表来自以下开源网站中的其中一个,包括:https://github.com/fxsjy/jieba、https://github.com/uk9921/stopwords;此处只是举例,但是不限于上述的两个停用词表,符合该类的停用词表皆在保护范围内;
采用n=2的n-gram方法将上述删除过非文字部分和无效连接词的文本进行向量化处理;
步骤二、根据负面词词典将步骤一得到文本向量进行分词过滤,得到分词过滤后的语句;其中,选用一批负面词词典,例如,对于判断的否定,如果负面词距离,此处负面词指否定词,与实体距离很近,则很有可能会产生语义上的偏差,无法直接使用。所以需要将这一部分文本过滤掉,从而保证模型的准确率;其中,负面词词典为专业人员事先根据使用者需要进行人工总结得到,所述负面词词典中的词可以分为三类,包括常见的否定词(否、非、不、相反)、专业名词(以证券交易系统为背景举例,例如一级市场、二级市场、开盘价、收盘价、最高价、最低价、市盈率、换手率等)、专业负面动词(以证券交易系统为背景举例,例如诈骗、跑路、暴雷);
其中,所述负面词与所述实体的距离的计算是指欧式距离,n维空间下的欧式距离是两个点在各维上差值的平方和的算数平方根,具体公式为:
这里的实体是指监测实体名单中的实体名;得到距离值后根据本身的模型参数进行对比来判断是否应该进行过滤;这里的模型参数是根据多次文本消岐结果进行不断调整得到的;
步骤三、通过hmm隐马尔科夫模型对步骤二得到的语句中的每个词进行词性标注,分析,得到原始文本的初步实体名;
在hmm隐马尔科夫模型中观测序列即为分词后的语句,隐藏序列即为经过标注后的词性标注序列;
其中,观测序列到隐藏序列是通过viterbi算法进行计算得到的,计算过程中采用的起始概率、发射概率和转移概率是通过大量的语料统计得到的;
通过语料统计得计算概率的具体步骤如下:
1、得到语料库中词性标注种类和个数,进而得到隐藏序列;
2、对输入的句子进行分词得到观测序列;
3、对每个词性标注,计算该词性出现时的前一个词性的次数/该词性出现的总次数得到转移概率矩阵;
4、对每个观测状态,计算该状态不同词性出现的次数/该观测状态出现的总次数得到发射概率矩阵;
5、计算各词性初始概率:
hmm模型参数:两个状态集合,三个概率矩阵;
两个状态:隐含状态s,可见状态o;
三个矩阵:起始概率矩阵,隐含状态转移概率(前一时刻是s1,后一时刻是s2的概率),输出转移概率(当前时刻状态是s1,输出为o1的概率)。
hmm参数是(π,a,b),π是初始概率矩阵,a是隐含状态转移矩阵,b是某个时刻由隐藏状态到可见状态的发射概率矩阵;
再通过viterbi算法得到最优解。
步骤四、提取步骤二中进行分词过滤后的文本的关键词;
提取关键词的方法可以为text-rank、tf-idf、ske、word2vec+kmeans或基于lda的关键词提取方法中的一种进行;
此处具体使用text-rank进行文本的关键词自动提取;其中,text-rank认为文档或句子中相邻的词语重要性是相互影响的,所以text-rank引入了词语的顺序信息。
步骤五、计算实体名与关键词之间的相似性,具体为实体名和关键词之间的关联程度和距离;
其中,实体名的个数为多个,关键词的个数也为多个,计算初步实体名称和关键词的相似性确定文本所表达的主题是否和命名实体相关,从而进一步增强识别的准确性;
初步实体名称和关键词之间的距离的计算与上述的负面词与所述实体的距离的计算相同,为欧式距离的计算;
欧式距离,n维空间下的欧式距离是两个点在各维上差值的平方和的算数平方根,具体公式为:
其中,初步实体名称和关键词的相似性是通过wordembedding得到的词向量进行计算得到的;
步骤六、根据步骤五得到的相似性结果得到原始文本与实体的识别结果。
具体实例为:
步骤一:
起始状态:未消歧的信息原始文本如实体a标签(例如,国光电器),未消歧的信息原始文本如实体a标签下找到文本a(国光公司与美迪电器产生市场贸易纠纷)、b(在中国光电器品类的数量发生了翻天覆地的变化)、c(国家大力扶持新能源光电器材的发展);
处理手段为:将文本a、b、c进行非文字部分的过滤和无效连接词的删除过滤;
同终结状态:得到文本a’(国光公司美迪电器产生市场贸易纠纷)、b’(中国光电器品类数量发生翻天覆地变化)、c’(国家大力扶持新能源光电器材发展);
步骤二:
起始状态:上一步骤的终结状态;
进行的操作为:将文本a’(国光公司美迪电器产生市场贸易纠纷)、b’(中国光电器品类数量发生翻天覆地变化)、c’(国家大力扶持新能源光电器材发展)进行负面词过滤,主要通过n维空间下的欧式距离公式进行计算;
终结状态:分词并过滤负面词后的文本a’、b’,其中c’由于不符合距离参数,即实体名之间距离过长,判定为不合要求的文本,因此被过滤掉了;
步骤三:
起始状态:上一步的终结状态;
进行的操作为:采用hmm模型参数进行词性标注;
终结状态:文本a’、b’的词性标注结果,a’(国光公司(n)美迪电器(n)产生(v)市场(n)贸易(n/v)纠纷(n/v)),b’(中国(n)光电器(n)品类(n)数量(n)发生(v)翻天覆地(a)变化(n/v));
步骤四:
初始状态(输入):步骤二获得的文本a’、b’,以及步骤三的词性标注结果,a’(国光公司(n)美迪电器(n)产生(v)市场(n)贸易(n/v)纠纷(n/v)),b’(中国(n)光电器(n)品类(n)数量(n)发生(v)翻天覆地(a)变化(n/v));
进行的操作为:采用text-rank进行文本的关键词自动提取;
终结状态(输出):文本a’、b’的关键词组[a1,a2,a3…][b1,b2,b3…];即[国光公司,美迪电器,市场,贸易,纠纷],[中国,光电器,数量,变化];
步骤五:
初始状态(输入):文本a、b的关键词组[a1,a2,a3…][b1,b2,b3…],即[国光公司,美迪电器,市场,贸易,纠纷],[中国,光电器,数量,变化]和实体名a[国光电器];
进行的操作为:计算实体名与关键词组的相似度(文本距离均较近,因此忽略不作计算,仅以相似度作为评判指标);
终结状态(输出):实体名a和关键词组[a1,a2,a3…][b1,b2,b3…]的相似度分别为0.7和0.4;
步骤六:
经过比较得只有关键词组[a1,a2,a3…]即[国光公司,美迪电器,市场,贸易,纠纷]和实体a[国光电器]相关度较高,所以只保留对应的原始文本a作为实体a的相关文本,其他两条b、c被过滤。
以上实例仅是简述本发明技术方案的实施流程,实际上在实际运用中,处理的文本的条数和文本长度的量均为海量级别,因此在对文本进行快速高效的处理的前提下,也必须保证有一定的准确率,本发明通过对海量文本进行分析过滤和负面词过滤,根据使用者定义的负面词词典能够有效的对文本进行专业化区分,提高文本的专业性,使得到的信息能够限定在具有较专业水平的范围内,使得得到的结果可信度更高,通过采用hmm模型参数进行词性标注,得到文本的初步的实体名,采用text-rank对得到的初步的多个实体名进行关键词提取,将得到的关键词与进行搜索的实体进行相似度计算,得到最终的消岐结果,该技术方案具有较强的可解释性,各个步骤的结果可见,能够解决现有的海量文本消岐分析工作,使得信息的搜索精度能够进一步提高。
根据得到的相似性的数值对原始文本与实体的相似性进行排序,根据使用者的需要排除相似性最低的,得到命名实体识别结果。尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的实施例。
- 还没有人留言评论。精彩留言会获得点赞!