答题卡字符串识别方法、装置、终端和计算机存储介质与流程
本发明涉及图像处理领域,具体而言,涉及一种答题卡字符串识别方法、一种答题卡字符串识别装置、一种终端和一种计算机可读存储介质。
背景技术:
随着计算机和人工智能的高速发展,其逐渐应用到工作和生活的多个领域。在教育教学过程中,考试是对教学成果的一种有效的评价方式,一个考试完成后教师会对大量的学生试卷进行批阅并对批阅后的所有的学生情况进行汇总分析,传统阅卷和分析工作会占用教师大量的时间,甚至压缩的教师的备课时间,所以出现了计算机智能阅卷的相关技术,通过这种阅卷方式能够大大节省教师的阅卷时间。目前现有的阅卷系统仅能够对自身系统定义的答题卡板式进行制模(制作答题卡模板)和阅卷,而无法兼容其他厂商的答题卡,如需使用第三方试卷答题卡进行考试时,原答题卡无法使用,则需要使用繁琐的操作重新制作答题卡,重新印刷答题卡也增加了成本。现有的网阅系统虽然能够支撑第三方卷卡的批阅,但是不能支持第三方卷卡的手批。另外,现有技术中的阅卷系统不能支持对教师手批试卷进行统分。像高考、中考、大型联考及期中期末考试一般会采用网络阅卷的方式,而大型考试毕竟在所有考试中占少数,学生教学过程中存在更多的日常考试、测验或测试,在日常的考试场景中,教师使用手写分数进行判分的方式比较常见,导致现有技术中网络阅卷系统的广泛应用受到一定限制。
目前对答题卡考号(或特定字符串)进行识别,主要还是采用基于传统图像处理的模式,现有方法主要有以下几方面的缺陷:
1、当通过条码或二维码识别,获取考生信息,现有的识别方法主要识别固定位置且清晰度较高的二维码。如果二维码模糊、定位点被覆盖或周围有笔画干扰时,则较难识别;
2、依据识别定位点判断考号位置的方式效率低下且易受到噪声干扰,影响识别准确性。当前各教育科技类公司普遍采用图像处理及模式识别方法进行答题卡识别,并开发出了许多答题卡识别系统,但依旧采用传统的识别方法,无法从根本上突破图像处理方法的瓶颈,只能做到自动化处理而无法实现完全的智能化识别;
3、考号识别通过填涂考号数字区域,在通过定位块来确定对应的数字,在不同的区域不同的学校考号位数不一样,这样会导致答题卡制作不通用。
另外,整个说明书对背景技术的任何讨论,并不代表该背景技术一定是所属领域技术人员所知晓的现有技术,整个说明书中的对现有技术的任何讨论并不代表该现有技术一定是广泛公知的或一定构成本领域的公知常识。
技术实现要素:
本发明旨在至少解决现有技术或相关技术中存在的技术问题之一。
为此,本发明的一个目的在于提出了一种答题卡字符串识别方法。
本发明的另一个目的在于提出了一种答题卡字符串识别装置。
本发明的又一个目的在于提出了一种终端。
本发明的又一个目的在于提出了一种计算机可读存储介质。
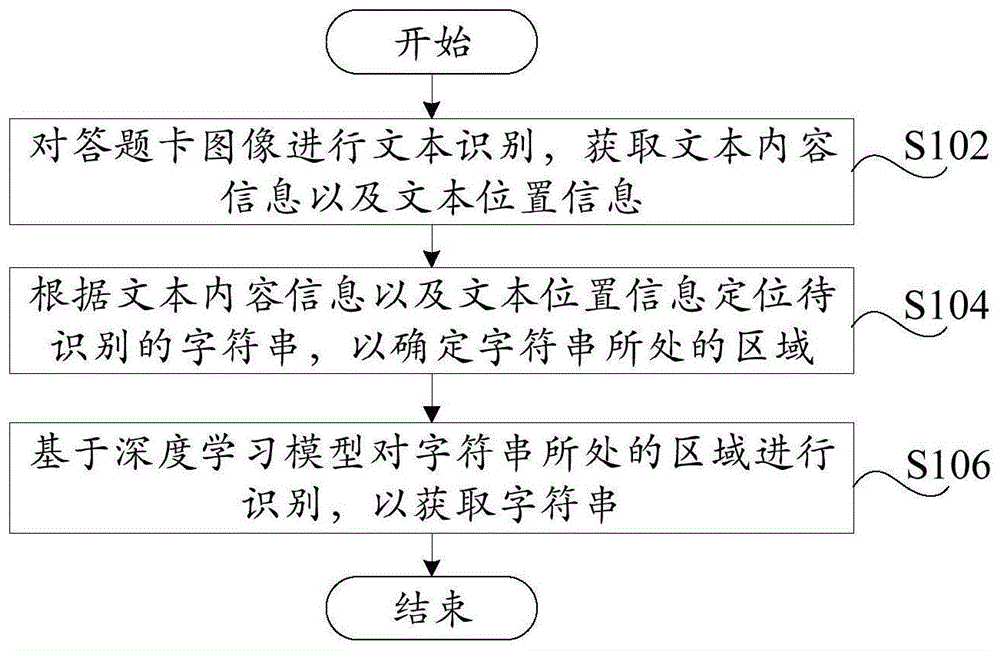
在本发明的第一方面的技术方案中,提出了一种答题卡字符串识别方法,包括:对答题卡图像进行文本识别,获取文本内容信息以及文本位置信息;根据文本内容信息以及文本位置信息定位待识别的字符串,以确定字符串所处的区域;基于深度学习模型对字符串所处的区域进行识别,以获取字符串。
在该技术方案中,依靠文本识别技术,在获取文本内容的同时记录文本位置信息,该位置信息被用于定位待识别的字符串,一旦确定了待识别的字符串(目标字符串)的位置区域,就能够进一步处理该区域的图像对该区域进行定向识别,即根据字符串的特点建立比较高效的深度学习模型进行字符串的精确识别,对于手写字符串以及答题卡中存在较多干扰笔画的情况,也能够保持较高的识别率。例如,目标字符串的特点为手写的数字,则建立数字识别模型并利用手写数字图片进行训练,从而对手写数字串达到精确识别。
其中,深度学习模型的本质是一种基于深度学习算法的目标识别模型,用于对字符串所在的区域进行信息提取。例如,本申请的一个目标是对答题卡图像中的字符串进行识别,那么深度学习模型就是一种基于深度学习算法的字符串识别模型,若字符串中只包含数字,那么该深度学习模型即为基于深度学习算法的数字识别模型。
深度学习模型能够学习样本数据(训练集)的内在规律和表示层次,在学习过程中获得的信息对字符、图像和声音等数据的解释有很大帮助,最终目标是让机器具备一定的分析学习能力,从而能够识别字符、图像和声音等数据。
在该技术方案中能够实现字符串(数字)识别的深度学习模型包括:densenet(全称“denselyconnectedconvolutionalnetworks”,密集连接卷积网络),densenet是一种具有密集连接的卷积神经网络,在该网络中,任何两层之间都有直接的连接,也即网络每一层的输入都是前面所有层输出的并集,该层所学习的特征图也会被直接传给其后所有的层,作为输入。
此外,深度学习模型也可以使用类似的cnn模型搭建,比如resnet、googlenet、vgg-nets、alexnet、lenet等。其中,cnn(convolutionalneuralnetworks,卷积神经网络),resnet(残差网络),googlenet(是christianszegedy提出的一种深度学习结构),vgg(全称vggnet,是牛津大学计算机视觉组和googledeepmind公司一起研发的深度卷积神经网络),alexnet(是由hinton和alexkrizhenvsky提出的一种神经网络),lenet(是由yanlecun提出的一种用于手写字符识别与分类的神经网络)。
随着计算机处理能力的提升、识别算法的改进以及神经网络模型的完善,文本识别技术(例如,opticalcharacterrecognition,光学字符识别)也随之进步,能够准确获取图像中的文本的位置信息,进一步提升识别率。
现有技术中的答题卡特定字符串识别方法,通常对答题卡有特殊要求,如答题卡必须为含铅铜版纸进行彩色印刷,且对答题卡裁切精度有严格要求,这样经济成本、环境成本高,而且受限于光电头安装位置和排列密度相对固定,对于不同格式的答题卡调整难度很大。而基于本申请的技术方案,通过文本识别方法确定目标字符串的所在区域,不需要答题卡具有特定的格式,不需要定位块,面对答题卡排版改变,答题卡纸张大小改变,答题卡中存在涂写干扰等情况,都不会对其区域确定产生影响,使其识别效率有了较大地提升。
另外,根据本发明上述实施例的答题卡字符串识别方法,还可以具有如下附加的技术特征:
在上述任一技术方案中,可选地,根据文本内容信息以及文本位置信息定位待识别的字符串,以确定字符串所处的区域,具体包括:利用文本模版与文本内容信息进行匹配,根据匹配到的文本内容信息所对应的文本位置信息确定字符串所处的区域的坐标。
在该技术方案中,文本模版与字符串具有逻辑上的对应关系,例如,待识别的字符串为考号数字串,在考号填写处存在“考号”等提示性文字,那么可以选用“考号”作为文本模版,若待识别的字符串为身份证号数字串,则在身份证号填写处必然会出现“身份证号”等提示性标注,那么可以选用“身份证号”作为文本模版。利用文本模版与识别到的文本内容进行匹配,就能够定位字符串在答题卡图像中的位置。由于文本识别的过程已经获取了文本的位置信息(坐标),则字符串的位置信息也随之确定。
在上述任一技术方案中,可选地,基于深度学习模型对字符串所处的区域进行识别,以获取字符串,具体包括:根据字符串所处的区域的坐标,在已填涂的答题卡的图像中截取相应的区域图像;对区域图像进行水平投影和垂直投影,根据投影结果确定字符串中字符的坐标;根据字符的坐标,在区域图像中截取相应的字符图像;根据基于深度学习的识别模型,识别字符图像;合并识别结果以获取字符串。
在该技术方案中,基于已确定的字符串所在区域,采用投影法对字符串中的每个字符进行精确定位,以提高字符识别准确率。具体地,水平投影和垂直投影是指,在该水平方向或者垂直方向取一条直线,统计垂直于该直线(轴)方向上的像素黑点的数量,累加求和作为该轴该位置的值。可以先进行垂直投影再进行水平投影,或者先进行水平投影再进行垂直投影,结合水平投影和垂直投影能够确定字符的各个边界的坐标,即使答题卡排版改变,都不会对其区域确定产生影响,使其识别效率有了较大提升。定位到每个字符之后,基于深度学习的识别模型针对每个字符进行识别,有助于提高识别准确度。
在上述任一技术方案中,可选地,对区域图像进行水平投影和垂直投影,根据投影结果确定字符串中字符的坐标,具体包括:对区域图像进行二值化处理,得到二值图;对二值图进行水平投影和垂直投影,生成水平投影数据和垂直投影数据;根据水平投影数据确定限制字符填写位置的框线在水平方向上的坐标区域,根据垂直投影数据确定限制字符填写位置的框线在垂直方向上的坐标区域,水平方向的坐标区域对应于框线的上边界和下边界,垂直方向的坐标区域对应于框线的左边界和右边界;根据上边界、下边界、左边界和右边界确定框线的坐标,其中,水平投影用于计算二值图在水平方向上的像素点个数,垂直投影用于计算二值图在垂直方向上的像素点个数,框线的坐标即字符的坐标,用于表示字符所处的位置。
在该技术方案中,为限制字符(字符串)的填写位置,字符周围存在文本框,针对字符周围的框线进行投影识别,进而确定每个字符的文本框。对于形式多样,排版不确定的各种答题卡,其一般都含有用于规定填写位置的框线(文本框),针对这些框线进行投影识别,不需要答题卡具有定位块,不需要使用特定纸质进行制作,并且能保证较高的识别准确度。
在上述任一技术方案中,可选地,还包括:根据框线的坐标在二值图中截取框线区域图像;确定框线区域图像中不含有字符,则删除区域图像。
在该技术方案中,删除不含有字符的区域,降低深度学习模型的运算量,能够提高运算速度。
在上述任一技术方案中,可选地,对答题卡图像进行文本识别,获取文本内容信息以及文本位置信息,具体包括:根据光学字符识别模型识别答题卡图像,获取空白答题卡的文本内容信息以及文本位置信息。
在该技术方案中,光学字符识别模型,即ocr(opticalcharacterrecognition,光学字符识别),ocr是指电子设备检查纸上打印的字符,通过检测暗亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。随着计算机处理能力的提升、识别算法的改进以及神经网络模型的完善,光学字符识别模型也会随之进步,能够准确获取图像中的文本的位置信息。
在上述任一技术方案中,可选地,字符串包括考号,深度学习模型包括数字识别模型。
在本发明的第二方面的技术方案中,提出了一种答题卡字符串识别装置,包括:存储器、处理器及存储在存储器上并可在处理器上运行的程序,程序被处理器执行时实现如上述任一项技术方案的答题卡字符串识别方法的步骤。该答题卡字符串识别装置包括如上述任一项技术方案的答题卡字符串识别方法的全部有益效果,在此不再赘述。
在本发明的第三方面的技术方案中,提出了一种终端,包括:上述第二方面技术方案所述的答题卡字符串识别装置。该终端包括如上述任一项技术方案的答题卡字符串识别方法的全部有益效果,在此不再赘述。
在本发明的第四方面的技术方案中,提出了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被执行时,实现如上述任一项技术方案所述的答题卡字符串识别方法的步骤。
本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1示出了根据本发明的一个实施例的答题卡字符串识别方法的流程示意图;
图2示出了根据本发明的另一个实施例的答题卡字符串识别方法的流程示意图;
图3示出了根据本发明的一个实施例的答题卡字符串识别方法的考号区域分析结果示意图;
图4示出了根据本发明的一个实施例的答题卡字符串识别方法的二值图示意图;
图5示出了根据本发明的一个实施例的答题卡字符串识别方法的水平投影结果示意图;
图6示出了根据本发明的一个实施例的答题卡字符串识别方法的简化水平投影示意图;
图7示出了根据本发明的一个实施例的答题卡字符串识别方法的边界检测结果示意图;
图8示出了根据本发明的一个实施例的答题卡字符串识别方法的垂直投影结果示意图;
图9示出了根据本发明的一个实施例的答题卡字符串识别方法的简化垂直投影示意图;
图10示出了根据本发明的一个实施例的答题卡字符串识别方法的空白答题卡示意图;
图11示出了根据本发明的一个实施例的答题卡字符串识别方法的文本框识别结果示意图;
图12示出了根据本发明的一个实施例的答题卡字符串识别装置的示意框图;
图13示出了根据本发明的一个实施例的终端示意框图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
实施例一
如图1所示,根据本发明的一个实施例的答题卡字符串识别方法,包括:步骤s102,对答题卡图像进行文本识别,获取文本内容信息以及文本位置信息;步骤s104,根据文本内容信息以及文本位置信息定位待识别的字符串,以确定字符串所处的区域;步骤s106,基于深度学习模型对字符串所处的区域进行识别,以获取字符串。
在该实施例中,依靠文本识别技术,在获取文本内容的同时记录文本位置信息,该位置信息被用于定位待识别的字符串,一旦确定了待识别的字符串(目标字符串)的位置区域,就能够进一步处理该区域的图像对该区域进行定向识别(例如,目标字符串的特点为手写的数字,则建立数字识别模型并利用手写数字图片进行训练,从而对手写数字串达到精确识别。)即根据字符串的特点建立比较高效的深度学习模型进行字符串的精确识别,对于手写字符串以及答题卡中存在较多干扰笔画的情况,也能够保持较高的识别率。随着计算机处理能力的提升、识别算法的改进以及神经网络模型的完善,文本识别技术(例如,opticalcharacterrecognition,光学字符识别)也随之进步,能够准确获取图像中的文本的位置信息,进一步提升识别率。现有技术中的答题卡特定字符串识别方法,通常对答题卡有特殊要求,如答题卡必须为含铅铜版纸进行彩色印刷,且对答题卡裁切精度有严格要求,这样经济成本、环境成本高,而且受限于光电头安装位置和排列密度相对固定,对于不同格式的答题卡调整难度很大。而基于本申请的技术方案,通过文本识别方法确定目标字符串的所在区域,不需要答题卡具有特定的格式,不需要定位块,面对答题卡排版改变,答题卡纸张大小改变,答题卡中存在涂写干扰等情况,都不会对其区域确定产生影响,使其识别效率有了较大地提升。
根据上述实施例的答题卡字符串识别方法,可选地,步骤104具体包括:利用文本模版与文本内容信息进行匹配,根据匹配到的文本内容信息所对应的文本位置信息确定字符串所处的区域的坐标。
在该实施例中,文本模版与字符串具有逻辑上的对应关系,例如,待识别的字符串为考号数字串,在考号填写处存在“考号”等提示性文字,那么可以选用“考号”作为文本模版,若待识别的字符串为身份证号数字串,则在身份证号填写处必然会出现“身份证号”等提示性标注,那么可以选用“身份证号”作为文本模版。利用文本模版与识别到的文本内容进行匹配,就能够定位字符串在答题卡图像中的位置。由于文本识别的过程已经获取了文本的位置信息(坐标),则字符串的位置信息也随之确定。
根据上述任一个实施例的答题卡字符串识别方法,可选地,步骤106具体包括:根据字符串所处的区域的坐标,在已填涂的答题卡的图像中截取相应的区域图像;对区域图像进行水平投影和垂直投影,根据投影结果确定字符串中字符的坐标;根据字符的坐标,在区域图像中截取相应的字符图像;根据基于深度学习的识别模型,识别字符图像;合并识别结果以获取字符串。
在该实施例中,基于已确定的字符串所在区域,采用投影法对字符串中的每个字符进行精确定位,以提高字符识别准确率。具体地,水平投影和垂直投影是指,在该水平方向或者垂直方向取一条直线,统计垂直于该直线(轴)方向上的像素黑点的数量,累加求和作为该轴该位置的值。可以先进行垂直投影再进行水平投影,或者先进行水平投影再进行垂直投影,结合水平投影和垂直投影能够确定字符的各个边界的坐标,即使答题卡排版改变,都不会对其区域确定产生影响,使其识别效率有了较大提升。定位到每个字符之后,基于深度学习的识别模型针对每个字符进行识别,有助于提高识别准确度。
根据上述任一个实施例的答题卡字符串识别方法,可选地,对区域图像进行水平投影和垂直投影,根据投影结果确定字符串中字符的坐标,具体包括:对区域图像进行二值化处理,得到二值图;对二值图进行水平投影和垂直投影,生成水平投影数据和垂直投影数据;根据水平投影数据确定限制字符填写位置的框线在水平方向上的坐标区域,根据垂直投影数据确定限制字符填写位置的框线在垂直方向上的坐标区域,水平方向的坐标区域对应于框线的上边界和下边界,垂直方向的坐标区域对应于框线的左边界和右边界;根据上边界、下边界、左边界和右边界确定框线的坐标,其中,水平投影用于计算二值图在水平方向上的像素点个数,垂直投影用于计算二值图在垂直方向上的像素点个数,框线的坐标即字符的坐标,用于表示字符所处的位置。
在该实施例中,为限制字符(字符串)的填写位置,字符周围存在文本框,针对字符周围的框线进行投影识别,进而确定每个字符的文本框。对于形式多样,排版不确定的各种答题卡,其一般都含有用于规定填写位置的框线(文本框),针对这些框线进行投影识别,不需要答题卡具有定位块,不需要使用特定纸质进行制作,并且能保证较高的识别准确度。
根据上述任一个实施例的答题卡字符串识别方法,可选地,还包括:根据框线的坐标在二值图中截取框线区域图像;确定框线区域图像中不含有字符,则删除区域图像。通过删除不含有字符的区域,降低深度学习模型的运算量,能够提高运算速度。
根据上述任一个实施例的答题卡字符串识别方法,可选地,步骤s102具体包括:根据光学字符识别模型识别答题卡图像,获取空白答题卡的文本内容信息以及文本位置信息。
在该实施例中,光学字符识别模型,即ocr(opticalcharacterrecognition,光学字符识别),ocr是指电子设备检查纸上打印的字符,通过检测暗亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。随着计算机处理能力的提升、识别算法的改进以及神经网络模型的完善,光学字符识别模型也会随之进步,能够准确获取图像中的文本的位置信息。
实施例二
如图2所示,根据本发明的另一个实施例的答题卡字符串识别方法,包括:步骤s202,输入一张空白答题卡图片;步骤s204,进行ocr识别;步骤s206,根据文本信息定位出考号的区域;步骤s208,输入答题卡图片,截取考号区域子图;步骤s210,对考号区域子图进行水平投影垂直投影,得到每个考号框的矩形坐标;步骤s212,深度学习模型识别考号。
在该实施例中,先对空白答题卡进行分析,获取待识别的字符串(考号)的位置信息,根据该位置信息能够直接在已填涂的答题卡中直接选取字符串区域的图像。步骤s210则通过投影的方式确定字符串的框线坐标,根据框线坐标截取相应的字符(考号中的数字)图像,将这些图像输入到基于深度学习的模型中进行识别,由于深度学习模型可根据实际需求进行训练,提高字符串识别过程的抗干扰能力,尤其对于手写字符串具有很好的识别效果。
实施例三
下面结合图3至图11对根据实施例二的答题卡字符串识别方法进行具体说明:
1、输入空白答题卡图像empty_img(参见图10,图10是空白答题卡的截图),进行ocr识别,得到含坐标的文本信息text_list;
文本信息如下:
[[”,[35,11,50,35]]]
[['(共23题总分150分)',[467,245,247,24]]]
[['姓名:班级:',[84,296,596,24]]]
[['准考证号:',[84,369,119,25]]]
[['1.答题前请先填写考生姓名、班级和准考证号',[167,577,500,25]]]
[['注',[101,610,38,23]]]
[['惹∣2.准考证号务必填写在方框内,每个方框填写一个数字',[101,626,668,35]]]
[['惠∣3.选择题必须使用2b铅笔填涂',[103,666,395,33]]]
[['项',[101,696,39,23]]]
[['一、单选题(每小题5分,共60分)',[114,807,453,31]]]
[['1.【a】【b】【c】【d】2.【a】【b】【c】【d】3.【a】【b】【c】【d】',[132,871,899,26]]]
[['4.【a】【b】【c】【d】5.【a】【b】【c】【d】6.【a】【b】【c】【d】',[128,928,903,27]]]
[['7.【a】【b】【c】【d】8.【a】【b】【c】【d】9.【a】【b】【c】【d】',[129,986,902,26]]]
[['10.【a】【b】【c】【d】11.【a】【b】【c】【d】12.【a】【b】【c】【d】',[116,1043,914,27]]]
[['二、填空题(每小题5分,共20分)',[112,1177,455,31]]]
[['13',[115,1287,39,19]]]
[['l4',[114,1368,39,20]]]
[['15.',[114,1450,39,21]]]
[['16',[113,1533,40,20]]]
[['三、问答题(本大题共7小题,共70分)',[78,1619,517,31]]]
[['请在各题目的答题区域内作答,超出黑色矩形边框限定区域的答案无效',[121,1693,776,26]]]
[['l17.(本小题满分12分)',[123,1775,335,30]]]
[['■]',[27,2146,51,34]]]
2、从文本信息中分析出考号的区域
2.1先确定考号区域的上边界。遍历text_list,text_list[i]匹配考号标题模板,若成功则返回其矩形框坐标,矩形框的y坐标作为考号区域的上边界。
考号标题模板形如:
(考号|准考证号|学号)
2.2再确定考号区域的下边界。以上边界为基准向下边界扩展n个像素点,其中n为经验值。
2.3根据上下边界得到考号的矩形区域student_id_region,再对其进行上下扩展50个像素点,防止倾斜导致截图不完整问题;
3、通过投影方法得到每个考号框的矩形坐标
3.1输入学生作答了的答题卡图像img,截取考号区域子图student_id_img,参见图3;
3.2对student_id_img进行二值化处理,得到二值图binary_img,参见图4。
3.3对binary_img进行水平投影(即在水平方向数0的个数),得到投影数组horizontal_projection,结果参见图5。
3.4取horizontal_projection的最大值max_len,过滤掉高度小于max_len/2的部分,再把宽度变为1,得到数组horizontal_projection1,结果参见图6。
3.5考号框的是一样长的,故水平投影后,上下边缘投影的结果也是长度基本一致的。遍历horizontal_projection1,若horizontal_projection1[i]与其连续的horizontal_projection1[j]的长度一致时,则i、j即为考号框的上下边缘的y坐标,即为up_y,down_y。
3.6在binary_img中取up_y与down_y之间是子图binary_sub_img,参见图7。
3.7对binary_sub_img进行垂直投影(即在垂直方向数0的个数),得到数组vertical_projectoin,参见图8。
3.8对vertical_projectoin进行化简,小于(down_y-up_y)*1/3的置为0,得到vertical_projectoin1,参见图9。
3.9对vertical_projectoin1进行遍历,若vertical_projectoin1[i]!=0,则i作为考号框的左边界left_index。继续遍历,若vertical_projectoin1[j]!=0且vertical_projectoin1[j]与vertical_projectoin1[i]的大小接近,则得到考号框的右边界right_index。
3.10以right_index-left_index作为单个考号框的宽度width,继续对vertical_projectoin1进行遍历,vertical_projectoin1[i]!=0,则i作为下一个考号框的左边界,以i+width为起点,在其前后8宽度范围内,从前往后找vertical_projectoin1[k]!=0,则k即为考号框的右边界。
3.11重复3.10,即可得到所有考号框的左右边界。
3.12结合上下边界及每个考号框的左右边界,即可得到每个考号框的矩形坐标[x,y,w,h]。
3.13检测考号框是否填写数字:
3.13.1用考号框的矩形坐标[x,y,w,h]在binary_img中截取子图,并上下左右缩小6个像素点,得到子图sub_img_one;
3.13.2计算sub_img_one中的像素点的均值pix_mean,若pix_mean大于阈值(经验值),则该考号框为空白的,删除之;
3.14考号框扩展;
3.14.1取第1个考号框与第2个考号框之间的间距的一半作为扩展值extend_value;
3.14.2对每个考号框的上下左右进行扩展extend_value_value个像素点,最终得到考号框的矩形坐标[x,y,w,h]。
4、考号识别
4.1以每个考号框的矩形坐标[x,y,w,h]在考号区域子图student_id_img截取子图student_id_sub_img;
4.2对每张student_id_sub_img按照尺寸d*h进行缩放;
4.3使用预训练的数字识别模型,识别每个子图student_id_sub_img,得到数字;识别结果如图11所示,图11中包含9个单独的数字;
4.4将4.3中的每个数字合并,图11中的9个单独数字组合即为考号(待识别的字符串)。考号:201802002。
5、数字识别模型训练
5.1模型数据
5.1.1使用真实标注的图片数据40000张,其中有带边框的数字、有不带边框的数字。
5.1.2图片统一处理为预设的尺寸d*h
5.2模型网络(深度学习模型的实现方法)
5.2.1构建densenet网络
densenet由5层denseblock(由多个bn+relu+conv组成)和3层transitionlayer(由bn-conv-pool组成)组成,及growthratek=12,densenet(k=4)。
在该实施例中实现字符串(数字)识别的深度学习模型为densenet(全称“denselyconnectedconvolutionalnetworks”,密集连接卷积网络),densenet是一种具有密集连接的卷积神经网络,在该网络中,任何两层之间都有直接的连接,也即网络每一层的输入都是前面所有层输出的并集,该层所学习的特征图也会被直接传给其后所有的层,作为输入。详情请参阅densenet网络论文链接:https://arxiv.org/pdf/1608.06993.pdf。
5.2.3模型训练
模型迭代训练50000次,训练准确率0.9986,验证集准确率0.9993。
其中,数字识别模型可以使用其他的cnn模型搭建,比如resnet、googlenet、vgg-nets、alexnet、lenet等。
实施例四
如图12所示,根据本发明的一个实施例的答题卡字符串识别装置300,包括:存储器302、处理器304及存储在存储器302上并可在处理器304上运行的程序,程序被处理器304执行时实现如上述任一实施例的答题卡字符串识别方法的步骤。该答题卡字符串识别装置300包括如上述任一项实施例的答题卡字符串识别方法的全部有益效果,在此不再赘述。
实施例五
如图13所示,根据本发明的一个实施例的终端400,包括:上述答题卡字符串识别装置300。该终端400运行时能够实现:对答题卡图像进行文本识别,获取文本内容信息以及文本位置信息;根据文本内容信息以及文本位置信息定位待识别的字符串,以确定字符串所处的区域;基于深度学习模型对字符串所处的区域进行识别,以获取字符串。该终端400包括如上述任一实施例的答题卡字符串识别方法的全部有益效果,在此不再赘述。
实施例六
根据本发明的一个实施例,还提供了一种计算机可读存储介质,其上存储有计算机程序,上述计算机程序被执行时实现上述任一实施例限定的答题卡字符串识别方法。
针对现有技术中存在的技术问题,本发明提出了一种答题卡字符串识别方法、装置和计算机可读存储介质,利用文本识别技术,获取答题卡中目标字符串的位置信息,而不需要定位块进行定位,能够兼容各种形式的答题卡,对存在目标字符串的图像区域进行水平投影和垂直投影,获取每个字符串中每个字符的位置从而进行精确识别,抗干扰能力强,识别率高。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
应当注意的是,在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的部件或步骤。位于部件之前的单词“一”或“一个”不排除存在多个这样的部件。本发明可以借助于包括有若干不同部件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!